







文章目录
本文主要对raft协议的相关论文进行了总结。
Introduction
目前大多数分布式系统都采用replicated state machines的容错机制,raft协议作为一种共识算法,就是用来保证不同的servers上的replicated log的一致性。

上图描述了共识算法在分布式系统容错机制中的作用。
- client发送多个commands给servers
- server的共识算法模块将多个commands记录在log中,并使log在多个servers上保持一致性
- server按照log的command记录按序执行
- 将结果返回给client
Raft算法的核心是leader,Raft会首先从servers中选出一个leader,该leader具有管理replicated log的所有相关权限。 Raft把共识问题划分为三个子问题:
- Leader election:当前leader故障时如何选出新的leader
- Log replication:lead必须负责添加新的log和将log复制到其他server上
- Safety:当一个server执行了replicated log中index为idx的log时,说明所有servers的replicated log中index为idx的log一样。
Raft Consensus Algorithm
Raft Basics
每个server有三种状态:
- leader:每个term内只有一个
- follower:只会处理来自leader和candidate的请求,如果有client向follower发送请求,follower会将其重定向到leader
- candidate:用于选举新的leader
三种状态的相互转换如下图所示。

Raft把时间划分为不同长度的term,具体如下图所示。
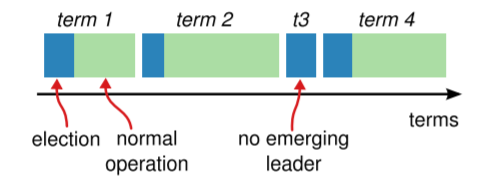
每个term从leader election开始,如果有leader成功选出,则由该leader完成剩下的term。如果在选举时发生分票,则任期会以没有leader而结束,重新开始下一轮term。
不同的servers观察到term变化的时间可能不一样,raft将term看做一种logical clock,来检测过期的leader。每个server都存储了当前的term number,并会单调增长,并在与其他server通信的过程中会进行交换更新。 在通信过程中,term number可能出现以下情况:
- 当前server的term number小于另一个server,则将term number更新到更大的值。
- 如果candidate或者leader发现自己的term number已经过时(小于其他server),则将状态立即退回到follower
- 如果server收到的请求来自过时的term number,则拒绝该请求
Raft server间通过RPC进行通信,其基本类型有三种:
- RequestVote RPCs: 由candidates在leader election期间发起
- AppendEntries RPCs:由leader在进行log备份时发起
- InstallSnapshot RPCs:用于在server间传递snapshot
Raft共识算法的核心是五大性质,通过五大性质来保证一致性。

Leader Election
Raft使用heart break机制(即空的AppendEntries RPCs)来触发leader election过程。 选举过程如下所示:
- servers启动时,默认为follower状态
- 如果follower在election timeout内没有收到leader或candidate的heart break,则follower变为candidate开始leader election过程,开始步骤3。如果收到了heartbreak,则保持follower状态。
- candidate首先增加自己的current term number。
- candidate为自己投票,并向所有其他server发送RequestVote RPCs请求。
- 如果candidate成功当选为leader,开始步骤6。如果收到信息其它server成为了leader,开始步骤7。如果一段时间后没有server成功当选为leader(多个follower同时当选为candidate,导致分票),则重新返回步骤3。
- candidate变为leader状态,并向所有server发送heart break声明自己已成为leader。如果所有server都承认,则结束。如果有server不承认(leader的term过时),则退回到lfollower状态,返回步骤2。
- 如果新leader的term大于等于当前term,则candidate承认新leader存在并退回到follower状态,返回步骤2。否则,candidate拒绝新的leader并维持candidate状态,返回步骤5。
Raft使用随机的election timeout(150ms-300ms)来确保尽量少的发生分票情况,防止多个follower同时变成candidate。每个candidate在开始election前同样会随机化自己的election timeout,如果在这个时间内没有出现leader时,才会重新变为follower,防止分票事件重复出现。
Log Replication
Raft中的log形式如下图所示。

每个log entry中存有command和term number,term number用来维护log之间的一致性。 每个log entry都有一个独一无二的log index标识。
当leader决定了一条log entry可以被执行时,该log entry被称为committed。 Raft保证committed log entries最终会被所有可用的severs所执行。当leader将log entry已经复制到了集群中半数以上的servers上时,该log entry就可以committed,如上图的log entry 7,提交当前的log entry的同时也会将leader log中所有之前未提交过的log entries提交(包括前一个leader的)。leader会将已经提交的最大的log index通过AppendEntries RPCs发送给其他servers,当其他servers收到时,就知道该log已经被leader提交,就会按相同的顺序提交log。
Raft通过两条属性来保证一致性:
- 如果在不同log中的两个log entries有相同的index和term,则它们一定有相同的command
- 如果在不同log中的两个log entries有相同的index和term,则两个log在该index之前的所有内容相同
第一个属性是由leader在任期内只会在指定的log index处创建一个log保证。第二个属性是由AppendEntries RPCs来保证。当leader发送AppendEntries RPCs时,会携带最新log entry的前一个log entry的term和index,如果follower在自己的log中没有找到前一个log entry,则拒绝添加新的log entry。
如果leader在还没有replicated完所有的log就发生故障,可能会出现leader和followers的log不一致的情况,如下图所示。

在Raft中,对于leader和follower的log不一致的情况,会强制将follower的log复制为leader的log。具体的操作如下:
- leader会为每个follower都保存一个nextIndex,记录应该发送给follower的next log entry。
- 当新的leader第一次上线,会将nextIndex初始化为last log index + 1
- 如果follower在nextIndex - 1处与leader的log不相同,则AppendEntries RPC返回fail。如果相同执行步骤5。
- leader将nextIndex = nextIndex - 1,重复步骤3。
- follower将从nextIndex开始的log删除,并替换为leader的log。
Safety
log的一致性并不代表log committed的一致性,假如follower在leader提交logs时故障,如果该follower恢复后被选为新的leader,则会导致丢失部分commited log entries。Raft保证任何一个term内的leader,都包含之前所有已经提交的log entries。
Election Restriction
在选举阶段,为了保证选出的leader至少拥有所有的committed entries,Raft要求投票时candidate不能比任何servers上的log延后。 因为commited log entries至少是半数出现,所以leader log的up-to-date性质保证了其包含所有的committed entries。如果出现延后,则server投反对票。
Raft的up-to-date定义如下:
-如果两个log的last entry处在不同的term,则term大的更新
-如果两个log的term一样,则log更长的更新
Committing Entries From Previous Terms
Raft规定每个leader只能提交当前term内的log entry,不然可能造成log缺失,因为leader并不知道前一term内的log是否提交。
具体的例子如下图所示。

对于Raft来说,如果我们提交的是当前任期的log entry,那么由于replicated log中的一致性保证,所有前一任期的log entry也会被commit。
Follower and Candidate Crashes
在Raft中,如果follower和candidate发生了故障,RPCs会进行不断地重传。如果crashed servers重启,则RPCs会正常地完成通信流程,如果crashed servers在完成RPCs并回复leader前故障,会收到同样的RPCs。
Timing and Availability
Raft不能因为某些时间过于频繁或较少地发生而导致错误地结果,因此对时间地控制很重要。 Raft中的时间需求如下所示。
broadcastTime << electionTimeout << MTBF
其中,broadcastTime是server发送RPC到收到回复的平均时间,electionTimeout为选举的超时时间,MTBF为一台server上发生故障的平均间隔时间。在Raft论文中,broadcastTime一般为0.5ms到20ms,electionTimeout一般为10ms到500ms,MTBF通常为几个月。
Cluster Membership Changes
在Raft运行过程中,我们需要解决集群配置的更改(增加节点或减少节点)带来的split-brain问题,具体实例如下图所示。

如果我们一次将所有集群进行配置更换,由于不同节点启用新配置的时间不同,因此在不同的配置下可能分别产生各自的leader,从而造成split-brain现象。
Raft采用了两阶段更改的方式来解决split-brain现象,Raft提出了一种叫做joint consensus的过渡状态,只有当joint consensus被提交后,集群才能变为新配置,状态的基本内容如下:
- log entries会被复制到新旧配置包含的所有节点上
- 所有配置下的任何节点都有可能成为leader
- 当进行投票表决时,需要 C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1359
1359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









