







到上海来了,上海的天气真是又闷又热。今天休息整理了一下只学习了两个小时。在前面已经复习完了计组和计网,总的来说基本上都可以理解了。从今天起就开始继续学习和复习数据库相关知识
惯例每天刷一下leetcode:
leetcode 76:最小覆盖子串
总来说就是使用了滑动窗口,当没覆盖的时候右边滑动,覆盖之后左边滑动缩小窗口。一只这么做下去,然后每一次都需要判断是否覆盖,这里的话需要一些技巧。题解的方法使用了哈希表去优化O(n2)的查询过程,变成了O(n)。讨论区里面有很多人说可以使用countnum来进一步加快,目前最后四个测试样例没过。
leetcode 53最大子数组和
给定一个数组,找出其中连续序列和最大的值。采用动态规划求解。分析该类问题,最明显的特征就是可以从小规模问题来进一步求解大规模问题,可以采用动态规划进行求解,而分治法是平行的将问题分解为多个子问题进行求解。
leetcode 56合并区间问题
先对于左端点进行排序,排序完成后可以知道,此时构成将来的区间的小区间一定是聚集的。可以用反证法证明,然后再逐步合并即可。合并时有的时候反面的条件更加好写。
leetcode 189轮转数组
比较简单,主要考察了vector容器的使用。
数据库:
Oracle和Mysql中sql语句的执行方式:
总的来说都会经历一个语义检查的过程,不同的是Oracle检查完之后才查缓存而Mysql一上来就进行缓存查询,然后再经过解析器,优化器,执行器进行解析执行。相比较于其他的数据库系统,mysql最大的优势是支持不同的存储引擎。可以分为三层,连接层,SQL层和存储层。
软解析和硬解析,软解析共享池中有缓存,硬解析重新生成执行计划。
接下来主要讲讲在MySQL中SQL的解析过程:(主要参考了小林coding)
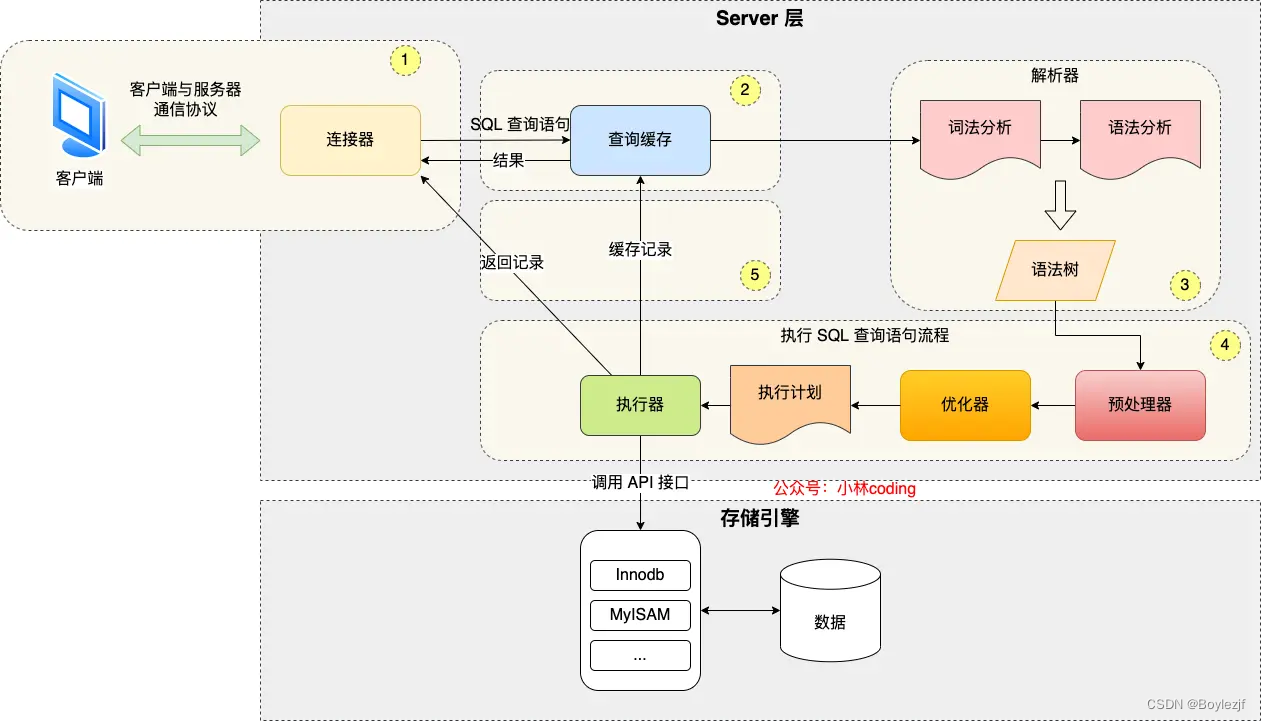
如上图所示,MySQL是一个典型的客户端,服务端模式设计,我们主要讲讲服务端干了点啥。
有的人把MySQL分为三层,即连接层,SQL层,存储层。有的人分为两层Server层和存储层,anyway其实都差不多。
首先是连接器,用于和客户端建立连接。验证密码和身份。这里有一个长连接和短连接的问题,如果一直是短连接,每次SQL事务都要进行一次连接,效率不高,但是如果一直是长连接,随着时间增长长连接所建立的对象所占内存会增加。解决方式主要有两种,首先是服务端定期断开长连接,第二是客户端主动调用函数终止连接,释放内存。
连接完成之后,根据客户端所提供的SQL语句,服务器去缓存中查询是否具有缓存结果。但是实际使用中来看MySQL缓存策略并不是很有用,在8.0版本后就已经被删除了。
解析器:词法分析,形成语法树。
执行器: 预处理,对比表名,列名是否一样,优化器,决定按照什么方式进行检索的代价最小。
执行器和存储引擎的交互方式:
主键索引查询:主键等值查询。
全表扫描:使用不到索引因此全表扫描。
索引下推:回表。
然后学习了一下SQL的基本语法:
略
数据库建表的基本原则: 1.建立的表越少越好 2.数据库表的字段越少越好 3.联合主键的字段越少越好 4. 使用的主键和外键越多越好。

SLECT 基本语法,基本了解一下就行,起别名,DISTINCT ,ORDER BY, DESC,ASC,LIMIT 等。关键字不可以调换顺序:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...通配符(%代表一个或者多个字符,_表示一个字符),IN,日期等等。















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









