






一、 盲源分离通信抗干扰基本原理
简单来说,盲源分离数为了解决“鸡尾酒会”问题。「鸡尾酒会问题」(Cocktail Party Problem)诞生于 1953 年,是语音识别领域的经典问题,指是人们在鸡尾酒会中交谈,语音信号会重叠在一起,机器需要将它们分离成独立的信号。对于计算机来说,这个问题与图像识别中的物体识别非常相似。物体就像我们想要注意到的声音,图片的背景则是其他声音。关于这个问题目前有两种解决思路。
一种基于单通道系统,即依靠语音的频谱解决问题。比如将想听到的声音的时频元(time-frequency unit)标注为 1,其他声音标注为 0,让机器学习去输出 1 的部分;另一种方法是基于多通道系统,即在鸡尾酒会的不同位置布置多个麦克风,利用空间属性对声音进行分离。虽然深度学习已经在鸡尾酒会问题中取得很大突破,但仍无法真正解决这一问题。
根据接收通道数目m,盲源分离可以分为多通道(m>1)和单通道(m=1)盲源分离。再根据源信号数目n与m的关系,多通道盲源分离又可分为超定(m>n)、适定(m=n)和欠定(2≤m<n)几种情况。单通道盲源分离原属于欠定盲源分离,但是,由于接收端仅有一个接收通道,基于矩阵的多通道盲源分离理论框架不再适用。
此外根据源信号混合的方式,盲源分离问题也分为线性混合模型、非线性混合模型以及卷积线性混合模型。线性混合模型指观测信号为各个源信号的线性叠加,非线性混合模型指观测信号由源信号为变量的非线性函数组成,卷积线性混合模型指观测信号由源信号不同时延值得线性叠加得到。卷积线性混合模型常见于存在多径效应或频率选择性衰落的信道,而非线性混合模型较为少见。本文仅考虑最为常见的线性混合模型下的多通道盲源分离和单通道盲源分离。
二、多通道盲源分离(FastICA)
1.多通道盲源分离数学模型
盲源分离问题最早来源于“鸡尾酒会问题”,即在嘈杂的聚会上,如何在多人说话的环境中有选择性地接收到感兴趣的人说话的声音。人类可以依靠大脑对音频信号的处理,实现对感兴趣的信号的接收。该场景可抽象为下图:
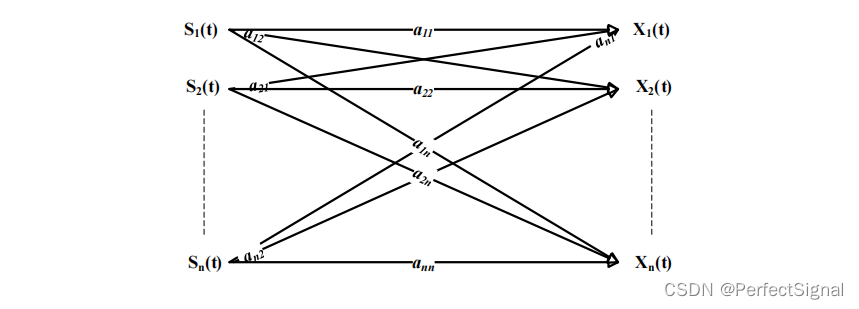
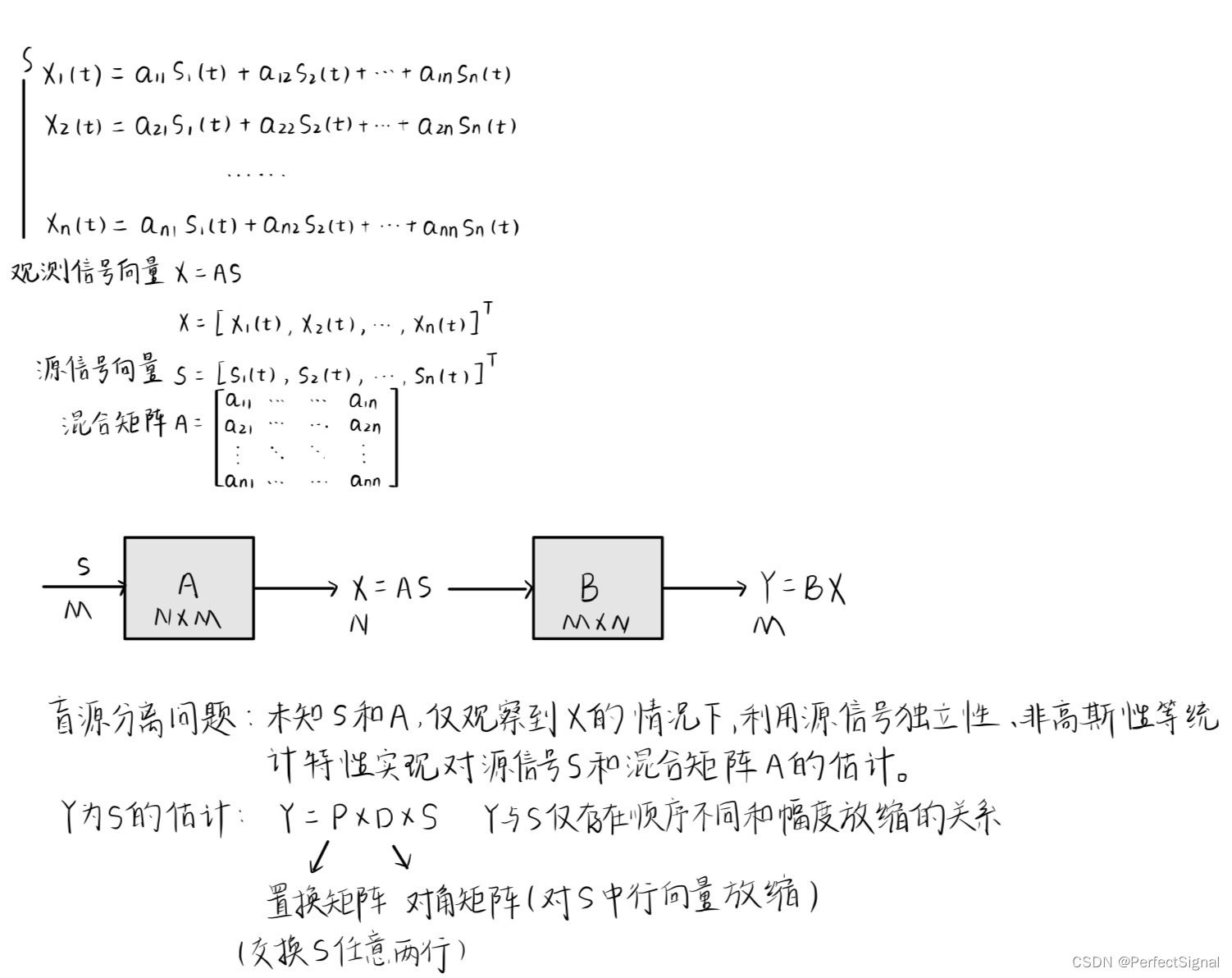
2.独立向量分析
独立分量分析(Independent ComponentAnalysis, ICA)是盲源分离问题中最经典最有效的处理方法。ICA 也是由学者 P.Comon提出,该方法可根据源信号之间的统计独立性对源信号进行有效的估计。由于 ICA 对于盲源分离问题的处理有较好的效果,部分学者将 ICA 与盲源分离混为一谈。
由于盲源分离问题可抽象为缺少条件下的解方程的问题,因此需要人为加入部分约束条件才能使该问题有解可解:
(1) 各源信号相互统计独立。
(2) 混合矩阵 A 为列满秩,即M>=N,即为超定或正定模型。
(3) 源信号向量组 S 中最多有一个高斯信号。
(4) 源信号向量组 S 中各个信号都是单位方差的零均值的平稳随机过程。
在现实场景中,源信号组常常满足条件(1)和(3),对于不满足条件(1)的,则需要使用欠定盲分离的方法来进行分离,如根据信号高阶统计特征构建出高维观测信号向量进行分离。对于不满足条件(4)的,将使用数据处理的方式即使用白化(Whiten)将信号方差变为 1,中心化(Centralization)将信号均值变为 0。将白化和中心化合称为数据预处理。
独立分量分析就是一种最优化问题,即在约束条件下,怎样的分离矩阵 B 能让分离信号向量Yi(t)尽可能的分离。由于假设源信号之间相互统计独立,因此分离时常采用的是独立性准则,即使得分离信号向量之间的独立性达到最大。统计学上定义的独立性为下式所示:
p
(
Y
)
=
∑
i
=
1
N
p
(
Y
i
)
p(Y) = \sum_{i=1}^{N}{p(Y_{i})}
p(Y)=i=1∑Np(Yi)
若统计独立,则联合概率密度函数可由各边缘概率密度函数累乘得到。然而独立性难以直接度量,不同学者提出使用下列更直观的统计量进行衡量独立性,如:互信息量极小化准则、信息最大化准则、非高斯性最大化准则、极大似然准则。
3.快速固定点算法
(1)数学原理
快速固定点算法(FastICA)是由芬兰学者 A.Hyvarinen在 1997 年提出的一种基于批处理的顺序提取算法。由于其快速的收敛性能以及较好的稳定性被学者广泛运用于该领域。FastICA 算法主要分为两个部分:信号预处理和分离。
①信号预处理
由于观测信号 不一定满足约束条件(4),因此需要对其进行中心化和白化将其标准化为方差为 1 的零均值信号。中心化可表示为:
X
i
(
t
)
˙
=
X
i
(
t
)
−
E
[
X
i
(
t
)
]
\dot{X_{i}(t)} = X_{i}(t)-E[X_{i}(t)]
Xi(t)˙=Xi(t)−E[Xi(t)]
将观测信号Xi(t)减去其时间平均值E[X(t)]即得到中心化后的信号。
%去均值
[M,T]=size(X); %获取输入矩阵的行列数,行数为观测信号的数目,列数为采样点数
average=mean(X,2); %求每一个采集到的信号X的时间平均均值,2表示对行求平均
for i=1:M
X(i,:)=X(i,:)-average(i)*ones(1,T);
end
%得到均值为0的信号矩阵X,便于分析
白化是指通过主成分分析(Principal Component Analysis,PCA)对观测信号矩阵 X 进行线性变换,使得变换后的矩阵Xw中各分量互不相关且具有单位方差。由于白化操作近似于对信号进行了简化,因此白化后使用 ICA 算法能够收敛更快且具有更好的稳定性。白化的具体操作如下所示:
首先求出 X 的协方差矩阵:
C
=
1
T
X
X
T
C = \frac{1}{T}XX^{T}
C=T1XXT
其中 T 代表观测向量 X 的长度。
对 C 进行特征分解如下:
C
=
V
A
V
−
1
C = VAV^{-1}
C=VAV−1
其中矩阵
V
V
V是特征值按列组成的矩阵,
A
A
A 是由特征值组成的对角矩阵。
因此白化后的
X
w
X_{w}
Xw可由下式得到:
C
=
A
−
1
2
V
T
X
C = A^{-\frac{1}{2}}V^{T}X
C=A−21VTX
%白化
Cx=cov(X'); %计算协方差矩阵Cx,cov函数是对X中的列向量之间求协方差,因此要转置
[eigvector,eigvalue]=eig(Cx); %计算Cx的特征值和特征向量
W=eigvalue^(-1/2)*eigvector'; %白化矩阵
Z=W*X; %正交矩阵,即白化后的X_w
②分离
由于假设源信号之间是统计独立的,因此使用独立性作为分离的目标函数。上文介绍了四种常见的独立性准则,由于经典的非高斯性度量参数峭度对非高斯信号有较好的度量,但对野值(即突发差错点、奇异点、极端值等)十分敏感。负熵也有较好的度量,但计算难度较大。因此将峭度和负熵结合得到如下公式的度量函数,对分离信号
Yi的独立性进行衡量:
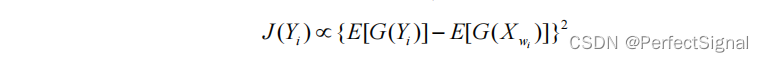
其中 是第 i 个分离信号向量, 是白化后的观测信号矩阵中第 i 个观测信号向量,函数 G()是一个非二次函数,E[]是均值函数。分离问题即转化为最优化问题,即求出使得J(Yi)达到最大值时的分离矩阵B中的一行向量wi 。
在对目标函数进行优化的过程中,FastICA 算法采用固定点算法。即在求解方程
f
(
x
)
=
0
f(x) = 0
f(x)=0的根时,将 f(x)写为反函数的形式
x
=
g
(
x
)
x = g(x)
x=g(x)
则当x=a时,
a
=
g
(
a
)
a = g(a)
a=g(a)
牛顿迭代法即为固定点算法的一种,迭代公式如下:
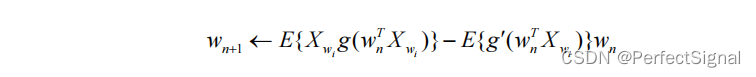
其中wn代表第 n 次迭代的分离行阵列向量,函数g()是非二次函数G()的导函数,函数g’()是函数g()的导函数,常使用:
g
(
x
)
=
t
a
n
h
(
a
x
)
g(x) = tanh(ax)
g(x)=tanh(ax)
其中a常取为1,则此时g’(x)为下式:
g
′
(
x
)
=
1
−
[
g
(
x
)
]
2
g'(x) = 1-[g(x)]^2
g′(x)=1−[g(x)]2
一次迭代收敛只能得到一个分离矩阵行向量,为了分离出 M 个估计信号,因此需要进行 M 组迭代,从而获得分离矩阵 B,实现分离。
%迭代的初始化参数值过程
Maxcount=10000; %最大迭代次数
Critical=0.00001; %判断是否收敛,若两次结果相差很小,则认为收敛
m=M;%需要估计的分量的个数(信号个数)
W=rand(m);%随机生成一个m*m的矩阵
%迭代过程
for n=1:m
W_new=W(:,n); %初始权矢量(任意)W_new代表这一次新的迭代结果
count=0;
W_last=zeros(m,1);
W(:,n)=W(:,n)/norm(W(:,n));%单位化一列向量
%while (abs(W_new-W_last)&abs(W_new+W_last))>Critical
while abs(W_new-W_last)>Critical
count=count+1; %迭代次数
W_last=W_new; %上次迭代的值
for i=1:m
W_new(i)=mean(Z(i,:).*(tanh((W_last)'*Z)))-(mean(1-(tanh((W_last))'*Z).^2)).*W_last(i);
end
%对结果额外地进行去相关,防止W中的各个向量收敛到同一个最大值
WPP=zeros(m,1);
for j=1:n-1
WPP=WPP+(W_new'*W(:,j))*W(:,j);
end
W_new=W_new-WPP;
W_new=W_new/(norm(W_new));
if count==Maxcount
fprintf('failure');
Z=W_new'*Z;
return;
end
end
W(:,n)=W_new;%找到了,因此把该列放入W矩阵中
end
Z=W'*Z;%数据输出
三、单通道盲源分离(SSA-ICA)
单通道盲源分离指仅在观测到一路混合信号 的情况下得到估计信号组 ,显然此时 N=1<M,不满足 ICA 算法中的假设前提,因此无法直接使用 ICA 算法及模型对单通道盲源分离问题进行求解。由于 ICA 算法已经相对成熟,因此不少学者考虑将单通道转化为多通道问题问题,再根据 ICA 理论进行求解,如根据经验模态分解(EMD,empirical mode decomposition)将单通道分解为多路固有模态函数转化为多通道再使用 FastICA 求解,或者通过过采样的方式将混合信号映射为多路虚拟观测信号等。另有学者根据源信号的特点充分挖掘源信号之间的差异性以及特点,基于信号有限符号集特征的特征提出粒子滤波算法和逐幸存路径处理(PSP,per-survivor processing)等方法。已经有文献指出,使用奇异谱分析(SSA,Singularspectrum analysis)结合 ICA 的方法对时频混合信号的单通道分离有较好的分离性能,因此本文将使用 SSA-ICA 算法对单通道盲源
分离问题进行研究SSA-ICA 算法分为两部分,SSA 与 ICA。
1.SSA-ICA分离算法
SSA 分为分解阶段和重建阶段,分解阶段又包括嵌入和奇异值分解两个步骤,重建阶段分为分组和对角平均两个步骤。由于 ICA 部分即为第三章所述方法,因此本节仅对 SSA 部分进行分析描述。
(1)嵌入
根据单通道观测信号向量
X
(
t
)
=
[
X
(
1
)
,
X
(
2
)
,
.
.
.
,
X
(
T
)
]
X(t)=[X(1),X(2),...,X(T)]
X(t)=[X(1),X(2),...,X(T)]
构建M*L的轨迹矩阵Y,如公式:
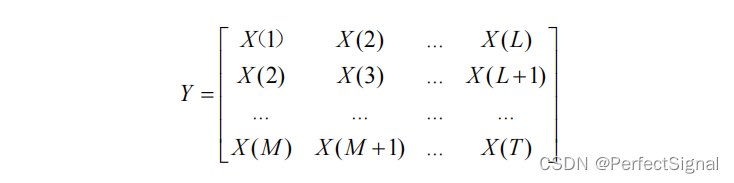
其中 T 代表一帧长度,M 和 L 为自定窗口长度,满足M = T−L+1。由于矩阵Y中的反对角元素都相同,也成为汉克尔矩阵(Hankel matrix)。
本课题中,M为2,源信号组有2路信号,T为1024,经计算,L = T-M+1 = 1023
%嵌入步骤
L=length(Y_obs)-M+1;
Y=hankel(Y_obs(1:M),Y_obs(M:end));
%H = hankel(c,r) 返回其第一列是 c 并且其最后一行是 r 的 Hankel 矩阵。如果 c 的最后一个元素与 r 的第一个元素不同,则 c 的最后一个元素优先。
(2)奇异值分解
由于矩阵Y 为M*L阶,因此直接求解奇异值十分复杂,考虑先由 Y 的协方差矩阵
C
=
Y
Y
′
C=YY'
C=YY′求出特征值
λ
i
\lambda_{i}
λi和特征向量
q
i
q_{i}
qi,再将特征向量按照对应的特征值大小降序排列。
令
r
k
=
Y
T
q
k
/
(
λ
k
)
r_{k}=Y^{T} q_{k}/\sqrt{(\lambda_{k})}
rk=YTqk/(λk)
于是观测信号
X
X
X的第
k
k
k个观测点的轨迹矩阵可表示为下式
Y
k
=
q
k
T
q
k
Y
,
k
=
1
,
2
,
.
.
.
,
M
Y_{k}=q_{k}^{T} q^{k}Y,k=1,2,...,M
Yk=qkTqkY,k=1,2,...,M
因此可通过轨迹矩阵 Y 得到 M 个子空间
Y
k
Y_{k}
Yk 。由于按特征值降序排列,可认为较大的特征值对应着信号的趋势,而较小的特征向量则视为噪声。即可将混合信号按功率大小区分。
%分解步骤
C=Y*Y';
[eVector,eValue] = eig(C);%eValue是特征值形成的对角矩阵,eVector是特征向量矩阵,每一列是一路特征向量
eValue = diag(eValue); %将对角矩阵变为一列向量
[value_sort,index]=sort(eValue,'descend');
(3)分组
将
M
M
M个子空间
Y
k
Y_{k}
Yk依据特征值降序排列分为
c
c
c组,则第
l
l
l组的轨迹矩阵可表示为下式
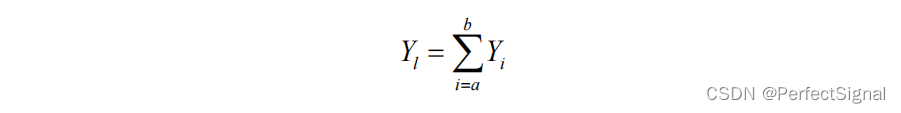
其中
a
a
a和
b
b
b代表第
l
l
l组的起止序号。
因此轨迹矩阵可表示为下式:
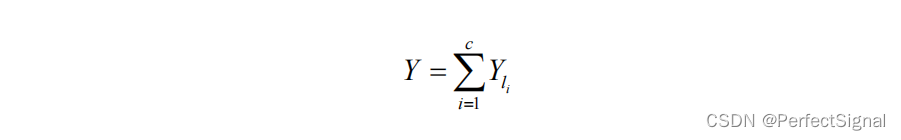
本课题中,源信号组一路为信号,另一路为噪声,所以将M个子空间分为2组,p为特征值的分界线,特征值大的一组为信号
Y
1
Y_{1}
Y1,特征值小的一组为噪声
Y
2
Y_{2}
Y2。
代码如下:
Y1 = zeros(M,L);
Y2 = zeros(M,L);
p=find(value_sort<=value_sort(1)/100,1)-1;
for i = 1:p
Y1 = Y1 + eVector(:,index(i))*(eVector(:,index(i)))'*Y;
end
for k = p+1:M
Y2 = Y2 + eVector(:,index(k))*(eVector(:,index(k)))'*Y;
end
(4)对角平均
该步骤即可将分组得到的 c 组轨迹矩阵映射为 c 条通道信号。令
S
i
k
S_{ik}
Sik为期望信号中元素在第
i
i
i行第
k
k
k列的估计轨迹矩阵。可通过下式得到观测信号的第
n
n
n个样本
s
(
n
)
s(n)
s(n):
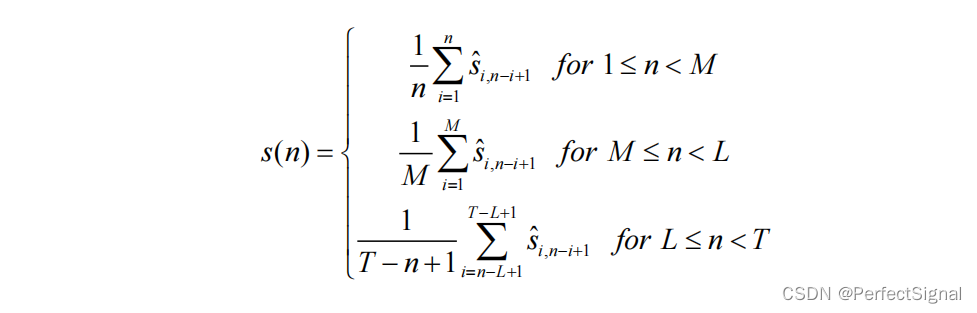
R1 = diag_average(Y1);
R2 = diag_average(Y2);

















 8321
8321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









