






参考资料:
https://github.com/InternLM/Tutorial/tree/camp2/xtuner https://github.com/InternLM/Tutorial/blob/camp2/xtuner/readme.md
1 微调介绍
LLM微调是一个将预训练模型在较小、特定数据集上进一步训练的过程,目的是精炼模型的能力,提高其在特定任务或领域上的性能。微调的目的是将通用模型转变为专用模型,弥合通用预训练模型与特定应用需求之间的差距,确保语言模型更贴近人类的期望。
回顾第一讲中提到从模型到应用的典型流程如下:
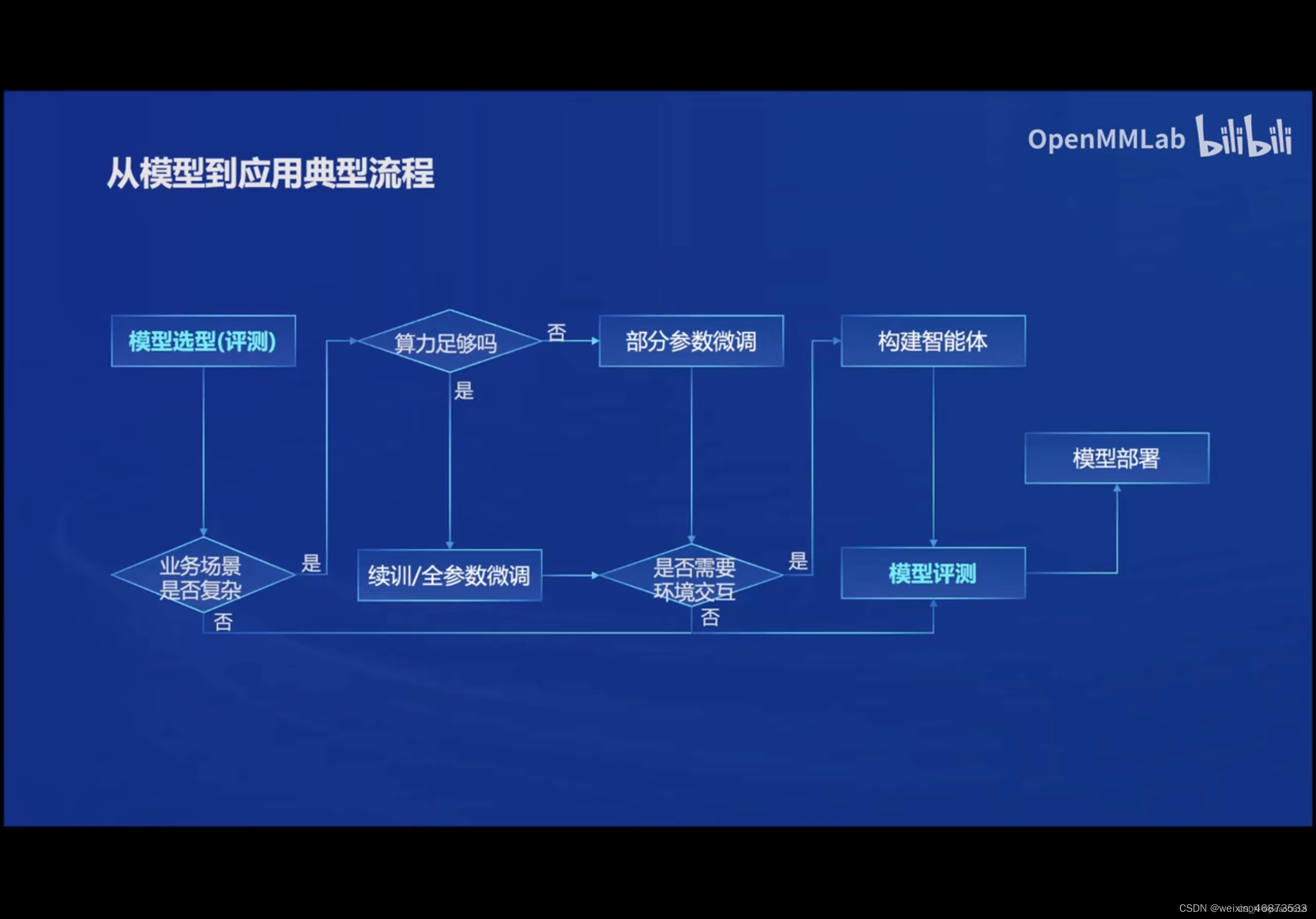
根据项目目标使用环境进行模型选型,如果业务场景需求比较复杂就需要进行模型微调,根据算力是否充足可以选择模型的全参数微调或部分参数微调。
- 增量预训练微调:让基座模型学习到一些新知识,如某个垂类领域的常识。
- 指令跟随微调:让模型学会对话模板,根据人类指令进行对话。
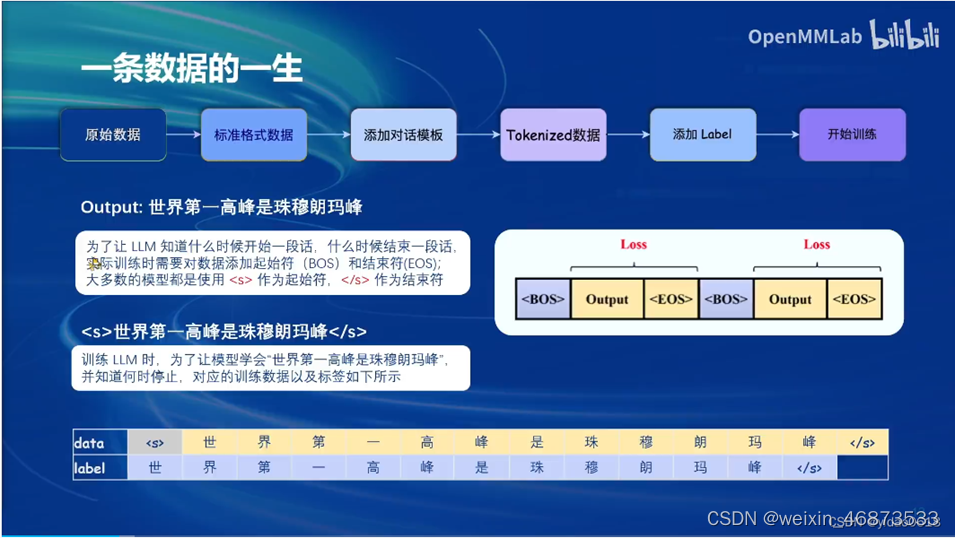
1.4 大模型微调方法
1.4.1 全量微调
通过在预训练的大模型基础上调整所有层和参数,使其适应特定任务。这一过程使用较小的学习率和特定任务的数据进行,可以充分利用预训练模型的通用特征,需要更多的计算资源。
1.4.2 高效参数微调(PEFT)
高效参数微调是指微调少量或额外的模型参数,固定大部分预训练模型参数,从而大大降低了计算和存储成本,同时能实现与全量参数微调相当的性能,甚至在某些情况下效果更好。
高效参数微调可以粗略分为三类:增加额外参数、选取一部分参数更新、引入重参数化。增加额外参数又分为类适配器方法和软提示两类。
高效参数微调目标
1、能够达到相当于全量微调的效果
2、仅更新模型的一部分参数
3、是数据通过流的方式到达,而不是同时到达,便于高效的硬件部署。
4、改变的参数在不同的下游任务中是一致的。
LoRA & QLoRA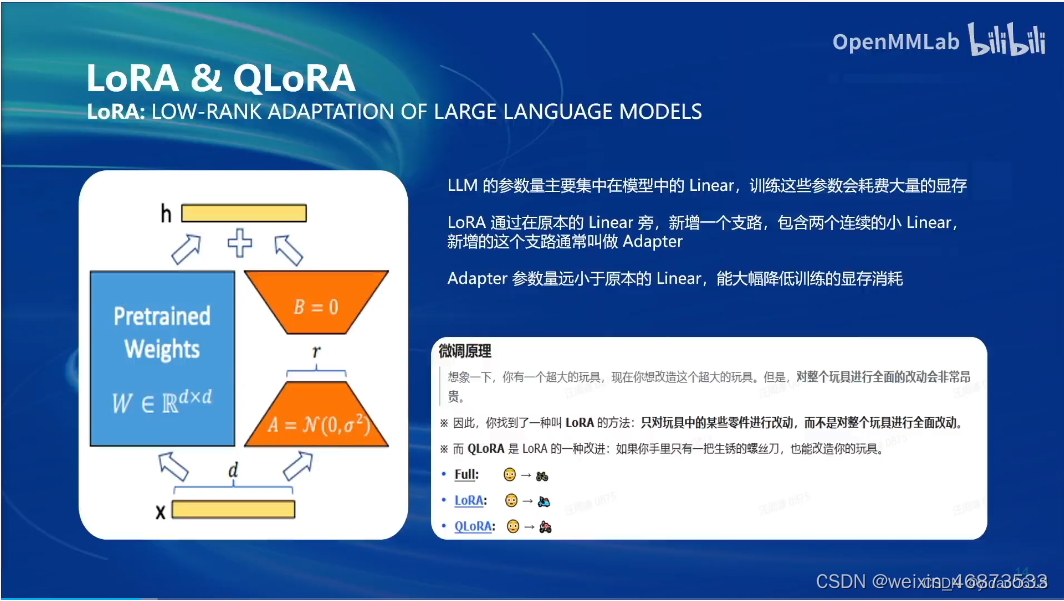
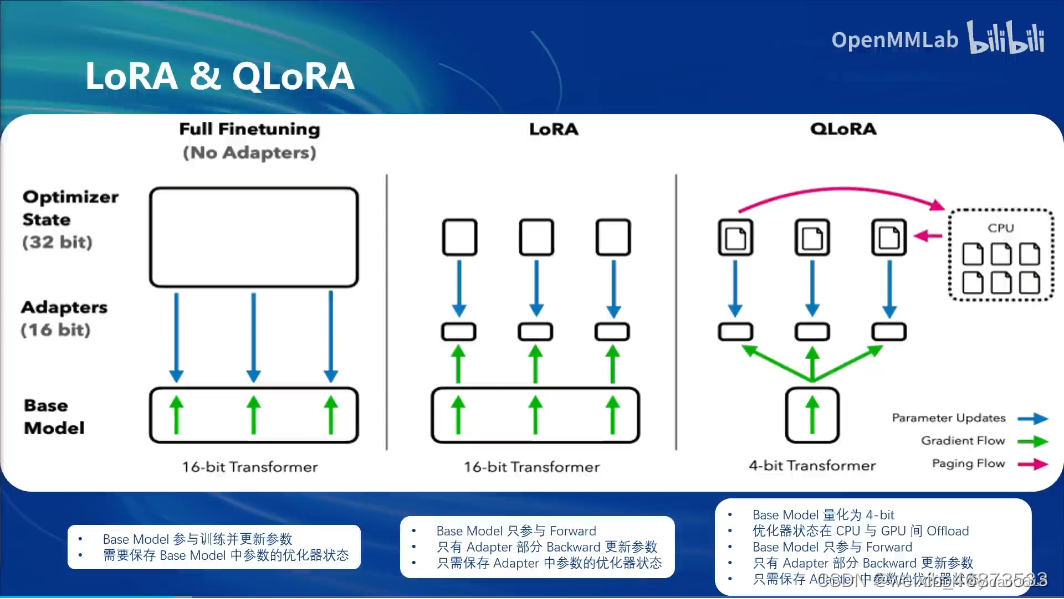
2.1 XTuner特点
高效
- 支持大语言模型 LLM、多模态图文模型 VLM 的预训练及轻量级微调。XTuner 支持在 8GB 显存下微调 7B 模型,同时也支持多节点跨设备微调更大尺度模型(70B+)。
- 自动分发高性能算子(如 FlashAttention、Triton kernels 等)以加速训练吞吐。
- 兼容 DeepSpeed 🚀,轻松应用各种 ZeRO 训练优化策略。
灵活
- 支持多种大语言模型,包括但不限于 InternLM、Mixtral-8x7B、Llama2、ChatGLM、Qwen、Baichuan。
- 支持多模态图文模型 LLaVA 的预训练与微调。利用 XTuner 训得模型 LLaVA-InternLM2-20B 表现优异。
- 精心设计的数据管道,兼容任意数据格式,开源数据或自定义数据皆可快速上手。
- 支持 QLoRA、LoRA、全量参数微调等多种微调算法,支撑用户根据具体需求作出最优选择。
全能
- 支持增量预训练、指令微调与 Agent 微调。
- 预定义众多开源对话模版,支持与开源或训练所得模型进行对话。
- 训练所得模型可无缝接入部署工具库 LMDeploy、大规模评测工具库 OpenCompass 及 VLMEvalKit。
2.2 XTuner运行原理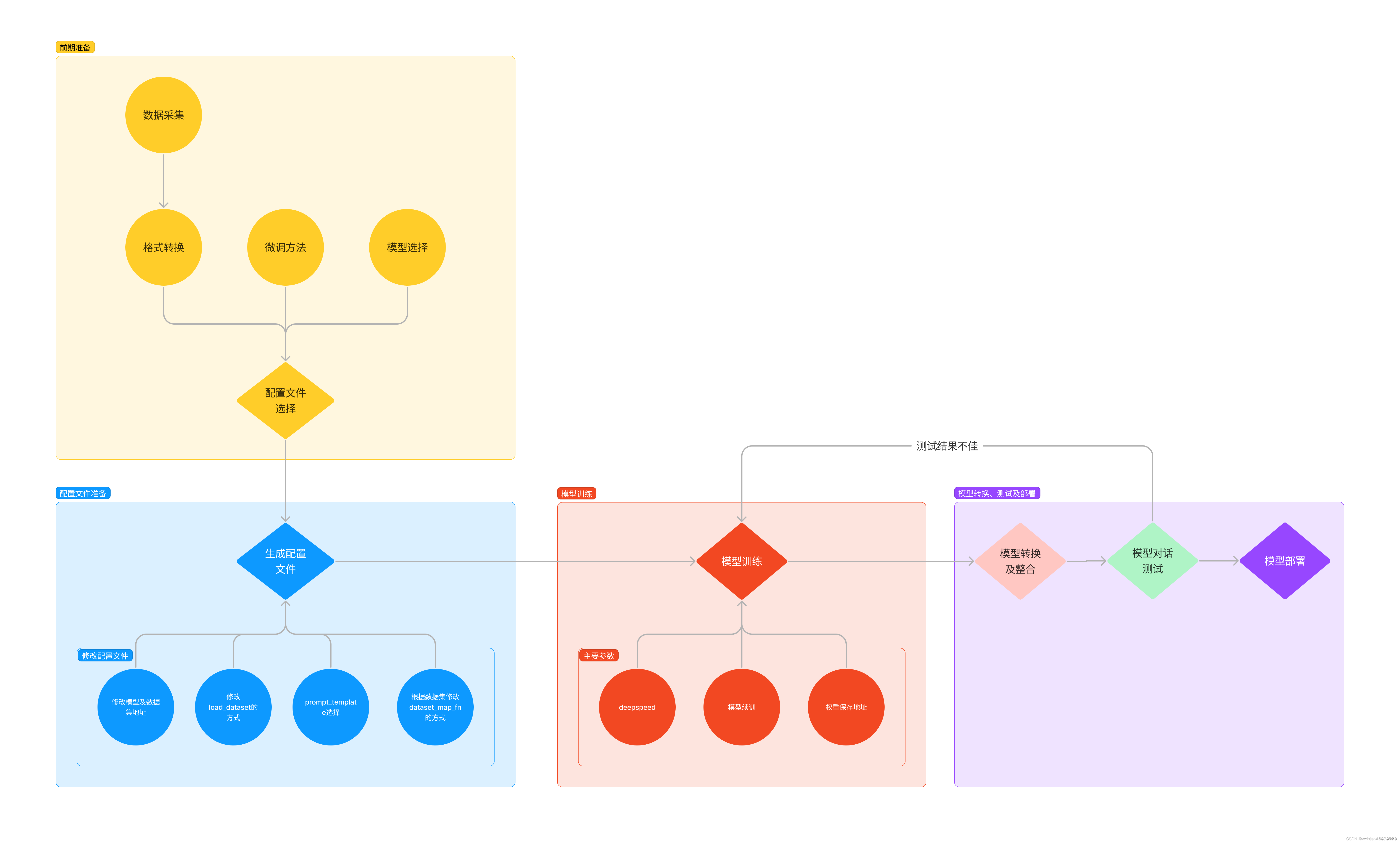
3 使用XTune进行微调
3.1 配置环境
step 1.创建开发机
step 2.配置虚拟环境
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 的环境:
# pytorch 2.0.1 py3.10_cuda11.7_cudnn8.5.0_0
studio-conda xtuner0.1.17
# 如果你是在其他平台:
# conda create --name xtuner0.1.17 python=3.10 -y
# 激活环境
conda activate xtuner0.1.17
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir -p /root/xtuner0117 && cd /root/xtuner0117
# 拉取 0.1.17 的版本源码
git clone -b v0.1.17 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.15 https://gitee.com/Internlm/xtuner
# 进入源码目录
cd /root/xtuner0117/xtuner
# 从源码安装 XTuner
pip install -e '.[all]'
xtuner命令的参数如下:
3.2 前期准备
3.2.1 数据准备
利用python生成json格式数据集
import json
# 设置用户的名字
name = 'xxx'
# 设置需要重复添加的数据次数
n = 10000
# 初始化OpenAI格式的数据结构
data = [
{
"messages": [
{
"role": "user",
"content": "请做一下自我介绍"
},
{
"role": "assistant",
"content": "我是{}的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦".format(name)
}
]
}
]
# 通过循环,将初始化的对话数据重复添加到data列表中
for i in range(n):
data.append(data[0])
# 将data列表中的数据写入到一个名为'personal_assistant.json'的文件中
with open('personal_assistant.json', 'w', encoding='utf-8') as f:
# 使用json.dump方法将数据以JSON格式写入文件
# ensure_ascii=False 确保中文字符正常显示
# indent=4 使得文件内容格式化,便于阅读
json.dump(data, f, ensure_ascii=False, indent=4)
![]()
上面程序循环生成了10000次自我介绍问答对的数据,并且存储为json格式。如下图所示:
3.2.2 模型准备
# 创建目标文件夹,确保它存在。
# -p选项意味着如果上级目录不存在也会一并创建,且如果目标文件夹已存在则不会报错。
mkdir -p /root/ft/model
# 复制内容到目标文件夹。-r选项表示递归复制整个文件夹。
cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/* /root/ft/model/
3.2.3 选择配置文件
# 列出所有内置配置文件
# xtuner list-cfg
# 假如我们想找到 internlm2-1.8b 模型里支持的配置文件
xtuner list-cfg -p internlm2_1_8b

| 模型名 | 说明 |
| internlm2_1_8b | 模型名称 |
| qlora | 使用的算法 |
| alpaca | 数据集名称 |
| e3 | 把数据集跑3次 |
实际上我们使用的是自定义的小助手数据集,并不是alpaca数据集,但最相近的就是internlm2_1_8b_qlora_alpaca_e3配置文件,然后进行配置文件的修改。
# 创建一个存放 config 文件的文件夹
mkdir -p /root/ft/config
# 使用 XTuner 中的 copy-cfg 功能将 config 文件复制到指定的位置
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config
3.3 配置文件修改
XTuner的配置文件中包含了5个部分:
- Settings:涵盖模型的基本设置,包括预训练模型的选择、数据集信息以及训练过程的一些参数。
- Model & Tokenizer:制定模型和分词器的具体类型及其配置。
- Dataset & Dataloader:数据处理的细节,加载数据集、预处理步骤、批处理大小等。
- Scheduler & Optimizer:优化器的相关配置。
- Runtime:包括日志记录,模型保存策略,自定义钩子等
3.4 模型微调
# 指定保存路径
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train
# 使用 deepspeed 来加速训练
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2
分别尝试基本训练和使用DeepSpeed的方式进行训练,基本训练用时 20min,使用DeepSpeed后用时 14min。
微调的过程中可能会出现严重的过拟合使模型失去基础能力,涡轮提问什么都会重复某句话。
解决方案:
- 减少保存权重文件的间隔并增加权重文件的保存上限。
- 增加常规的对话数据集从而稀释原本数据的占比。
模型续训:
在原本的训练命令的基础上额外增加参数--resume <你的checkpoint>
# 模型续训
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train --resume /root/ft/train/iter_600.pth
3.5 模型转换、整合、测试和部署
3.5.1 模型转换
模型转换就是将训练好的模型的权重文件转换为目前通用的Huggingface格式的文件:
# 创建一个保存转换后 Huggingface 格式的文件夹
mkdir -p /root/ft/huggingface
# 模型转换
# xtuner convert pth_to_hf ${配置文件地址} ${权重文件地址} ${转换后模型保存地址}
xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_768.pth /root/ft/huggingface
此时,huggingface文件夹即训练好的的LoRA模型文件。
使用xtuner convert命令进行模型转换时可以传递两个参数:
| 参数名 | 解释 |
| –fp32 | 代表以fp32的精度开启,假如不输入则默认为fp16 |
| –max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_768.pth /root/ft/huggingface --fp32 --max-shard-size 2GB
- 1
3.5.2 模型整合
转换后的模型参数并不是完整的模型参数,而是一个额外的层(adapter)。需要与基座模型组合后才能正常使用。
# 创建一个名为 final_model 的文件夹存储整合后的模型文件
mkdir -p /root/ft/final_model
# 解决一下线程冲突的 Bug
export MKL_SERVICE_FORCE_INTEL=1
# 进行模型整合
# xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH}
xtuner convert merge /root/ft/model /root/ft/huggingface /root/ft/final_model
| 参数名 | 解释 |
| –device {device_name} | 这里指的就是device的名称,可选择的有cuda、cpu和auto,默认为cuda即使用gpu进行运算 |
| –max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
| –is-clip | 这个参数主要用于确定模型是不是CLIP模型,假如是的话就要加上,不是就不需要添加 |
3.5.3 对话测试
# 创建一个名为 final_model 的文件夹存储整合后的模型文件
mkdir -p /root/ft/final_model
# 解决一下线程冲突的 Bug
export MKL_SERVICE_FORCE_INTEL=1
# 进行模型整合
# xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH}
xtuner convert merge /root/ft/model /root/ft/huggingface /root/ft/final_model
















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









