







从数据的角度而言,我们让
模型更加倾向于努力攻克那些难以判断的样本
。但是,并不是说只要我新建了一棵倾向于困难样本的决策树,它就能够帮我把困难样本判断正确了。困难样本被加重权重是因为前面的树没能把它判断正确,所以对于下一棵树来说,它要判断的测试集的难度,是比之前的树所遇到的数据的难度都要高的,那要把这些样本都判断正确,会越来越难。所以,除了保证模型逐渐倾向于困难样本的方向,我们还必须控制新弱分类器的生成,
保证每次新添加的树一定得是对这个新数据集预测效果最优的那一棵树。
思考:怎么保证每次新添加的树一定让集成学习的效果提升?
- 也许我们可以枚举
- 也许可以学习sklearn中的决策树构建树时一样随机生成固定数目的树,然后生成最好的那一棵
平衡算法表现和运算速度是机器学习的艺术,
我们希望能找出一种方法,直接帮我们求解出最优的集成算法结果。求解最优结果,我们能否把它转化成一个传统的
最优化问题
呢?
最优化过程

现在我们希望求解集成算法的最优结果,那我们应该可以使用同样的思路:我们首先找到一个损失函数 ,这个损失函数应该可以通过带入我们的预测结果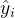 来衡量我们的梯度提升树在样本的预测效果。然后,我们利用梯度下降来迭代我们的集成算法:
来衡量我们的梯度提升树在样本的预测效果。然后,我们利用梯度下降来迭代我们的集成算法:

在k次迭代后,我们的集成算法中总共有k棵树,k棵树的集成结果是前面所有树上的叶子权重的累加。所以我们让k棵树的集成结果加上我们新建的树上的叶子权重,就可以得到第k+1次迭代后,总共k+1棵树的预测结果了。我们让这个过程持续下去,直到找到能够让损失函数最小化的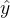 ,这个就是我们模型的预测结果。参数可以迭代,集成的树林也可以迭代。
,这个就是我们模型的预测结果。参数可以迭代,集成的树林也可以迭代。
迭代决策树的公式

其中
eta
是迭代决策树时的步长(
shrinkage
),又叫做学习率(
learning rate
)。它的值越大,迭代的速度越快,算法的极限很快被达到,有可能无法收敛到真正的最佳。 越小,越有可能找到更精确的最佳值,更多的空间被留给了后面建立的树,但迭代速度会比较缓慢。
参数设置
|
参数含义
|
xgb.train()
|
|
集成中的学习率,又称为步长
以控制迭代速率,常用于防止过拟合
|
eta
,默认
0.3
取值范围
[0,1]
|
除了运行时间,步长还是一个对模型效果影响巨大的参数,如果设置太大模型就无法收敛(可能导致 很小或者MSE很大的情况,如果设置太小模型速度就会非常缓慢,但它最后究竟会收敛到何处很难由经验来判定,在训练集 上表现出来的模样和在测试集上相差甚远,很难直接探索出一个泛化误差很低的步长。
所以通常,我们不调整 ,即便调整,一般它也会在
[0.01,0.2]
之间变动。如果我们希望模型的效果更好,更多的可能是从树本身的角度来说,对树进行剪枝,而不会寄希望于调整这个参数值。
很小或者MSE很大的情况,如果设置太小模型速度就会非常缓慢,但它最后究竟会收敛到何处很难由经验来判定,在训练集 上表现出来的模样和在测试集上相差甚远,很难直接探索出一个泛化误差很低的步长。
所以通常,我们不调整 ,即便调整,一般它也会在
[0.01,0.2]
之间变动。如果我们希望模型的效果更好,更多的可能是从树本身的角度来说,对树进行剪枝,而不会寄希望于调整这个参数值。
















 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











