









创建时间:2024-02-11
最后编辑时间:2024-02-12
作者:Geeker_LStar
你好呀~这里是 Geeker_LStar 的人工智能学习专栏,很高兴遇见你~
我是 Geeker_LStar,一名初三学生,热爱计算机和数学,我们一起加油~! ⭐(●’◡’●) ⭐ 那就让我们开始吧!
前两篇在讲模型评价标准 & 交叉验证,没讲算法,这一篇我们来讲一个新的算法——KNN(K 近邻)算法。
KNN 被称为 “最简单的分类算法”,理论方面没有太多需要讲的,so 这一篇会把理论 & 例子都讲完!
一、理论
KNN 算法,中文 K 近邻算法,大致思路就是:对于一个待分类的样本,看看和它距离最近的 K 个样本都属于什么分类,这 K 个样本中出现最多的分类就是这个待分类样本最可能的分类。
这涉及到两个问题:
- 距离怎么计算
- K 值怎么选取
距离的计算
先来看第一个。
因为对于带有标签的数据来说,在被送到模型去训练以前,所有的标签都已经被转化成数字(n 维向量,n 个数字)的形式了,这大大方便了距离的计算。
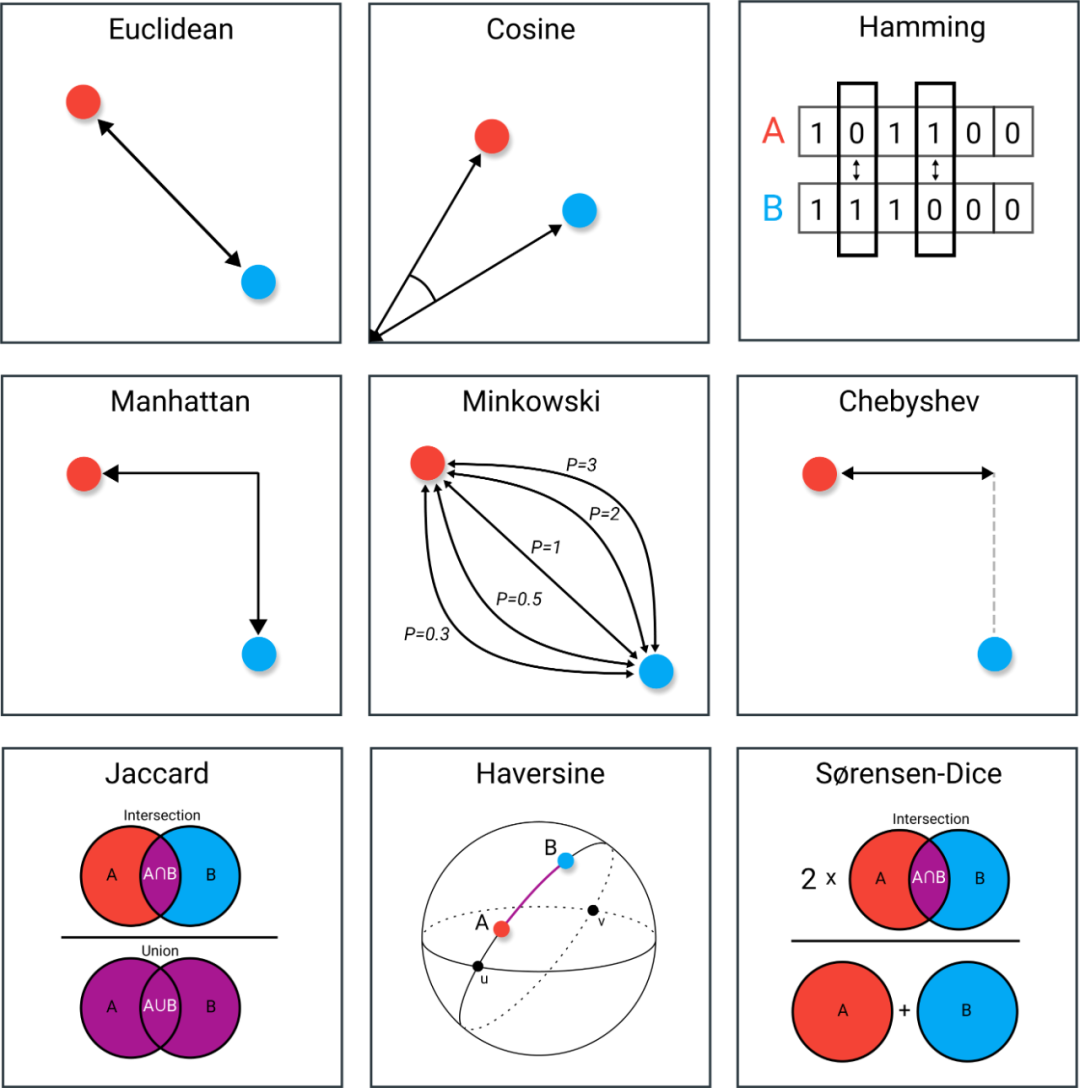
一般而言,计算距离的方式主要有以下几种:
- 欧式距离
- 余弦距离
- 曼哈顿距离
- 切比雪夫距离
- 闵可夫斯基距离
欧氏距离
欧式距离即欧几里得距离,二维空间中的形式你肯定见过,就是两点之间距离公式嘛。
二维:
d
=
(
x
1
−
x
2
)
2
+
(
y
1
−
y
2
)
2
d = \sqrt{(x_{1}-x_{2})^{2}+(y_{1}-y_{2})^{2}}
d=(x1−x2)2+(y1−y2)2
ok 推广到 n 维,用
Σ
\Sigma
Σ 变形一下:
d
=
∑
k
=
1
n
(
x
1
k
−
x
2
k
)
2
d = \sqrt{\sum_{k=1}^{n}(x_{1k}-x_{2k})^2}
d=k=1∑n(x1k−x2k)2
ok 很简单的一种距离公式,不过它的使用(牵扯到 knn 的使用)受到维数限制,当维度过高(有说法说超过 10 维)时,欧氏距离算出的最大值和最小值会无限接近,导致这种方法失效,这种情况也被称作 “维数灾难”。
不过先别担心,有降维算法比如 PCA 可以帮助我们,不过那就是后话了。
余弦距离
嗯作为假期刚学完必修二向量的我,这题我来()
必修二课本告诉我们,向量的数量积
A
⋅
B
=
∣
A
∣
×
∣
B
∣
×
c
o
s
θ
A · B = |A|×|B|×cos\theta
A⋅B=∣A∣×∣B∣×cosθ
那么
c
o
s
θ
=
A
⋅
B
∣
A
∣
∣
B
∣
cos\theta = \frac{A·B}{|A||B|}
cosθ=∣A∣∣B∣A⋅B,化成坐标表示就是:
c
o
s
θ
=
x
1
x
2
+
y
1
y
2
x
1
2
+
y
1
2
+
x
2
2
+
y
2
2
cos \theta = \frac{x_{1}x_{2}+y_{1}y_{2}}{\sqrt{x_{1}^{2}+y_{1}^{2}}+\sqrt{x_{2}^{2}+y_{2}^{2}}}
cosθ=x12+y12+x22+y22x1x2+y1y2
c
o
s
θ
cos\theta
cosθ 的取值范围在
[
−
1
,
1
]
[-1, 1]
[−1,1] 之间。当两个向量方向相同时,
c
o
s
θ
cos \theta
cosθ 取到最大值 1,两个向量方向相反时,
c
o
s
θ
cos \theta
cosθ 取到最小值 -1。
为了符合人们 “数字大距离远” 的习惯,常常会用
1
−
c
o
s
θ
1-cos \theta
1−cosθ 表示余弦距离,
1
−
c
o
s
θ
1-cos \theta
1−cosθ 的取值在
[
0
,
2
]
[0, 2]
[0,2] 之间,数字越大表示两个向量的方向越不相似。
不过,余弦距离也有局限性,它只关注向量之间的夹角,而忽略了向量模长的影响。在一些分类任务中,可能两个向量方向相同,但它们的模长相距比较远,并不是同一类的。此时如果使用余弦距离作为分类依据,准确率会较低。
同时,余弦距离和欧氏距离一样,也会受到 “维数灾难” 的影响。
曼哈顿距离
曼哈顿距离也好理解,比如平面上有两个点 ( x 1 , y 1 ) , ( x 2 , y 2 ) (x_{1}, y_{1}), (x_{2}, y_{2}) (x1,y1),(x2,y2),它们之间的距离就是它们横坐标的差的绝对值与纵坐标差的绝对值的和,类似于直角三角形两条直角边的长度之和,即: d = ∣ x 1 − x 2 ∣ + ∣ x 2 − y 2 ∣ d = |x_{1}-x_{2}|+|x_{2}-y_{2}| d=∣x1−x2∣+∣x2−y2∣。
推广到 n 维空间,用
Σ
\Sigma
Σ 表示,有:
d
=
∑
k
=
1
n
∣
x
1
k
−
x
2
k
∣
d = \sum_{k = 1}^{n}|x_{1k}-x_{2k}|
d=k=1∑n∣x1k−x2k∣
曼哈顿距离的使用场景有限,knn 不怎么用它。
切比雪夫距离
emmm 这名字怎么越来越长了()不过没事,它也很简单。
切比雪夫距离是指两个点的各组坐标(x、y、z 等)的差值的绝对值的最大值,别看定语这么多,其实在二维空间中就是
d
=
m
a
x
(
∣
x
1
−
x
2
∣
,
∣
y
1
−
y
2
∣
)
d = max(|x_{1}-x_{2}|, |y_{1}-y_{2}|)
d=max(∣x1−x2∣,∣y1−y2∣),也就是说 x 坐标差得远就选 x 坐标的差值,y 坐标差得远就选 y 坐标的差值。推广到 n 维就是:
d
=
m
a
x
(
∣
x
1
i
−
x
2
i
∣
)
,
i
∈
[
1
,
n
]
d = max(|x_{1i}-x_{2i}|), i ∈[1, n]
d=max(∣x1i−x2i∣),i∈[1,n]
切比雪夫距离的使用场景有限,常用在聚类算法中,knn 不怎么用它。
不知道你发现没有,其实切比雪夫、曼哈顿、欧式之间很暧昧()它们之间的关系怎么用数学表示呢?
闵可夫斯基距离
没错!(接上问)闵可夫斯基距离就是专门干这个的,换言之,闵可夫斯基距离不是某一种距离,而是一组距离的汇总。
在 n 维空间中,闵氏距离的公式是:
d
=
∑
k
=
1
n
∣
x
1
k
−
x
2
k
∣
p
p
d = \sqrt[p]{\sum_{k=1}^{n}|x_{1k}-x_{2k}|^p}
d=pk=1∑n∣x1k−x2k∣p
有了前面欧式、曼哈顿和切比雪夫距离的铺垫,这个公式应该不难理解,同时不难发现:
- p = 1 时,闵氏距离就是曼哈顿距离
- p = 2 时,闵氏距离就是欧氏距离
- p -> +∞ 时,闵氏就是切比雪夫距离(好吧这个挺难发现的,不过可以用放缩法证明)
这是在 p 取不同值的时候,等距离的点组成的图像,还是蛮形象的。

讲一下闵氏距离的局限性吧,因为它是其它三个的汇总,所以它的局限性也能反映其它三个的局限性。
来看一个例子,现在有三个人的身高体重数据,A(160, 50),B(170, 50),C(160, 60),不管用闵氏三种(欧式、曼哈顿、切比雪夫)中的哪一种,AB 的距离都等于 AC 的距离,等于 10. 但是身高 10cm 和体重 10kg 的含义并不一样,这反映出闵氏距离:
- 忽略了不同分量的量纲(单位)不同
- 忽略了不同分量的分布特征(方差等)
- 各个维度必须是相互独立的,表现在几何上就是 “正交” 的
emm 跑题有点远了()距离这块就先到这吧。重点还在 knn 呢。
ok,这些就是各种度量距离的方法,没有讲全,我考虑开一篇单独的博客专门讲这些。最后,寄出神图:
真的这图实在是太形象了()要不是这篇讲 knn,我绝对把它当封面图。
K 值的选取
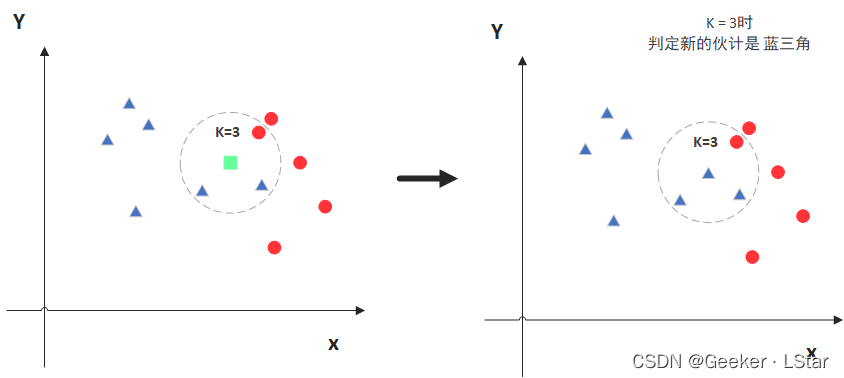
ok,讲完怎么计算距离,K 值的选取也是个重要的话题,我们先来看看不同的 K 值会带来怎样的效果。
比如,下边这个绿色方块是要被分类的对象,K 等于 3 时,它的 3 个邻居有 2 个是蓝色三角,所以它也被分为蓝色三角。
但是 K = 5 时,情况发生了变化,它的 5 个邻居中有 3 个是红色圆,于是它也被分到红色圆圈了。
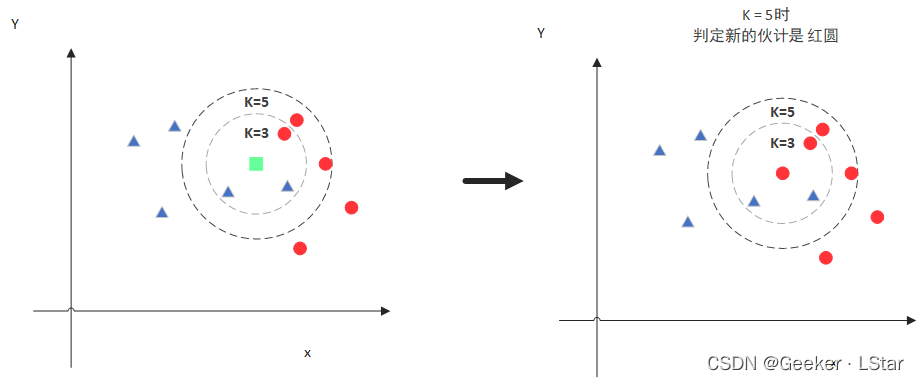
由此可见,K 值的选取很重要,K 选的太小容易过拟合,太大又容易欠拟合(如果一共就 35 个数据,K 取到 30,那 KNN 基本就没啥用了emm)。
k 值的选取一般可以采用 k 折交叉验证法(两个 k 不一样,不要混淆),大致思路是:换用不同的 k 值,采用 k 折交叉验证法看哪种 k 值下模型的平均准确率最高(或用其它评价标准下的平均性能最好),就选用这个 k 值。
关于交叉验证,详细地可以看我上一篇文章:【初中生讲机器学习】7. 交叉验证是什么?有哪些?怎么实现?来看!
如果实在选不好 k 值也可以使用默认值,sklearn 中的默认值是 5.
二、代码实现
手搓算法原理
嗯嗯嗯嗯。。。觉得 KNN 不难于是手搓了一个函数(暴力)模拟了一下它,计算用的是欧氏距离(yes sklearn 用的也是欧式)。
ok 先别笑我(()暴力甚至是 sklearn 中 knn 函数的方法之一,不过也有别的,后面讲。
# 自己实现 knn 算法代码
# 导入库 & 预处理
from sklearn.datasets import load_iris # 引入鸢尾花数据集,共 150 组数据
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=3, test_size=0.3)
# x:样本特征
# y:分类结果
# x_test:测试集样本特征
# k:k 值(选取最近的 k 个样本点),默认为 5
def knn(x, y, x_test, k=5):
y_predict = []
for sample_test in x_test: # 取出测试集中每一个样本(n 维向量)
distance = [] # 储存测试集中的一个样本和训练集中所有样本的欧氏距离
for sample in x: # 训练集中每一个样本(n 维向量)
d = 0 # 临时储存距离的变量
index_list = [] # 存储 k 个距离最小的元素的索引,方便看它们的分类结果
for n in range(0, len(sample_test)): # 每一个向量(一共 n 个)
d += abs(sample_test[n]**2 - sample[n]**2) # 欧氏距离
distance.append(d)
classification_list = []
for i in range(0, k): # 选取 k 个距离最小的元素
index = distance.index(min(distance))
classification_list.append(y[index]) # 记录这些元素的分类情况
distance[distance.index(min(distance))] = float('inf') # 设置为无穷大
# k 个邻居的分类中出现最多的一个记作新元素的分类
classification = max(set(classification_list), key=classification_list.count)
y_predict.append(classification)
return y_predict
y_predict = knn(X_train, y_train, X_test, 3)
print("准确率:", accuracy_score(y_test, y_predict))
准确率其实还可以嘿嘿嘿,93%.

sklearn 实例
下面我们用 sklearn 中封装好的算法来实现同样的实例。
看一下这行代码:
knn = KNeighborsClassifier(n_neighbors=5, algorithm='auto')
n_neighbors = 5 表示选择最近的 5 个邻居。
algorithm 值得好好讲一下,你也看到了,手搓部分我是怎么实现 knn 的——纯暴力。虽然暴力比较也是 KNeighborsClassifier() 的一种实现方式,但是暴力比较会在数据维度升高和数据量增大的时候迅速暴露出弊端,so 除了暴力,sklearn 中的 KNeighborsClassifier() 额外提供了两种算法——kd 树和球树。
至于在使用的时候到底选择哪种算法,可以自己设定,如果不好评估,设置为 auto,knn 会自己决定。
代码如下,详细的每一步的分析已经在第四篇(SVM 实例)中讲过了,这里不再重复。
# 利用 KNN 算法实现鸢尾花分类
# 导入数据集+函数
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
# 加载并预处理数据
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=3, test_size=0.3)
# 训练
knn = KNeighborsClassifier(n_neighbors=5, algorithm='auto')
knn.fit(X_train, y_train)
# 测试
y_predict = knn.predict(X_test)
print("准确率:", accuracy_score(y_test, y_predict))
这个其实和手搓版没有任何区别,只是我把 k 从 3 改到 5 了,准确率上升了一点。

ok~以上就是关于 KNN 算法的内容啦!这个算法比较简单,很好理解~
这篇文章讲了一些距离度量方式 and KNN 算法的原理及实现,希望对你有所帮助!⭐
欢迎三连!!一起加油!🎇
——Geeker_LStar














 6538
6538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









