







上一篇博客自己写了一些这一周配环境的经历,确实也不容易,可能就是一个很小的问题,却需要去寻找大量的资料去解决,现在回想起来确实也很容易了,就是过程有点艰难~hhh。环境配好了以后,以后就是理论加实践的学习了。到了现在,时间也已经进入1月份了,时间也已经变得十分紧张了,之前学过的一些内容,可能也有点遗忘,需要重新拿起来了。
在网络中加入隐藏层
通过加入一个或者多个隐藏层来克服线性模型的限制,就可以处理更普遍的函数关系模型。将许多全连接层堆叠在一起,每一层都输出到上面的层,知道生成最后的输出。可以把前L-1层看作表示,把最后一层看作线性预测器。这种架构就是多层感知机。
每个输入都会影响隐藏层中的每个神经元,而隐藏层中的每个神经元又会影响输出层中的每个神经元。
对于具有h个隐藏单元的单隐藏层多层感知机,用H属于R的n*h次幂表示隐藏层的输出,称为隐藏表示。
因为隐藏层和输出层都是全连接的,所以有隐藏层权重W1和隐藏层偏置b1,还有就是输出层权重W2和输出层偏置b2。按如下方式计算单隐藏层多层感知机的输出O。
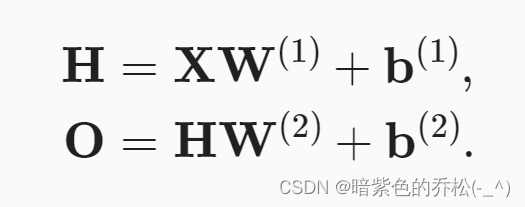
还需要一个在仿射变换之后对每个隐藏单元应用非线性的激活函数,激活函数的输出是活性值,有了激活函数之后,就不会将多层感知机退化成线性模型。σ表示激活函数。
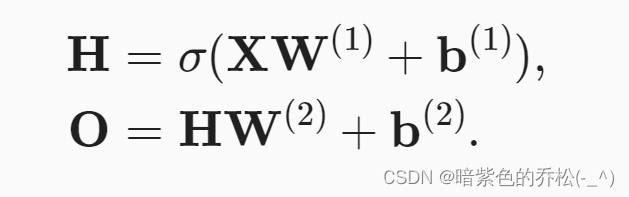
多层感知机可以通过隐藏神经元,捕捉到输入之间复杂的相互作用,这些神经元依赖于每个输入的值。
激活函数
激活函数通过计算加权和并加上偏置来确定神经元是否应该被激活,将输入信号转换为输出的可微运算。大多数激活函数都是非线性的。
首先是ReLU函数:
给定元素x,ReLU函数被定义为该元素与0的最大值:
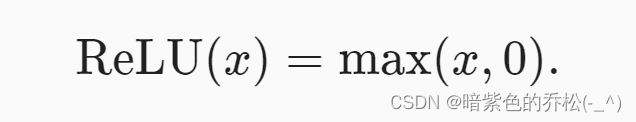
ReLU函数通过将相应的活性值设为0,仅保留正确元素并丢弃所有负元素,激活函数是分段线性的。
sigmoid函数:
对于一个定义域在R上的输入,sigmoid函数将输入变换为区间(0,1)上的输出,就相当于被挤压了一下。
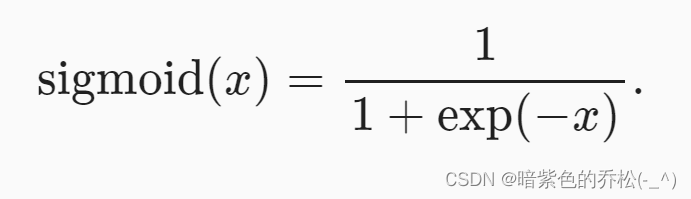
tanh函数:
当输入在0附近是,函数接近线性变换,和sigmoid函数类似,但是tanh函数关于坐标系原点中心对称。
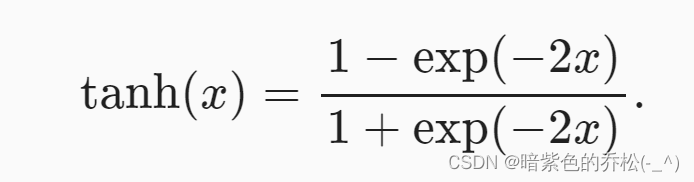
总结:
多层感知机在输出层和输入层之间增加一个或多个全连接隐藏层,并通过激活函数转换隐藏层的输出。
常用的激活函数包括ReLU函数,sigmoid函数和tanh函数。
多层感知机的简洁实现
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
模型选择、欠拟合和过拟合
影响模型泛化的因素:
可调整参数的数量。当可调整参数的数量很大时,模型往往更容易过拟合。
参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个很灵活的模型。
通常在评估几个候选模型后选择最终的模型,这个过程叫做模型选择。
我们常将数据分成三份,除了训练集和和测试数据集,还增加一个验证集。
欠拟合,说简单一点的话,就是没达到预期的拟合效果。
是否过拟合或者欠拟合取决于模型复杂性和可用训练数据集的大小。
训练数据集中的样本越少,就越有可能过拟合,随着训练数据的增加,泛化误差通常会减小。
总结:
欠拟合是指模型无法继续减少训练误差。过拟合是指训练误差远小于验证误差。
由于不能基于训练误差来估计泛化误差,因此简单地最小化训练误差并不一定意味着泛化误差的减小。机器学习模型需要注意防止过拟合,防止泛化误差过大。
验证集可以用于模型选择,但不能过于随意地使用它。
应该选择一个复杂度适当的模型,避免使用数量不足的训练样本。
权重衰减
总结:
正则化是处理过拟合的常用方法:在训练集的损失函数中加入惩罚项,来降低学习到的模型的复杂度。
保持模型简单的一个特别的选择是使用L2惩罚权重衰减。
在一训练代码实现中,不同的参数集可以有不同的更新行为。















 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











