






关键字: [reInforce, Amazon Bedrock, Persona-Based Access Control, Enterprise Data Access, Retrieval Augmented Generation, Role-Based Access Filters, Metadata-Based Document Filtering]
本文字数: 1600, 阅读完需: 8 分钟
导读
在本次演讲中,来自Amazon Web Services的高级解决方案架构师Bonnie Sherman和Hardik Vasa探讨了”基于角色的企业数据访问权限管理,用于生成式AI应用程序”。他们阐释了如何利用Amazon Bedrock的知识库功能,为生成式AI应用程序实现基于角色的访问控制。知识库能够从企业数据中构建向量数据库,并根据用户角色应用过滤器,从而限制对相关数据的访问。整个演讲重点阐述了Amazon Bedrock如何为生成式AI应用程序实现安全的数据访问、可扩展性和统一的信息访问,同时保留用户体验。
演讲精华
以下是小编为您整理的本次演讲的精华,共1300字,阅读时间大约是6分钟。
数据摄取工作流程和文本生成工作流程中,来自各种来源的企业数据被转换为数据块,然后发送至嵌入模型。该模型将这些数据块转换为嵌入向量,随后存储于向量数据库或向量存储中。在文本生成工作流程中,用户输入查询,该查询被转换为嵌入向量,并与存储在向量数据库中的嵌入向量进行相似性匹配。最相关的嵌入向量及其对应的数据块被检索出来,并作为上下文输入到大型语言模型中,生成相关的文本输出。
文本生成工作流程始于用户与生成式人工智能应用程序(如聊天机器人)的互动,通过提出自然语言问题。该问题使用相同的嵌入模型转换为嵌入向量。随后,在向量数据库中执行相似性搜索,以识别相关文档。检索到的文档用于增强原始提示,并将此增强提示输入到大型语言模型中,生成应用程序的最终响应。
鉴于管理此过程的复杂性,演讲者介绍了Amazon Bedrock Knowledge Bases,这是一项通过单一API简化整个RAG(Retrieval Augmented Generation,检索增强生成)工作流程的服务。Amazon Bedrock Knowledge Bases自动将用户问题转换为嵌入向量、创建和管理向量数据库以及执行提示增强过程。向量数据库可以使用多种选项实现,包括Amazon OpenSearch Service、Redis、Pinecone、Amazon Aurora PG Vector等,提供了灵活的选择。
为了说明基于角色的访问控制机制,演讲者提出了一个涉及多种数据源的公司场景,例如营销数据(可视为”潜在客户文档”)和财务数据(表示为”利润或利润和损失文档”)。在该组织内,存在不同的角色,每个角色都有不同的访问级别,例如首席财务官(CFO)和首席执行官(CEO)。演讲者强调了一个使用案例,其中CFO与文档交互,询问诸如”给我一份2022年和2023年的利润和损失报告”之类的问题。在这种情况下,CFO的请求将触发RAG工作流程,在向量数据库中搜索并根据检索到的财务文档提供响应,因为CFO的访问级别允许访问此类数据。
然而,如果同一CFO询问与营销相关的数据,如潜在客户生成,系统将阻止访问这些文档,因为CFO的角色不应该访问营销数据。这证明了基于角色的访问控制在限制用户只能查看其授权查看的数据方面的有效性。
实施基于角色的访问控制需要经历几个关键步骤。首先,企业数据和元数据文件被上传。其次,与现有的身份提供商(IdP)如Amazon Cognito或Okta进行集成。第三,用户请求被传递到API层,该层根据用户的访问级别检索相应的过滤器。例如,首席财务官(CFO)的过滤器可能包括”财务信息”和”子公司战略并购”。第四,将过滤器和用户问题发送至Amazon Bedrock知识库。第五,仅对与过滤器和元数据相匹配的文档执行搜索。举例来说,当CFO询问”请提供2022年和2023年的损益报告”,过滤器与财务文档的元数据相匹配,因此能够检索相关信息。但是,如果CFO询问与营销相关的”潜在客户开发”问题,过滤器与元数据不匹配,从而无法访问未经授权的数据。最后,检索相关文档并发送给大型语言模型以生成响应。
这种方法确保用户只能根据其被授权查看的数据访问和接收响应,这由其角色和访问级别决定。
为进一步阐明实施策略,演讲者概述了三种架构模式:
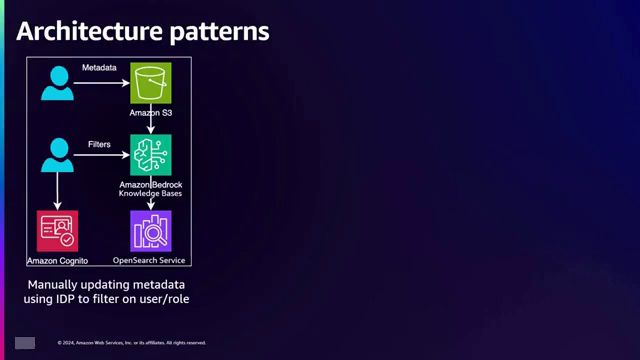
- 手动元数据更新:在此模式下,元数据文件与包含企业数据的S3对象一起手动更新。根据用户角色添加用户过滤器,知识库将文档和元数据传播到向量存储。然后,带有过滤器的用户提示映射到元数据以进行访问控制。
- 默认知识库功能:Amazon Bedrock知识库自动将S3前缀作为默认元数据进行传播。在此模式下,文档存储在特定用户的S3前缀中,用户过滤器映射到这些前缀以进行访问控制。
- 外部身份提供商:此模式适用于使用Microsoft Active Directory、Azure Active Directory或Okta等外部身份提供商的组织。元数据使用S3访问授权进行传播,用户过滤器使用从这些访问授权获得的临时凭证添加。然后,过滤器映射到元数据以进行访问控制。
为了演示基于角色的访问控制在实际应用中的运作,演讲者展示了一个使用Streamlit Python框架构建的示范应用程序。该应用程序模拟了不同的角色,如首席信息官和营销经理,并允许用户提交提示。根据所选角色及其相关过滤器,应用程序从矢量存储(Amazon OpenSearch Service)中检索相关文档,并相应地生成响应。演示阐明了具有不同访问级别的用户只能根据其所属角色的授权,通过应用的过滤器访问和接收相应的数据响应。
在演示中,演讲者展示了一个用例,其中选择了首席信息官的角色,应用的过滤器包括”功能信息”和”子功能战略并购”。当提交一个询问公司在并购方面采取的方法的提示时,应用程序成功地根据检索到的文档提供了响应,因为首席信息官的访问级别允许访问此类数据。
然而,当同一首席信息官角色询问关于潜在客户获取的问题时,一个与营销相关的查询,应用程序没有提供响应,因为过滤器与营销文档的元数据不匹配,从而阻止了对未经授权数据的访问。
为进一步说明基于角色的访问控制,演讲者将角色更改为营销经理,过滤器为”重点潜在客户”。当提交一个询问潜在客户获取策略的提示时,应用程序成功地检索并根据营销文档提供了响应,因为营销经理的访问级别允许访问此类数据。
最后,演讲者提供了宝贵的进一步学习和实施资源,包括一个亚马逊云科技博客、一个自学工作坊和全面的文档。他们的演讲提供了一个综合解决方案,解决了生成式人工智能应用程序中的数据访问挑战,利用Amazon Bedrock Knowledge Bases和基于角色的访问控制,确保对企业数据的安全和受控访问,同时保留了用户体验。
下面是一些演讲现场的精彩瞬间:
邦妮·舍曼与哈迪克·瓦萨是亚马逊云科技公司的高级解决方案架构师,他们将向我们介绍如何在企业数据的生成式人工智能应用程序中实现基于个性化的访问控制。

在生成式AI应用程序中,需要解决数据访问的常见挑战,例如健壮的身份验证机制、控制用户数据访问权限、系统可扩展性、统一信息访问以及无缝集成现有用户体验。

亚马逊Bedrock知识库为用户提供了一个统一的API,并创建了端到端的RAG工作流程。
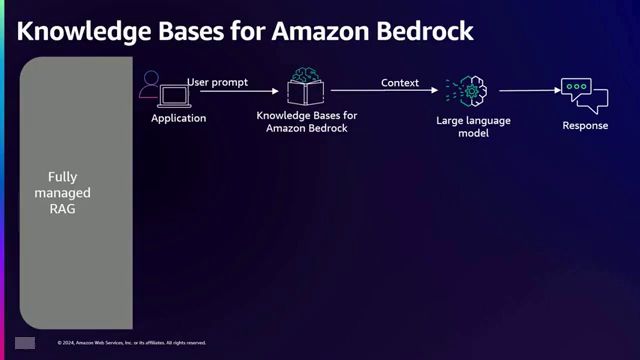
在幕后,它仍在使用将创建并搜索的向量数据库。
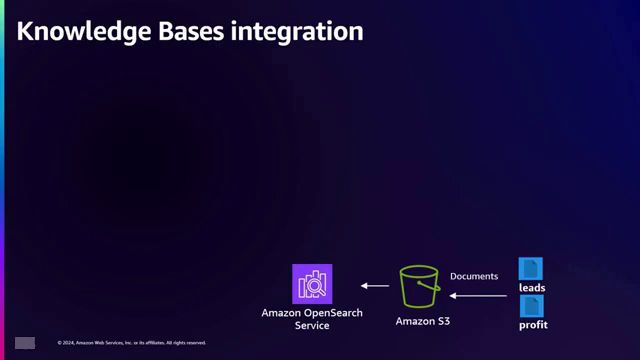
公司的知识库集成了应用程序,CFO可以通过聊天机器人查询2022年和2023年的利润和损失报告。
总结
- RAG通过从企业数据源获取相关数据,增强了语言模型的提示,从而实现了上下文感知和准确响应。
- Amazon Bedrock的知识库简化了RAG的实现,提供了统一的API,用于数据引入、向量数据库创建和文本生成工作流程。
- 基于角色的访问控制是通过将元数据文件与企业数据相集成、将用户角色映射到过滤器,并基于这些过滤器限制向量数据库内的搜索范围来实现的。
总的来说,该演讲强调了在生成式人工智能应用中实施健全的数据治理和访问控制的重要性,同时展示了Amazon Bedrock知识库和RAG架构如何有效解决这些挑战,为不同用户角色提供安全和个性化的体验。















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









