






利用S3 Glacier存储类别最大化冷数据的价值
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, Amazon S3 Glacier, Cold Data Storage, S3 Glacier, Lifecycle Transitions, Object Size Optimization, Intelligent Tiering]
导读
世界上大部分数据都是冷数据,但通过先进的分析技术和机器学习需求的增加,这些数据随时可能被利用起来。在本次讨论中,了解如何使用Amazon S3 Glacier存储类别来现代化您的数据归档,并存储长期数据,而无需担心昂贵的磁带驱动器或场外归档数据。探索以PB级规模摄取和恢复数据的选项,同时考虑成本和检索性能。
演讲精华
以下是小编为您整理的本次演讲的精华。
在引人入胜的亚马逊云科技 re:Invent 2024大会上,Gala Beasley和Andrew Pole深入探讨了冷数据领域,并揭示了利用S3 Glacier存储类别的策略,在最大化价值的同时最小化成本。他们富有洞察力的演讲阐明了冷数据的重要性,根据IDC的估计,冷数据占全球数据的70%到80%,通常处于闲置和很少被访问的状态。
Andrew Pole将冷数据定义为每季度访问不到一次的数据,其访问频率通常会随着时间的推移而降低。然而,企业认识到这些数据未来的潜在价值,尤其是在新兴的人工智能/机器学习应用领域,历史数据可以被利用来发掘新的见解和机遇。演讲者强调了存储冷数据的三个主要用例:保存,包括媒体文件、数据湖中的历史数据或任何可能具有未来价值但需要随着数据量增长而优化成本的数据;备份,客户希望不会恢复数据,但必须确保在需要时可以在所需的恢复时间目标内检索数据;以及合规性,数据必须保留5到10年甚至更长时间,以满足政府或自我规定的保留要求,需要低存储成本才能使长期保留成为可能。
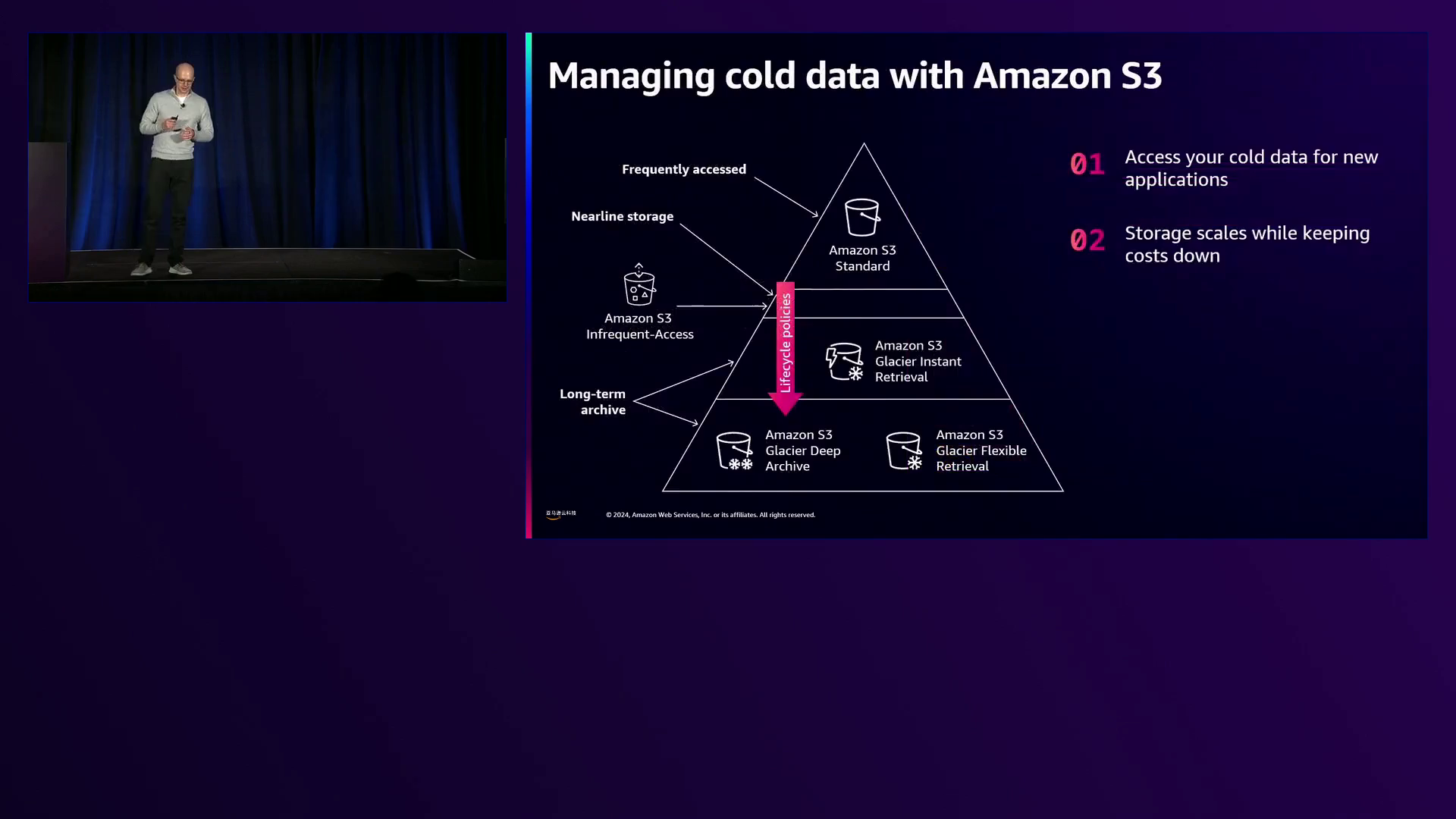
亚马逊S3提供了一系列区域存储类别,旨在帮助客户在数据变冷时降低成本。从经常访问的S3 Standard到高性价比的S3 Glacier Deep Archive,这些存储类别使客户能够在访问频率降低时将数据过渡到更冷的层,以较高的访问成本换取较低的存储成本。Andrew Pole深入探讨了Glacier存储类别,强调了它们的独特特征和理想用例。Glacier Instant Retrieval具有即时访问(毫秒级)和降低的存储成本,非常适合医疗影像或用户生成内容等场景,在这些场景中,低访问频率和成本优化是重点。Glacier Flexible Retrieval比Instant Retrieval的存储成本更低,在需要在几分钟到几小时内检索大量数据的用例中表现出色,利用免费的批量检索选项,使其对人工智能/机器学习应用程序具有成本效益。最后,Glacier Deep Archive提供最低的存储成本,大约每TB 1美元,专为合规性等长期保留用例而设计,在这些用例中,数据很少被访问,最小化存储成本是最重要的。
要将数据过渡到这些存储类别,可以使用S3 Lifecycle策略。Andrew Pole提供了一个实际示例,其中一个对象在第0天创建,90天后,如果访问模式降低到每月低于5%,则可以使用生命周期策略将该对象过渡到Glacier Instant Retrieval。再过90天(总共180天),如果不再需要毫秒级访问,则可以将该对象进一步过渡到Glacier Deep Archive,以实现更大的存储成本节省。生命周期策略支持各种过滤器,如存储桶前缀、对象标签、对象大小和保留的版本数量。Andrew Pole强调了对象大小的重要性,因为较大的对象在过渡到更冷的存储类别时会更快达到收支平衡(开始节省资金)。他还提到,亚马逊最近将默认行为更改为防止小于128千字节的对象过渡,因为客户希望更快达到收支平衡,但如果需要,客户仍然可以使用对象大小过滤器覆盖此默认设置。
为了说明这些策略在现实世界中的影响,Andrew Pole分享了Canva的例子,这是一个拥有超过1亿活跃用户的数字设计平台。Canva通过将大于400千字节的数据过渡到Glacier Instant Retrieval来优化存储,在6个月内实现收支平衡。他们还将日志和备份移至Glacier Flexible Retrieval,每月节省了300万美元的惊人费用。另一个案例是NASCAR,一家股车赛车公司,他们发现在比赛后的第二天,他们就可以将原始镜头直接移至Glacier Instant Retrieval,从而节省大量成本。
对于不确定访问模式的客户,Andrew Pole介绍了Intelligent Tiering,这是一种自动化存储类别,可在数据变冷时将其过渡到更低成本的层。在90天内没有访问后,对象会移至Archive Instant Access层(等同于Glacier Instant Retrieval定价),客户可以选择进一步过渡到Archive Access和Deep Archive Access层,类似于Glacier Deep Archive,而无需支付过渡成本。然而,Andrew Pole承认在某些情况下Intelligent Tiering可能不是最佳选择,例如当访问模式预先已知时,就像NASCAR的情况一样,数据可以在第2天直接移至Glacier Instant Retrieval。此外,对于对性能敏感的应用程序,Intelligent Tiering略低的可用性设计(99.9%与S3 Standard的99.99%)可能是一个考虑因素。
接下来,Gala Beasley上台讨论从Glacier存储类别恢复数据,强调了恢复冷数据的常见原因,如访问存档内容、满足合规性要求或构建机器学习平台。对于Glacier Instant Retrieval,可以使用与S3 Standard相同的GET API调用来访问数据。但是,对于Glacier Flexible Retrieval和Deep Archive,客户必须提交恢复请求,并考虑时间和成本之间的权衡。
Gala Beasley概述了从Glacier Flexible Retrieval和Deep Archive恢复数据的三个步骤。首先,启动恢复,客户根据时间和成本要求确定最佳恢复类型(批量、标准或加急),估计启动所有请求所需的时间,并决定在S3 Standard中保留临时副本的天数。对于Glacier Deep Archive,标准恢复大约需要12小时,而批量恢复大约需要48小时。其次,检查完成情况,客户可以使用S3控制台、HEAD Object命令、List API或事件通知(例如S3事件通知)来监控恢复进度。第三,访问已恢复的数据,一旦恢复到S3 Standard,就可以像访问任何其他S3对象一样访问数据,但客户必须记住这只是一个临时副本。
Gala Beasley强调了批量检索的节省成本优势,批量检索是免费的,但Glacier Flexible Retrieval需要5到12小时,Glacier Deep Archive需要48小时。她还讨论了批量操作,可以最大化恢复请求速率(最高每秒1000次事务或约每天8600万个请求),并自动重试失败的请求,提供完成报告。对于拥有数百万个请求的客户来说,批量操作可能特别有用,正如Gala Beasley分享的一个客户的例子,该客户以每秒25次事务的速率发出请求,与使用批量操作相比,他们的恢复时间增加了40倍。
为了说明批量操作的好处,Gala Beasley分享了Deluxe的例子,这是一家为创作者处理内容的媒体公司。通过切换到批量操作工作流程,Deluxe简化了他们的微服务、降低了成本,并将恢复速度从几小时提高到几分钟,如图表所示,之前的版本需要大约3小时才能开始处理数据,而批量操作使数据处理可以在20分钟内开始。
总之,本次富有洞见的会议的关键要点是:利用亚马逊S3 Glacier以低成本保存资产;根据访问要求和成本考虑选择合适的存储类别;探索从冷数据中产生价值的方式,如人工智能/机器学习应用程序;以及使用批量操作优化大规模恢复,提高效率并节省成本。
通过利用各种S3 Glacier存储类别并遵循数据过渡和恢复的最佳实践,企业可以最大限度地发挥冷数据的价值,同时最小化存储成本并确保在需要时可以访问数据。演讲者的专业知识和现实世界案例,包括数据点、数字、比例和比率表达式以及客户用例,为冷数据管理的复杂性提供了全面的指导,使与会者能够做出明智的决策并充分发挥数据资产的潜力。
下面是一些演讲现场的精彩瞬间:
Gala Beasley是亚马逊S3 Glacier的高级技术项目经理,Andrew Pole是S3的主要产品经理。

他们介绍了冷数据的主题。

随着企业的发展,越来越多的数据变成了冷数据,访问频率降低,但它们对未来的人工智能/机器学习应用程序来说,价值却越来越高,这是一个令人兴奋的时期,可以研究冷数据解决方案。

一家公司通过使用亚马逊S3 Glacier优化其数据存储,每月节省了300万美元,同时保持了对其数据的必要访问。
NASCAR通过在比赛日的第二天将原始视频移至亚马逊S3 Glacier Instant Retrieval,利用了亚马逊S3的数据生命周期功能,从而节省了费用。

强调了即时检索对用户生成内容(如宠物照片和视频)的好处,确保快速访问并降低存储成本。

总结
在这场引人入胜的演讲中,演讲者深入探讨了使用亚马逊S3 Glacier进行冷数据存储的策略,揭示了如何最大限度地发挥其价值。他们首先将冷数据定义为不经常访问但未来可能会在人工智能/机器学习应用中使用的数据。演讲者强调了冷数据的三个主要使用案例:保存、备份和合规性,并着重强调了具有成本效益的存储解决方案的重要性。
随后,演讲者介绍了S3 Glacier的存储类别,每一种都针对特定的检索需求和成本考虑因素进行了量身定制。Glacier Instant Retrieval提供毫秒级访问,适用于医疗影像等数据;而Glacier Flexible Retrieval和Glacier Deep Archive则以较长的检索时间为代价提供更低的存储成本,非常适合备份和长期保留。他们强调了对象大小在确定成本效益方面的重要性,较大的对象在过渡到更冷的存储类别时更快达到成本均衡。
为了优化成本,演讲者建议利用S3 Lifecycle策略或Intelligent Tiering,根据访问模式自动将数据过渡到更冷的层。他们还强调了大规模从Glacier恢复数据时进行批量操作的重要性,使客户能够简化工作流程并降低成本。
最后,演讲者鼓励与会者探索冷数据的价值,强调通过人工智能/机器学习分析可能产生新的见解和应用。他们敦促与会者选择合适的存储类别、优化大规模恢复,并发掘冷数据资产中隐藏的价值。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









