







鉴于Transformer盛行,导致模型训练已经ImageNet打底了,因此这里得学点分布式训练的知识,不然大数据集都训练不起来,本文是根据参考文献的一些归纳总结和自我理解,在学之前我们先看一下GPU的通信方式(源自PyTorch官方文档GETTING STARTED WITH DISTRIBUTED DATA PARALLEL):
点对点通信

集群通信
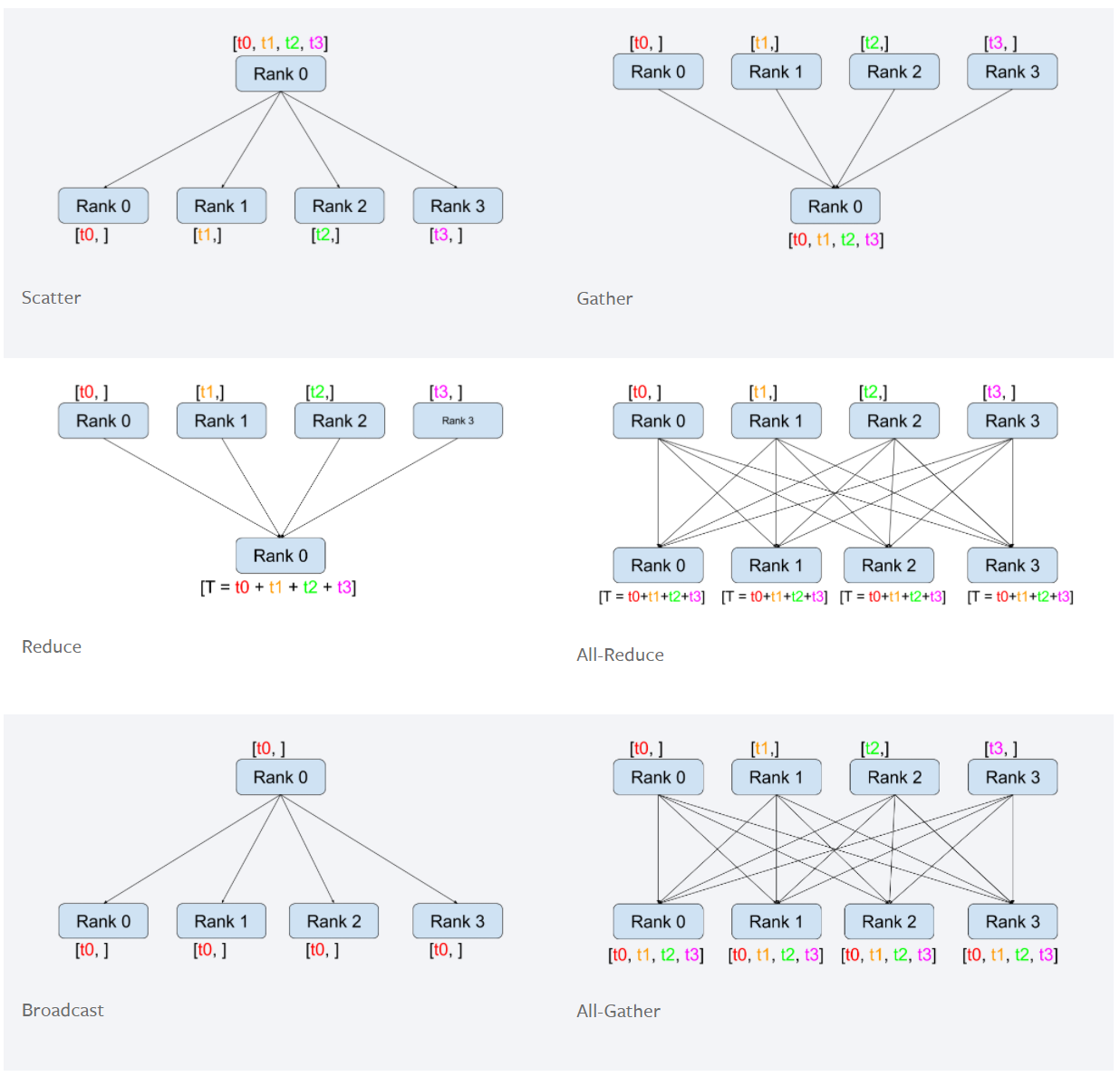
这里解释一下Reduce和All-Reduce,因为DDP中会用到。所谓的Reduce,就是不同节点各有一份数据,把这些数据汇总到一起。在这里,我们规定各个节点上的这份数据有着相同的shape和data type,并规定汇总的方法是相加。而All-Reduce则在Reduce的基础上,把最终的结果发回到各个节点上,All-Reduce的实现就是使用了ring思想(会在下文中涉及到)。
再来了解一下什么是线程和进程:进程=火车,线程=车厢,(源自知乎答主biaodianfu,回答主页在此:线程和进程的区别是什么?)
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
DP
DP即Data Parallel,是一种单机多卡的、参数服务器架构的多卡训练模式,在PyTorch中可以用以下命令简单表示:
model = torch.nn.DataParallel(model)
它总共只有一个进程,通过master节点向其他卡广播其参数;在梯度反向传播后,各卡将梯度集中到master节点,master节点对搜集来的参数进行平均后更新参数,再将参数统一发送到其他卡上。
DDP
与DP不同,DDP采用Ring-Reduce通讯方式,其通讯方式如下图所示(图源自ring allreduce和tree allreduce的具体区别是什么?中Garvin Li的回答):

Ring-Reduce每个gpu只需和他前一个和后一个gpu通讯即可,其具体流程如下列图所示(下列流程图均来自浅谈Tensorflow分布式架构:ring all-reduce算法):
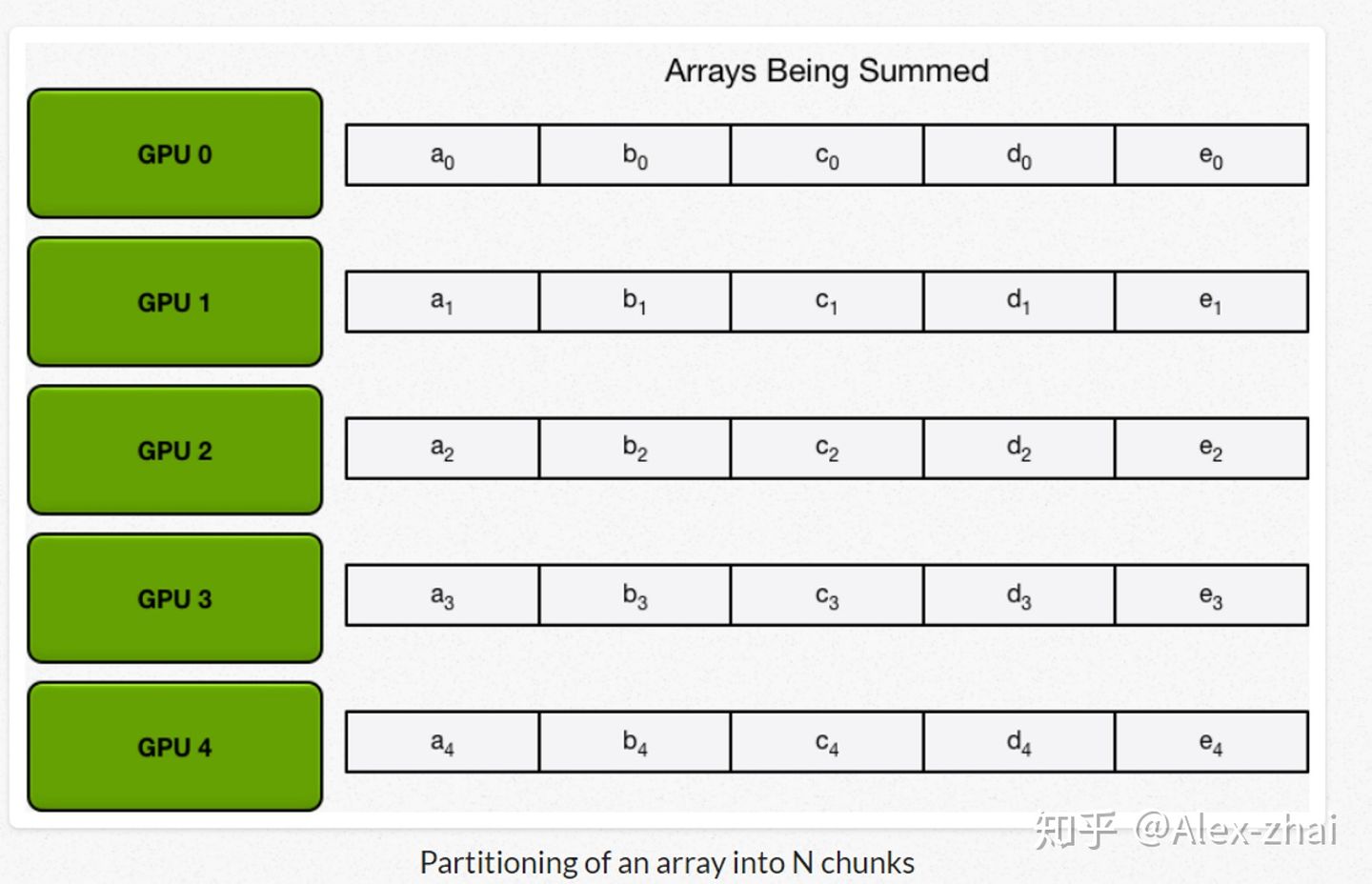
首先先将数据分成相应的5份(因为这里拿5个gpu举例),在神经网络中对应的就是把总的batchsize分成batchsize*5。
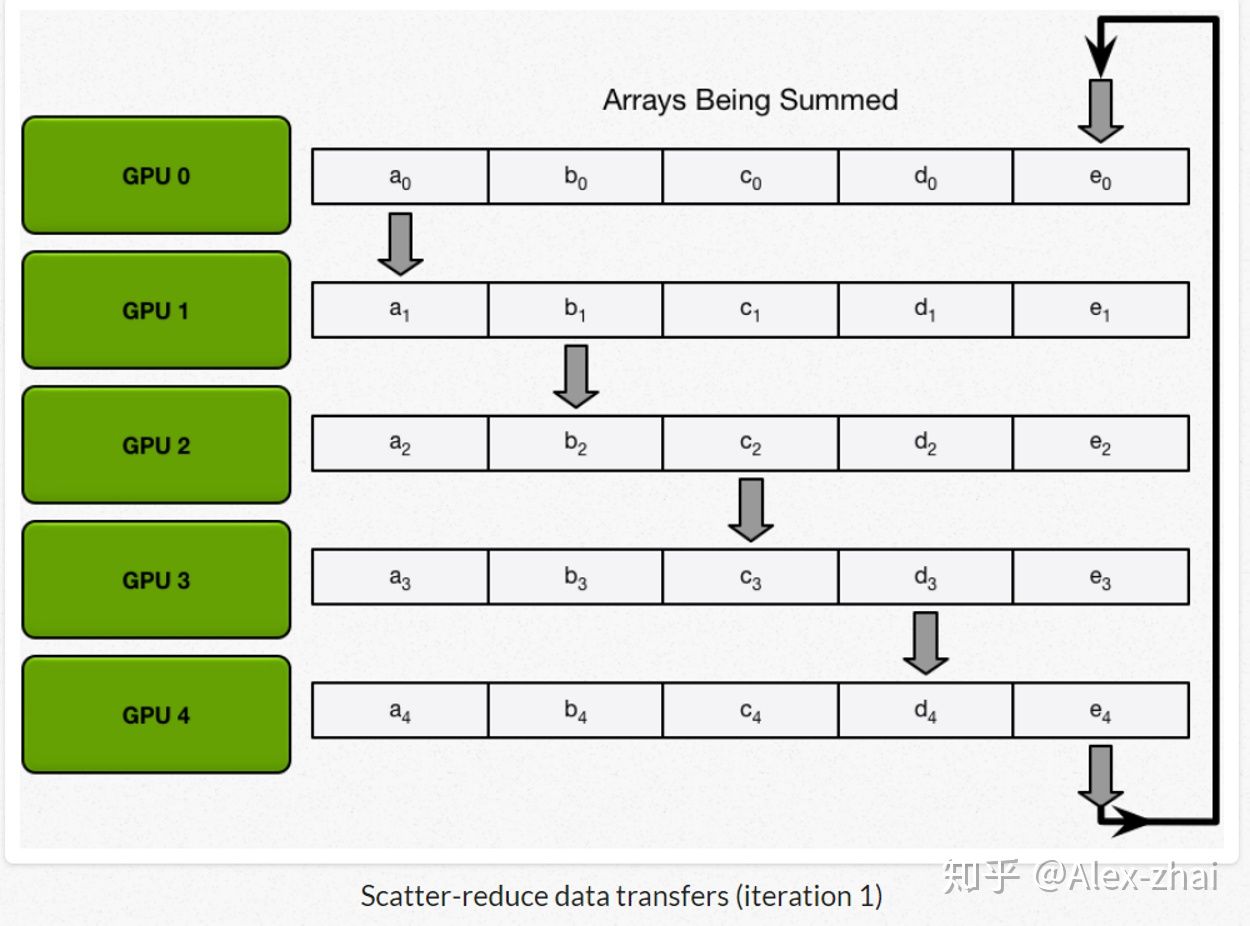
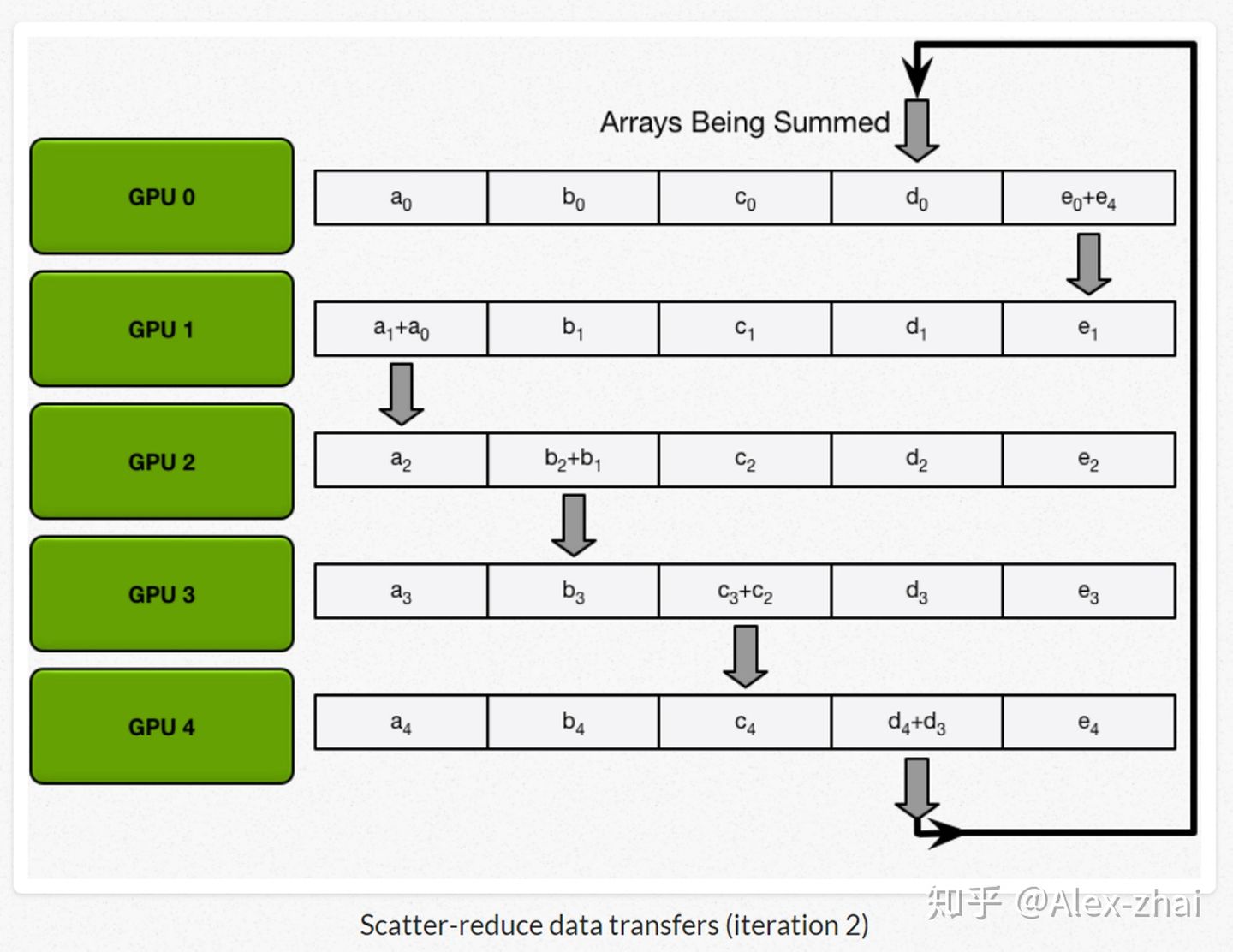
接着进行scatter-reduce:逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分。
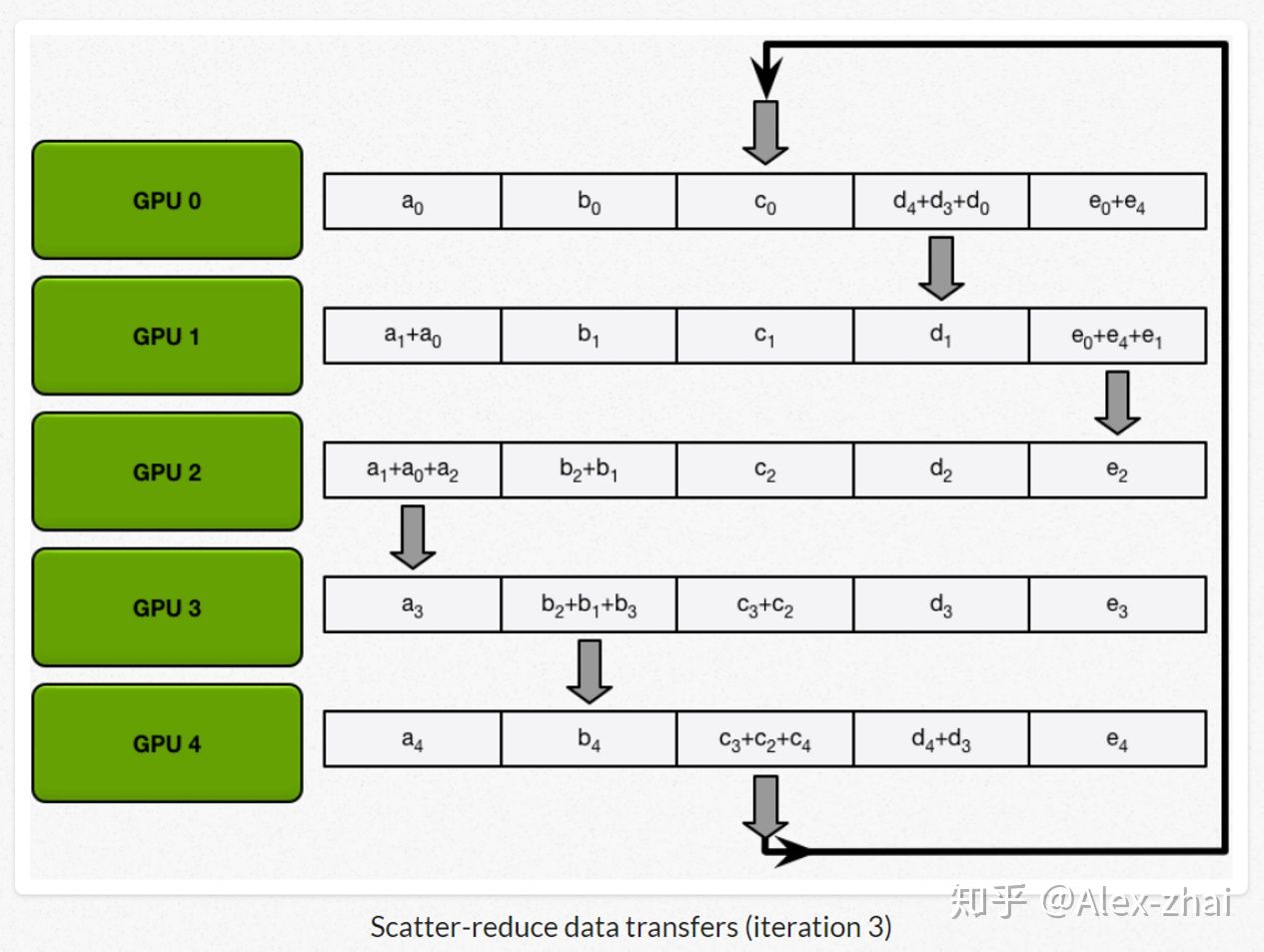
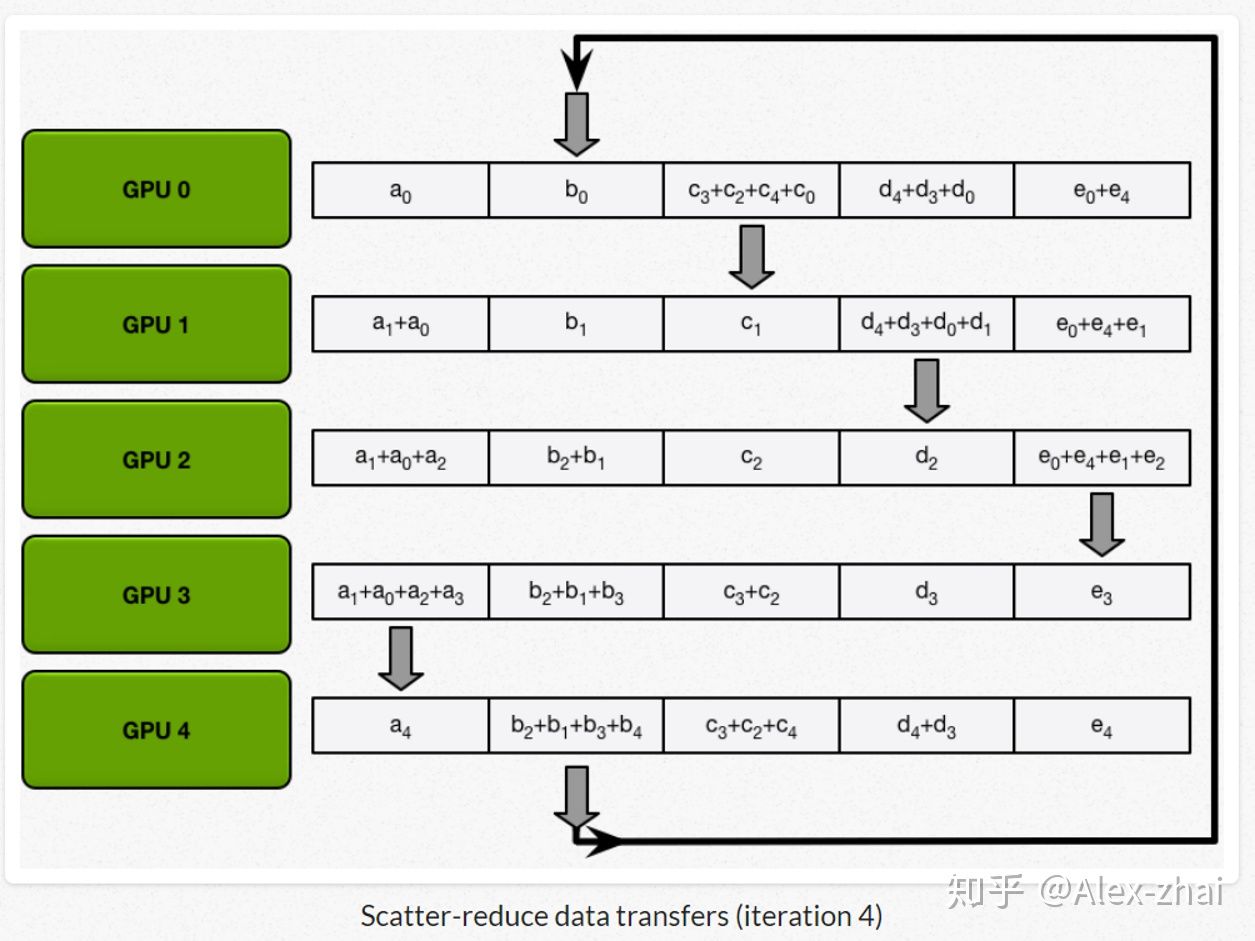
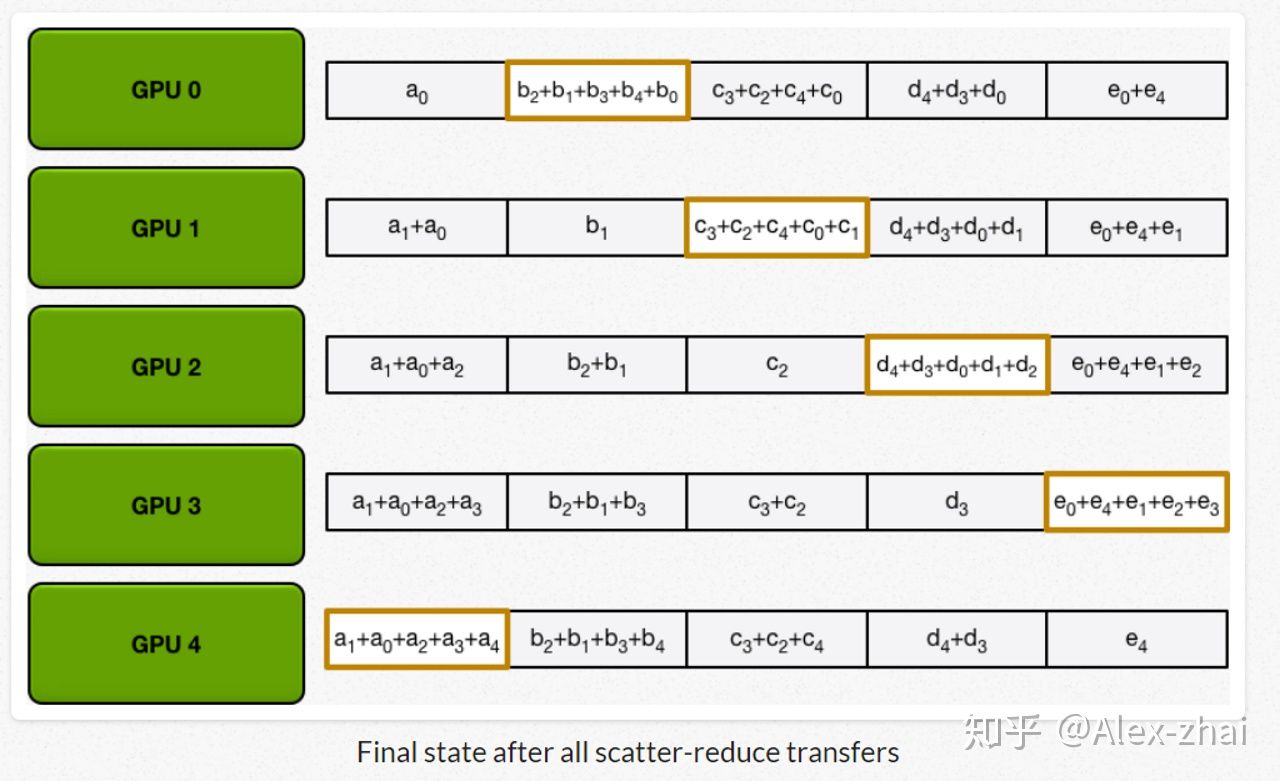
最后进行allgather:GPU 逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度。
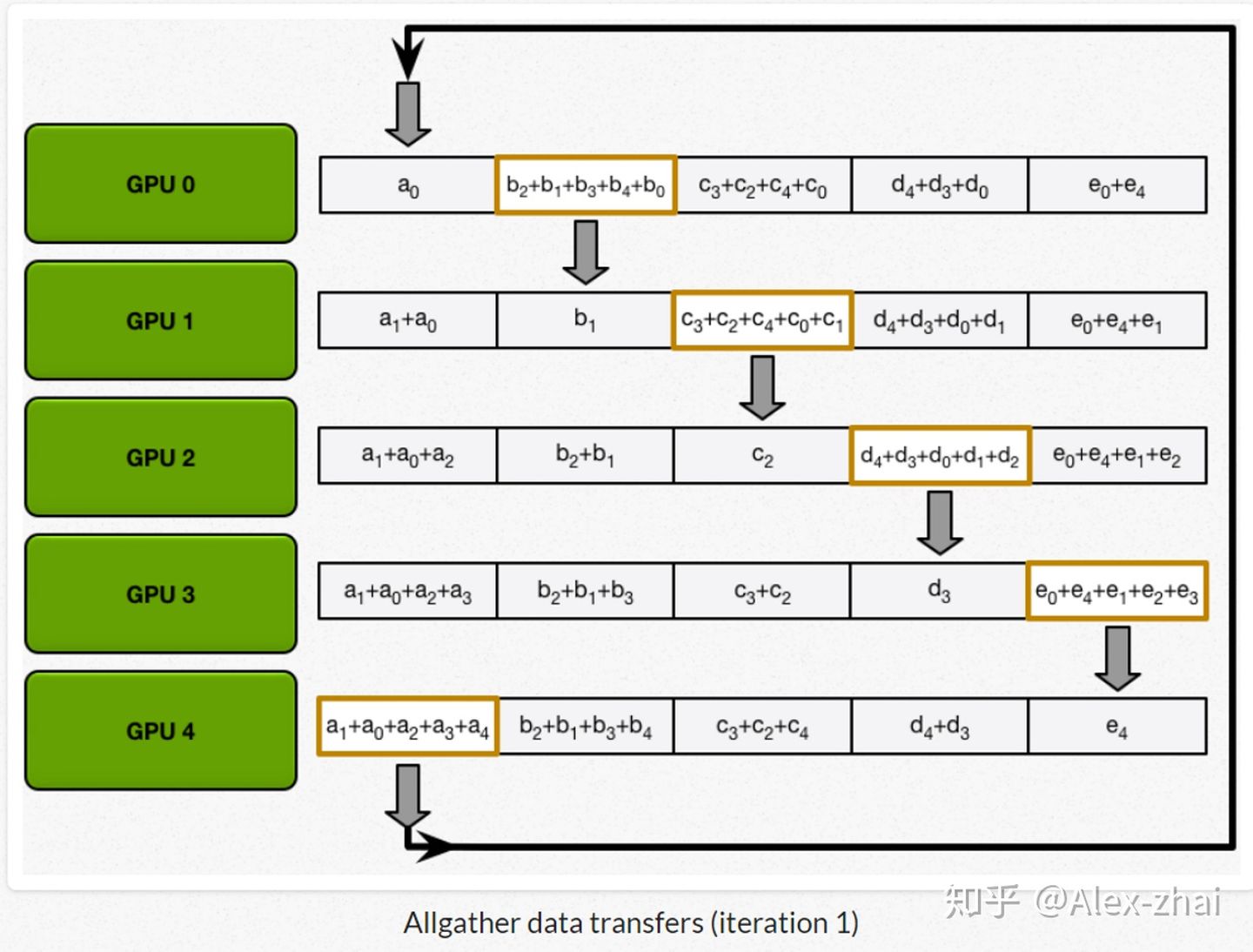
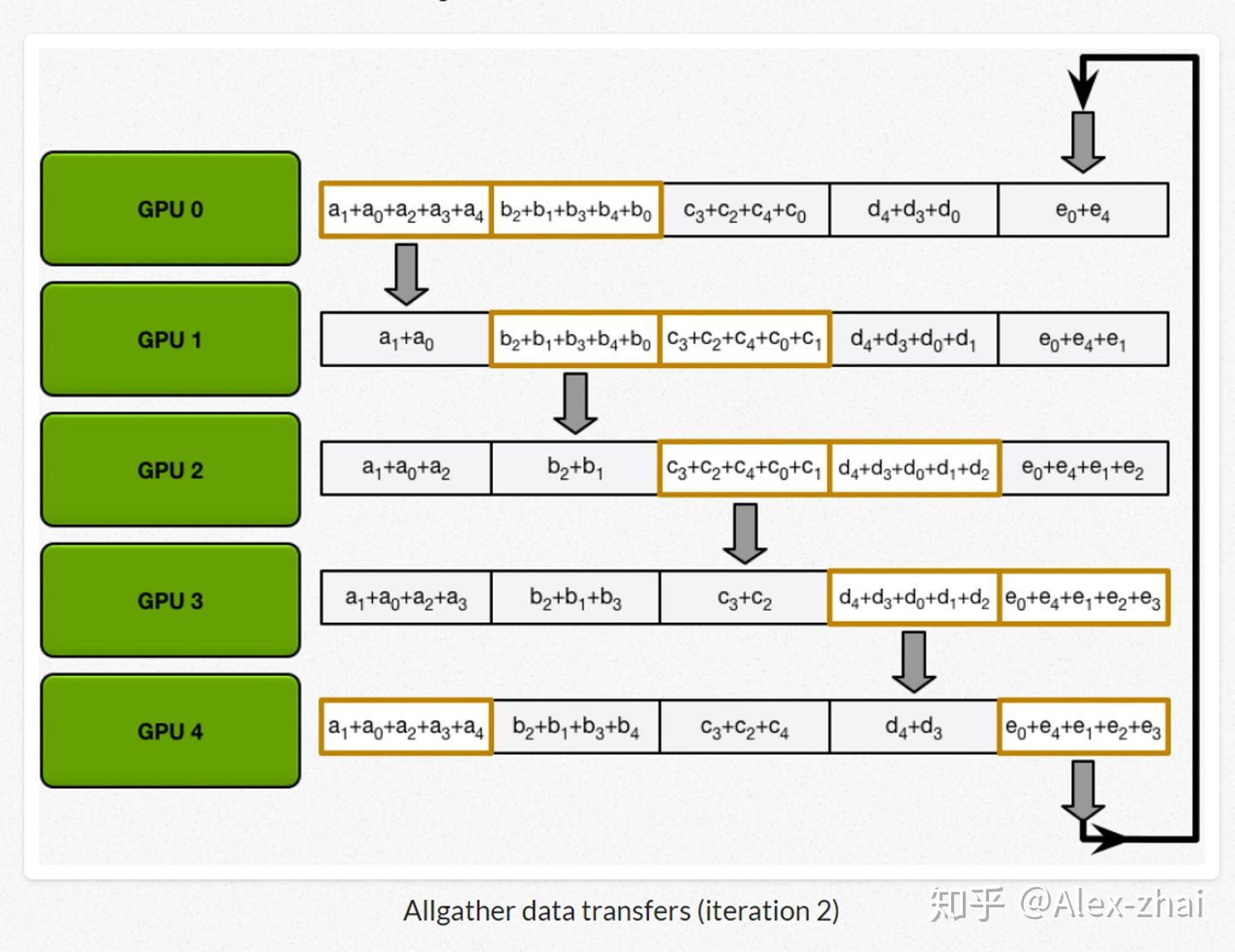
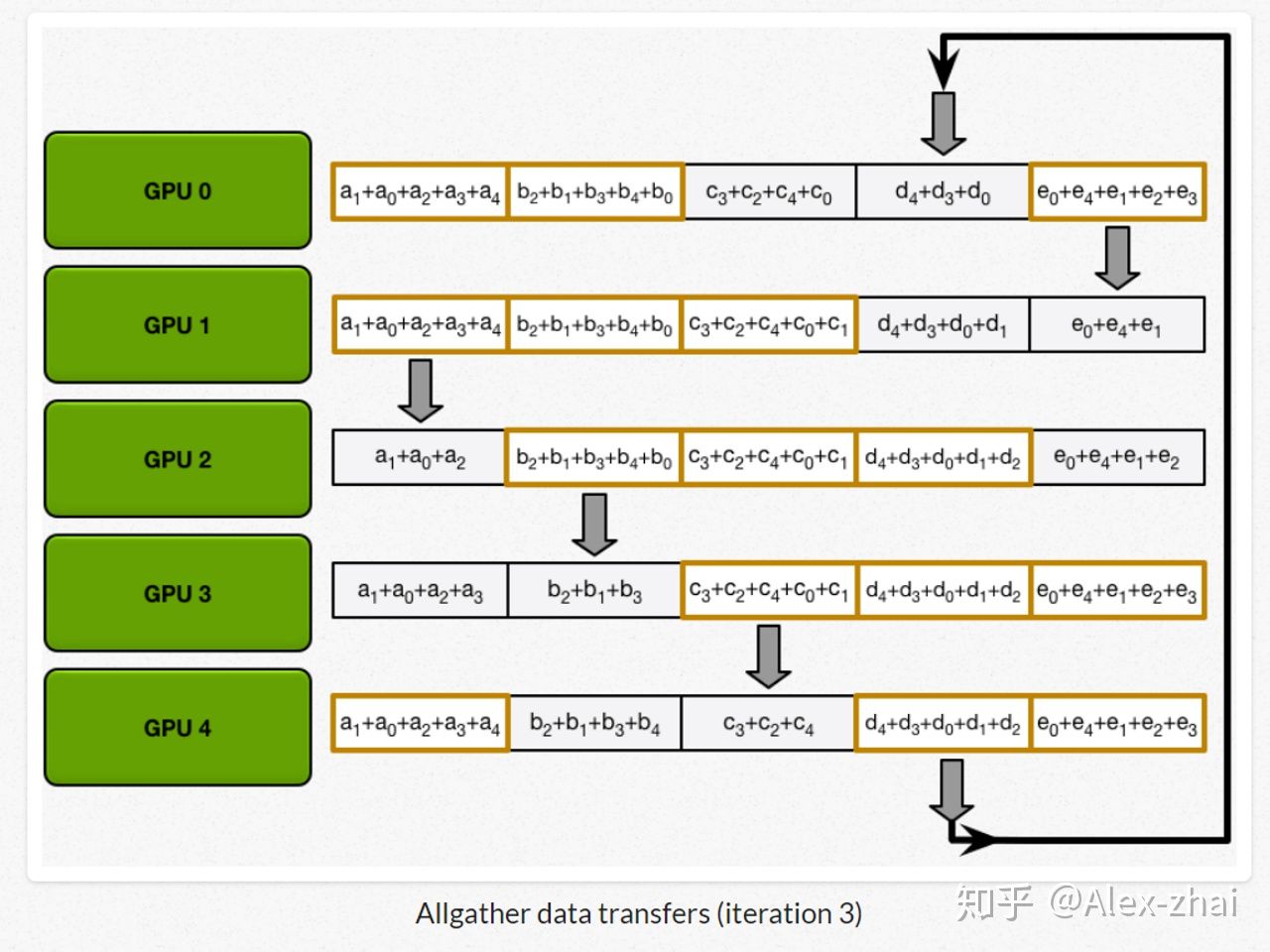
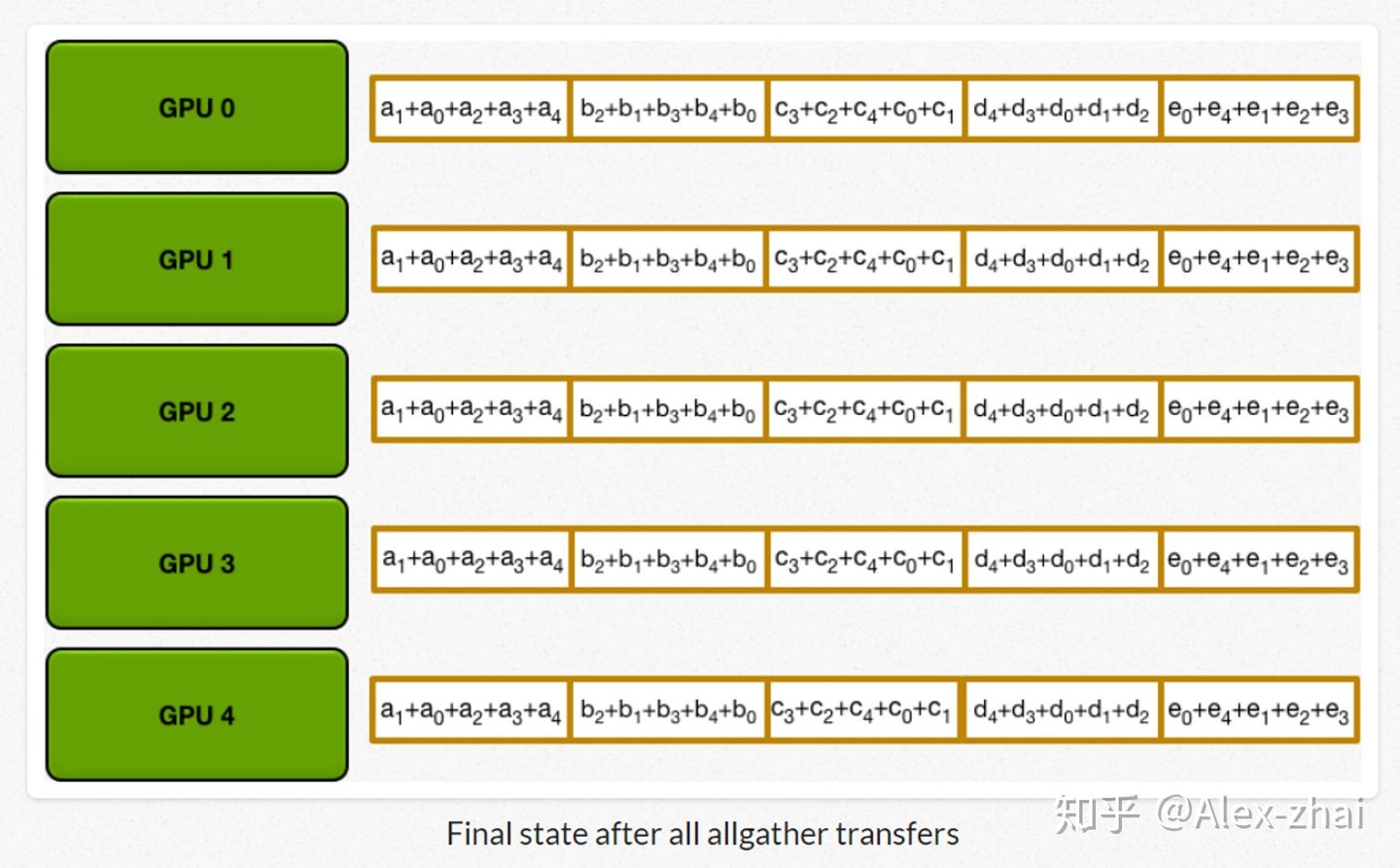
相比于DP每个进程都得和主进程进行通讯, DDP每个进程只跟自己上下游两个进程进行通讯,极大地缓解了参数服务器的通讯阻塞。
在PyTorch中使用DDP
有了上述前置知识后我们可以开始学习DDP模式了,具体来说其可以分为以下三种(分类源自DDP系列第一篇:入门教程):
- 每个进程一张卡。DDP的最佳使用方法。
- 每个进程多张卡,复制模式。一个模型复制在不同卡上面,每个进程都实质等同于DP模式。这样做是能跑得通的,但是,速度不如上一种方法,一般不采用。
- 每个进程多张卡,并行模式。一个模型的不同部分分布在不同的卡上面。例如,网络的前半部分在0号卡上,后半部分在1号卡上。这种场景,一般是因为我们的模型非常大,大到一张卡都塞不下batch size = 1的一个模型。
接着我们来介绍一下DDP中一些常见参数:
- group:进程组,默认情况下,只有一个组。
- world size:表示全局进程个数,一般和 GPU 数相同(单进程单GPU情况)。
- rank:表示进程序号,用于进程间通讯,表征进程优先级,序号一般从 0 到 world_size - 1。rank = 0 的主机为 master 节点。
- local_rank:进程内 GPU 编号,非显式参数,一般为一台主机内的 GPU 序号(从 0 到该机 GPU 数减一),由 torch.distributed.launch 内部指定。
DDP基本使用流程
- 在使用 distributed 包的任何其他函数之前,需要使用
init_process_group 初始化进程组,同时初始化 distributed 包 - 如果需要进行小组内集体通信,用 new_group 创建子分组
- 创建分布式并行模型 DDP(model, device_ids=device_ids)
- 为数据集创建 Sampler
- 使用启动工具 torch.distributed.launch 在每个主机上执行一次脚本,开始训练
- 使用 destory_process_group() 销毁进程组
在Pytorch 分布式训练中有对各个函数、概念、后端等等非常详细的介绍,常见的DDP命令也详见Pytorch DistributedDataParallel 多卡训练,本文就不再赘述(其实是我不会)。
代码练习
## main.py文件
import torch
import argparse
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1)
FLAGS = parser.parse_args()
local_rank = FLAGS.local_rank
# DDP backend初始化
# a.根据local_rank来设定当前使用哪块GPU
torch.cuda.set_device(local_rank)
# b.初始化DDP,使用默认backend(nccl for gpu)
dist.init_process_group(backend='nccl')
device = torch.device("cuda", local_rank)
model = nn.Linear(10, 10).to(device)
# 初始化DDP模型
model = DDP(model, device_ids=[local_rank], output_device=local_rank)
my_trainset = torchvision.datasets.CIFAR10(root='./data', train=True)
# 使用DistributedSampler,
train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset)
# 需要注意的是,这里的batch_size指的是每个进程下的batch_size。也就是说,总batch_size是这里的batch_size再乘以并行数(world_size)。
trainloader = torch.utils.data.DataLoader(my_trainset, batch_size=batch_size, sampler=train_sampler)
for epoch in range(num_epochs):
# 设置sampler的epoch,DistributedSampler需要这个来维持各个进程之间的相同随机数种子
trainloader.sampler.set_epoch(epoch)
# 后面这部分,则与原来完全一致了。
for data, label in trainloader:
prediction = model(data)
loss = loss_fn(prediction, label)
loss.backward()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.step()
# 保存模型
if dist.get_rank() == 0:
torch.save(model.module, "saved_model.ckpt")
启动方式
针对 DDP 并行化,需要用 torch.distributed.launch 来启动训练。其中可选参数如下
--nnodes:可用的机器数
--node_rank:当前机器的编号
--nproc_per_node:每台机器启动的进程数,一般为 GPU 数
address,port:多机多卡是通过这个指定的 IP 和端口号进行数据通信
# example
## Bash运行
# 假设我们只在一台机器上运行,可用卡数是8
python -m torch.distributed.launch --nproc_per_node 8 main.py
# 假设我们在2台机器上运行,每台可用卡数是8
# 机器1:
python -m torch.distributed.launch --nnodes=2 --node_rank=0 --nproc_per_node 8 \
--master_adderss $my_address --master_port $my_port main.py
# 机器2:
python -m torch.distributed.launch --nnodes=2 --node_rank=1 --nproc_per_node 8 \
--master_adderss $my_address --master_port $my_port main.py
# 假设我们只用4,5,6,7号卡
CUDA_VISIBLE_DEVICES="4,5,6,7" python -m torch.distributed.launch --nproc_per_node 4 main.py
DDP的一些常见的坑和技巧详见:PyTorch 如何使用分布式训练和DDP系列第三篇:实战与技巧。(墙裂推荐!!!)
Flag
我还没实际测过效果,等下次服务器集群弄好了再好好研究一下,看看多卡DDP比DP能快多少。














 1547
1547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









