









深度学习基础–多层感知机(MLP)
最近在阅读一本书籍–Dive-into-DL-Pytorch(动手学深度学习),链接:https://github.com/newmonkey/Dive-into-DL-PyTorch,自身觉得受益匪浅,在此记录下自己的学习历程。
本篇主要记录关于多层感知机(multilayer perceptron, MLP)的知识。多层感知机是在单层神经网络的基础上引入一个或多个隐藏层。
以单层神经网路SOFTMAX回归为例子。给定一个小批量样本X,假设输出层的softmax回归的权重和偏差参数分别为Wo和bo,输出层的输出记为O,则softmax回归的计算表达式为:
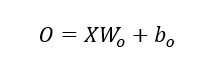
在上述的SOFTMAX回归中,我们在输入层与输出层间引入一个隐藏层,形成多层感知机。假设隐藏层的输出记为H,隐藏层的权重参数和偏差参数分别为Wh和bh,∅表示激活函数。则这个多层感知机的计算表达式为:
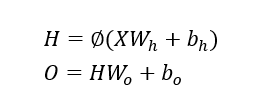
上述式子联立可得:
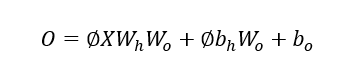
利用pytorch实现上述的多层感知机:
0 引入相关的包
import torch
from torch import nn
from torch.nn import init
import numpy as np
import torchvision
import torchvision.transforms as transforms
1 获取数据集
采用的是Fashion-MNIST数据集。def load_data_fashion_mnist(batch_size, root='~/Datasets/FashionMNIST'):
transform = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform)
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
return train_iter, test_iter
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size)
2 定义和初始化模型
采用ReLU函数作为激活函数。num_inputs, num_outputs, num_hiddens = 784, 10, 256
class FlattenLayer(torch.nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x shape: (batch, *, *, ...)
return x.view(x.shape[0], -1)
net = nn.Sequential(
FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
for params in net.parameters():
init.normal_(params, mean=0, std=0.01)
3 定义损失函数
仍是采用SOFTMAX回归使用的交叉熵损失函数loss = torch.nn.CrossEntropyLoss()
4 定义优化算法
采用⼩批量随机梯度下降(SGD)为优化算法。optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
5 训练模型
迭代周期设置为5,训练模型。def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,params=None, lr=None, optimizer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y).sum()
# 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
sgd(params, lr, batch_size)
else:
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
num_epochs = 5
train_ch3(net, train_iter, test_iter, loss, num_epochs,batch_size, None, None, optimizer)
#结果
#epoch 1, loss 0.0031, train acc 0.709, test acc 0.798
#epoch 2, loss 0.0019, train acc 0.819, test acc 0.819
#epoch 3, loss 0.0017, train acc 0.844, test acc 0.840
#epoch 4, loss 0.0015, train acc 0.856, test acc 0.820
#epoch 5, loss 0.0014, train acc 0.864, test acc 0.832
END!















 1673
1673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









