







文章目录
Introduction
现有coordinate service的缺陷:
- 不同的分布式应用有不同的协调需求,如队列协调需求,选举需求,配置更改需求等,每个coordinate service只适用于解决一种协调需求。
- 大量的使用锁机制,导致系统性能的整体下降。
ZooKeeper优点:
- 提供了API接口,可以通过API实现各种协调服务,其核心为coordination kernel
- 去除了锁机制,使用wait-free数据
- 通过保证FIFO client oerdering of all operations和linearizable writes就足够满足各种不同的协调需求
- 基于副本机制的高可用性和性能
The ZooKeeper Service
Service Overview
ZooKeeper中的数据以znode的形式存放在内存中,并根据命名空间来将其组组织为树的形式(类似于文件系统的组织方式)。
client可以向ZooKeeper server创建两种类型的znode:
- Regular:client通过显式的创建和删除操作来管理regular znodes。
- Ephemeral:client创建该类型的znodes后,要么由client自己显式的删除它们,要么由ZooKeeper在创建该znodes的session终止后自动销毁它们。
ZooKeeper中,Regular znodes可以包含子节点,但是Ephemeral znodes不能包含子节点。 client在创建znode时,可以设置sequential标志位,设置该标志位的znode会在其名字后面加上一个自动增加的计数值(p_1, p_2,p_3)。
ZooKeeper实现了watches功能来通知client数据发生了改变,从而避免client需要一直进行轮询。 当client在处理读操作时设置了watch标志位时,如果在读操作完成后数据发生了改变或session断开,ZooKeeper会通知client之前读取的信息现在已经改变了。watches机制是一次性触发器,触发一次后就会失效。 例如,客户端发起getData(’’\foo’’, true)请求,在获取到数据后,’’\foo’'znodes中的数据发生了两次改变,ZooKeeper只会向client发送一次watch event。如果是读取数据后session断开,ZooKeeper也会发送watch event。
Data Model
ZooKeeper的数据模型组织本质上就是Unix文件系统+API。 这种组织方式的好处是可以轻松的管理不同应用下的所有数据,可以方便的对某一个应用下的所有子数据设置访问权限。不同于传统的文件系统,znodes并不是用来存储传统数据的,而是用来管理不同的client applications。 如下图所示,子树/app1和子树/app2代表client application1和client application2,/app1下的每个节点/app1/p_i代表application1中的第i个client process。
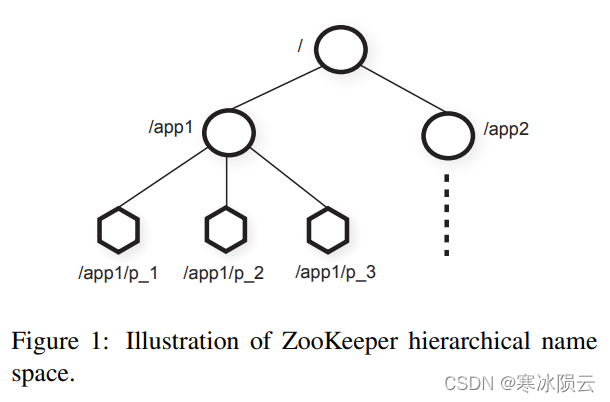
虽然znodes的设计初衷并不是用来存储数据的,但是ZooKeeper允许clinets存储一些用于分布计算的metadata和configurations,znodes节点本身通常也存储了timestamps和version counters用于client跟踪其状态。
Sessions
每当client与ZooKeeper服务相连时就会创建一个session。 session包含timeout时间,当ZooKeeper在timeout时间内没有收到client的消息就会认为client出现故障。
Client API
client可以通过以下API接口与ZooKeeper进行交互.


所有API接口都有同步和异步两个实现版本。 可以发现,ZooKeeper并不适用handler来访问znodes,而是根据API中传入的full path来访问,这样做不仅简化了API(无需open(),close()方法),而且节省了ZooKeeper server需要管理handler的额外内存开销。
ZooKeeper Guarantees
ZooKeeper对指令的执行顺序有两个基本保证。

ZooKeeper对于单纯的写操作可以保证线性一致性,但是对于读写操作并不能保证,因为对于读操作,ZooKeeper会直接在副本进行处理,可能会读取到过时数据。
对于读操作,ZooKeeper是顺序一致性的,ZooKeeper的FIFO Order保证了同一个client内所有的操作是线性一致性的,ZooKeeper的Linearizable Writes保证了写操作的全局可见性。

顺序一致性的理解很简单,具体可以如上图所示。顺序一致性模型中虽然整体执行顺序是无序的,但所有线程都只能看到一个一致的整体执行顺序,且每个线程内部的执行顺序保持不变。以上图为例,线程 A 和 B 看到的执行顺序都是:B1->A1->A2->B2->A3->B3,且每个线程内部操作的执行顺序不变。
Examples of primitives
文中列举出了几个可以使用ZooKeeper实现的常见协调服务:
- Configuration Management
- Rendezvous
- Group Membership
- Simple Locks
- Simple Locks without Herd Effect
- Read/Write Locks
- Double Barrier
具体请见详细论文。
ZooKeeper Implementation
ZooKeeper service的基本架构如下图所示。
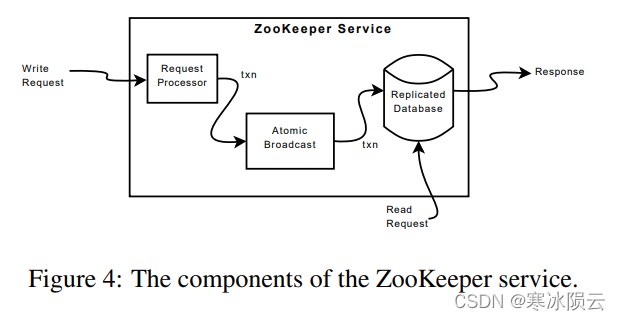
对于write request,Request Processor首先对request进行预处理并做好执行准备,接着由Atomic Broadcast协调不同servers的写操作,最后将结果提交到Replicated Database中。对于read request,ZooKeeper直接从Replicated Database中读取数据。Replicated Database通常以树的形式存放在内存中,树中的每个znode默认最多存储1MB的数据(可以更改),为了提升系统的可恢复性,数据通常会被在写入Database前持久化的写入硬盘中。
每个ZooKeeper server可以为多个clients提供服务,client与server建立连接并提交request。在处理write request时,需要使用一致性协议来协调不同server,其中直接处理write request的server称为leader,剩下的ZooKeeper servers称为followers。
Request Processor
当leader收到write request时,它会计算该write request生效后系统的状态并将其转化为事务,因为事务具有幂等性。 在转化为事务时,request processor必须要计算request生效后的状态,因为可能有未完成的事务还未更新到database中,此时如果从database中拿取数据会导致错误。例如,当client发送setData request时,processor会计算new data,new version number和time stamps并保存在事务setDataTXN中。
Atomic Broadcast
在ZooKeeper service中,由leader来执行request并向所有serves通过Zab
来广播其状态变化。为了达到高吞吐量,ZooKeeper中的request processing过程都是基于流水线设计的,流水线中的每个部件同时处理上千个request。 由于ZooKeeper中处理当前request后的状态变化会依赖于之前的状态,因此Zab保证broadcast的发送顺序与状态变化顺序一致且在new leader发送broadcast前会继承所有previous leader的状态更改。
为了保证boradcast的发送顺序,ZooKeeper使用TCP连接进行网络通信。
Replicated Database
每个replica都在内存中存有ZooKeeper的状态,当有server宕机时,就可以根据replica中保存的状态进行恢复。为了进行快速启动,ZooKeeper会定期的生成fuzzy snapshot, 之所以称为fuzzy snapshot时因为ZooKeeper在生成snapshot时不会锁住当前的系统状态,而是直接对data tree进行depth first scan并记录每个znode的数据。 这种方式可能会导致snapshot记录的状态是不完整的,但是ZooKeeper事务的幂等性保证了可以通过重复执行request来解决该问题。
例如,有以下事务待应用到database中。
<SetDataTXN, /foo, f2, 2>
<SetDataTXN, /goo, g2, 2>
<SetDataTXN, /foo, f3, 3>
初始时,/foo和/goo的value和version number分别为f1,g2和1,1。如果在执行的过程中建立snapshot,snapshot的结果可能为</foo, f3, 3></goo,g1,1>。在快速恢复后,我们只需要再执行一次事务序列即可。
Client-Server Interactions
当ZooKeeper处理write request时,会将write request相关的所有watch notifications进行发送。Servers会按序处理write request,并且不会并发的处理其它read request或write request。server仅在本地处理notification,只有跟client相连的server才负责跟踪和处理notification。
server在本地独立处理read request。 每个read reqeust都会被打上zxid标记,zxid对应server看到的最后一个事务,定义了read request相对于write request的偏序。本地处理read request可以获得极高的性能,可以直接在本地内存中读取数据。
这种本地快速读取数据的一个缺点是可能会读取到过时的数据。 在ZooKeeper中,只要集群中的半数servers完成数据更新操作即可视为更新成功,由于read request直接在本地操作,因此可能本地集群还没有进行数据更新。如果需要读取到最新的数据,可以调用sync方法。 FIFO的执行顺序保证了调用sync时的线性一致性,调用sync时,leader会确保read request之前所有的write request都更新到所有的servers时才会返回结果。
ZooKeeper以FIFO的顺序来处理clients request,并会给每个请求分配一个zxid。每个heartbreak message也会包含最近一个request的zxid。当client连接到一个new server时,会检查new server的zxid和client的zxid,为了一致性保证,new server的zxid不能小于client的zxid。
ZooKeeper使用timeout定时器来检测client与server的session故障,如果集群中的任何server都在timeout时间内没收到任何来自client的信息,ZooKeeper会认为session故障。当处于空闲状态时,client会定时向server发送heartbreak message,如果client无法跟当前连接的server进行通信,则会换到新的server上进行连接。















 2884
2884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









