







1、Mybatis的一二级缓存
- 一级缓存(sqlsession级别)
第一次发出一个查询 sql,sql 查询结果写入 sqlsession 的一级缓存中,缓存使用的数据结构是一个 map。
key:MapperID+offset+limit+Sql+所有的入参
value:用户信息
同一个 sqlsession 再次发出相同的 sql,就从缓存中取出数据。如果两次中间出现 commit 操作(修改、添加、删除),本 sqlsession 中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。 - 二级缓存(mapper级别)
二级缓存的范围是 mapper 级别(mapper 同一个命名空间),mapper 以命名空间为单位创建缓存数据结构,结构是 map。mybatis 的二级缓存是通过 CacheExecutor 实现的。CacheExecutor其实是 Executor 的代理对象。所有的查询操作,在 CacheExecutor 中都会先匹配缓存中是否存在,不存在则查询数据库。
key:MapperID+offset+limit+Sql+所有的入参
具体使用需要配置:
1、Mybatis 全局配置中启用二级缓存配置
2、在对应的 Mapper.xml 中配置 cache 节点
3、在对应的 select 查询节点中添加 useCache=true
对于 mapper 级别的缓存不同的sqlsession 是可以共享的。
一级缓存和二级缓存的使用顺序
请注意,如果你的MyBatis使用了二级缓存,并且你的Mapper和select语句也配置使用了二级缓存,那么在执行select查询的时候,MyBatis会先从二级缓存中取输入,其次才是一级缓存,即MyBatis查询数据的顺序是:
二级缓存 ———> 一级缓存——> 数据库
如果两次查询之间发生了增删改查操作,一二级缓存都会清空
2、SpringBoot自动装配机制以及自定义一个starter
3、Redis如何做内存优化?
可以好好利用Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面
4、Redis实现分布式锁
Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系Redis中可以使用SETNX命令实现分布式锁。
当且仅当 key 不存在,将 key 的值设为 value。 若给定的 key 已经存在,则 SETNX 不做任何动作
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
返回值:设置成功,返回 1 。设置失败,返回 0 。
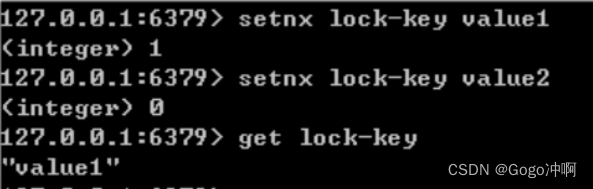
使用SETNX完成同步锁的流程及事项如下:
使用SETNX命令获取锁,若返回0(key已存在,锁已存在)则获取失败,反之获取成功
为了防止获取锁后程序出现异常,导致其他线程/进程调用SETNX命令总是返回0而进入死锁状态,需要为该key设置一个“合理”的过期时间
释放锁,使用DEL命令将锁数据删除
5、Redis服务降级
缓存降级是指当访问量剧增、服务出现问题(比如响应时间慢或者不响应)或者非核心服务影响到核心流程的性能时,即使是有损部分其他服务,仍然需要保证主服务可用,可以将其他次要访问的数据进行缓存降级,从而提升主服务的稳定性
降级的目的是保证核心服务可用,即使可能有损其他操作。比如双十一的时候淘宝购物车无法修改地址只能使用默认地址,这个服务就是被降级了,这是阿里为了保证订单可以正常提交和付款,但修改地址的服务可以在服务器压力降低,并发量相对减少的时候再恢复。
缓存降级是指缓存失效或者缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或者访问服务的内存数据。降级一般是有损的操作,所以尽量减少降级对业务的影响程度
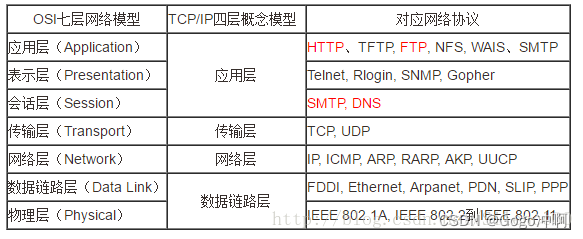
6、五层协议
7、InnoDB 的行锁是针对索引字段加的锁(排他锁),表级锁是针对非索引字段加的锁。当我们执行 UPDATE、DELETE、Insert 语句时,如果 WHERE条件中字段没有命中唯一索引或者索引失效的话,就会导致扫描全表对表中的所有记录进行加锁。这个在我们日常工作开发中经常会遇到,一定要多多注意!!!而当使用select语句时,只有在sql语句后面加上for update才会加锁,而加锁原则与上述一致。
lock in share mode是加共享锁(可以读不可以写);for update是加排他锁(不可以读不可以写)
8、HTTP1.0,HTTP1.1,HTTP2.0之间的区别
1、HTTP1.0与HTTP1.1主要区别
长连接
HTTP 1.0需要使用keep-alive参数来告知服务器端要建立一个长连接,而HTTP1.1默认支持长连接,这样减少创建连接的开销,提高了效率。
HTTP是基于TCP/IP协议的,创建一个TCP连接是需要经过三次握手的,有一定的开销,如果每次通讯都要重新建立连接的话,对性能有影响。因此最好能维持一个长连接,可以用个长连接来发多个请求。
节约带宽
HTTP 1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,否则返回401。客户端如果接受到100,才开始把请求body发送到服务器。这样当服务器返回401的时候,客户端就可以不用发送请求body了,节约了带宽。另外HTTP还支持传送内容的一部分。这样当客户端已经有一部分的资源后,只需要跟服务器请求另外的部分资源即可。这是支持文件断点续传的基础。
HOST域
现在可以web server例如tomat,设置虚拟站点是非常常见的,也即是说,web server上的多个虚拟站点可以共享同一个ip和端口。HTTP1.0是没有host域的,HTTP1.1才支持这个参数。
2、HTTP1.1 HTTP 2.0主要区别
多路复用
HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级,当然HTTP1.1也可以多建立几个TCP连接,来支持处理更多并发的请求,但是创建TCP连接本身也是有开销的。TCP连接有一个预热和保护的过程,先检查数据是否传送成功,一旦成功过,则慢慢加大传输速度。因此对应瞬时并发的连接,服务器的响应就会变慢。所以最好能使用一个建立好的连接,并且这个连接可以支持瞬时并发的请求。关于多路复用,可以参看学习NIO 。
数据压缩
HTTP1.1不支持header数据的压缩,HTTP2.0使用HPACK算法对header的数据进行压缩,这样数据体积小了,在网络上传输就会更快。
服务器推送
当我们对支持HTTP2.0的web server请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种方式非常合适加载静态资源。服务器端推送的这些资源其实存在客户端的某处地方,客户端直接从本地加载这些资源就可以了,不用走网络,速度自然是快很多的。
9、AQS
AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
10、事务传播
@Transactional只能回滚RuntimeException和RuntimeException下面的子类抛出的异常 不能回滚Exception异常
如果需要支持回滚Exception异常请用@Transactional(rollbackFor = Exception.class)
@Transactional 注解应该只被应用到 public 方法上















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









