







独特的目标函数
梯度提升算法中都存在着损失函数。不同于逻辑回归和SVM
等算法中固定的损失函数写法,集成算法中的损失函数是可选的,要选用什么损失函数取决于我们希望解决什么问题,以及希望使用怎样的模型。比如说,如果我们的目标是进行
回归预测
,那我们可以选择
调节后的均方误差RMSE
作为我们的损失函数。如果我们是进行
分类预测
,那我们可以选择
错误率error
或者
对数损失log_loss
。只要我们选出的函数是一个可微的,能够代表某种损失的函数,它就可以作为XGB的
损失函数
。
在众多机器学习算法中,损失函数的核心是衡量模型的泛化能力,即模型在未知数据上的预测的准确与否,我们训练模型的核心目标也是希望模型能够预测准确。在XGB中,预测准确自然是非常重要的因素,但我们之前提到过,XGB的是实现了模型表现和运算速度的平衡的算法。普通的损失函数,比如错误率,均方误差等,都只能够衡量模型的表现,无法衡量模型的运算速度。回忆一下,我们曾在许多模型中使用空间复杂度和时间复杂度来衡量模型的运算效率。XGB因此引入了模型复杂度来衡量算法的运算效率。因此
XGB
的目标函数被写作:
传统损失函数 + 模型复杂度
。

其中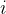 代表数据集中的第个样本,
代表数据集中的第个样本,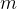 表示导入第
表示导入第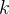 棵树的数据总量,
棵树的数据总量,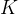 代表建立的所有树。
第一项代表传统的损失函数
,衡量真实标签
代表建立的所有树。
第一项代表传统的损失函数
,衡量真实标签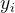 与预测值
与预测值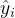 之间的差异,通常是RMSE,调节后的均方误差。
第二项代表模型的复杂度
,使用树模型的某种变换
之间的差异,通常是RMSE,调节后的均方误差。
第二项代表模型的复杂度
,使用树模型的某种变换 表示,这个变化代表了一个从树的结构来衡量树模型的复杂度的式子,可以有多种定义。注意,我们的
第二项中没有特征矩阵
的介入。我们在迭代每一棵树的过程中,都最小化
表示,这个变化代表了一个从树的结构来衡量树模型的复杂度的式子,可以有多种定义。注意,我们的
第二项中没有特征矩阵
的介入。我们在迭代每一棵树的过程中,都最小化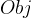 来力求获取最优的
来力求获取最优的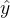 ,因此我们同时最小化了模型的错误率和模型的复杂度。
,因此我们同时最小化了模型的错误率和模型的复杂度。
类比于方差-偏差困境
与其他算法一样,我们最小化目标函数以求模型效果最佳,并且我们可以通过限制
n_estimators
来限制我们的迭代次数,因此我们可以看到生成的每棵树所对应的目标函数取值。目标函数中的第二项看起来是与棵树都相关,但我们的第一个式子看起来却只和样本量相关,仿佛只与当前迭代到的这棵树相关。
其实并非如此,我们的第一项传统损失函数也是与已经建好的所有树相关的,相关在这里:


上式中的
第一项是衡量我们的偏差
,模型越不准确,第一项就会越大。
第二项是衡量我们的方差
,模型越复杂,模型的学习就会越具体,到不同数据集上的表现就会差异巨大,方差就会越大。所以我们求解的最小值,其实是在求解方差与偏差的平衡点,以求模型的泛化误差最小,运行速度最快。
我们知道树模型和树的集成模型是天生的
过拟合
的模型,因此我们必须通过
剪枝
来控制模型不要过拟合。现在XGBoost的损失函数中自带限制方差变大的部分,也就是说
XGBoost会比其他的树模型更加聪明,不会轻易过拟合。
参数设置
在应用中,我们使用参数"
obj
"来确定我们目标函数的第一部分中的 ,也就是衡量损失的部分。
xgb.train()的参数obj默认选择时binary:logistic ,常用的选择如下:
,也就是衡量损失的部分。
xgb.train()的参数obj默认选择时binary:logistic ,常用的选择如下:

且在
xgboost
中,允许自定义损失函数,但通常我们还是使用已经为我们设置好的损失函数。
















 2843
2843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











