







文章目录
Introduction
RDD的特性与作用:
- 一种抽象的分布式数据结构,针对中间结算计算结果的存储优化方案。
- 可容错、可并行操作
- 允许用户显式将中间数据保留到内存,控制分区以优化数据布局,使用丰富的操作符操作它们
- 提供粗粒度(作用于整个数据集)的数据转换操作,如map,filter和join
- 通过log record和recompute完成fault tolerance,无需复制大量数据
Resilient Distributed Datasets
RDD Abstraction
RDD是一个只读的、分区的数据记录集合。
RDD只能从以下几种数据中创建:
- 存储在稳定介质中的数据
- 其它RDD
RDD有很强的容错性,它在任何情况下都不需要被物化(存入稳定存储),因为每个RDD都可从衍生的RDD或其持久化的原始数据中恢复。
用户可以控制RDD的操作:
- persistence:用户可以决定那些RDD会被重复使用,并选择其存储策略(如放置在内存中)
- partitioning:可以对RDD进行分区,将其数据分配到不同的节点上
Spark Programming Interface
用户可以通过以下接口来操作RDD:
- 可以通过对存储介质中的数据进行transformation操作新建RDD
- 可通过action(如count, collect, save等)对RDD进行运算得到返回值或导出数据
- 可通过persisit持久化RDD,以供重复使用,默认存入内存
Spark中调用action后不会立即执行操作,而是采取lazy策略,当需要用到执行结果时才会进行RDD计算,这样的好处是可以优化计算路径,具体可以自行查阅Spark lazy evaluation相关内容。
Advantages of the RDD Model

RDD模型相比DSM模型拥有以下优势:
- 尽管RDD只能通过粗粒度进行写操作,但和DSM相比起fault recovery开销更小,因为不需要checkpoint,可以根据lineage来进行恢复
- RDD的不变性可以让速度快的节点运行备份任务从而解决速度慢的节点带来的性能性能问题,DSM很难做到这一点。
- RDD运行时可基于数据局部性调度任务,提高性能
- RAM空间不足时,只被用于scan-operation的RDD会被存储在disk中。
Applications Not Suitable for RDDs
RDD最适合需要对整个数据集进行操作的批处理任务,而对共享状态进行细粒度的异步更新操作,如Web应用存储、Web增量爬虫,不太适合。
Spark Programming Interface
Spark的集群编程模型包含以下部分:
- 用户使用的Driver:
- 连接Worker集群
- 由定义RDD,并在RDD上确定action操作
- 跟踪记录RDD的lineage关系
- 向Worker分配执行任务(通过传递函数闭包实现)
- 执行任务的Worker:
- 长期运行的进程
- 存储RDD分区数据于内存中
RDD Operations in Spark

Representing RDDs
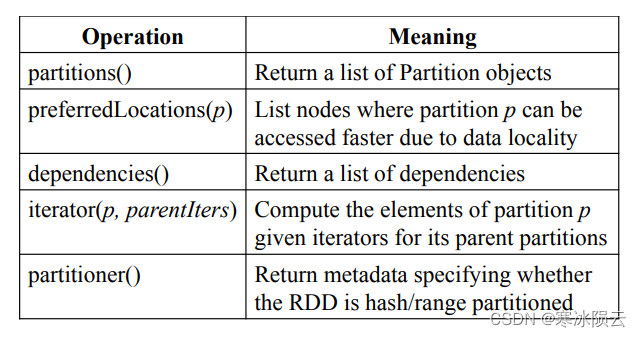
Spark中RDD的数据结构抽象为以下接口:
- 一组分区:RDD的分区组成集合
- 一组依赖:所依赖的parent RDD集合
- 函数:从parent RDD映射到当前RDD的function
- 元数据:包含分区方案和数据放置策略
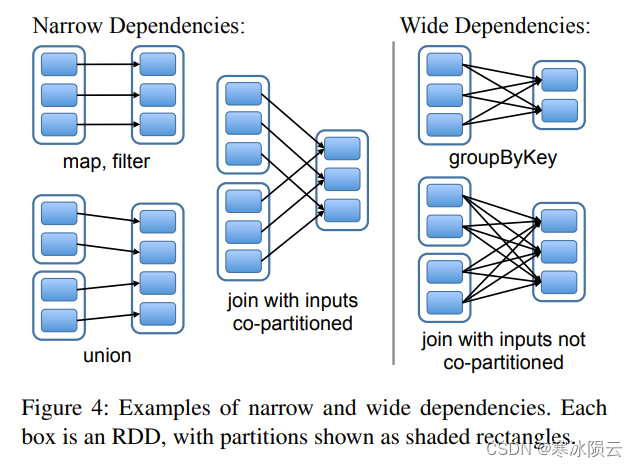
Spark中RDD的依赖关系被定义为两种,不同的依赖关系可以使用不同的执execution和fault recovery策略:
- 窄依赖:父RDD的每个分区至多被一个子RDD的分区使用(比如map操作)
- 可以采用pipelined execution
- 多个RDD分区间的执行互不干扰
- fault recoery时只需要将对应的parent RDD partition进行重新计算
- 宽依赖:父RDD的每个分区,可能被多个子RDD的分区使用(比如join操作)
- execution时需要parent RDD所有数据可用其需要进行shuffle
- recovery时可能需要对所有的parent RDD partition进行重新计算
下图给出了在HDFS file上建立RDD中可能出现的依赖情况。
Implementation
Job Scheduling
每当用户执行action operation后,scheduler会根据RDD lineage graph创建DAG图,其创建规则如下:
- 每个stage会包含尽可能多的narrow dependencies
- stage的边界是wide dependencies所需要的shuffle operation或已经计算完毕的partition
- scheduler会发起task计算每个stage内缺少的partition

scheduler根据数据局部性,使用延迟调度来分配任务:
- 如果task所要处理的partition已经存储在某个节点的内存中,则将该任务分配给该节点
- 否则,则分配给距离其数据所在d鹅HDFS节点近的计算节点中
对于宽依赖,中间的结果会被物化在拥有父RDD分区的节点上,用于加速fault recovery。
Interpreter Integration
Scala也包含了一个解释器,而它会把用户的输入编译成一个类,加载到JVM中,之后调用类的函数。
Spark中,对解释器进行了2个改变:
- 解释器创建的类的字节码,通过HTTP协议传输给Worker
- 修改代码生成逻辑,能直接引用每行生成的类的实例,以实现闭包
Memory Management
Spark提供了三种存储RDD的方式:
- 反序列化成Java对象保存到内存
- 最快,JVM能访问本机每个RDD元素
- 保存序列化的数据到内存
- 稍差,内存空间有限时,一种更有效的存储方式
- 存储到磁盘
- 最慢,对象太大无法存入内存时使用
当内存有限时,对RDD分区实行LRU替换策略,除非新创建的RDD分区和即将淘汰的分区是相同的。此外,使用RDD持久化优先级,让用户进一步控制RDD。
Support for Checkpointing
虽然使用lineage graph可以进行RDD fault recovery,但是lineage过长时会比较耗时,因此RDD中也支持了checkpoint。
对定期对RDD执行checkpoint,将快照存入稳定存储,以提高恢复速度,checkpoint只适用于wide dependencies,因为narrow dependencies可以并行恢复。
Spark提供一个API(给persist()传入REPLICATE标识)来进行checkpoint,由用户具体要对哪些数据进行checkpoing。
由于RDD是只读的,因此checkpoint更加简单且没有一致性问题。RDD的数据可以直接后台写出,不需要程序暂停或者达成分布式快照的共识。
















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









