







文章目录
有用的链接
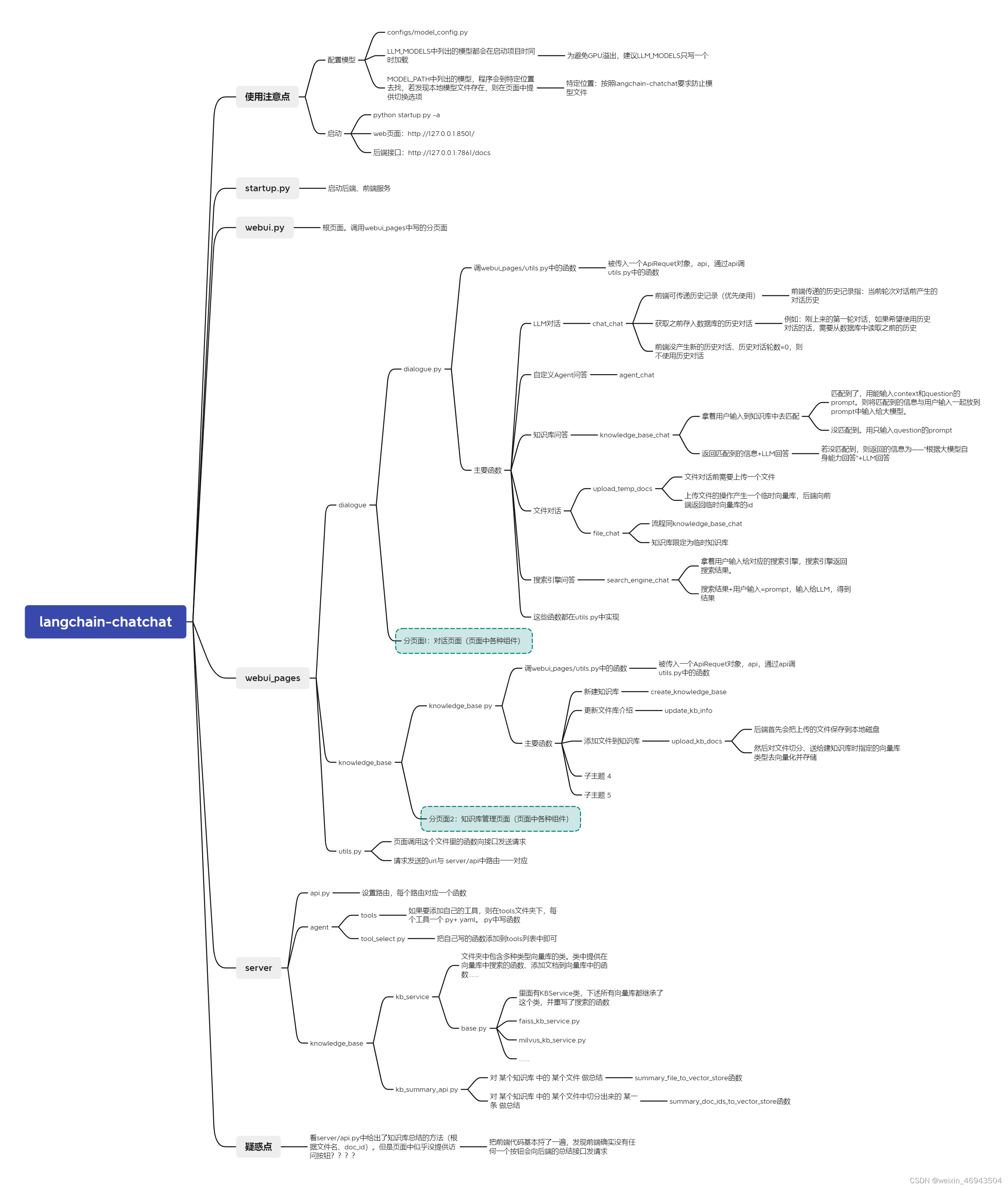
langchian-chatchat代码结构
- web页面:http://127.0.0.1:8501/
- 后端接口:http://127.0.0.1:7861/docs
部署
按照readme说的来就好
- 0.2.10版本有点bug,使用0.2.9版本。
模型
- Qwen 14B
- Qwen 72B的int4模型
- Qwen 34B的1.5版本
- 在config/model_config.py中添加新模型
测试(Qwen 14B)
GPU占用在30G左右
问题1:一个文件,怎么样才能让大模型检索得到
1. 调整文本分割(默认阈值为0.60)
- 单段文本最大长度:100
相邻文本重合长度:50
结论:能检索到
知识库效果

知识库问答效果:
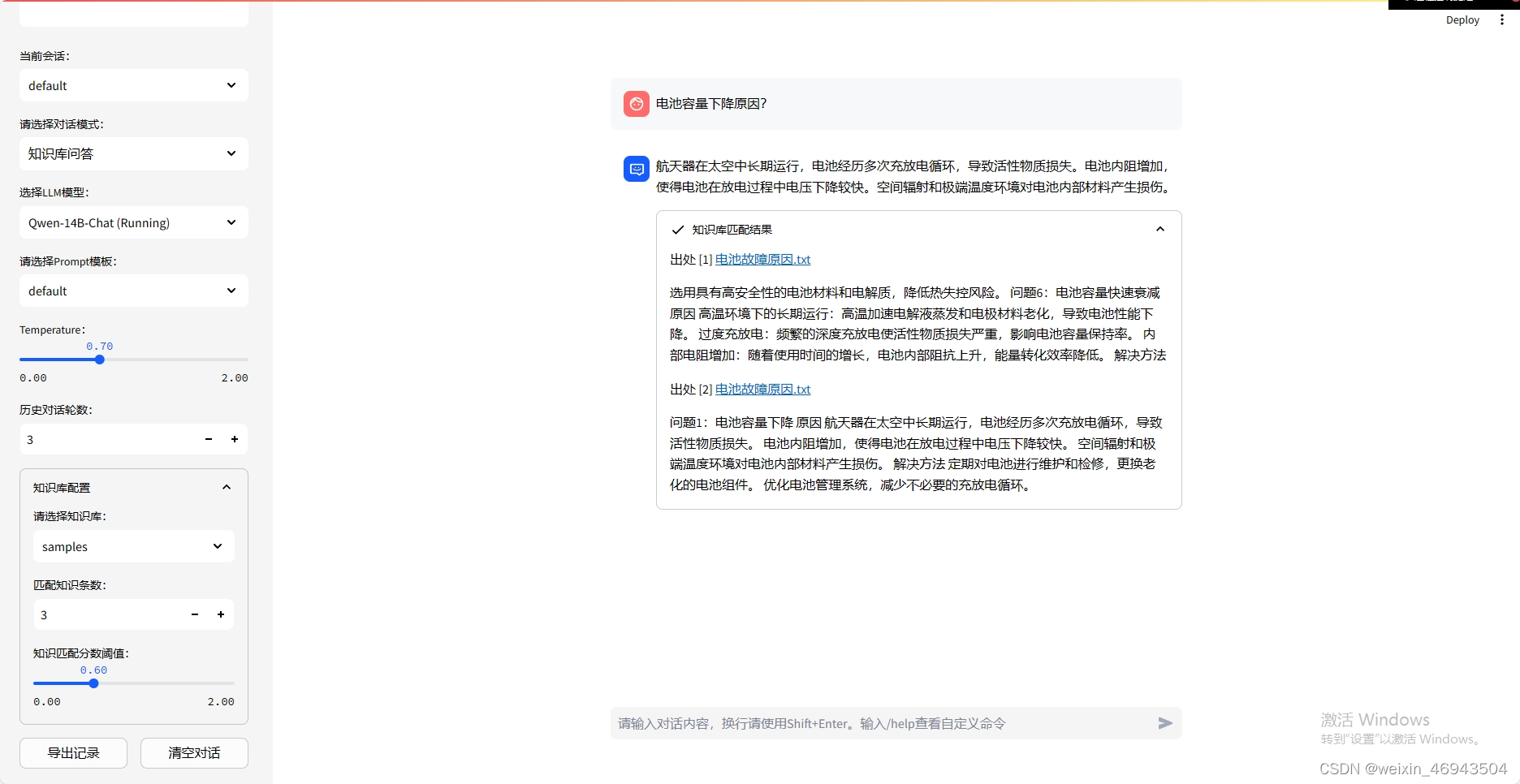
- 单段文本最大长度:250
相邻文本重合长度:50
结论:不能检索到
知识库效果

知识库问答效果
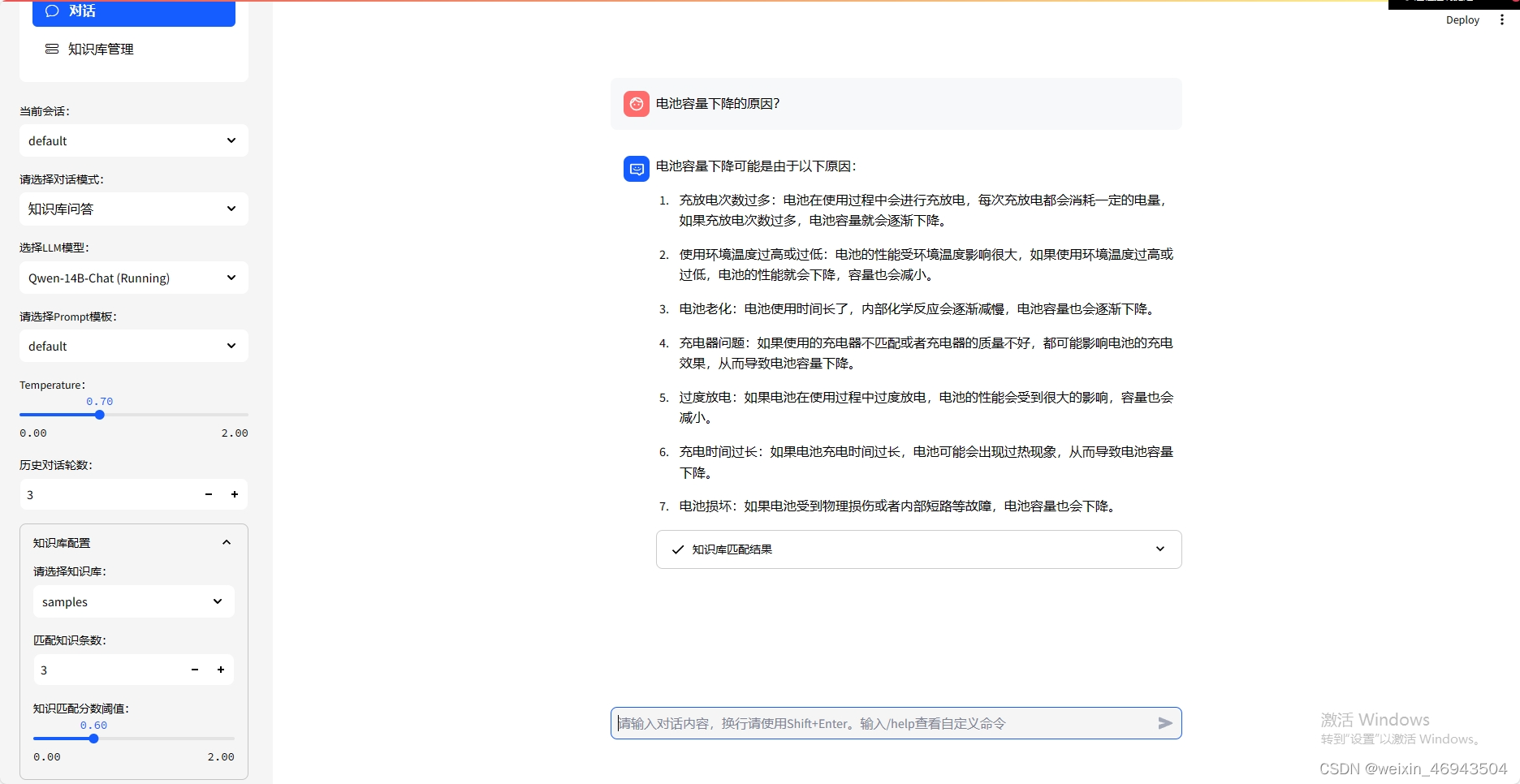
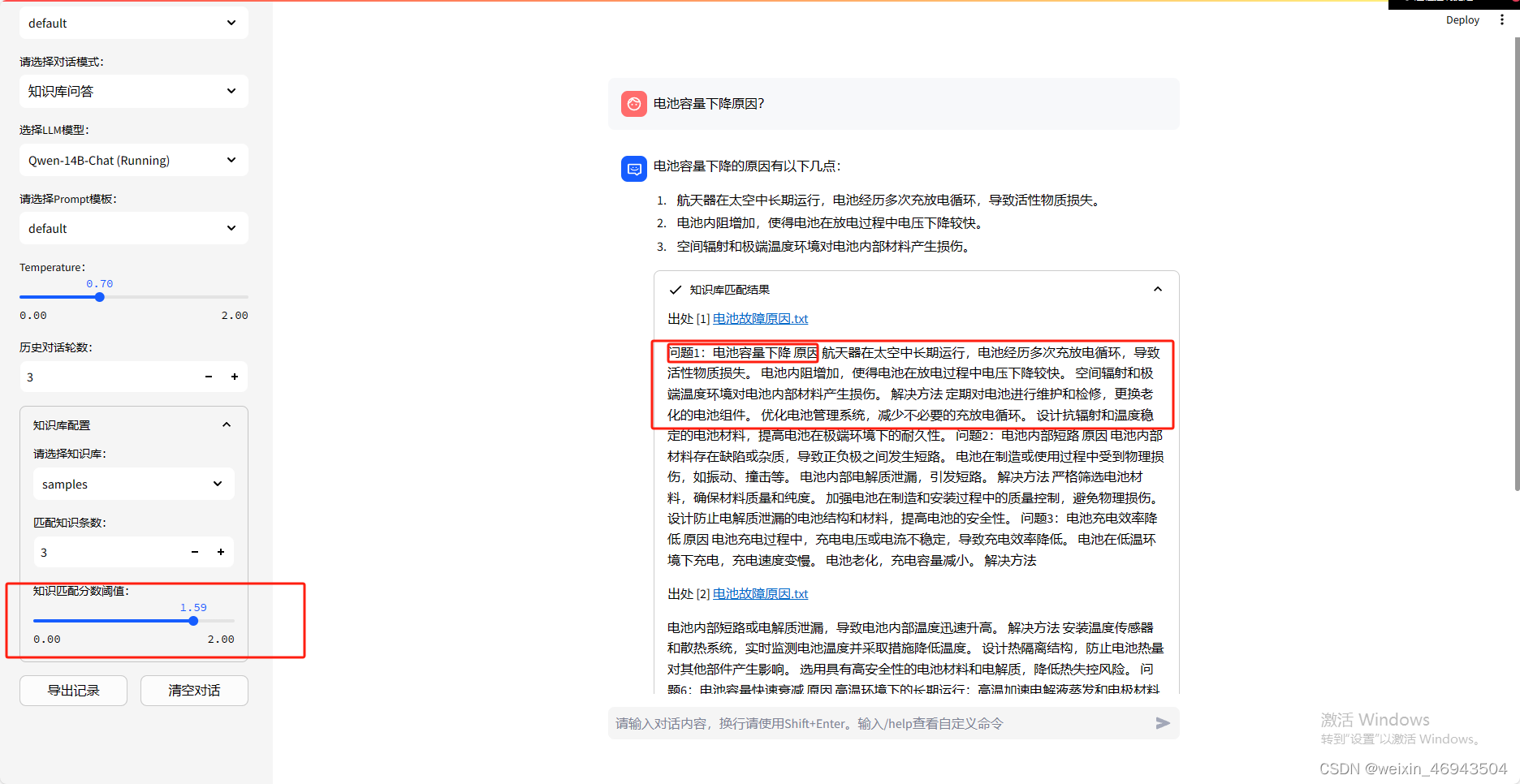
2. 调整文本匹配阈值(默认文本分割为250、50)
问答效果
- 阈值 1.5
结论:能找到
问题2:加了扰动之后,模型是否还能找到
加扰动后,知识库效果(单段最多100,重叠50)
原因被藏在很多无关内容中

问答效果
- 阈值 0.6
结论:找不到
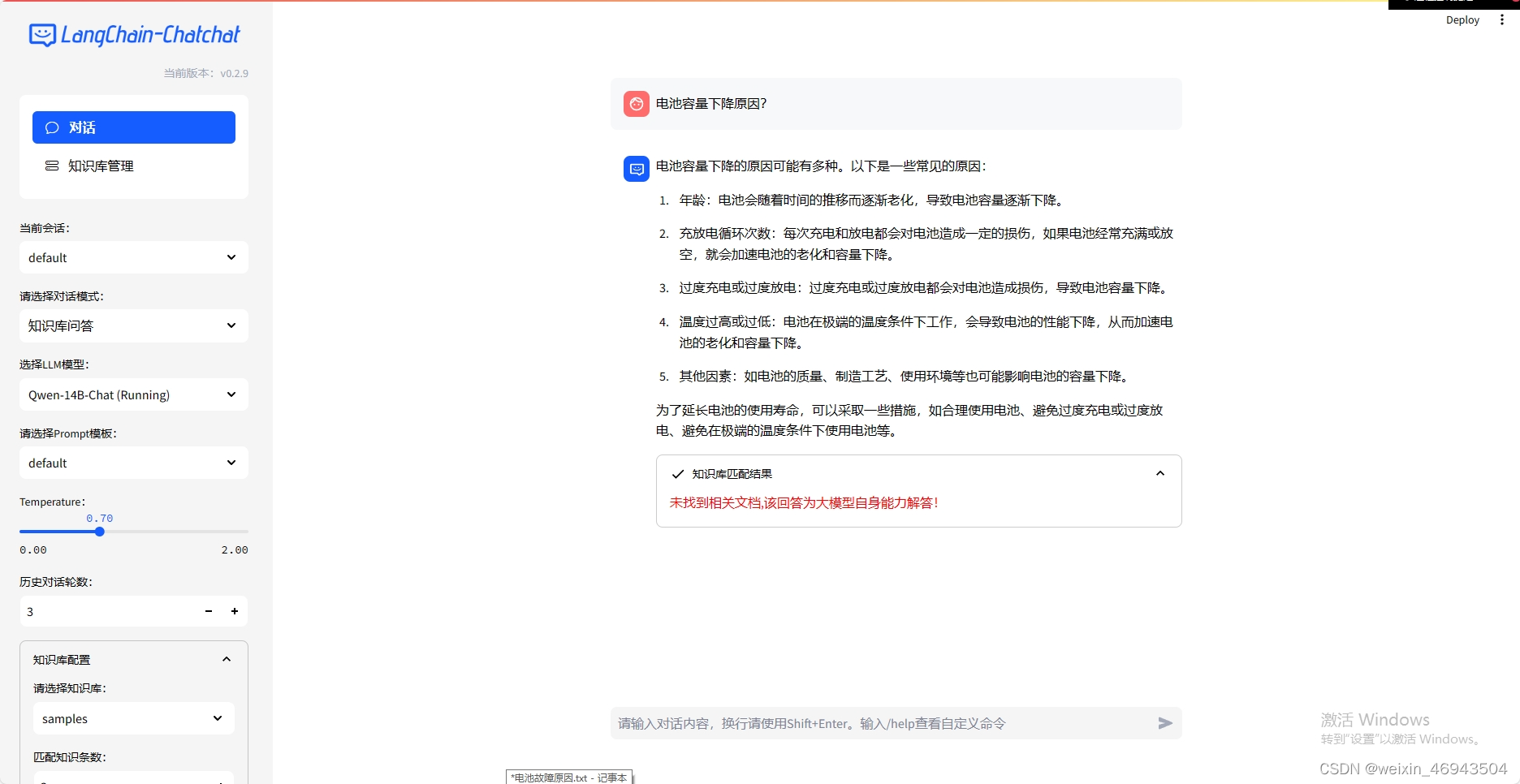
- 阈值 1.78
结论:能回答

问题3:读取表格的能力
1.能否对表格做问答
知识库效果
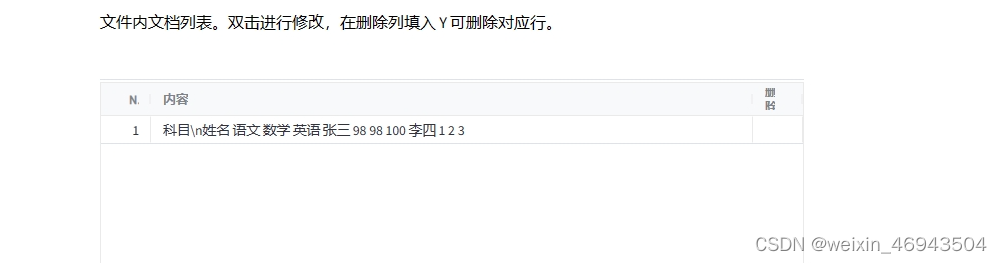
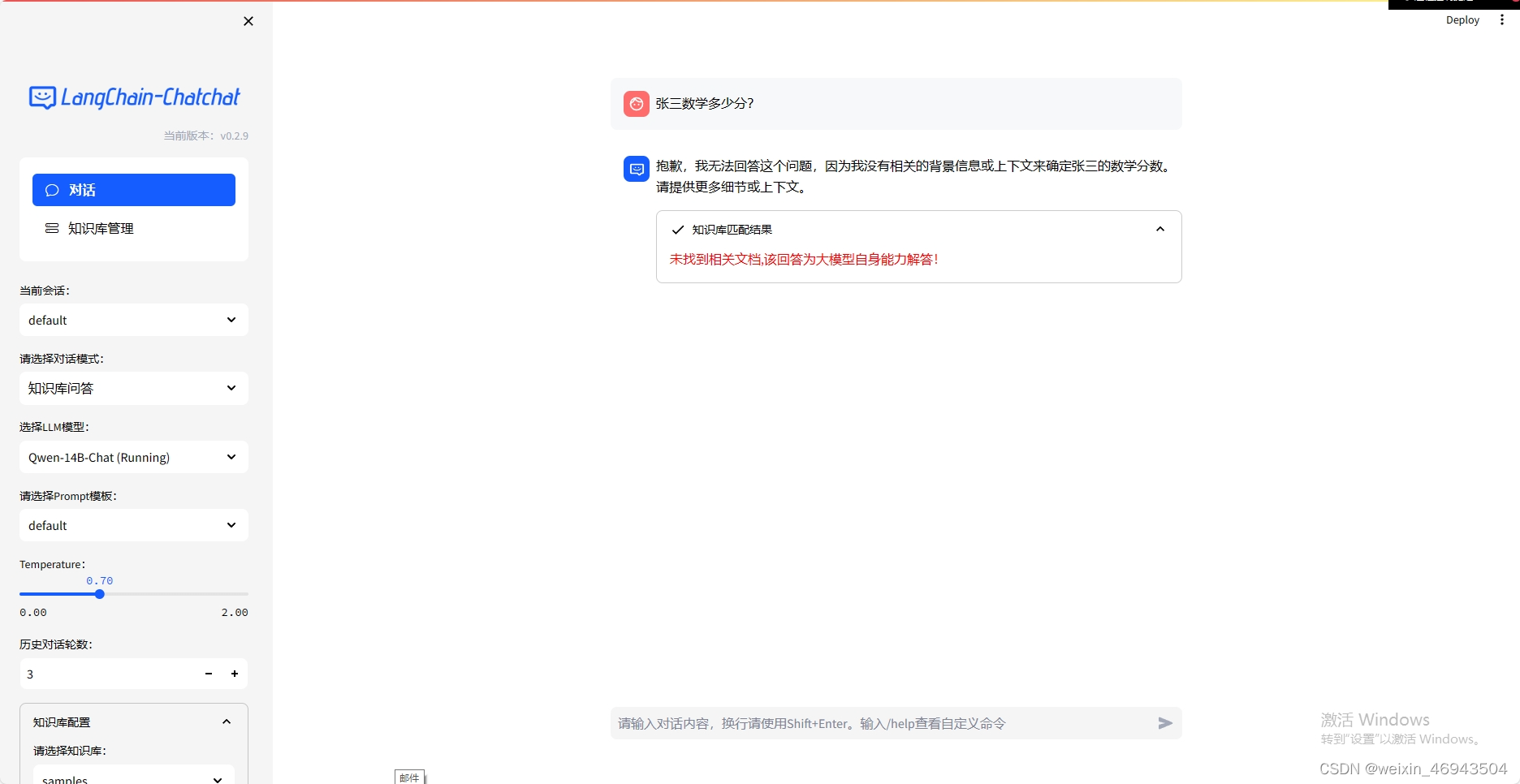
问答效果
- 阈值 0.60
不能回答
- 阈值:1.78
能回答
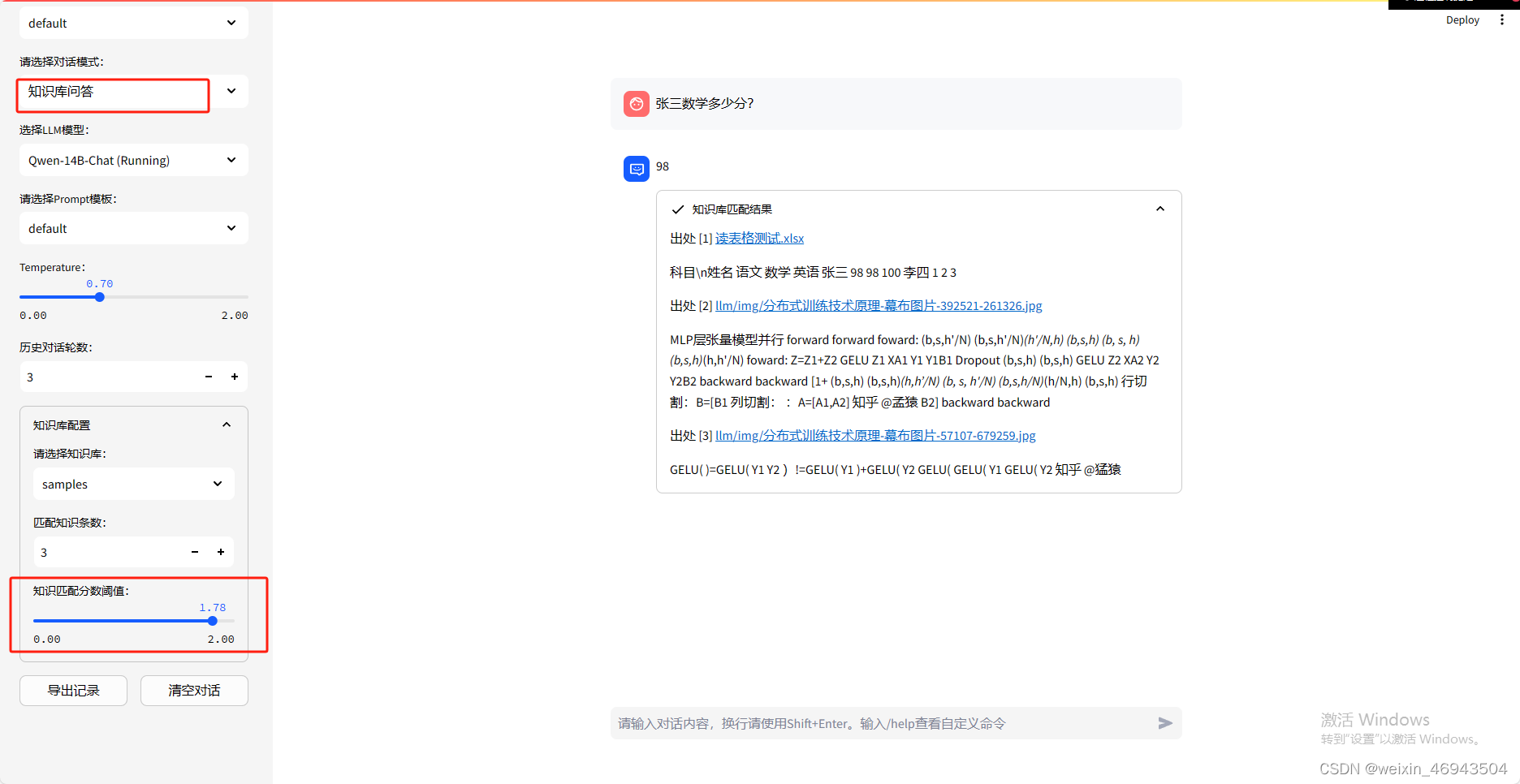
2.能否对表格做总结
知识库效果
问答效果
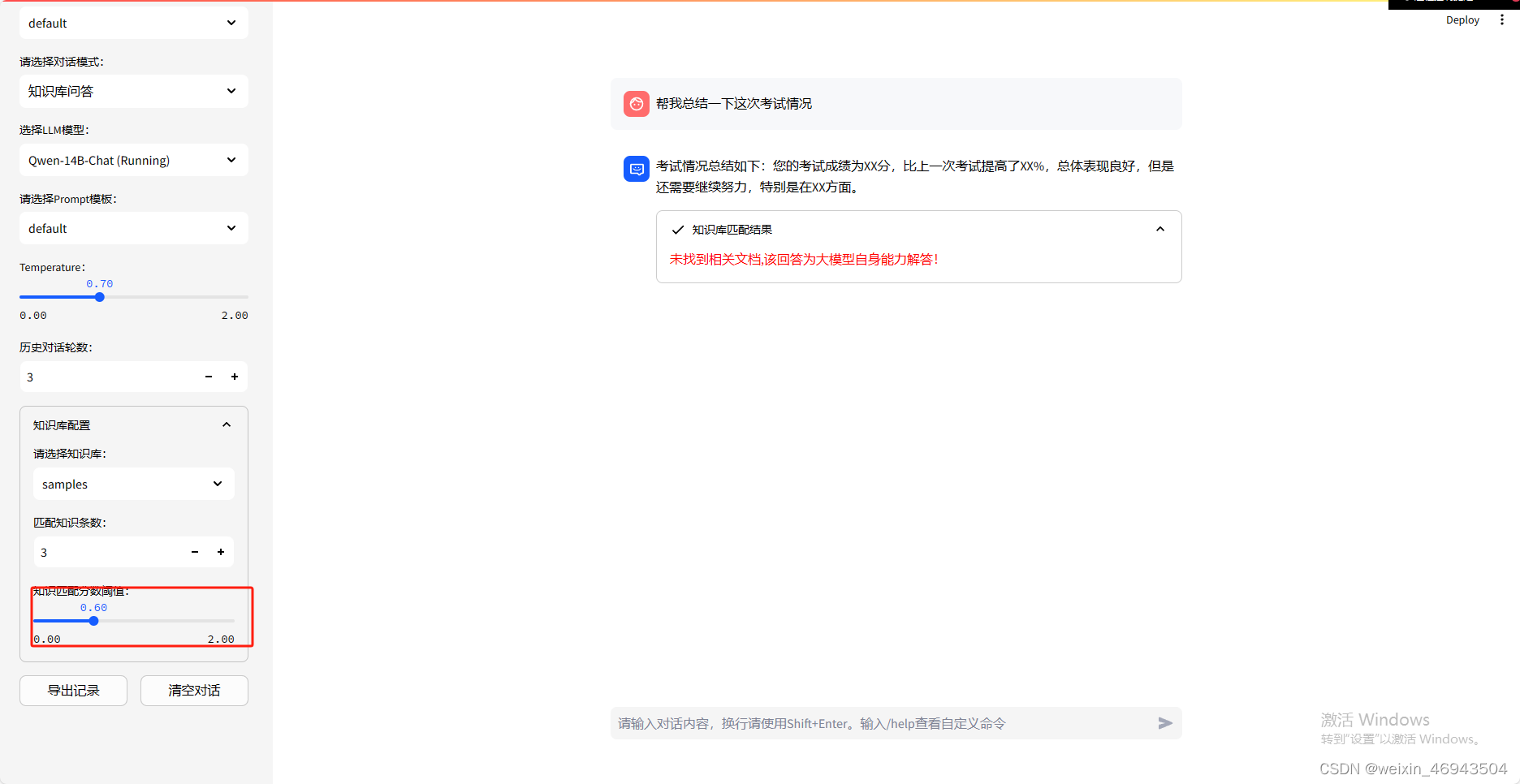
-
阈值0.60
结论:不能总结
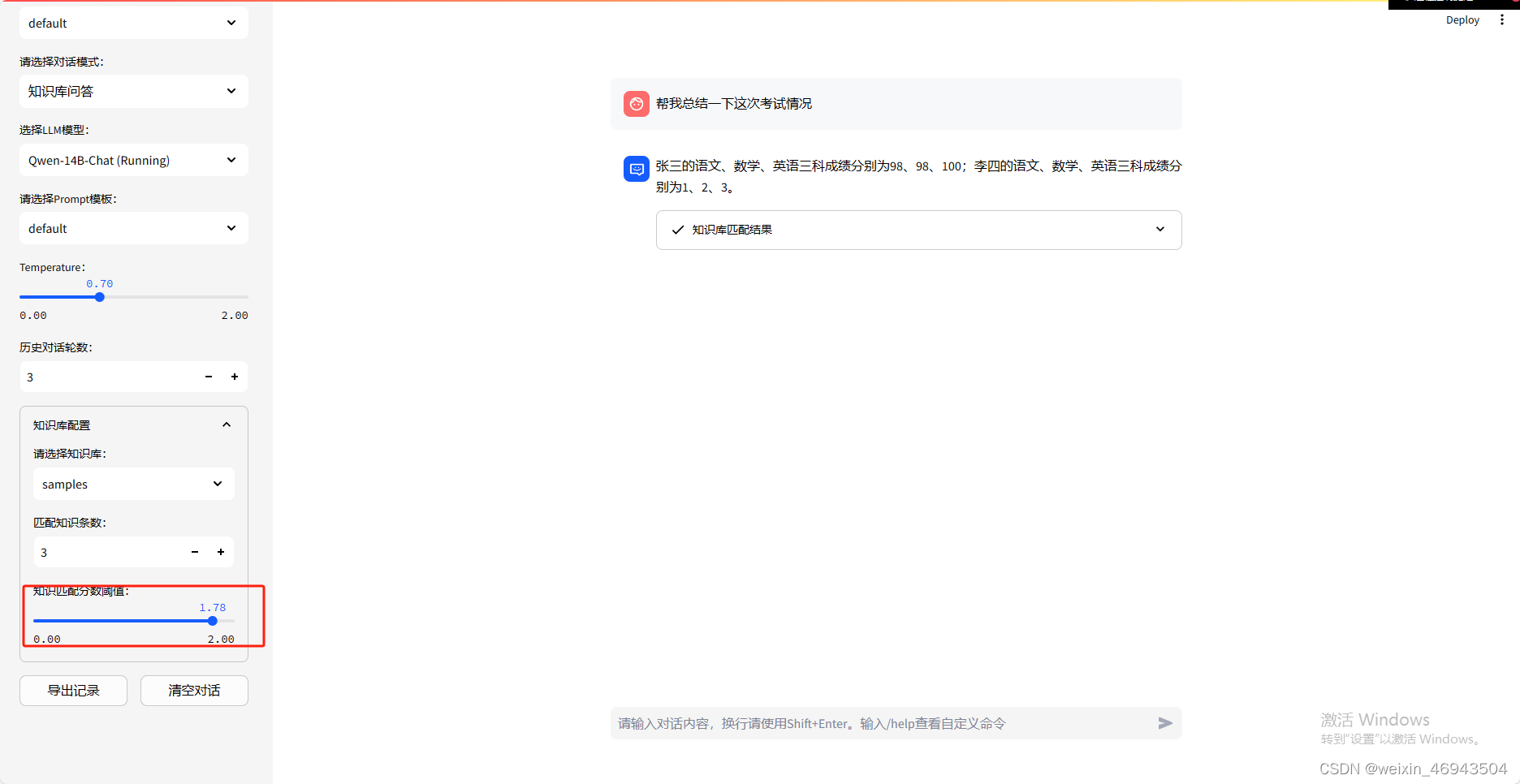
-
阈值 1.78
结论:能总结
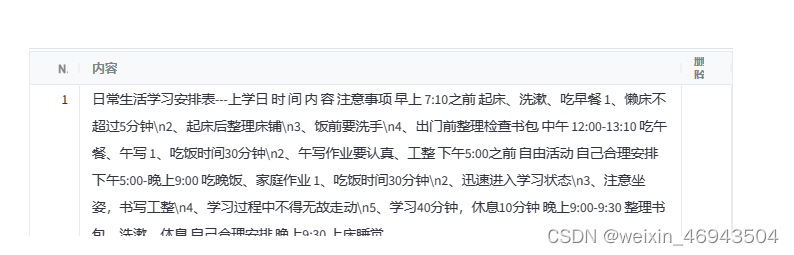
3.更复杂一些的表格
知识库效果(250、50)
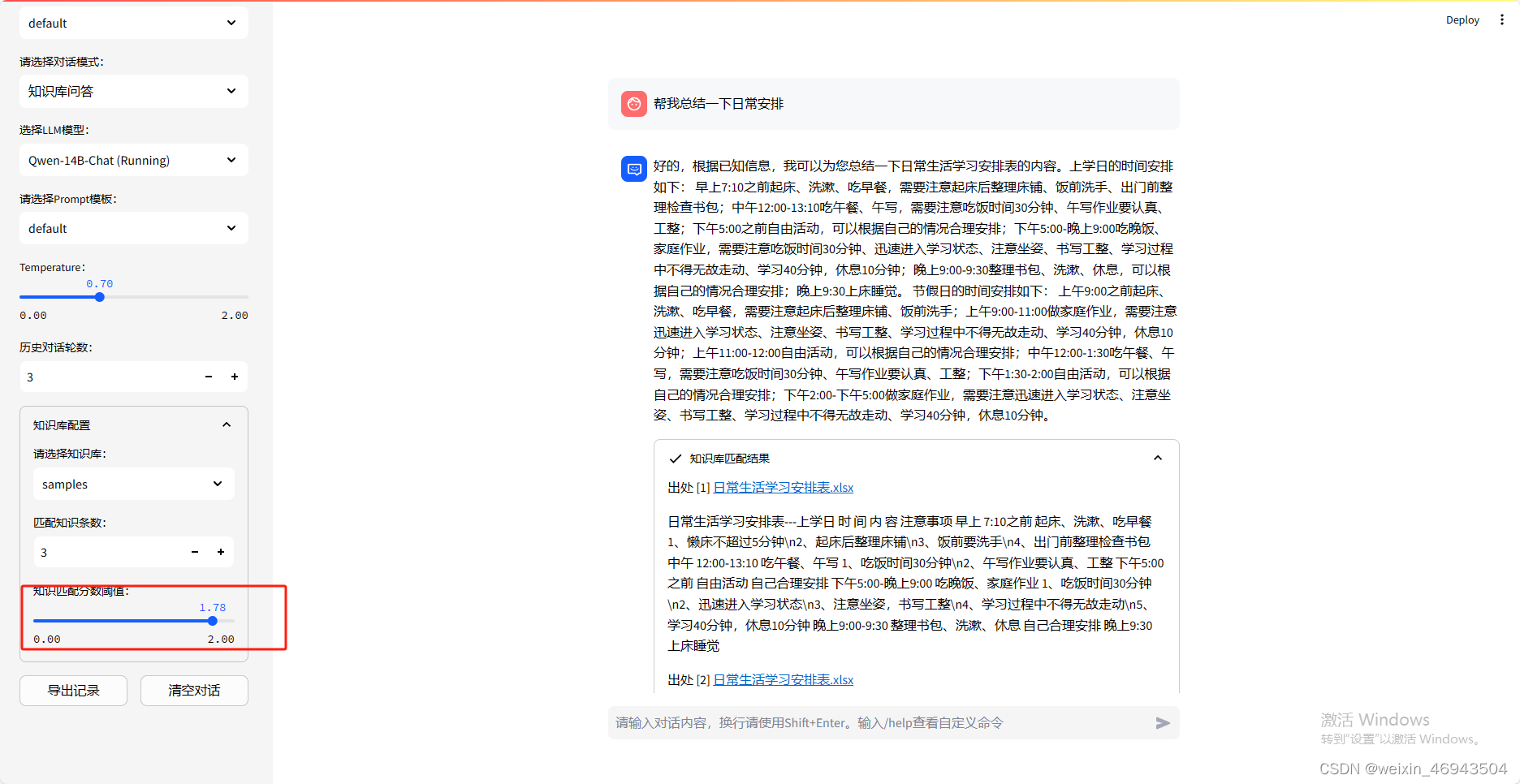
问答效果
- 阈值 1.78
结论:能总结
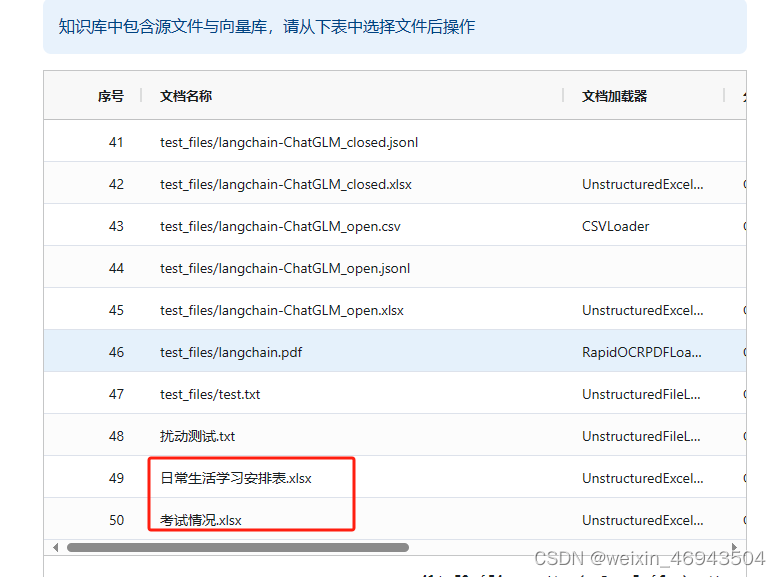
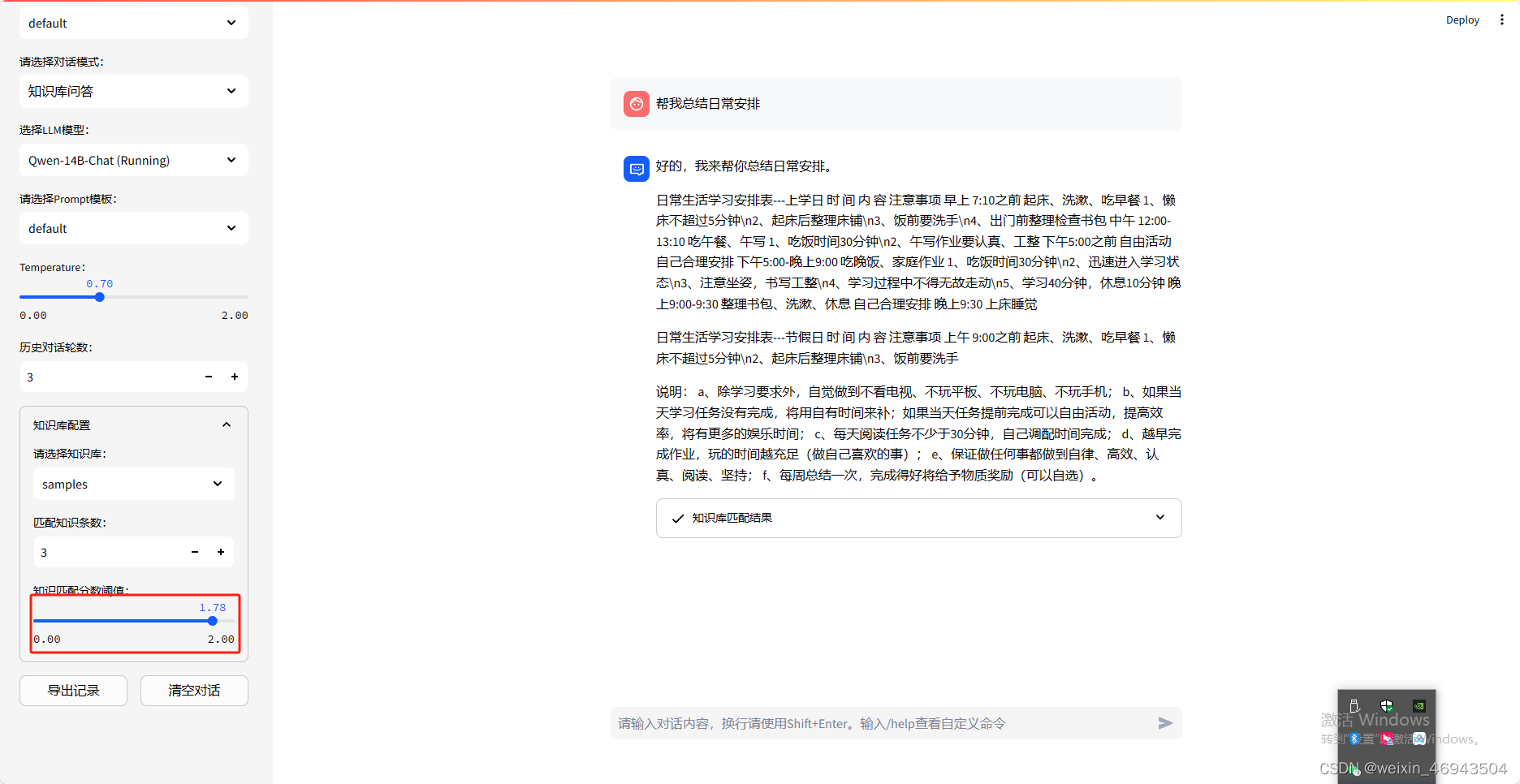
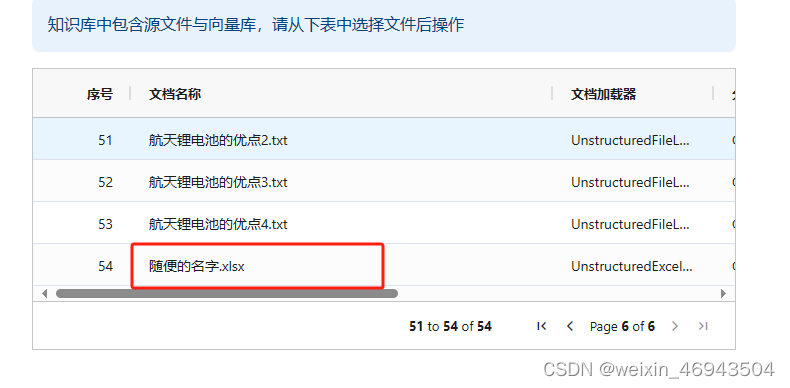
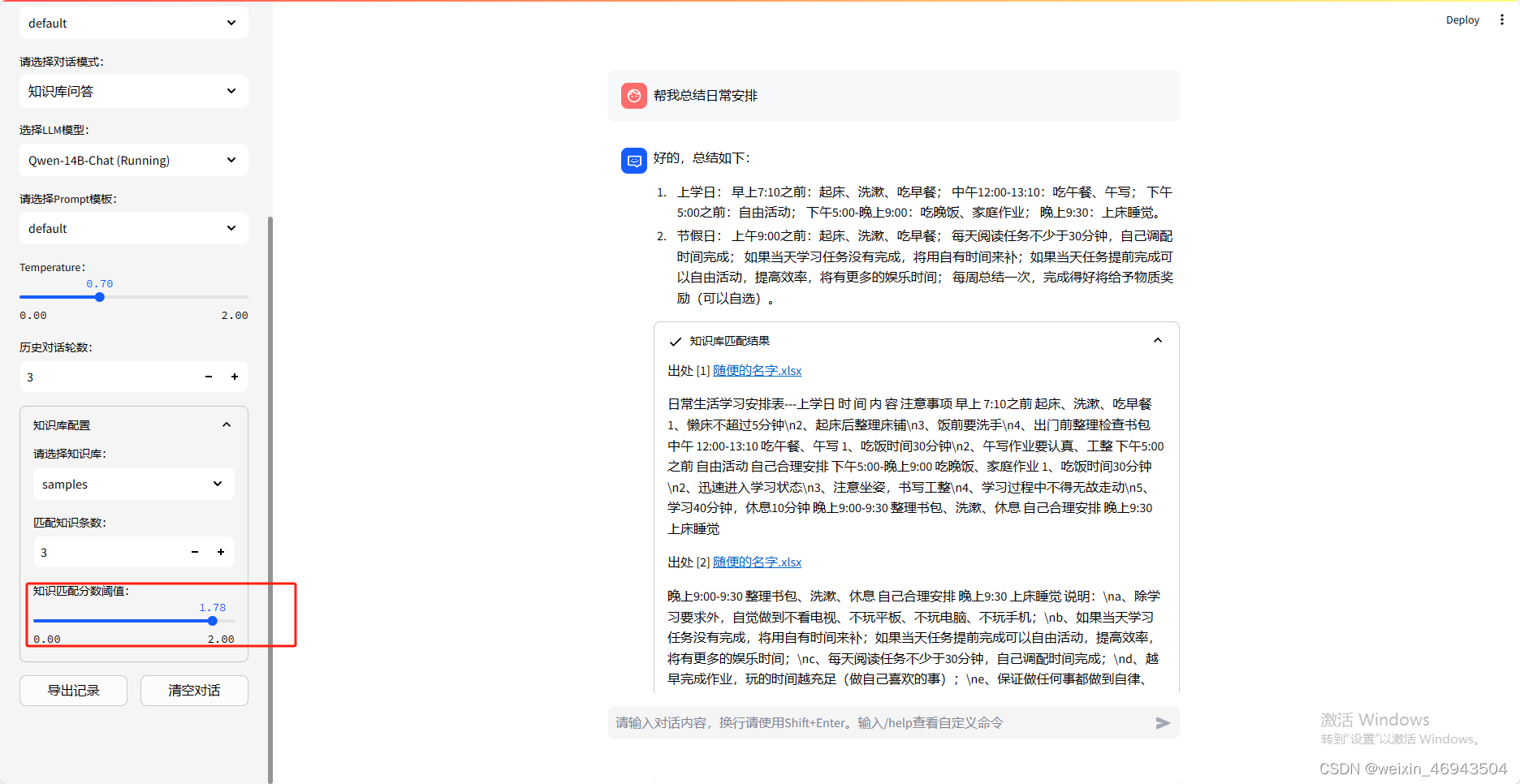
4.表格文件名是否有影响(默认阈值1.78)
结论:没有影响
- 情况1
知识库
知识库问答效果
- 情况2
知识库
知识库问答效果
5.表格翻转是否会还能回答(默认阈值1.78)
结论:能回答
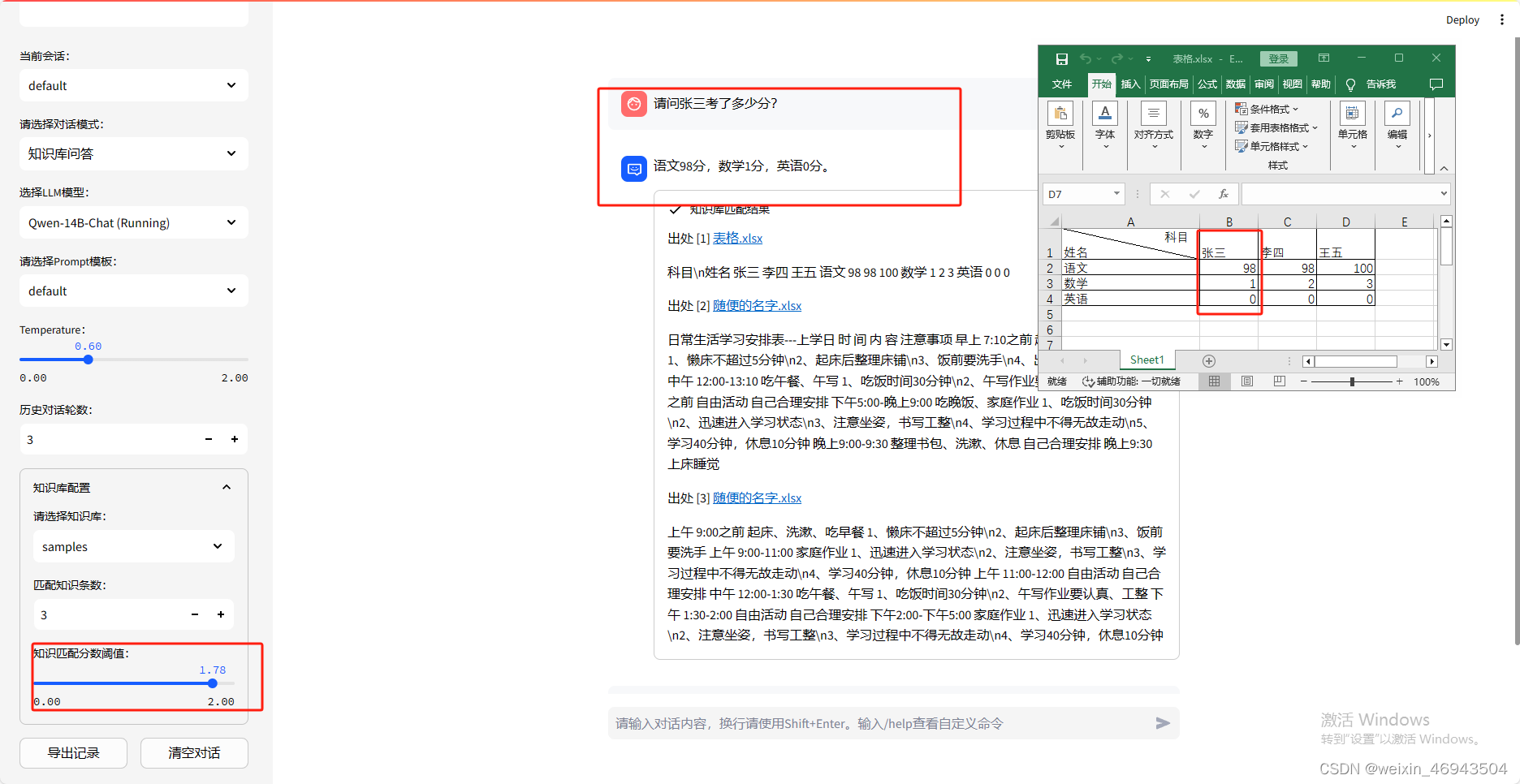
6.长表格、复杂表格问答(默认阈值1.78)
- 长表格
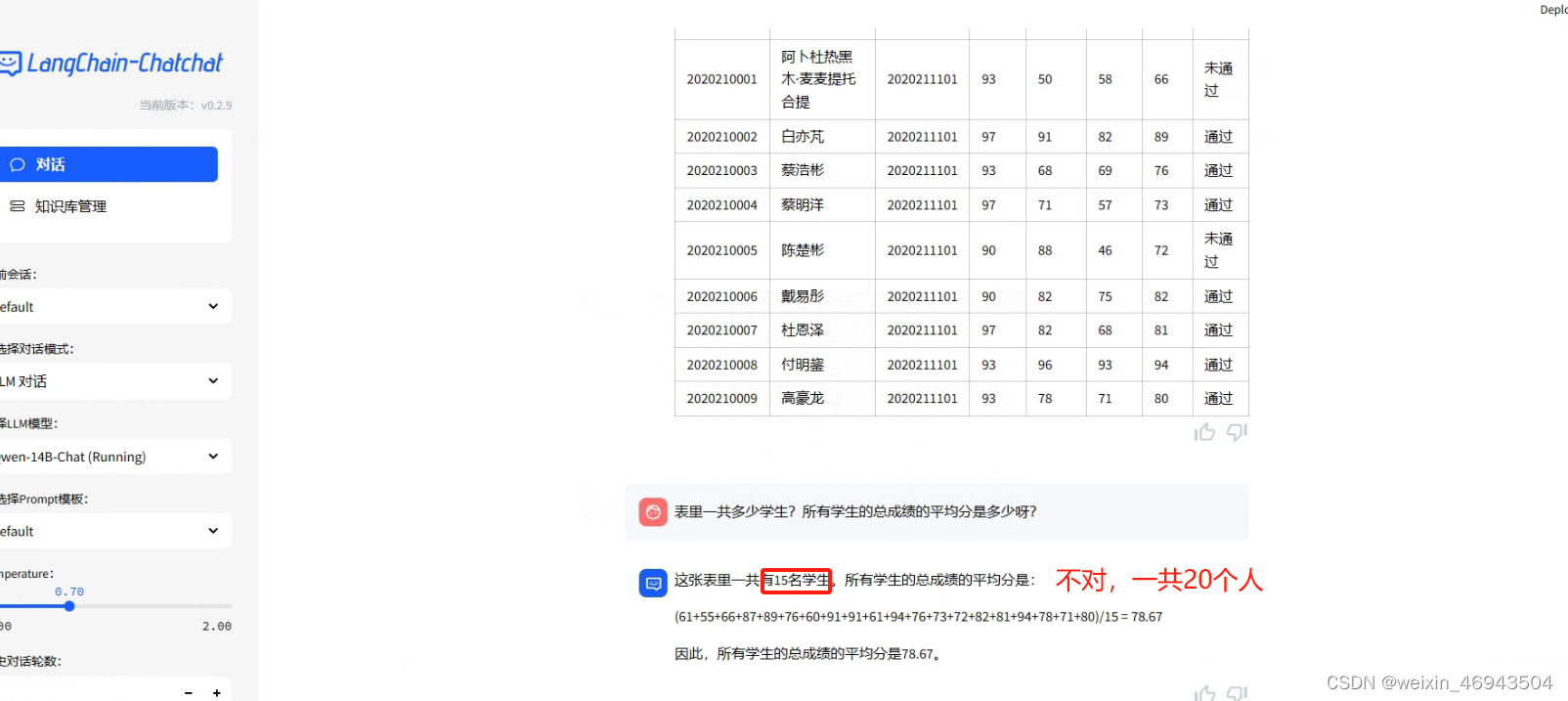
不能回答正确,对学生总数类的问题回答错误可能是由于能拿到的信息条数有限,得不到所有数据
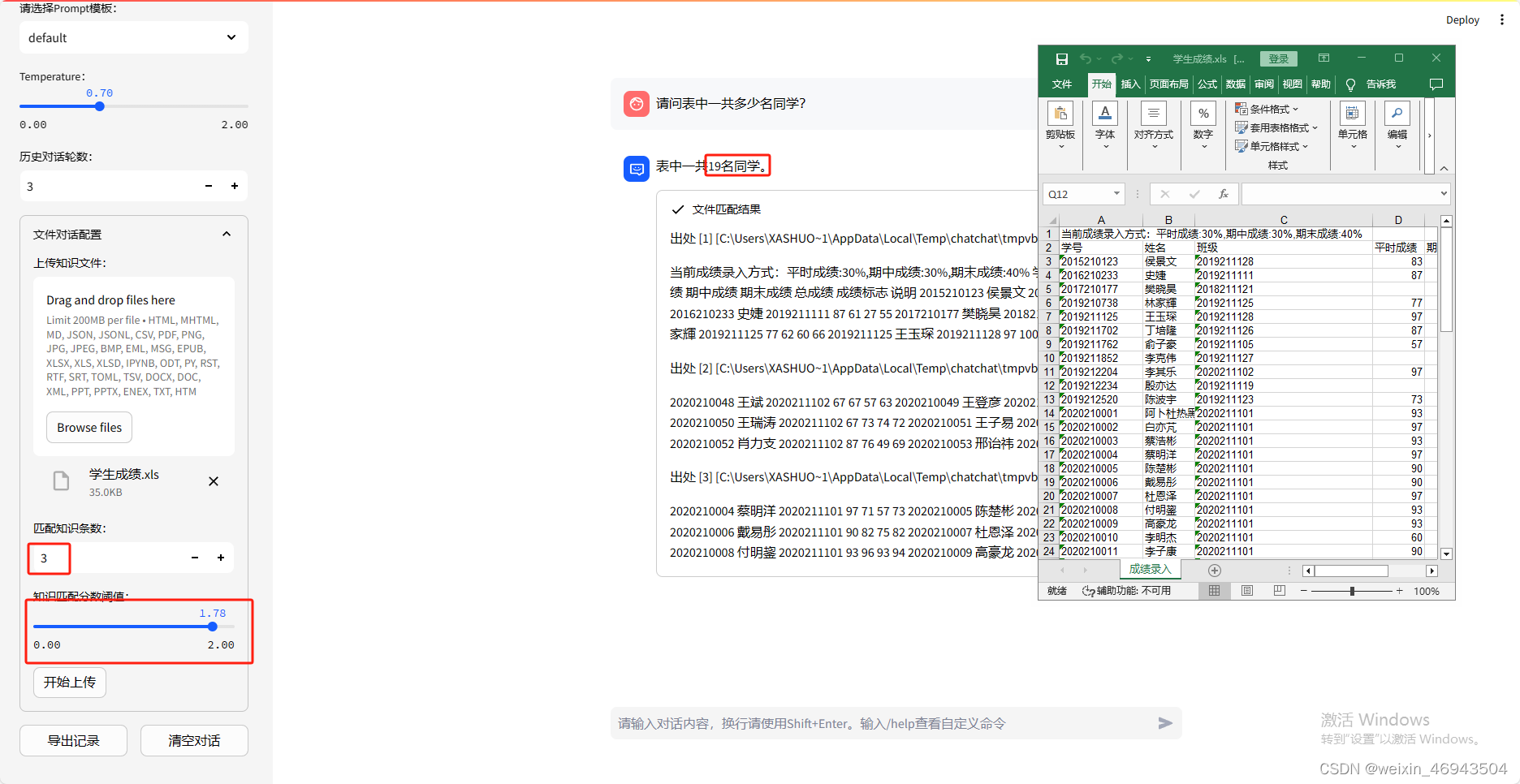
- 提问1:表中一共多少名同学
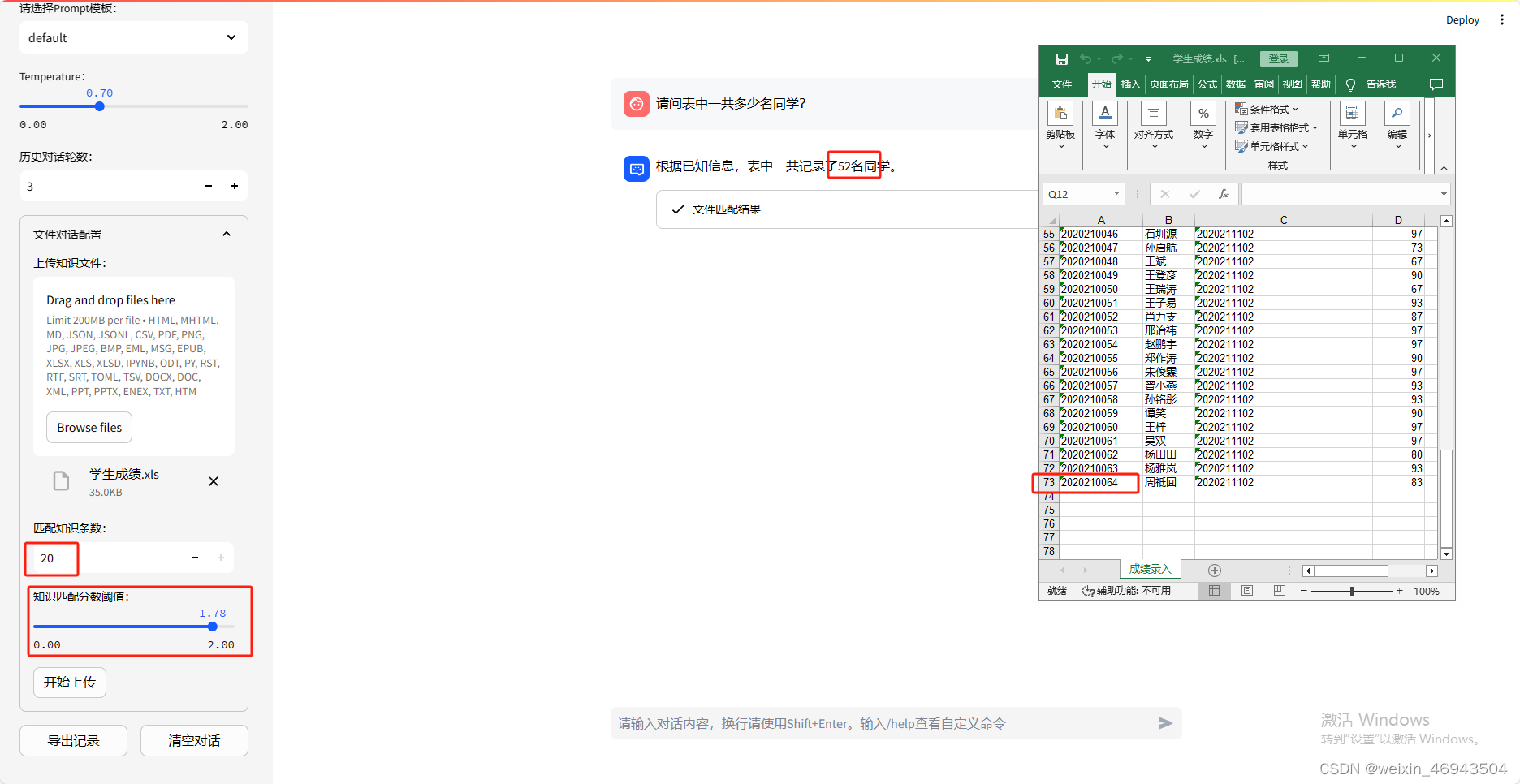
将信息条数调至最大(20条)回答仍错误
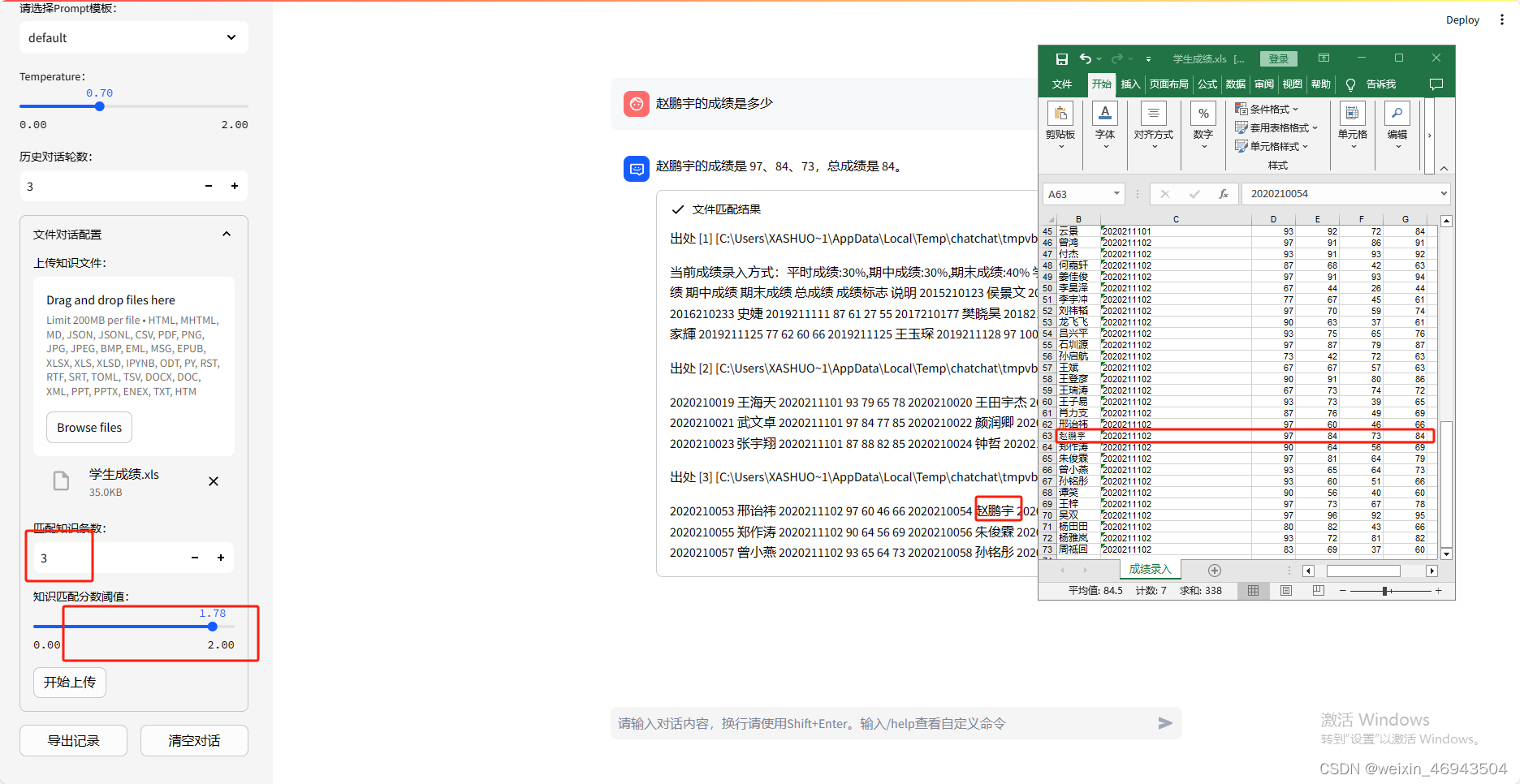
- 提问2:xxx同学成绩是多少?
回答正确
- 复杂表格
不能找到答案
- 提问1:课程名称是什么?教师是谁?总结这门课情况
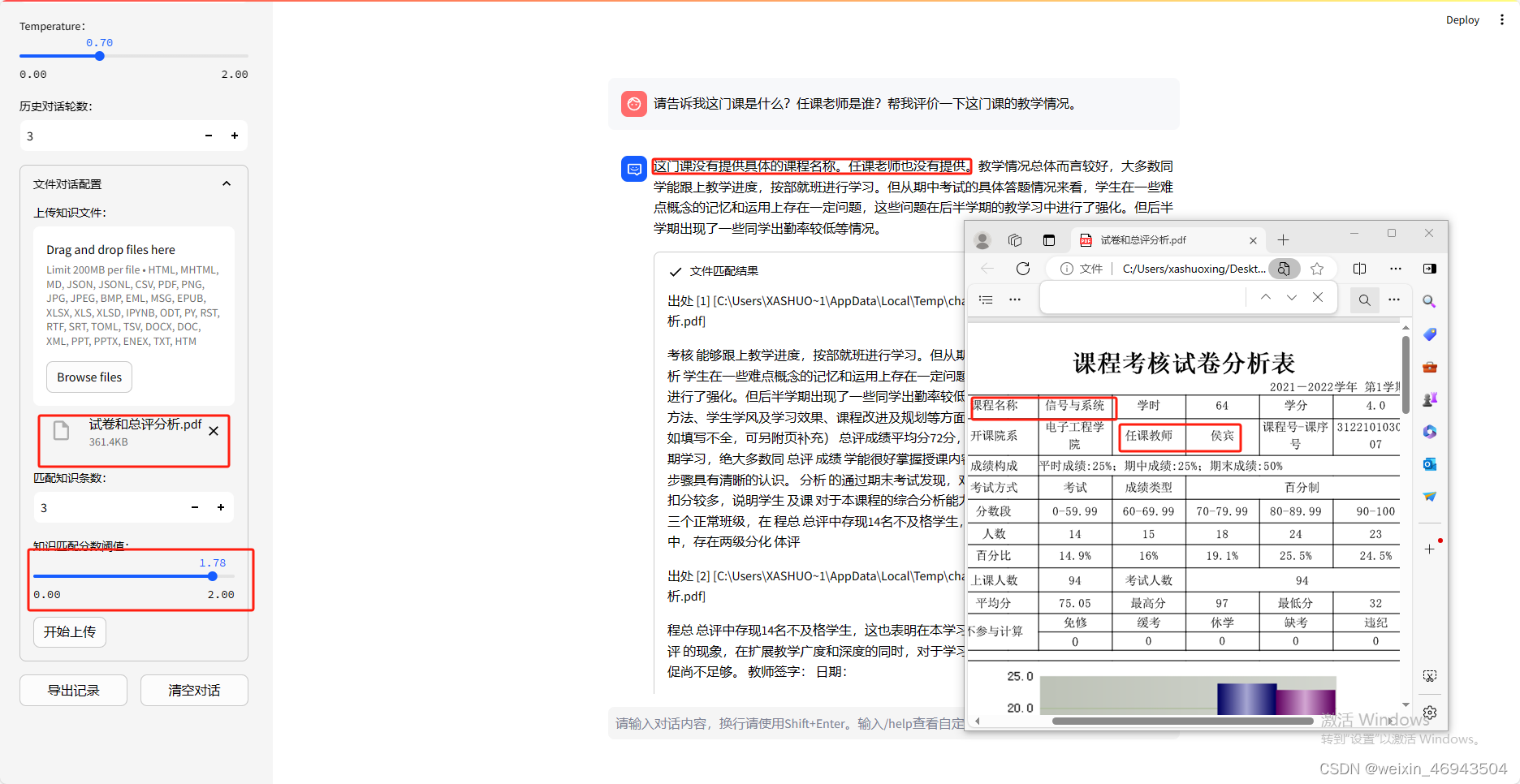
- 提问2:任课教师是谁?
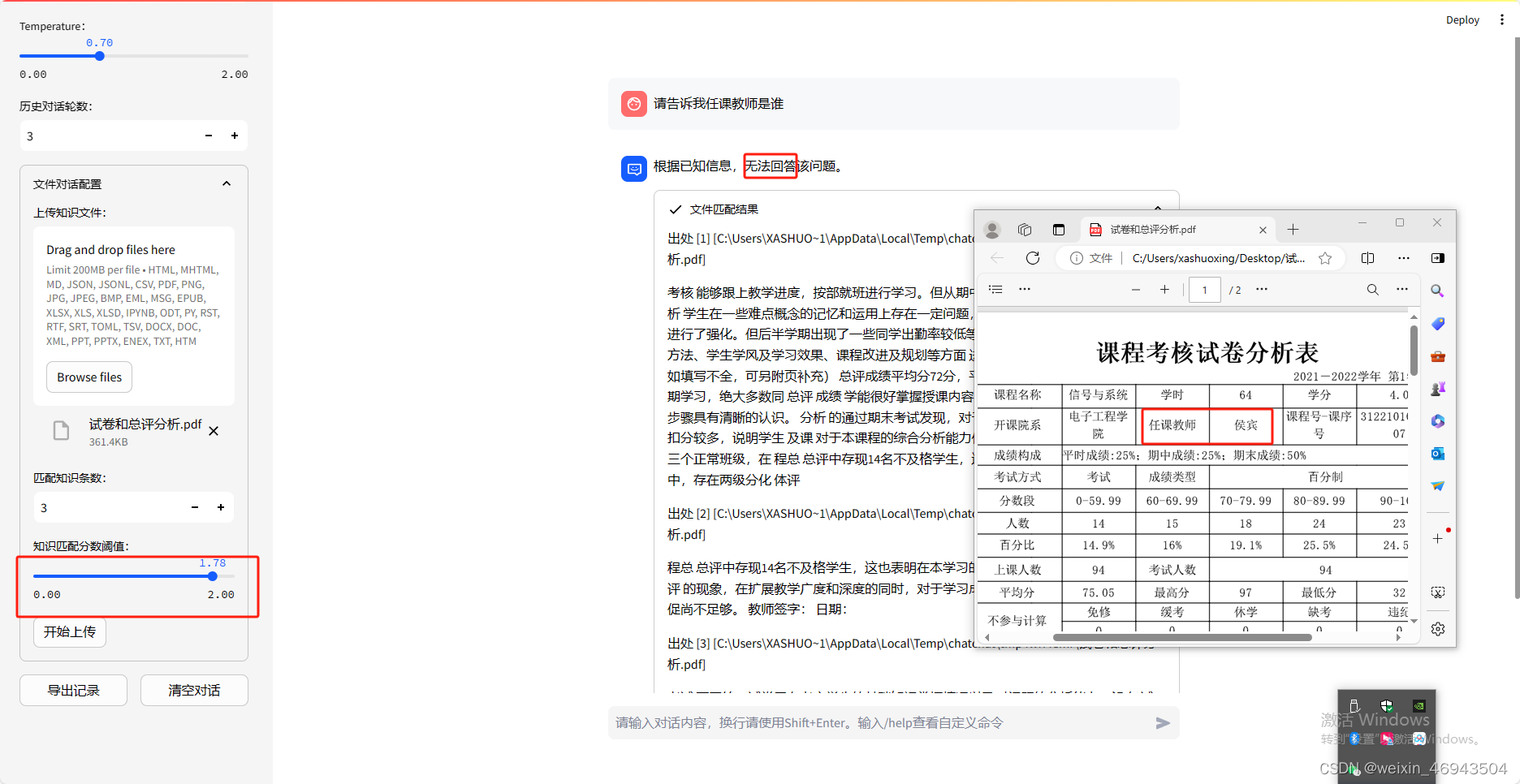
- 提问3:这门课叫什么?
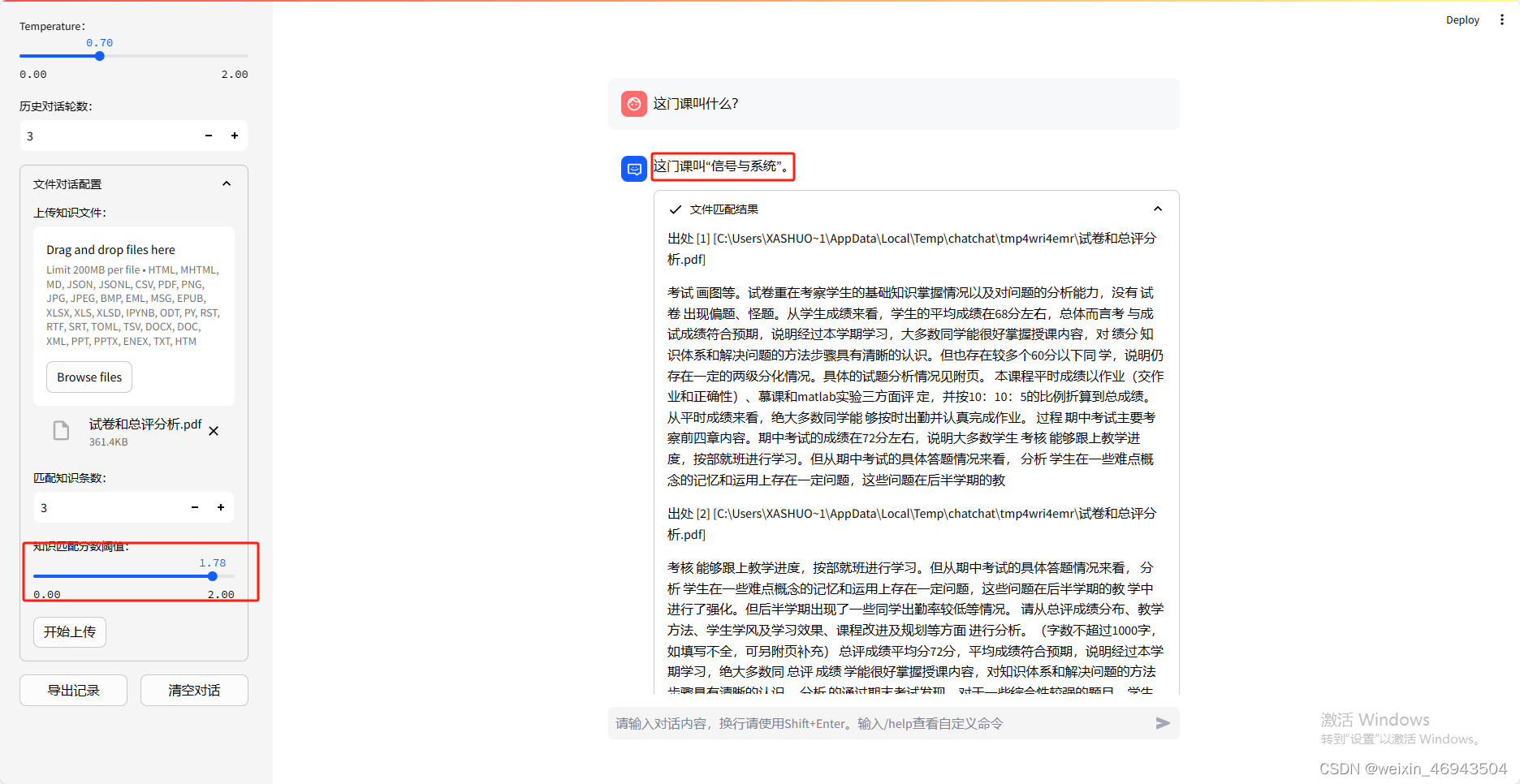
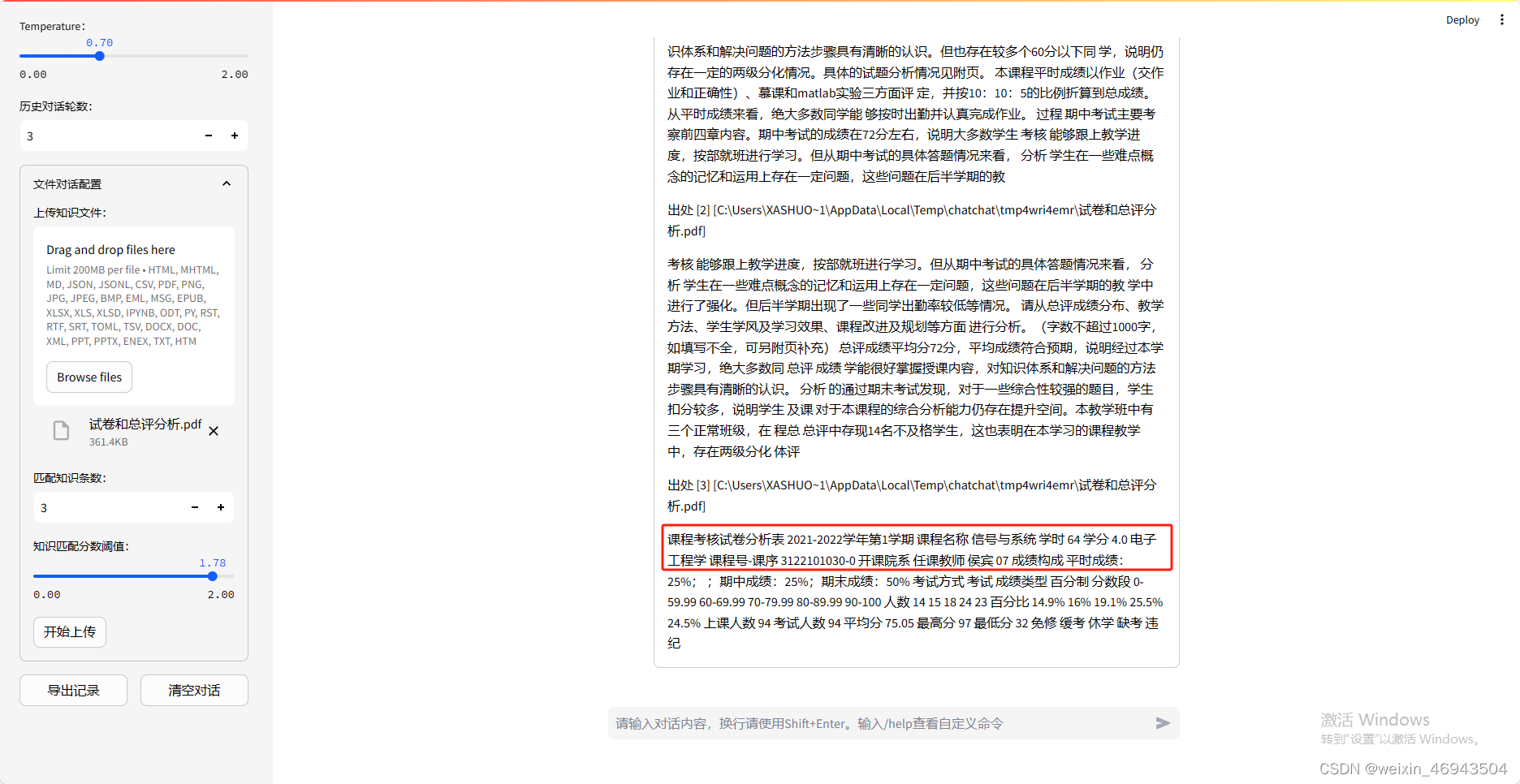
- 提问4:帮我总结一下这个班的情况,例如:班级一共多少人、平均分是多少、期中期末表现如何
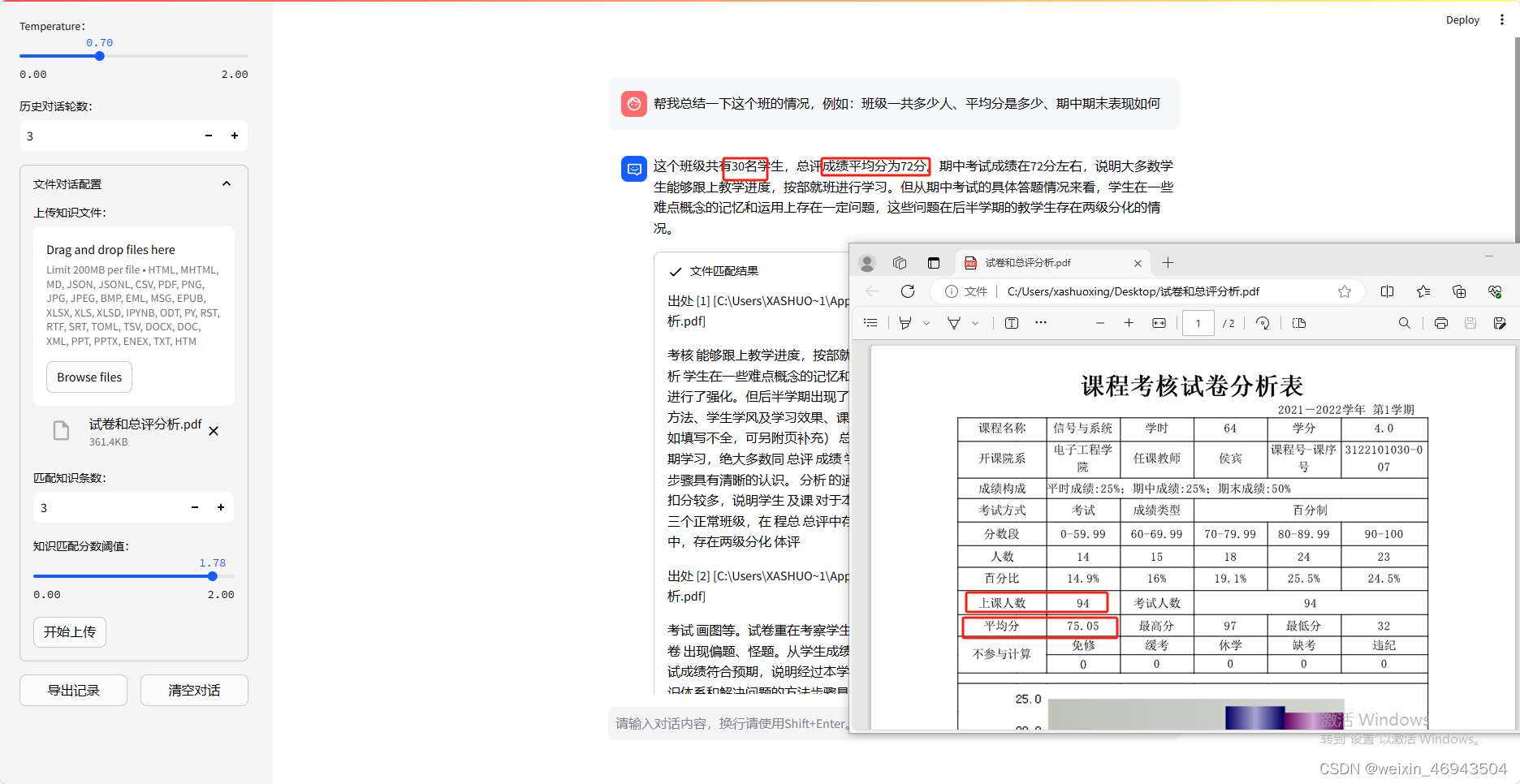
问题4:知识库对话模式下,支持指定文件名?
结论:不行
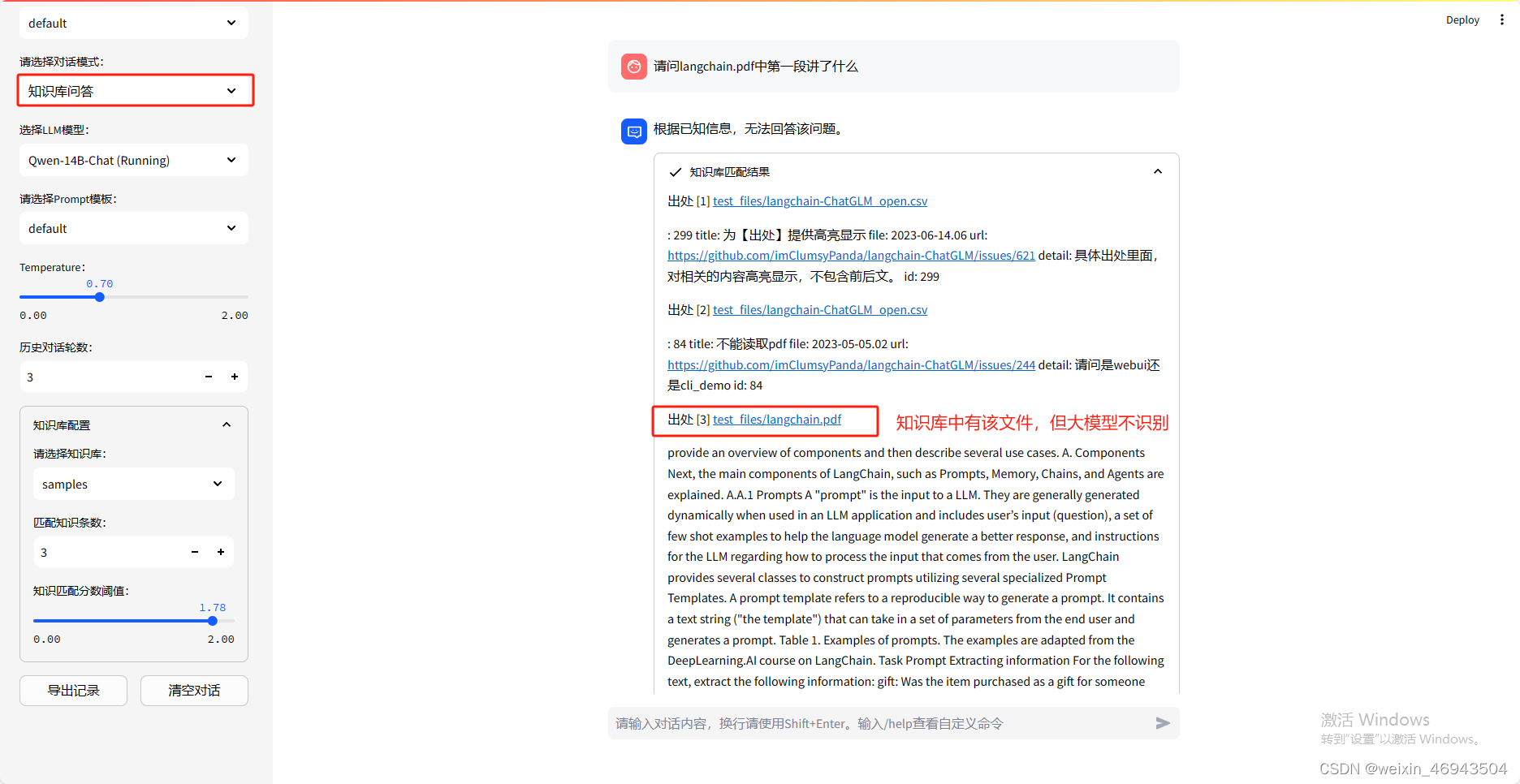
问题5:文件对话模式下,支持文件名?
1. 指定文件名去做总结
结论:不支持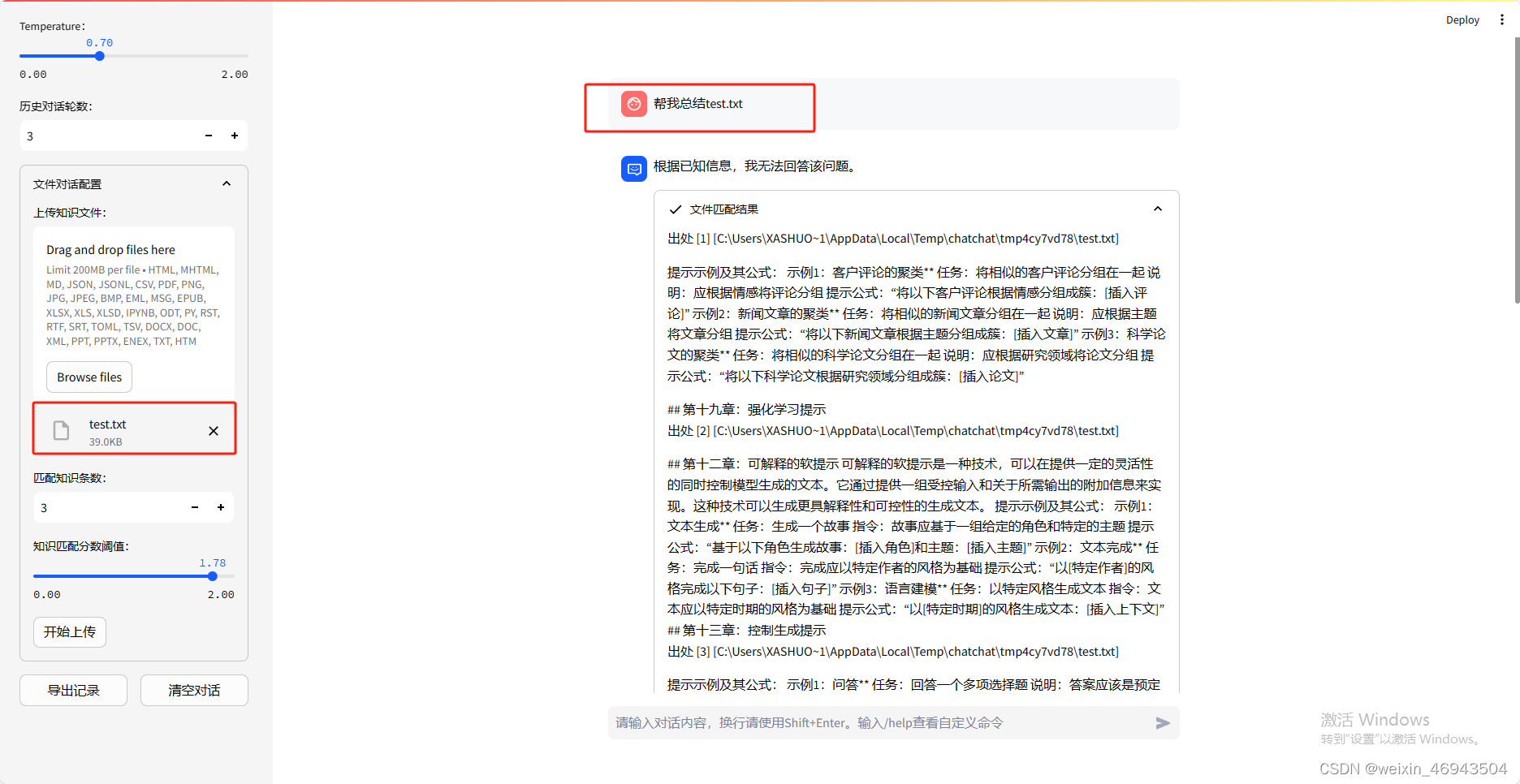
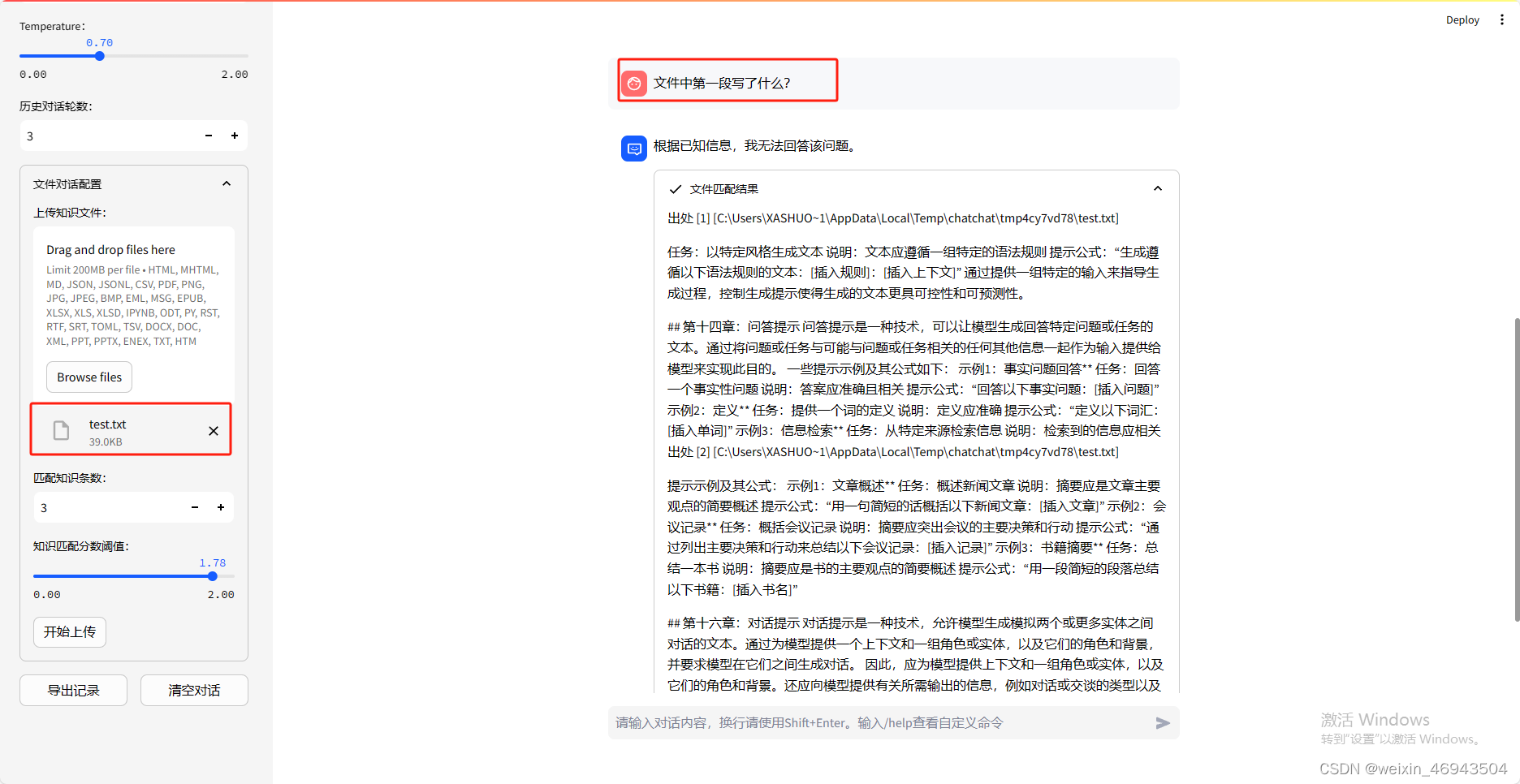
2. 指定文中某一段
结论:不支持
问题6:Qwen是否具备latex读取能力
1. latex形式的图
一个折线图,横坐标是人名,纵坐标是成绩
\documentclass{article}
\usepackage{pgfplots}
\pgfplotsset{compat=1.17}
\begin{document}
\begin{figure}[h]
\centering
\begin{tikzpicture}
\begin{axis}[
width=12cm,
height=8cm,
xlabel={姓名},
ylabel={总成绩},
xtick=data,
xticklabels={
侯景文,
史婕,
樊晓昊,
林家輝,
王玉琛,
丁培隆,
俞子豪,
李克伟,
李其乐,
殷亦达,
陈波宇,
阿卜杜热黑木·麦麦提托合提,
白亦芃,
蔡浩彬,
蔡明洋,
陈楚彬,
戴易彤,
杜恩泽,
付明鋆,
高豪龙
},
x tick label style={rotate=45, anchor=east, align=center},
ytick={0,20,...,100},
ymin=0,
ymax=100,
grid=major,
ymajorgrids=true,
xticklabel style={font=\footnotesize}
]
\addplot[mark=*, color=blue] coordinates {
(侯景文, 61)
(史婕, 55)
(樊晓昊, 0)
(林家輝, 66)
(王玉琛, 87)
(丁培隆, 69)
(俞子豪, 60)
(李克伟, 0)
(李其乐, 91)
(殷亦达, 0)
(陈波宇, 61)
(阿卜杜热黑木·麦麦提托合提, 66)
(白亦芃, 89)
(蔡浩彬, 76)
(蔡明洋, 73)
(陈楚彬, 72)
(戴易彤, 82)
(杜恩泽, 81)
(付明鋆, 94)
(高豪龙, 80)
};
\end{axis}
\end{tikzpicture}
\caption{总成绩折线图}
\end{figure}
\end{document}
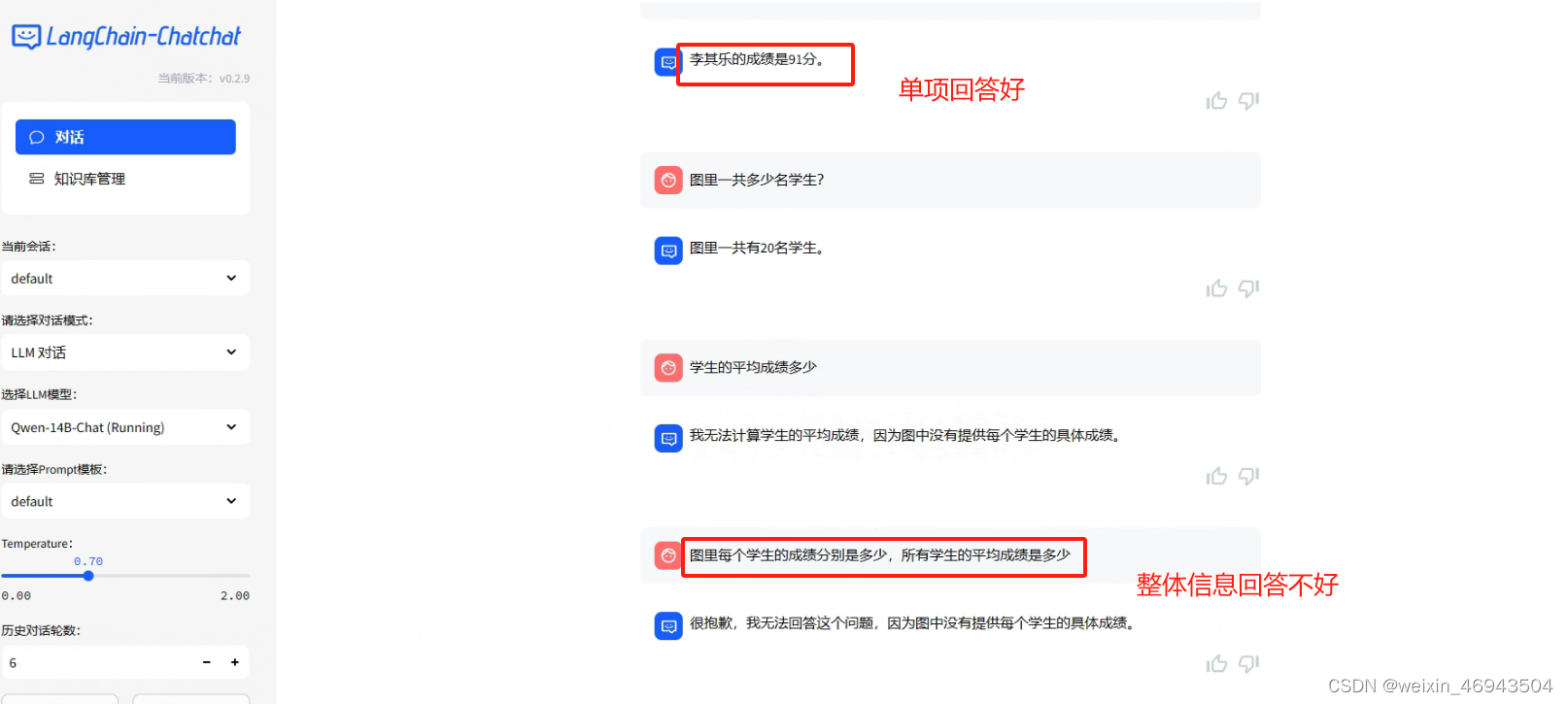
- 单项图问答
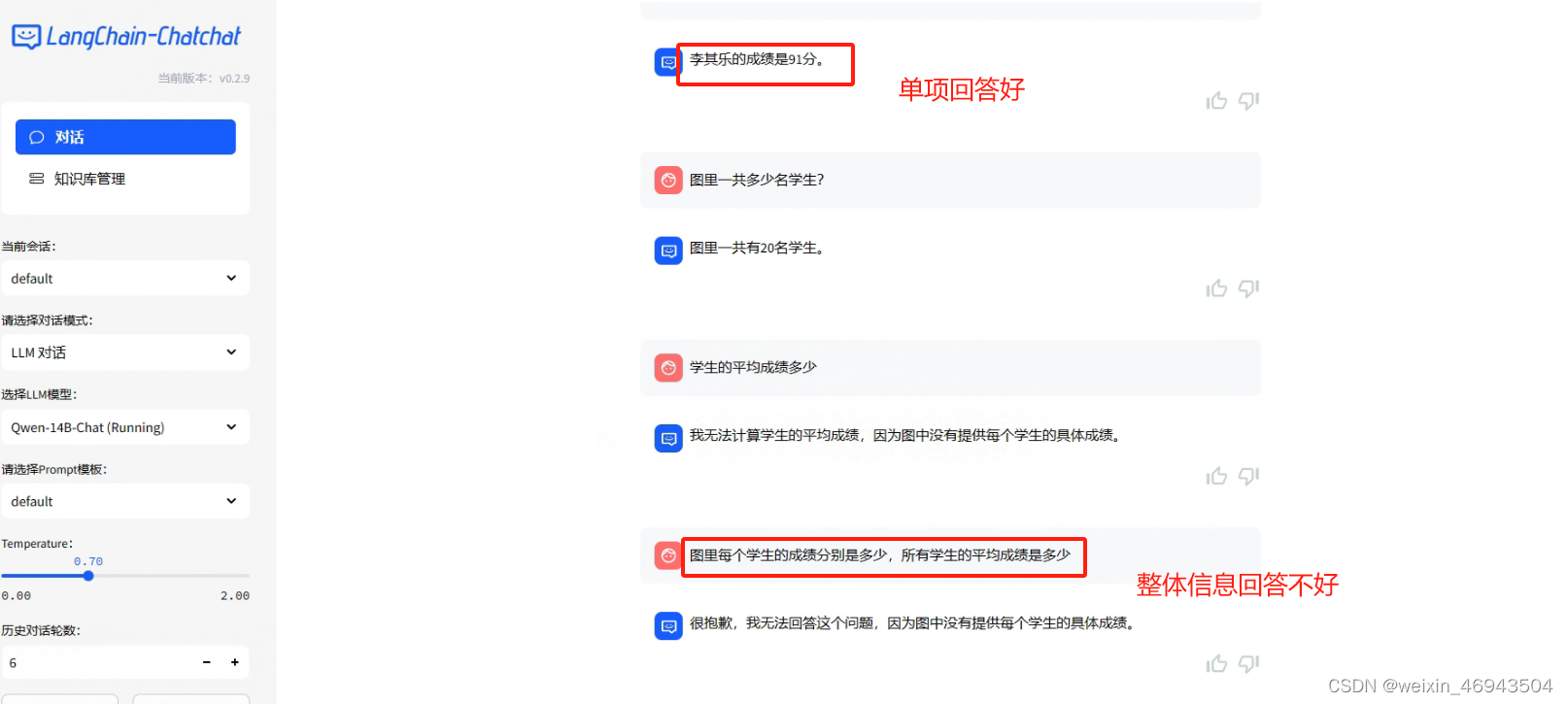
- 整体图信息
2. latex形式的表
\documentclass{article}
\usepackage{array}
\begin{document}
\begin{table}[h]
\centering
\begin{tabular}{|c|c|c|c|c|c|c|c|}
\hline
学号 & 姓名 & 班级 & 平时成绩 & 期中成绩 & 期末成绩 & 总成绩 & 成绩标志 \\
\hline
2015210123 & 侯景文 & 2019211128 & 83 & 52 & 51 & 61 & \\
2016210233 & 史婕 & 2019211111 & 87 & 61 & 27 & 55 & \\
2017210177 & 樊晓昊 & 2018211121 & & & & 0 & \\
2019210738 & 林家輝 & 2019211125 & 77 & 62 & 60 & 66 & \\
2019211125 & 王玉琛 & 2019211128 & 97 & 100 & 70 & 87 & \\
2019211702 & 丁培隆 & 2019211126 & 87 & 75 & 52 & 69 & \\
2019211762 & 俞子豪 & 2019211105 & 57 & 75 & 52 & 60 & \\
2019211852 & 李克伟 & 2019211127 & & & & 0 & \\
2019212204 & 李其乐 & 2020211102 & 97 & 94 & 83 & 91 & \\
2019212234 & 殷亦达 & 2019211119 & & & & 0 & \\
2019212520 & 陈波宇 & 2019211123 & 73 & 74 & 41 & 61 & \\
2020210001 & 阿卜杜热黑木·麦麦提托合提 & 2020211101 & 93 & 50 & 58 & 66 & \\
2020210002 & 白亦芃 & 2020211101 & 97 & 91 & 82 & 89 & \\
2020210003 & 蔡浩彬 & 2020211101 & 93 & 68 & 69 & 76 & \\
2020210004 & 蔡明洋 & 2020211101 & 97 & 71 & 57 & 73 & \\
2020210005 & 陈楚彬 & 2020211101 & 90 & 88 & 46 & 72 & \\
2020210006 & 戴易彤 & 2020211101 & 90 & 82 & 75 & 82 & \\
2020210007 & 杜恩泽 & 2020211101 & 97 & 82 & 68 & 81 & \\
2020210008 & 付明鋆 & 2020211101 & 93 & 96 & 93 & 94 & \\
2020210009 & 高豪龙 & 2020211101 & 93 & 78 & 71 & 80 & \\
\hline
\end{tabular}
\end{table}
\end{document}
- 理解latex
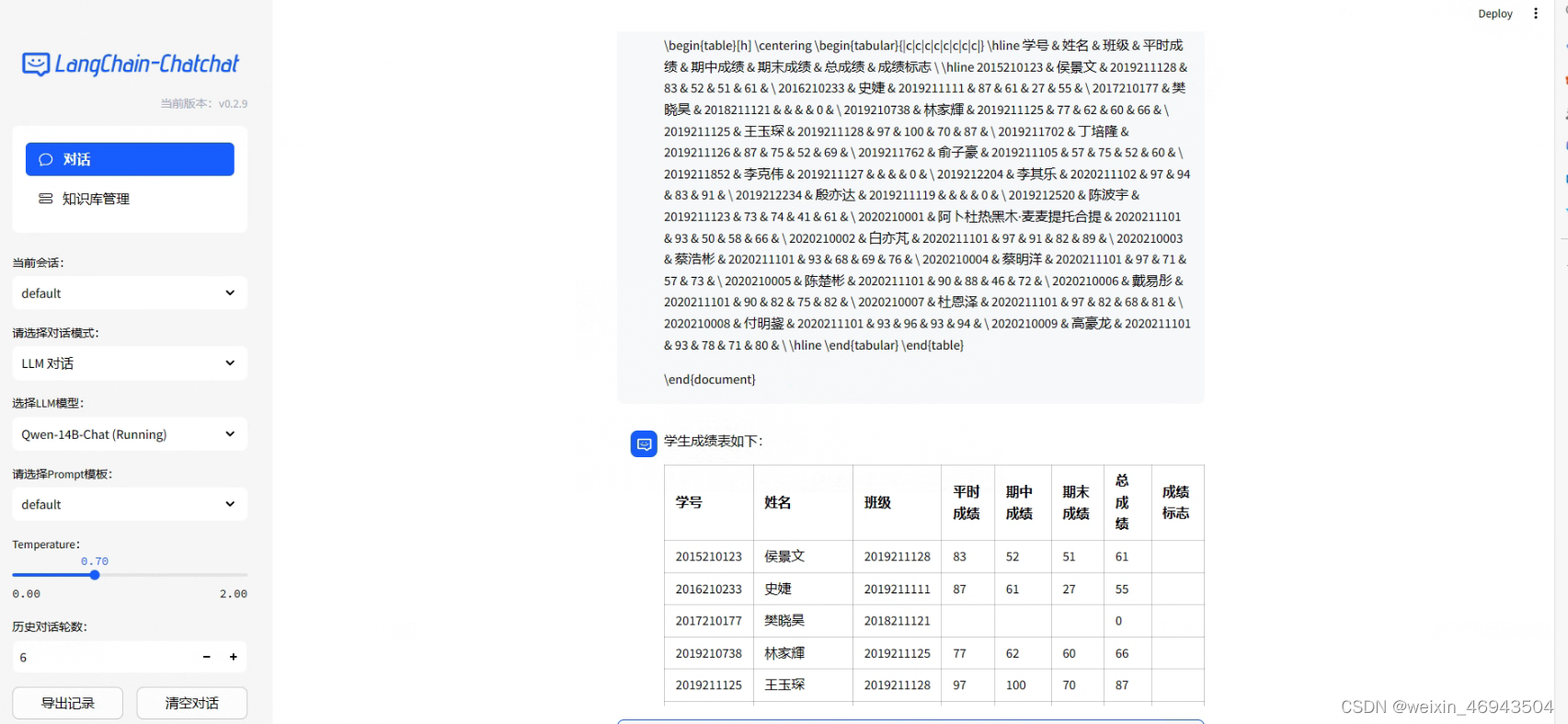
- 单项表问答
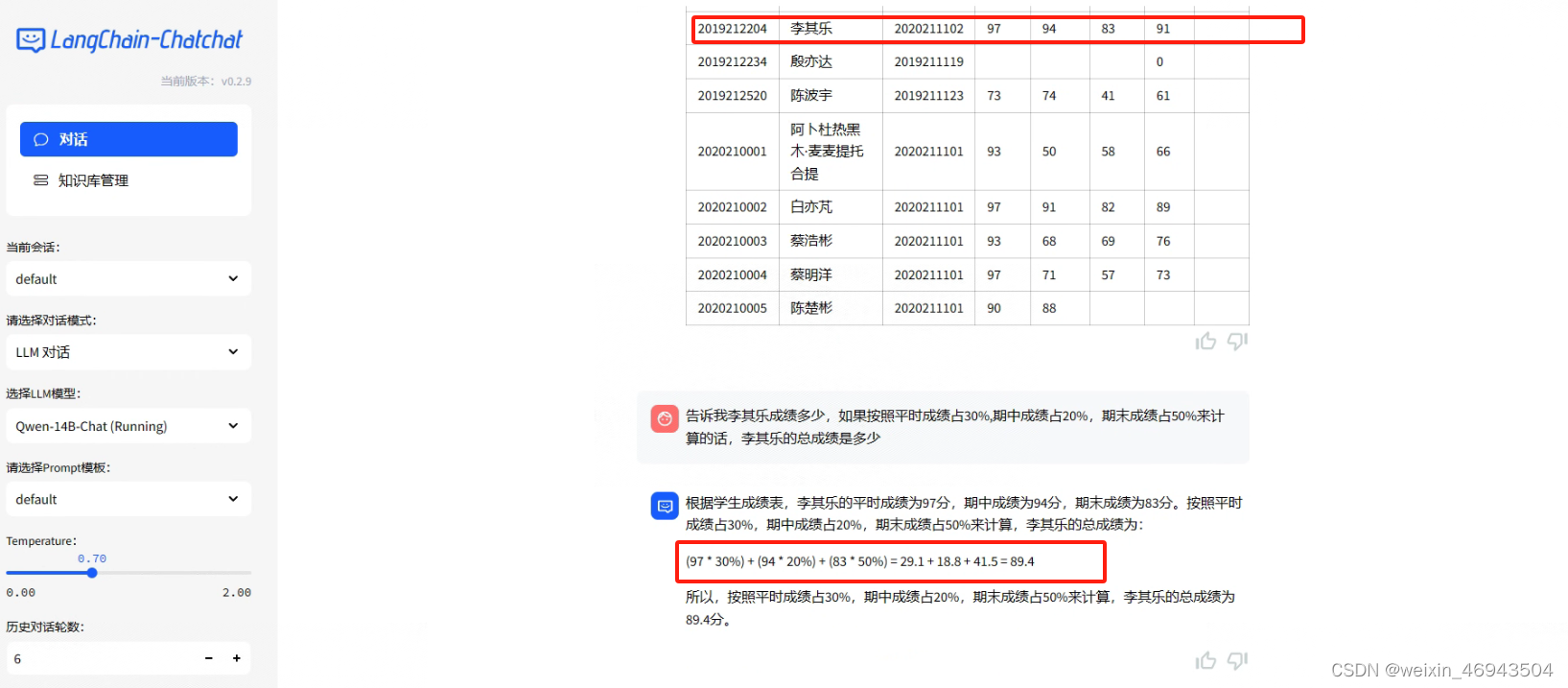
- 整体表问答
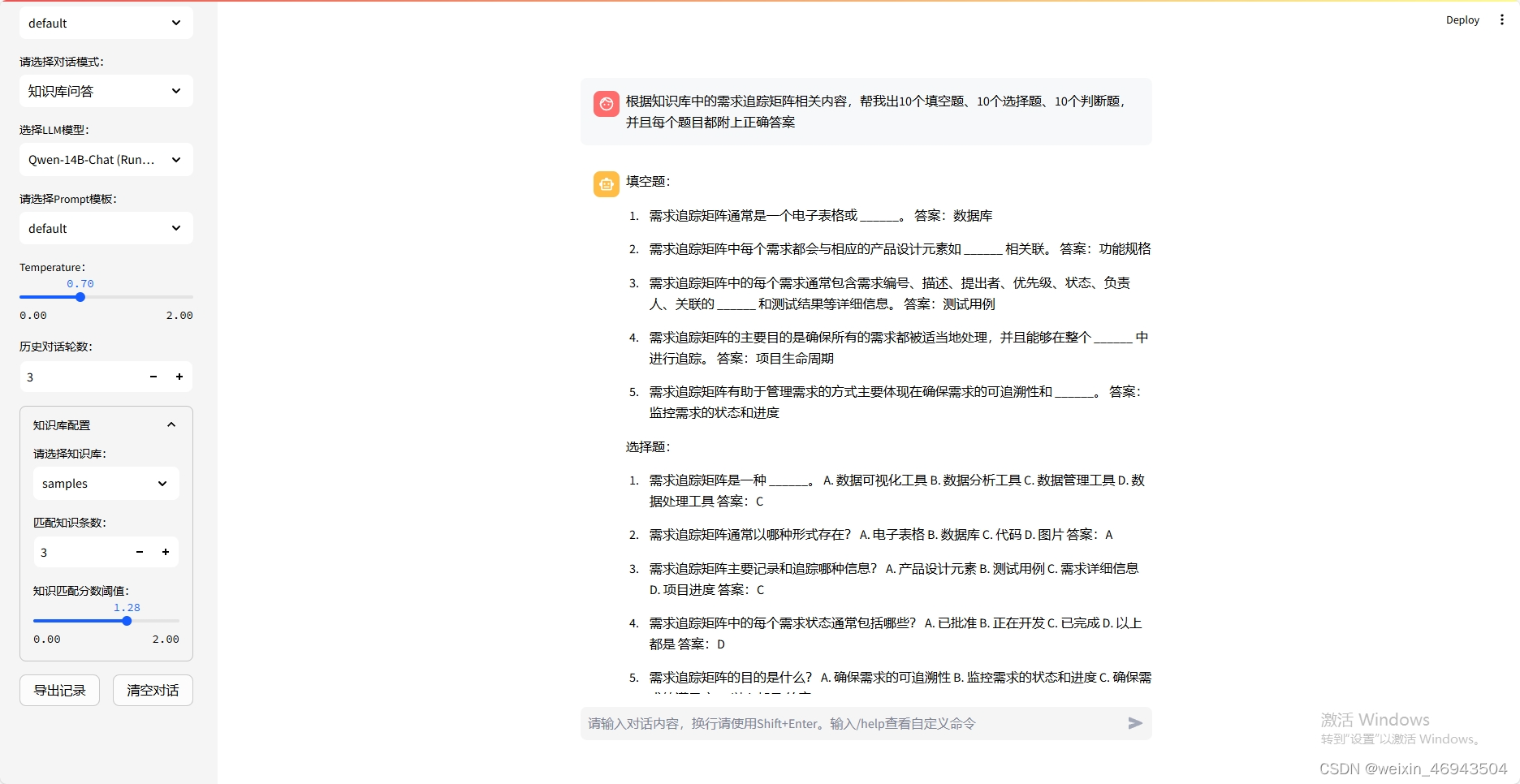
问题7:能否根据知识库中的信息出题目
1.纯文本题
- 本地langchain-chatchat(Qwen-14B)

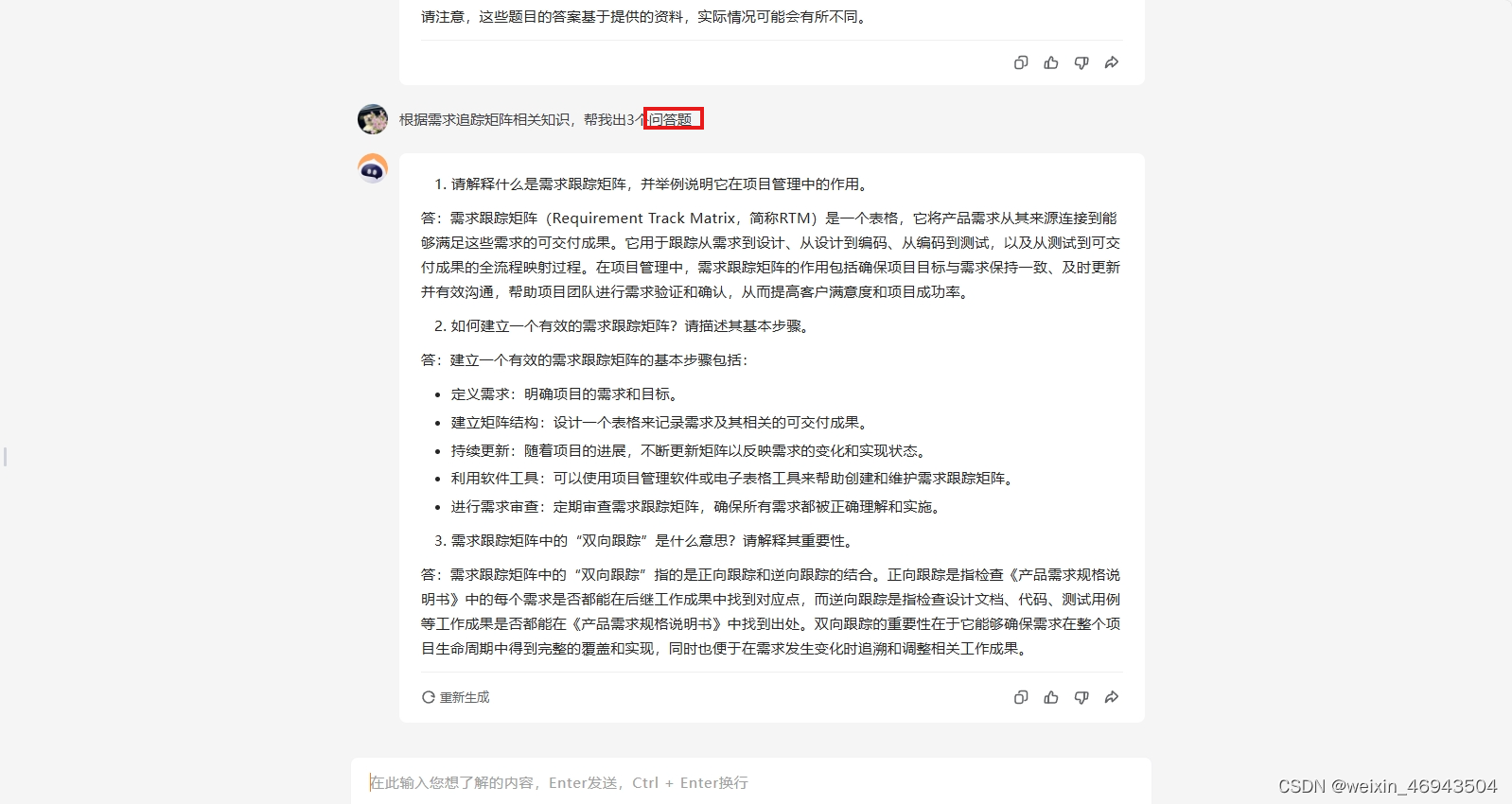
- 百川大模型

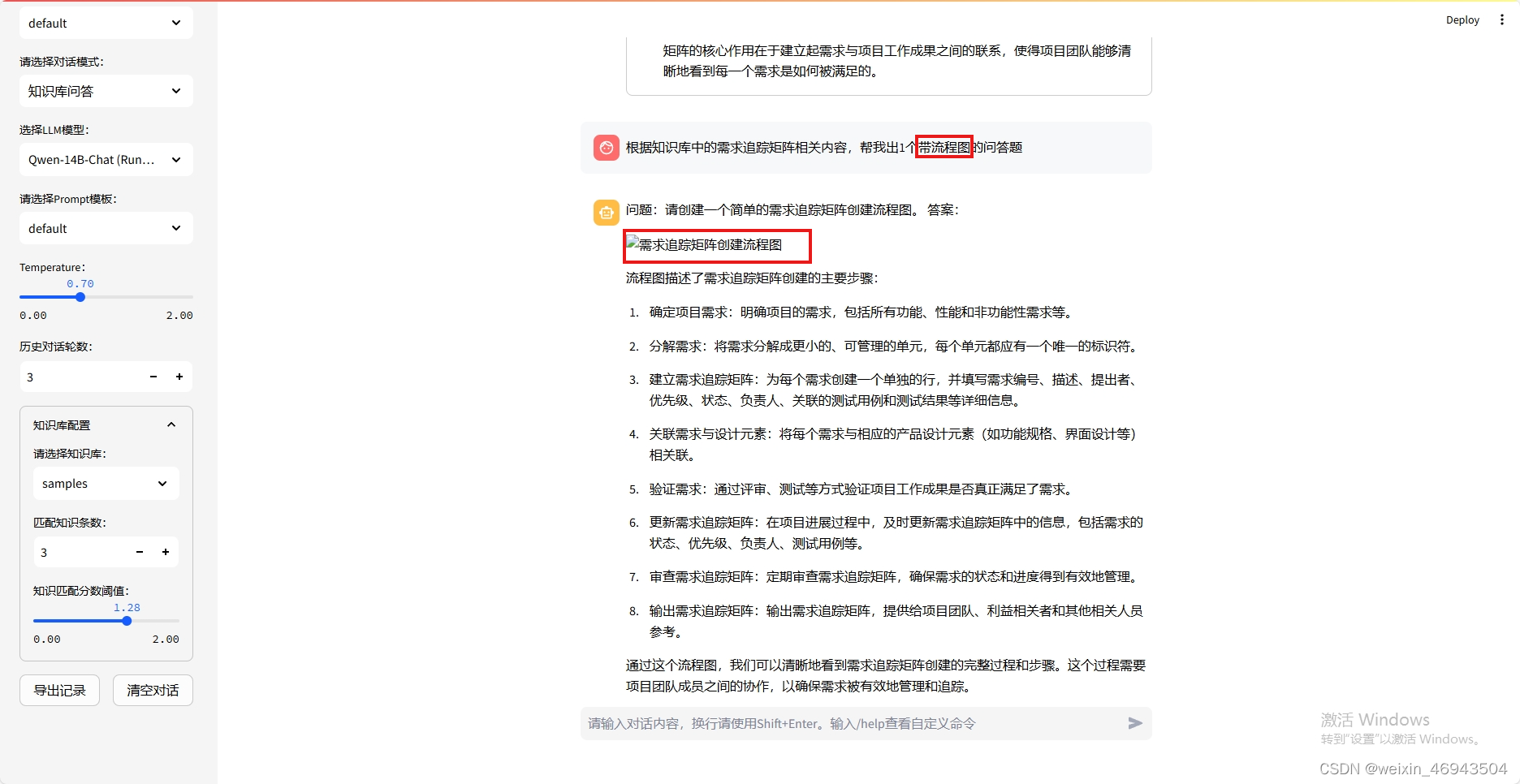
2.带图的问题
- 本地langchain-chatchat(Qwen-14B)
不能够正确显示出图像
- 百川大模型
不能够正确显示出图像
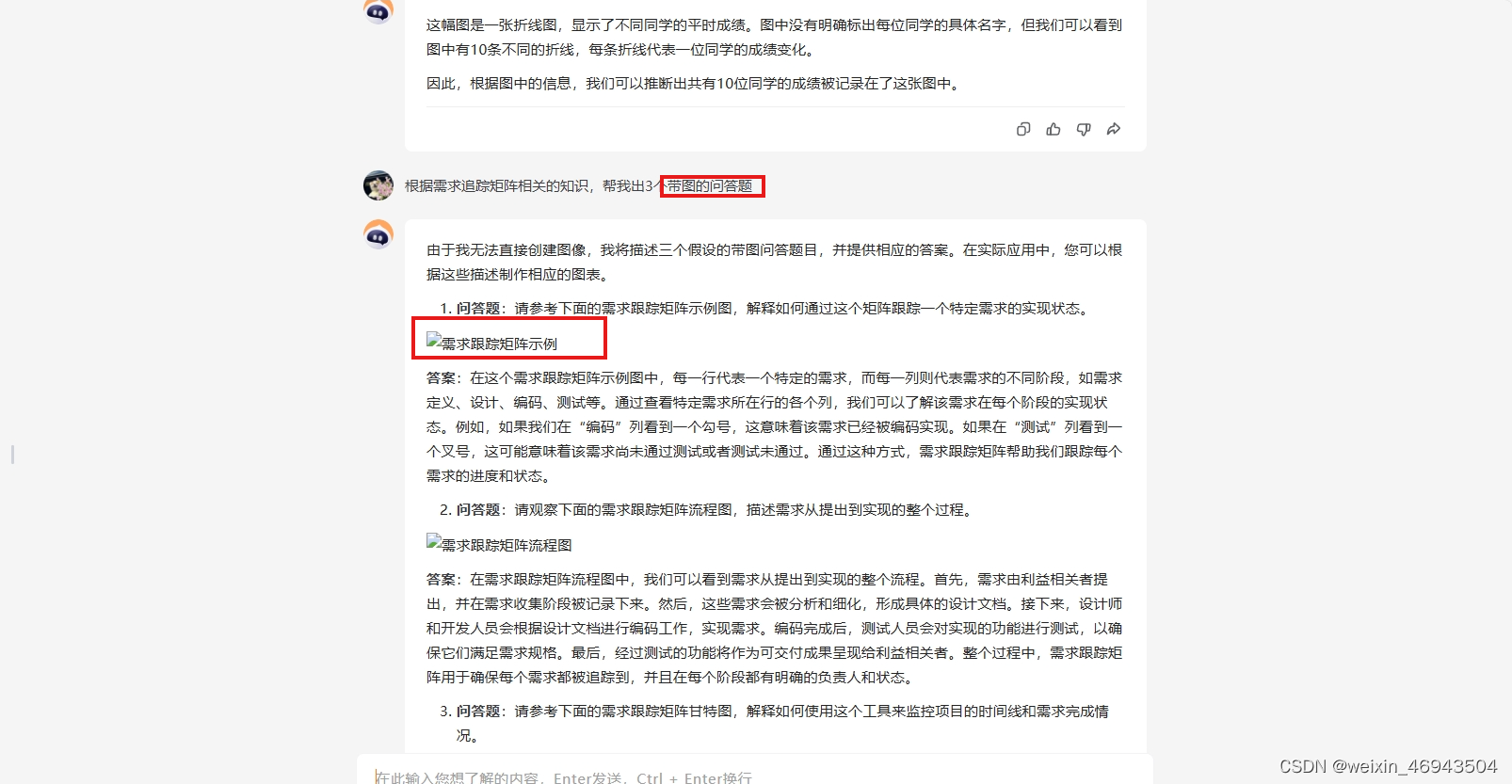
- chatglm大模型
可以显示图像,但明显图像与文字描述不相符
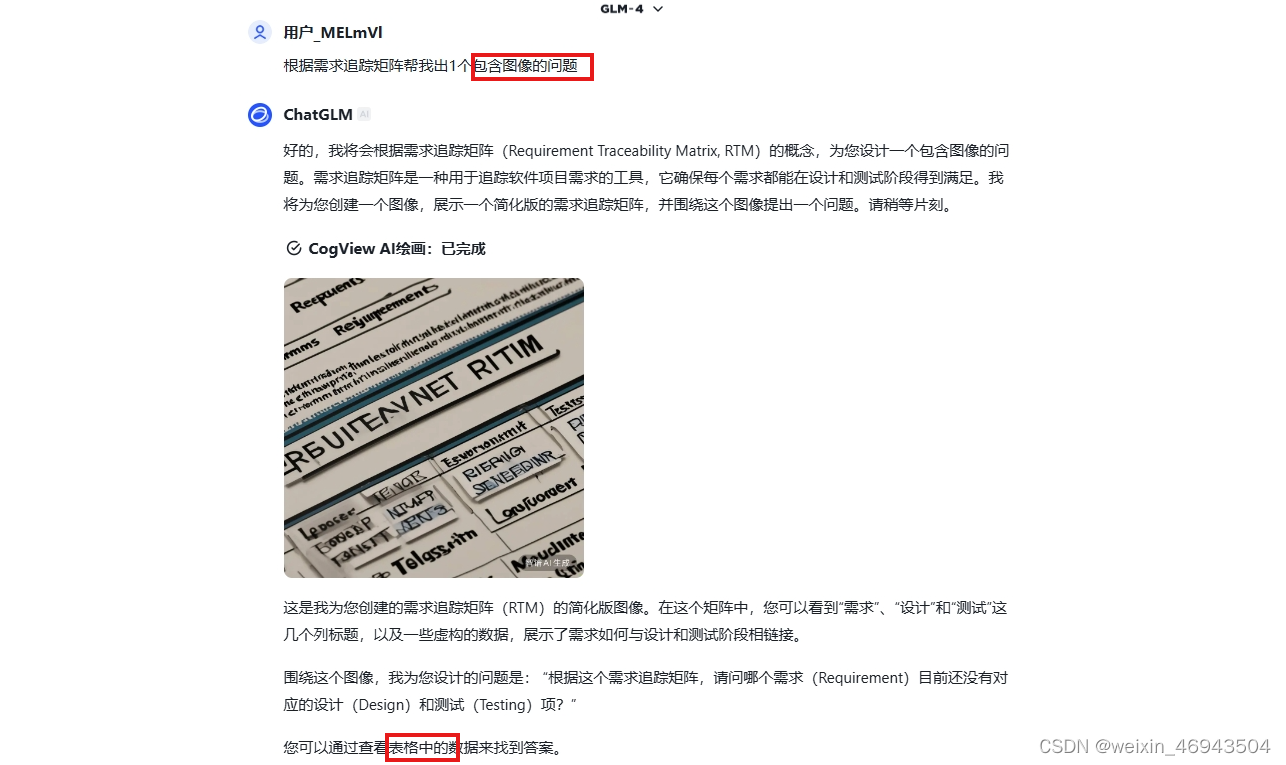
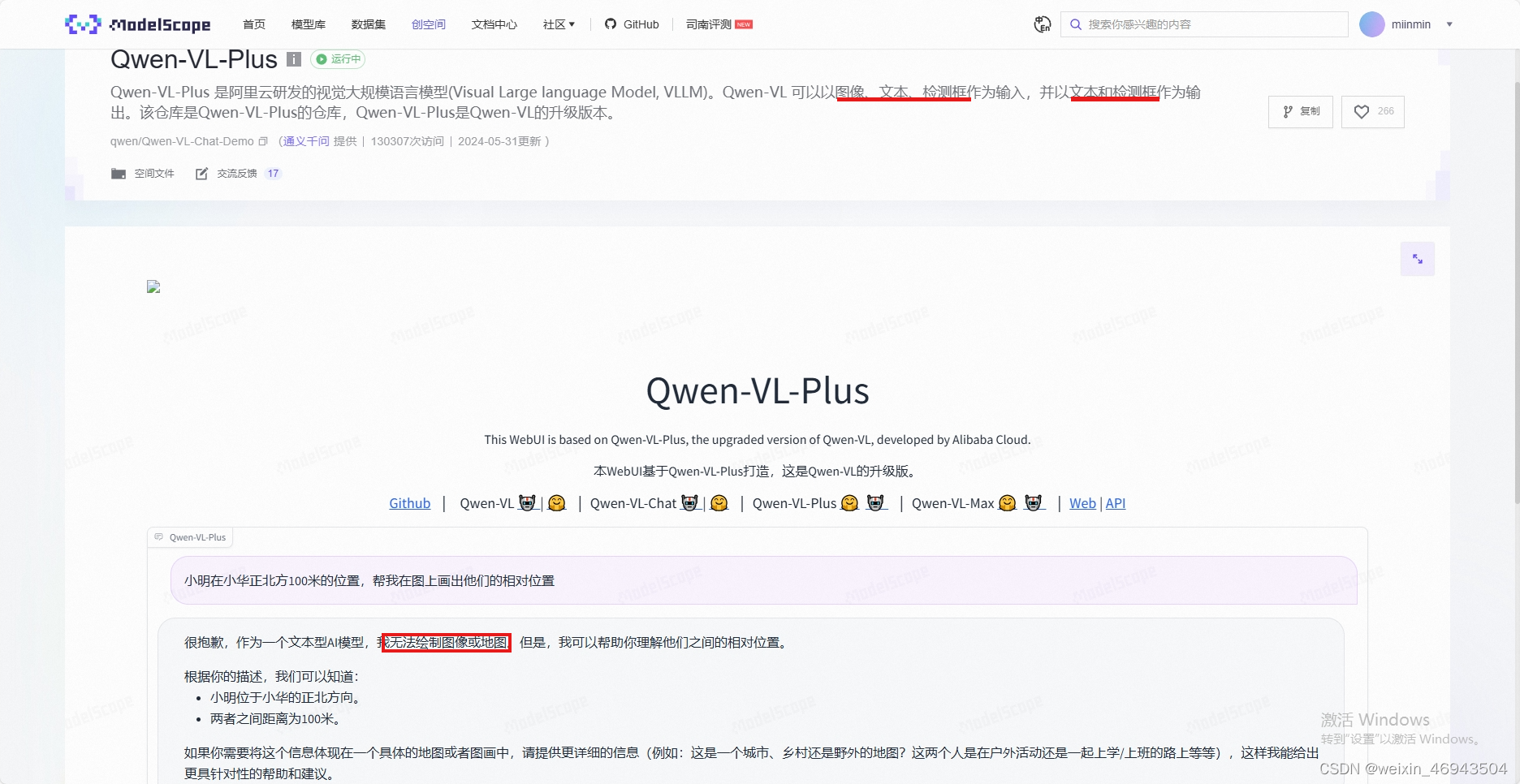
- Qwen-VL-Plus
千问的多模态大模型,可接受图像输入,无法输出图像
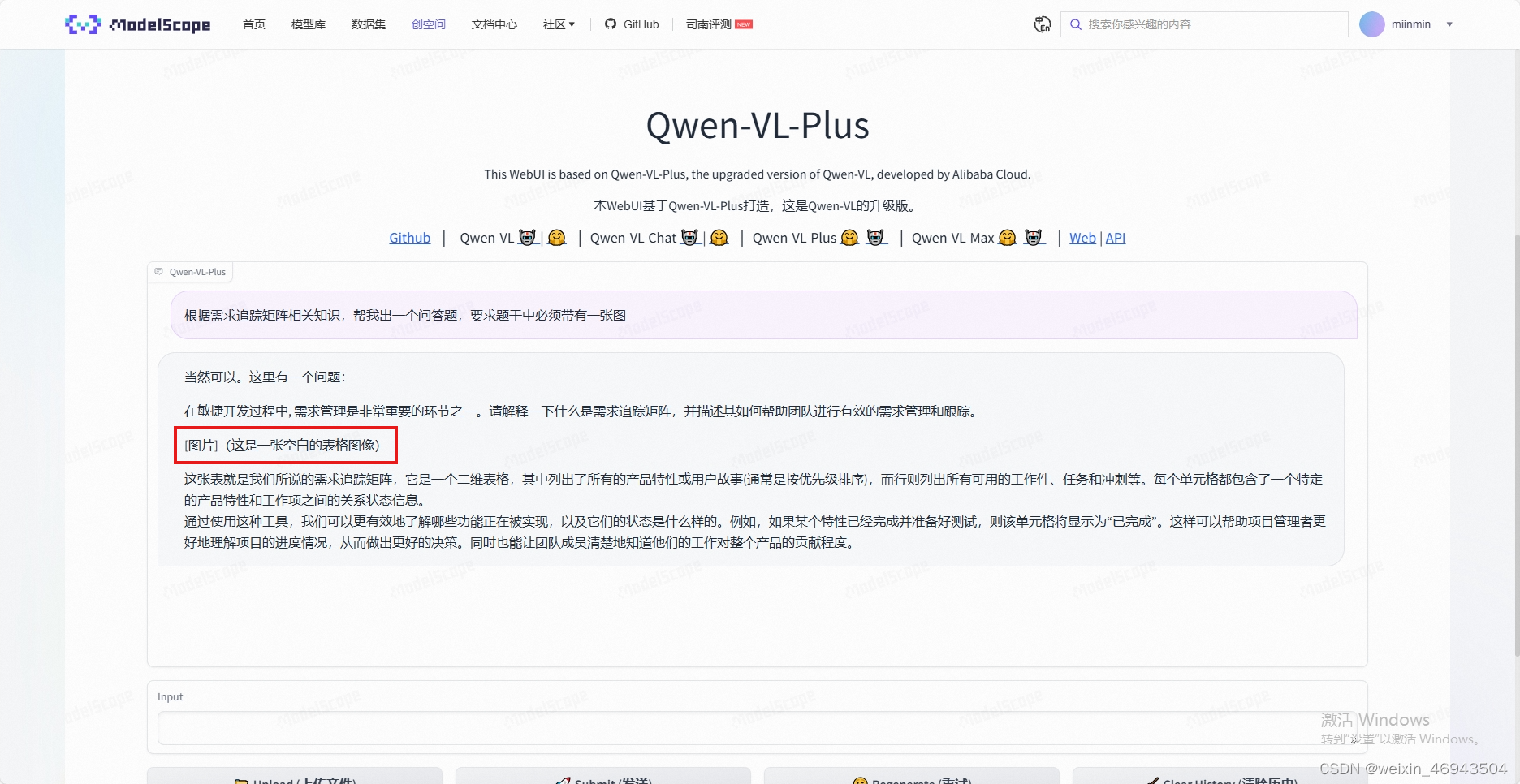
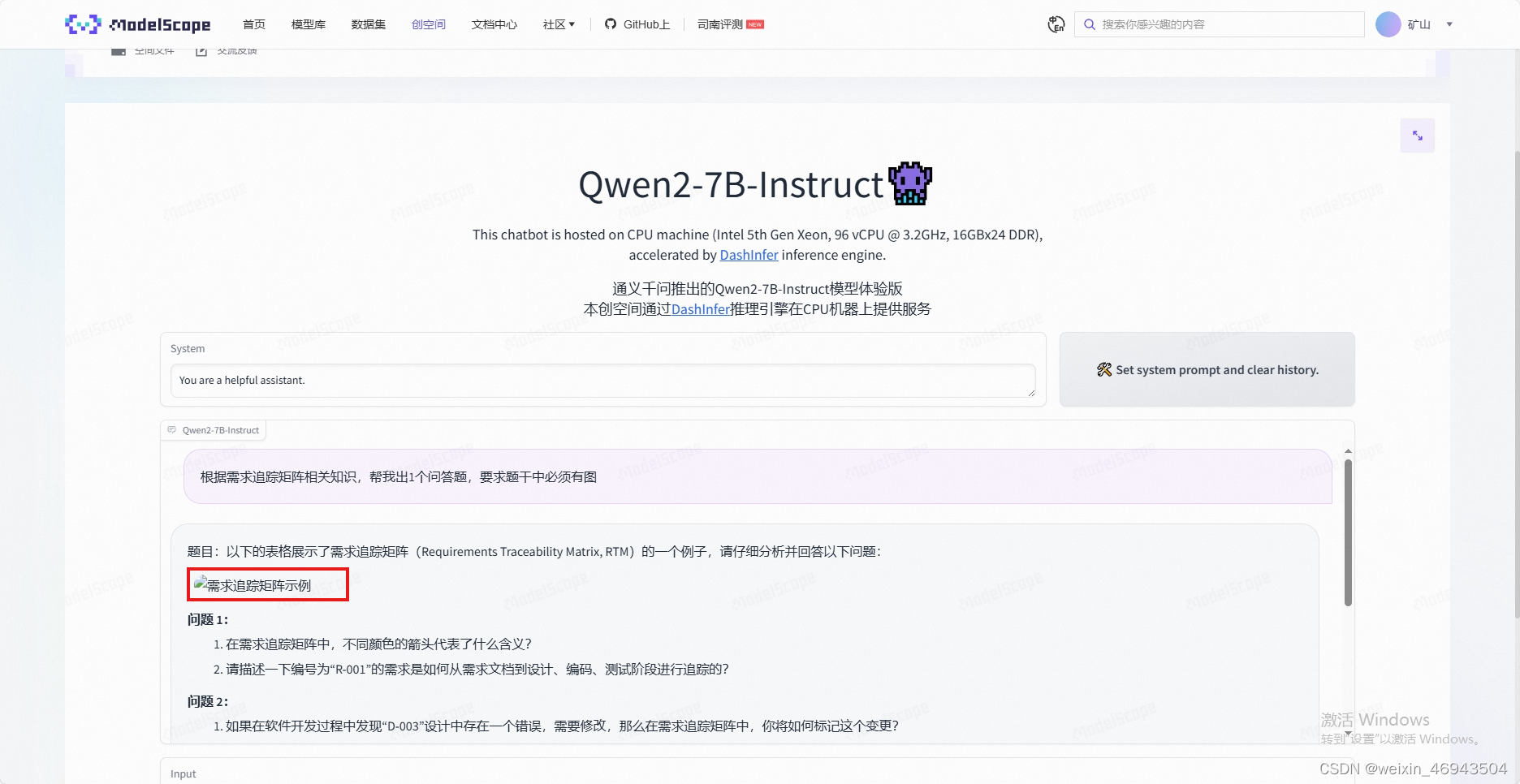
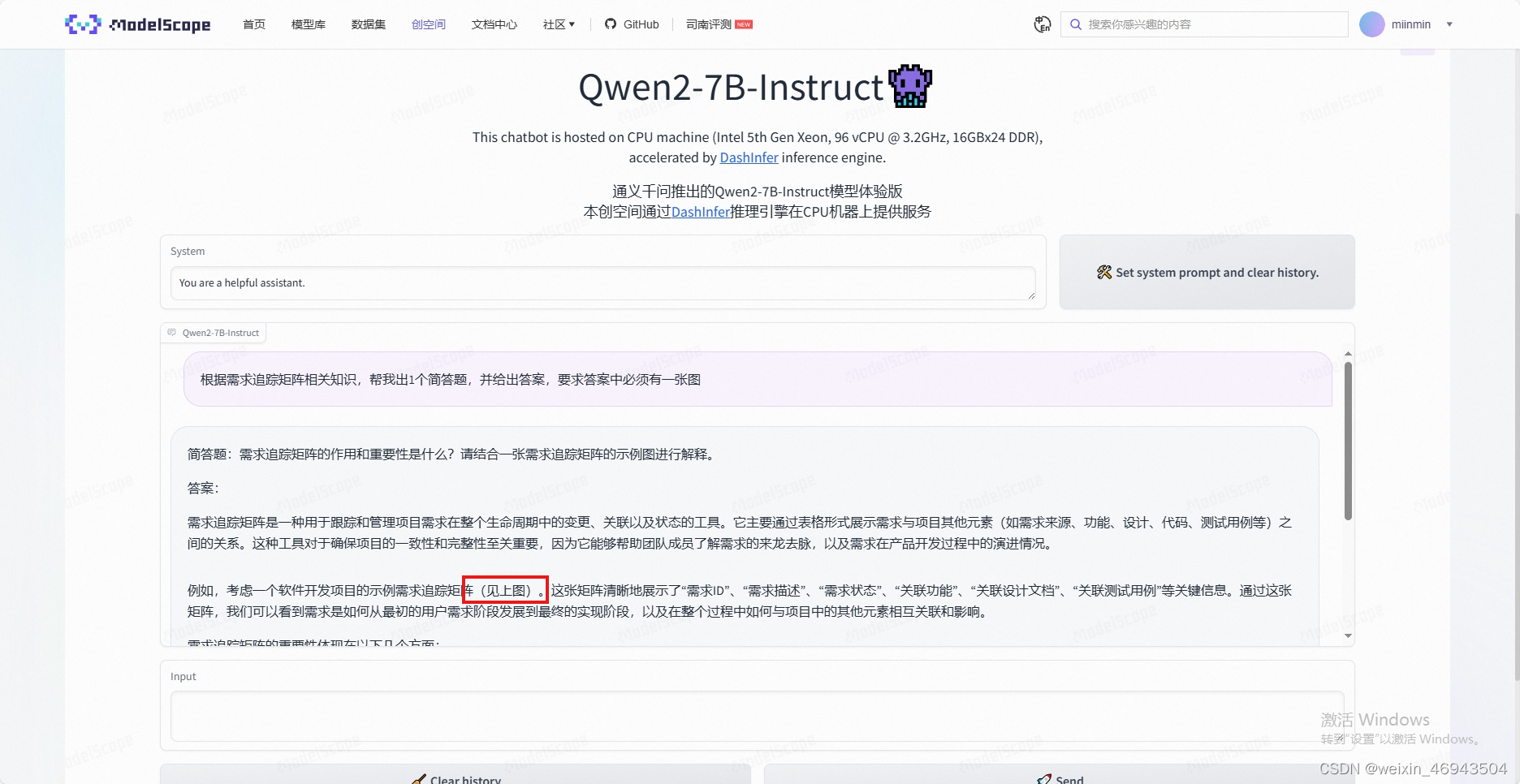
- Qwen2-7B-Instruct
无法正确显示图像
3.回答中带图
- 本地langchain-chatchat(Qwen-14B)
无法显示图像
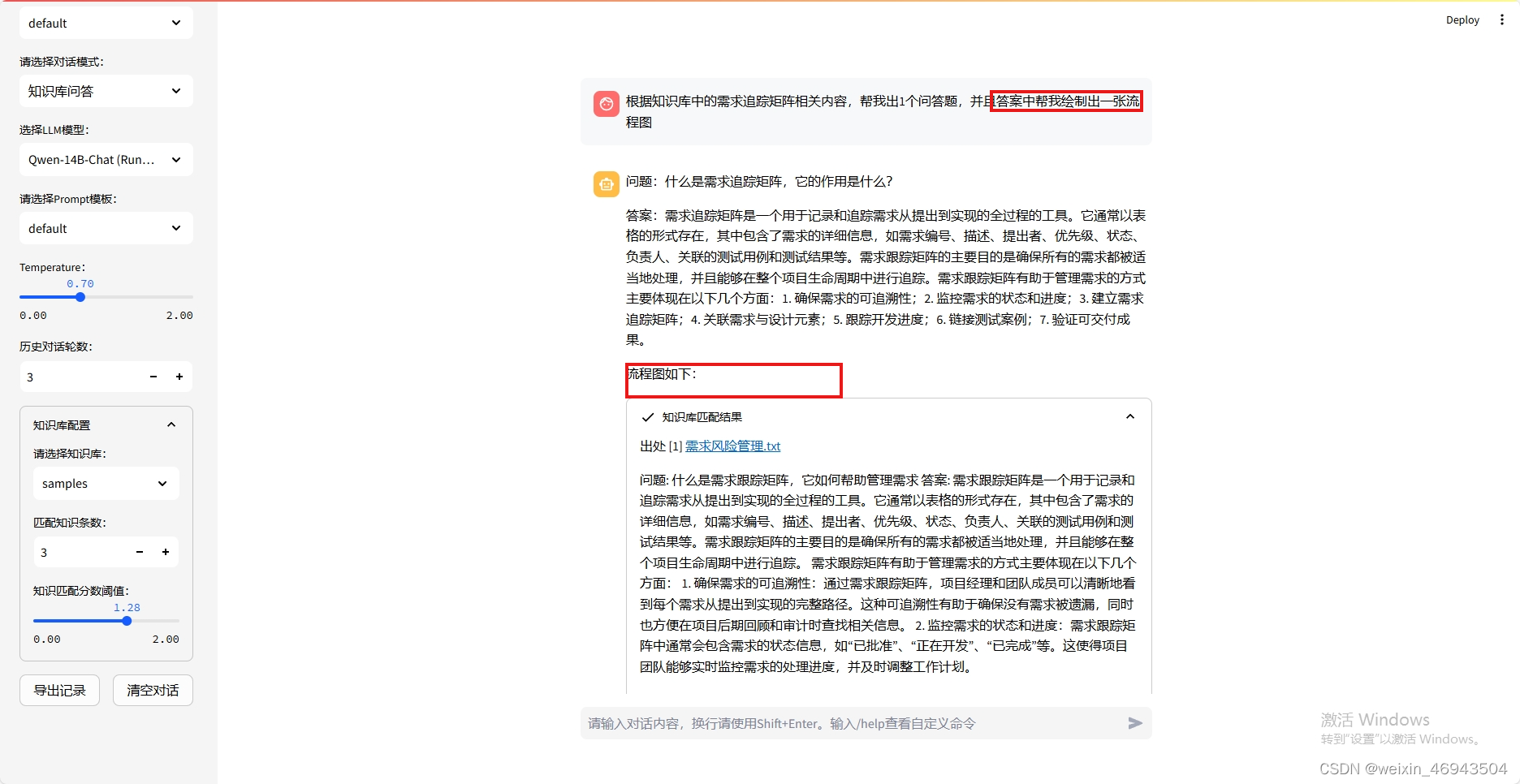
- 本地langchain-chatchat(Qwen-14B)
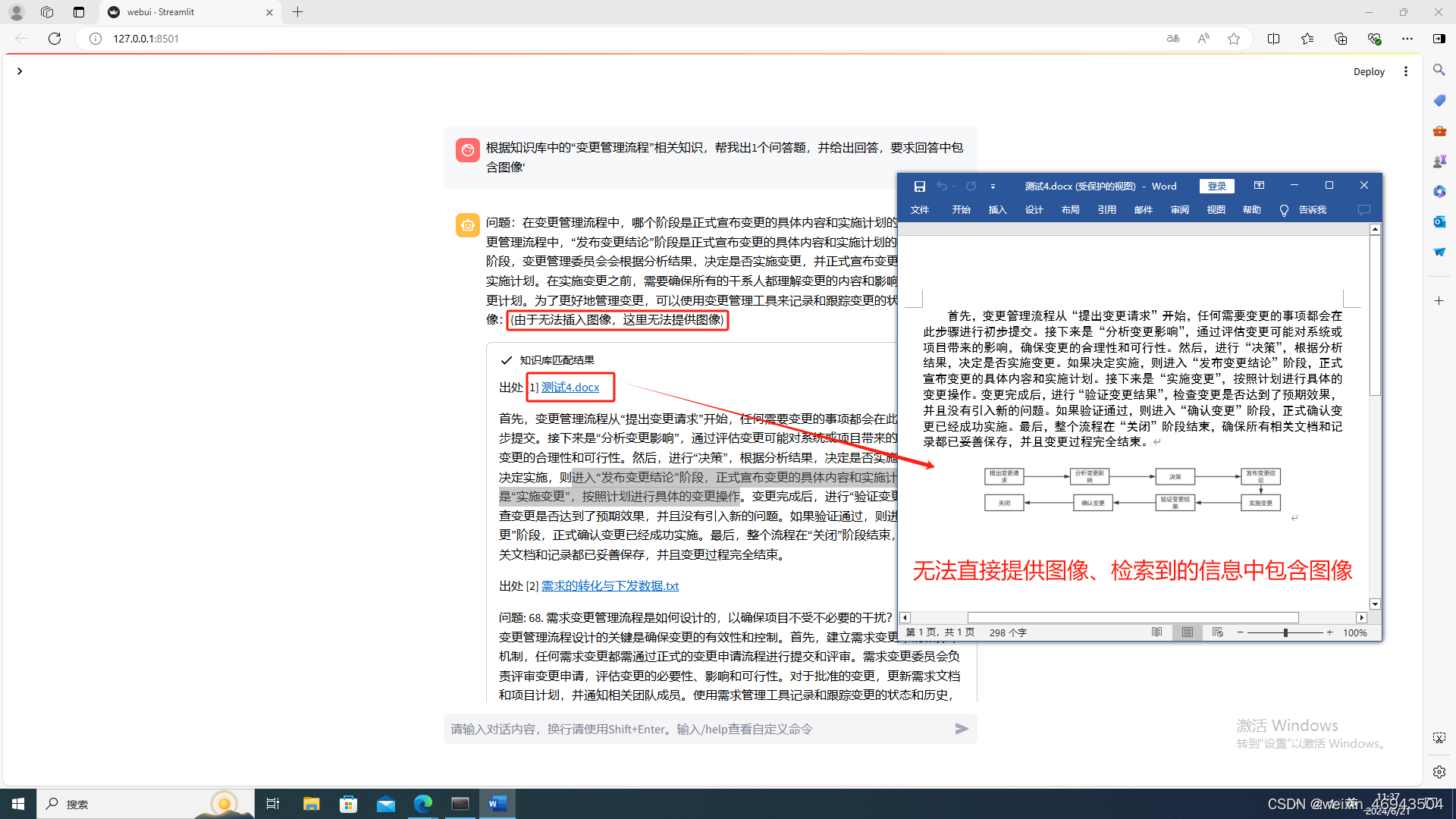
- 本地langchain-chatchat(Qwen-14B)
把word中的图片单独拿出来,上传到知识库中
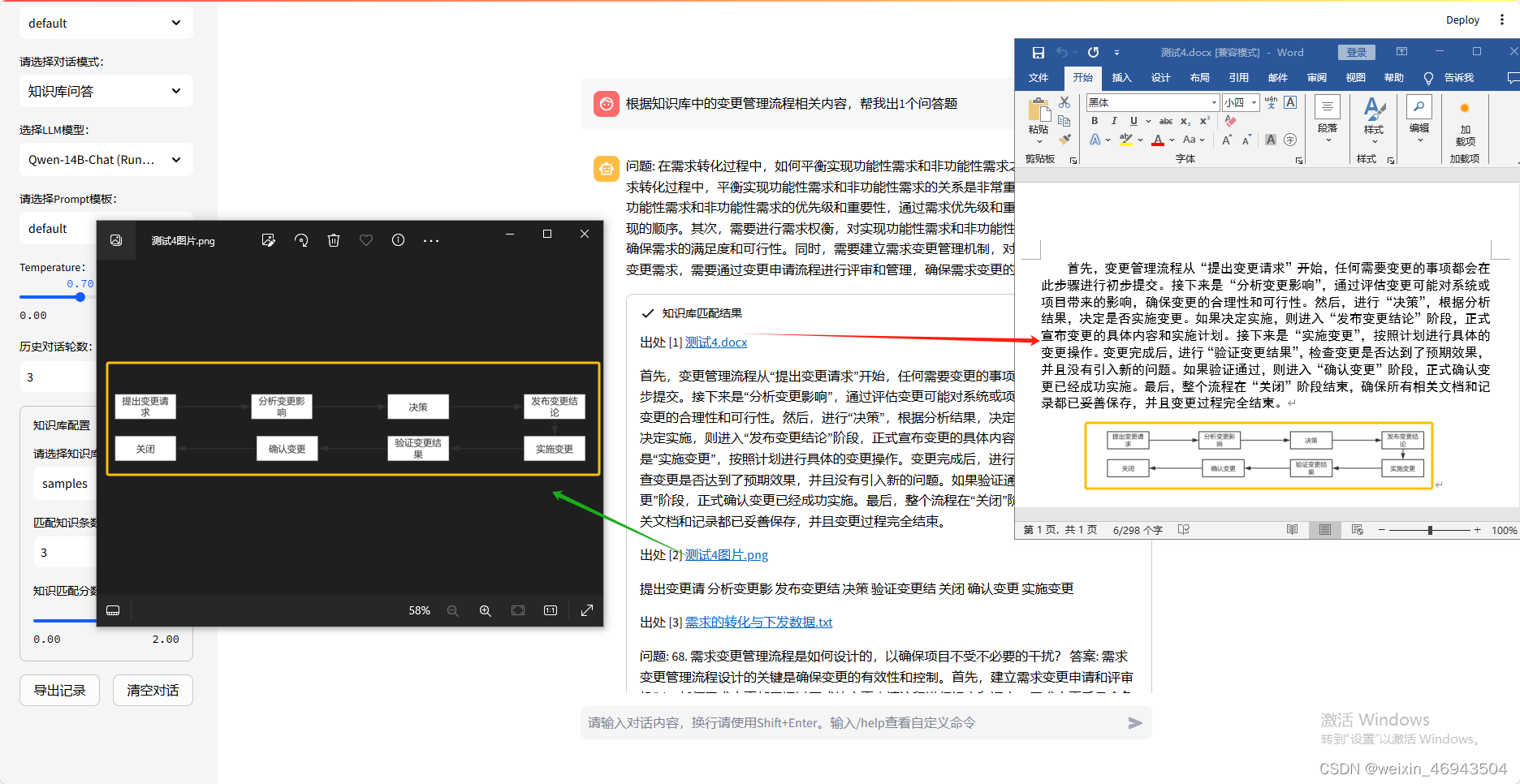
- 百川大模型
无法显示图像
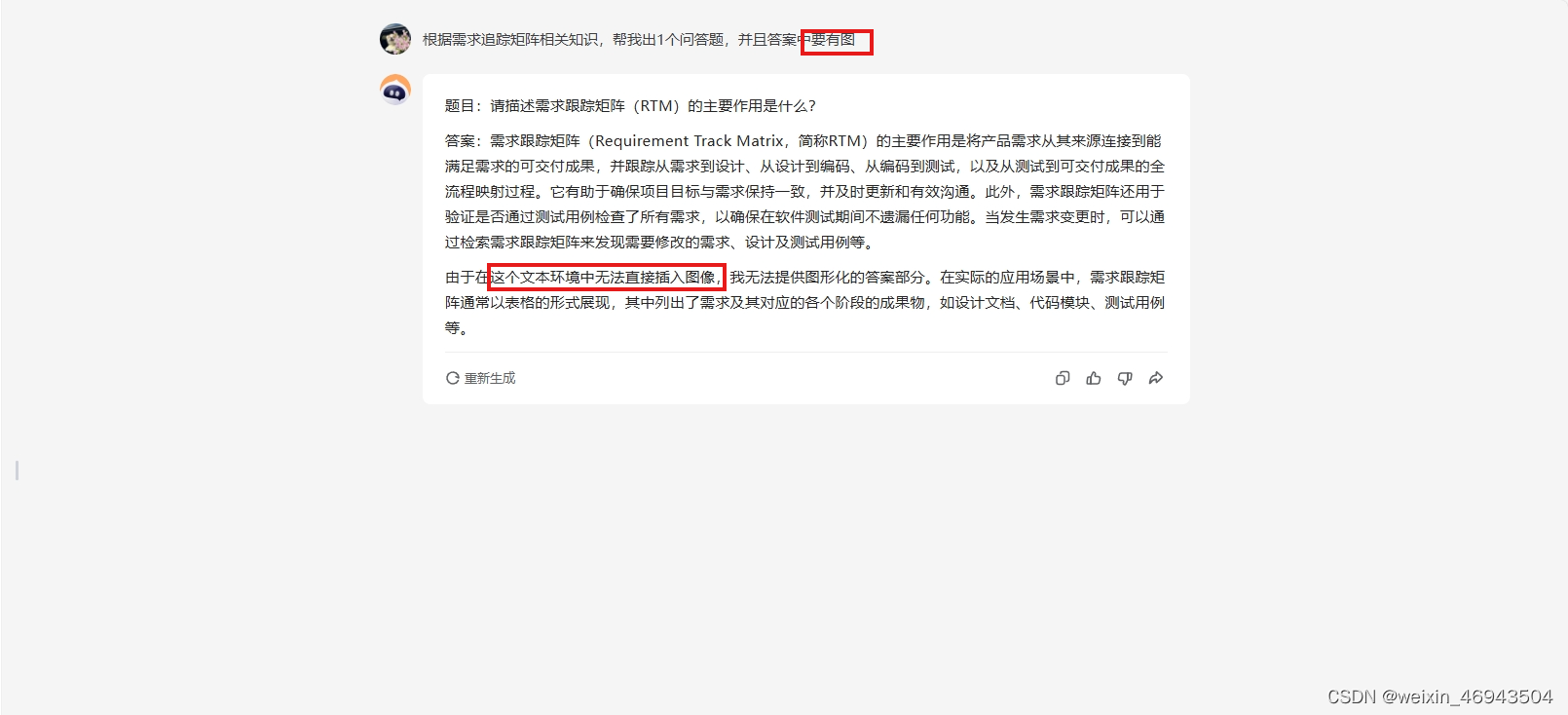
- chatglm大模型
能够生成带图的答案,但图文不符
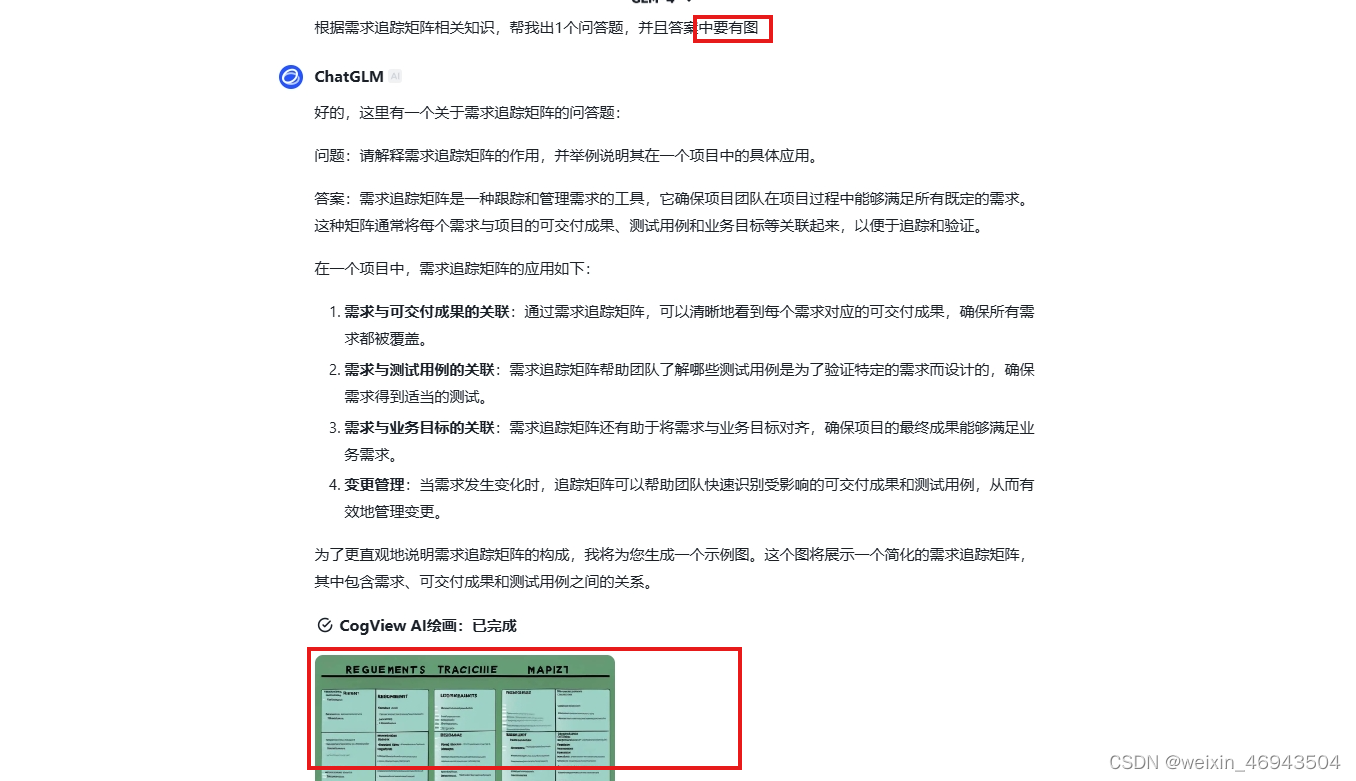

- Qwen-VL-Plus
千问的多模态模型,无法绘制图像

- Qwen2-7B-Instruct
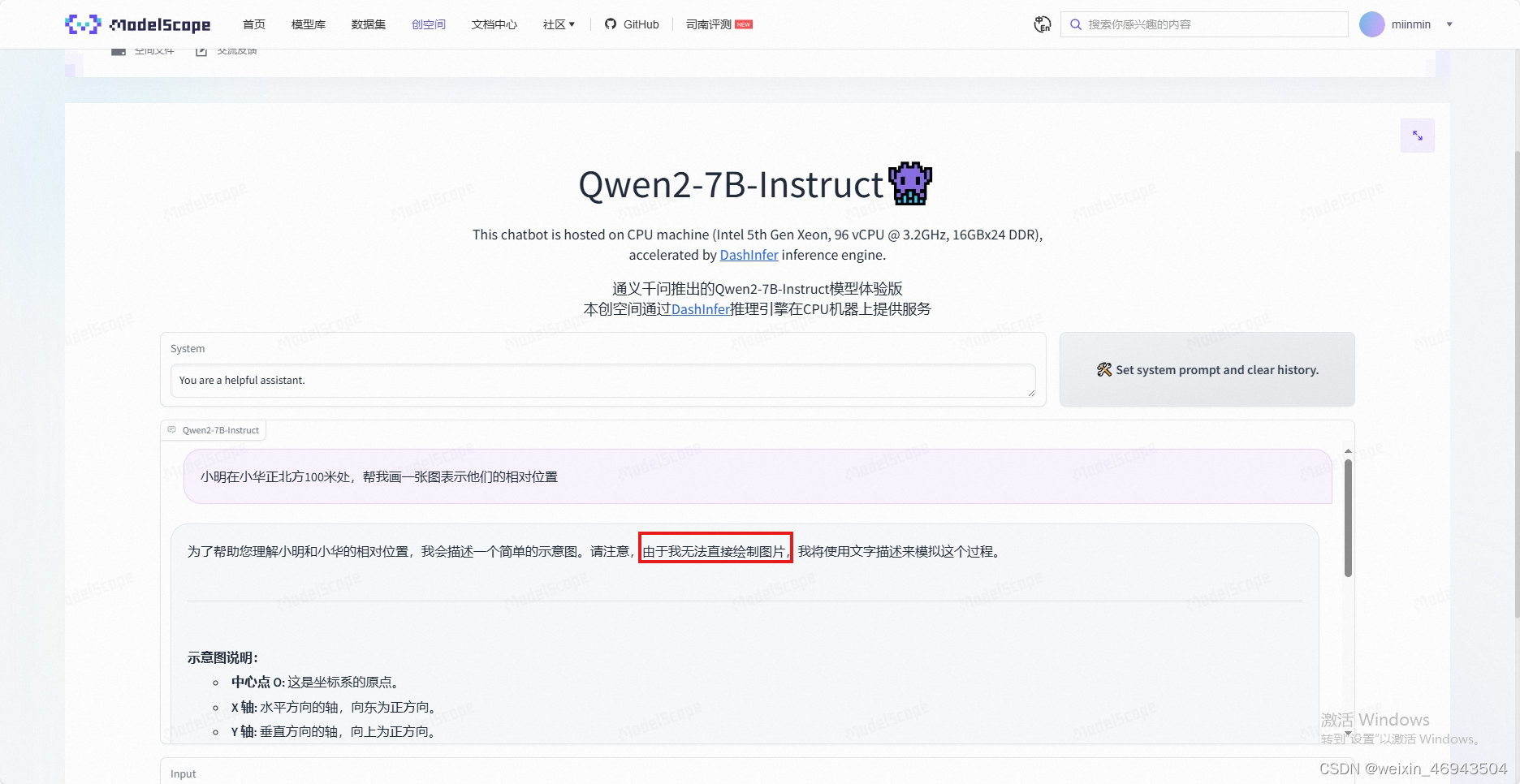
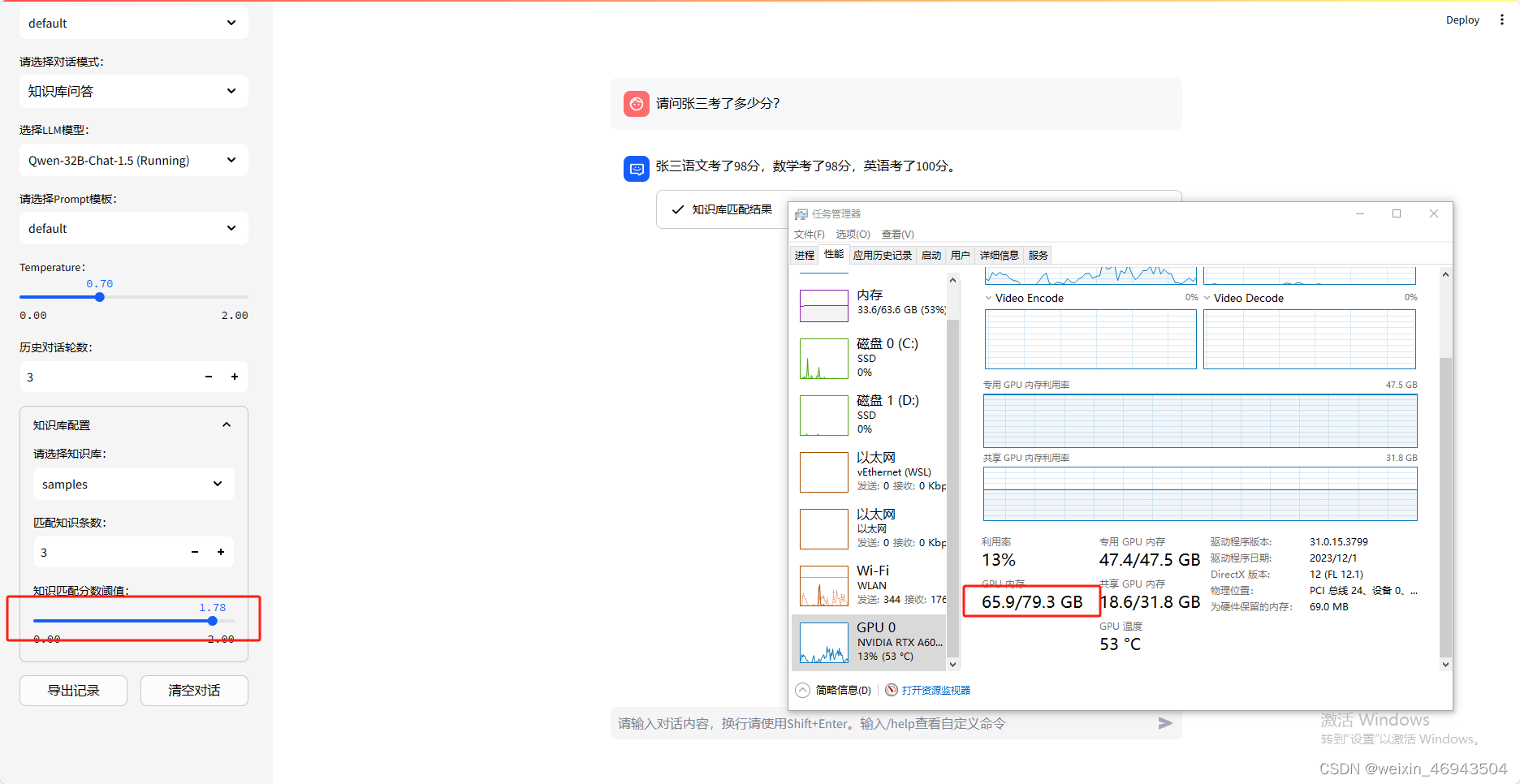
测试(Qwen 32B 1.5)
加扰动的文档问答
能回答
速度特别慢。GPU占用较高。

表格问答
调整阈值后可以回答,但是速度特别慢。GPU占用较高。
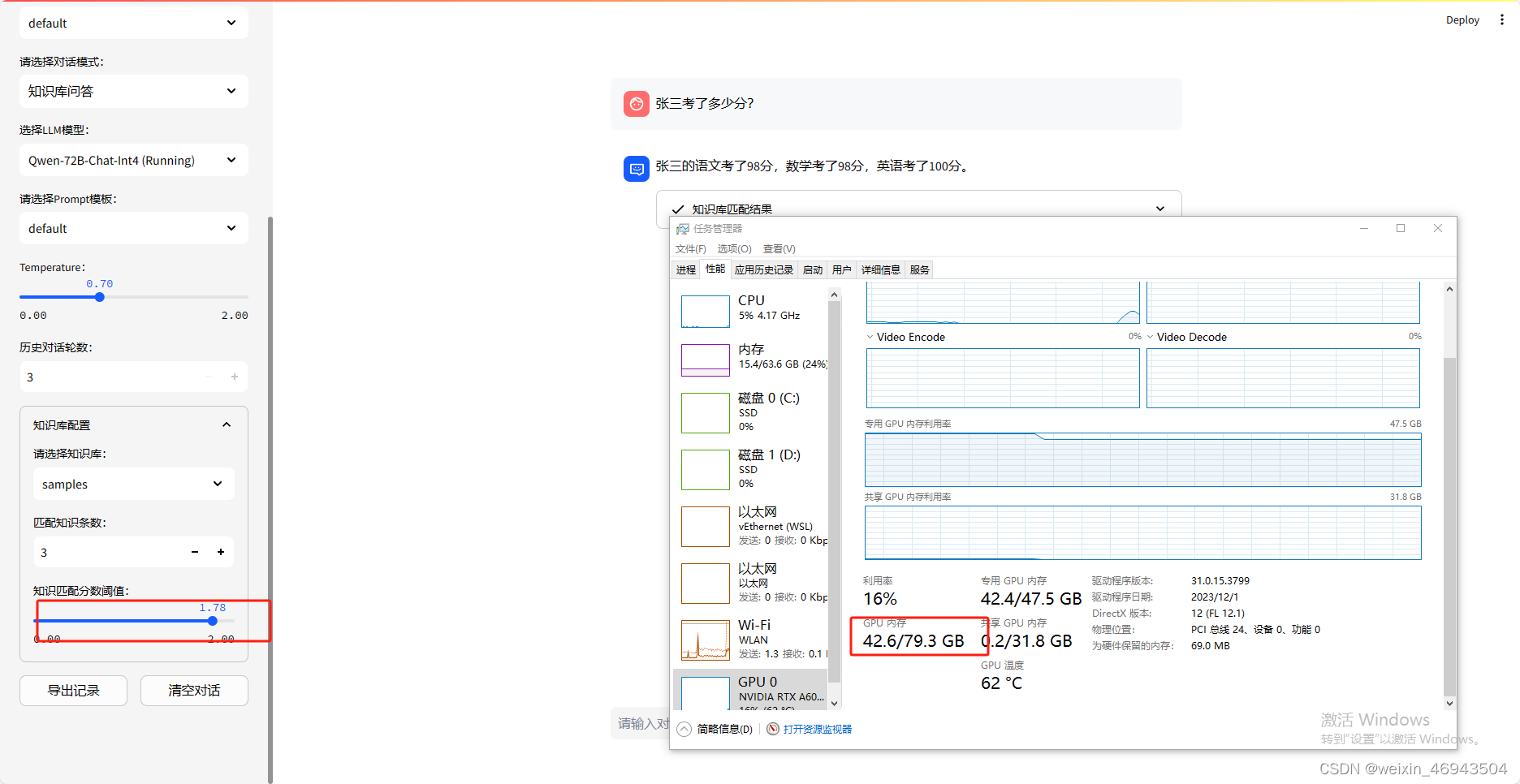
测试 (Qwen 72B Int4)
加扰动的文档问答
能回答
速度特别慢(3分钟)。GPU占用较高。

表格问答
调整阈值后可以回答,但是速度特别慢。GPU占用较高。
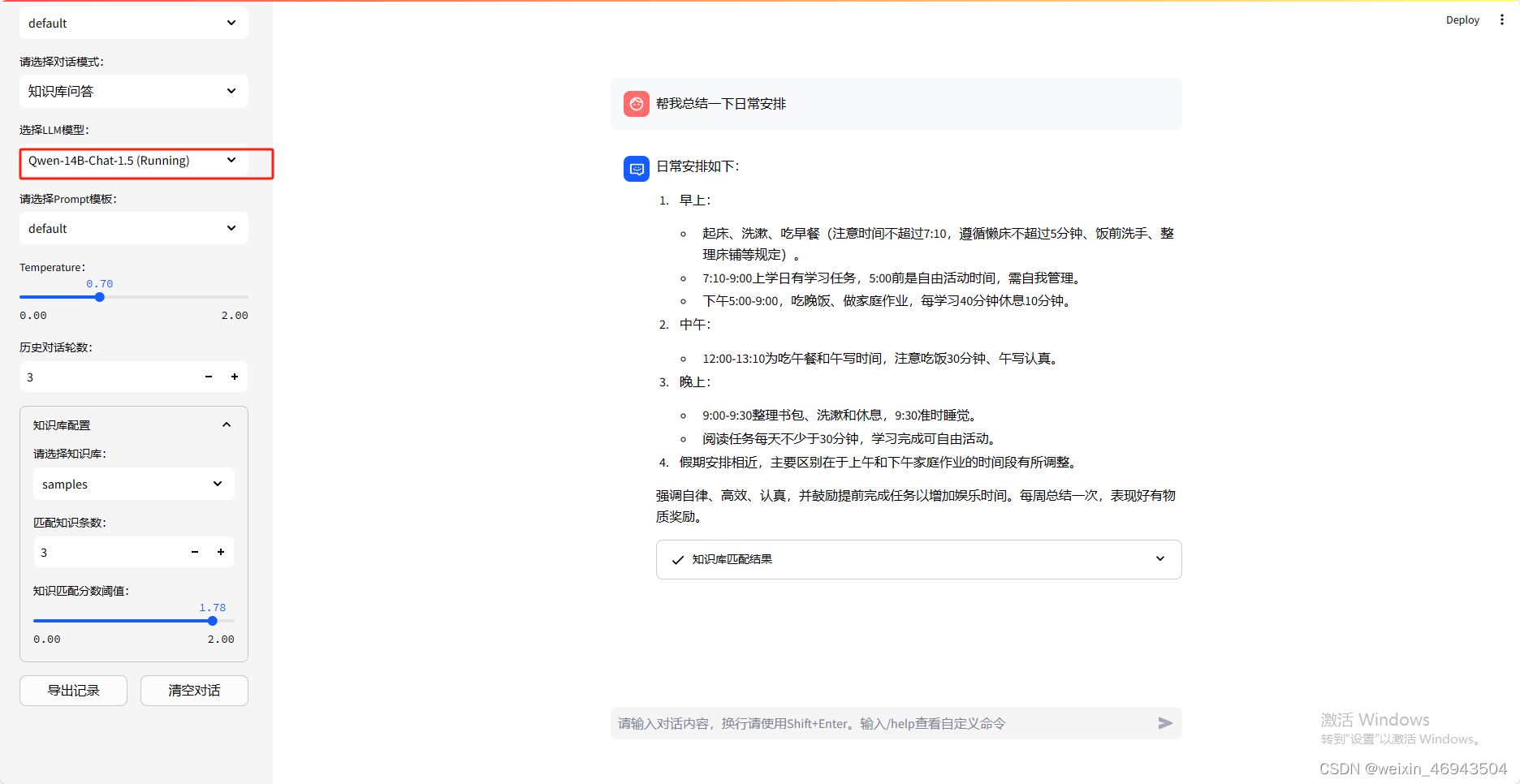
测试(Qwen 14B 1.5)
测试参考Qwen 14B,回答效果差不多,1.5版本GPU占用33G左右
双卡A6000运行langchain-chatchat(Qwen1.5-32B)
未配置多卡加载时
加载模型时,内存占满了,GPU没用。加载完成后,内存降下来,显存增加
一张显卡跑满,另外一张显卡没用到。
回答很慢


如何配置langchain-chatchat的多卡加载
https://github.com/chatchat-space/Langchain-Chatchat/wiki/%E5%BC%80%E5%8F%91%E7%8E%AF%E5%A2%83%E9%83%A8%E7%BD%B2#%E5%A4%9A%E5%8D%A1%E5%8A%A0%E8%BD%BD


配置双卡加载后
两张GPU均使用
回答速度提升


autoAWQ量化
安装
pip install autoawq
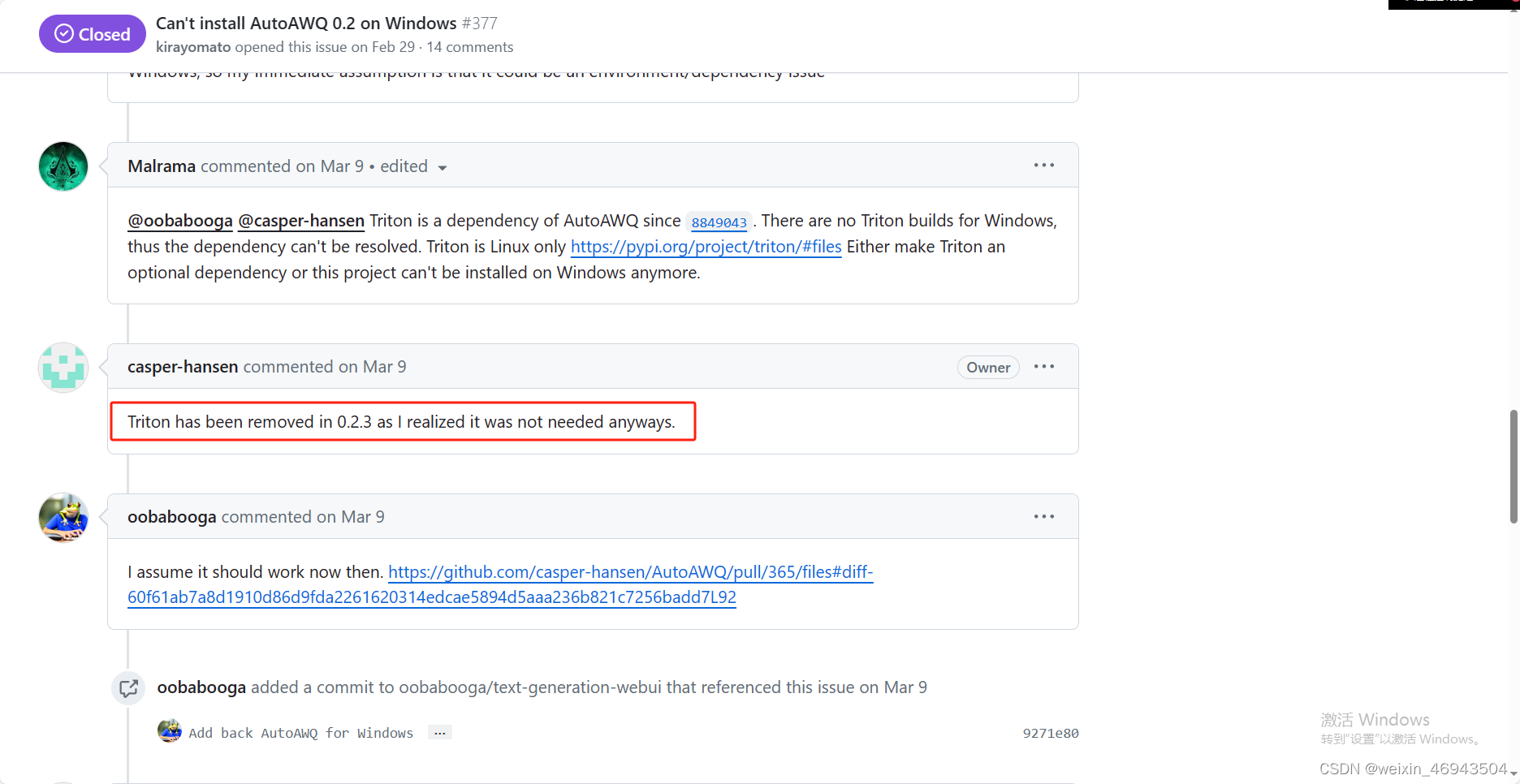
- 在我的langchain-chachat虚拟环境中,安装0.2.5的版本是完全没有问题的
安装0.2.0版本就会报错说找不到triton模块,并且当我尝试自己安装triton时,安不上。
原因:在0.2.3之前需要triton,而它只有linux下能用,所window下安装不了0.2.3之前的版本
使用
量化模型的代码
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_path = '../model/14B'
quant_path = './qunanted_14B'
quant_config = { "zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMM" }
# Load model
model = AutoAWQForCausalLM.from_pretrained(
model_path, **{"low_cpu_mem_usage": True, "use_cache": False}
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# Quantize
model.quantize(tokenizer, quant_config=quant_config)
# Save quantized model
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
print(f'Model is quantized and saved at "{quant_path}"')
报错
no module named transformer.gmma
autoawq与transformer的版本不匹配,autoaqw要transformers-4.40.1。
解决办法:先卸载autoawq,再卸载transformer,然后再pip install autoawqConnectionError: Couldn't reach 'mit-han-lab/pile-val-backup' on the Hub (ProxyError)
这是因为连不上hugging face,把数据集下载下来放到mit-han-lab\pile-val-backup文件夹下,定位到报错的地方修改数据集地址:
# dataset = load_dataset("mit-han-lab/pile-val-backup", split="validation")
dataset = load_dataset(r"D:\zm\LLM\Qwen\Quant\mit-han-lab\pile-val-backup", split="validation")
量化中
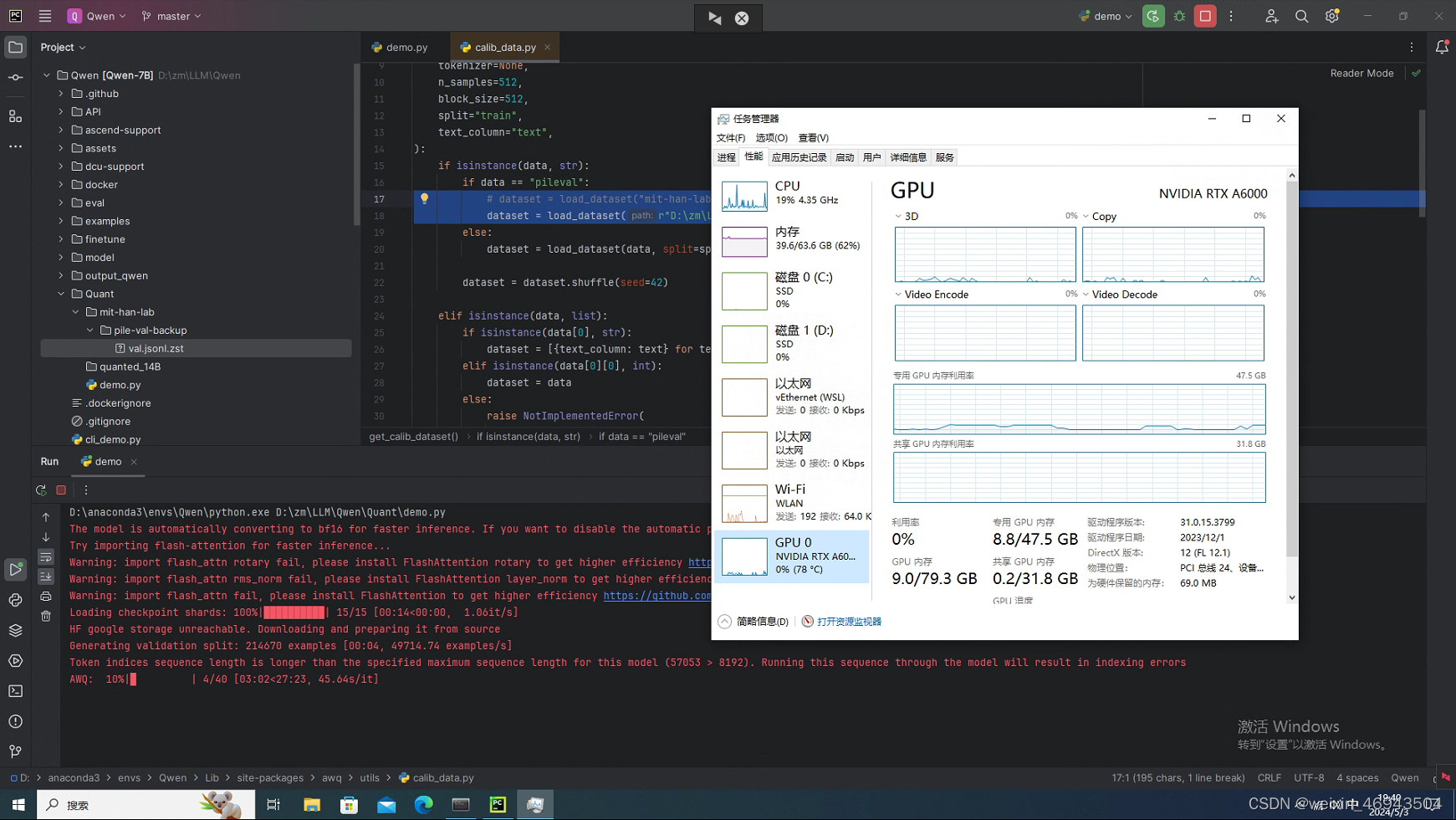
使用量化模型
发现一个问题:量化 后的模型虽然GPU占用少了,但是回答却是1个字1个字蹦出来的,为什么?
- autoawq量化的14B
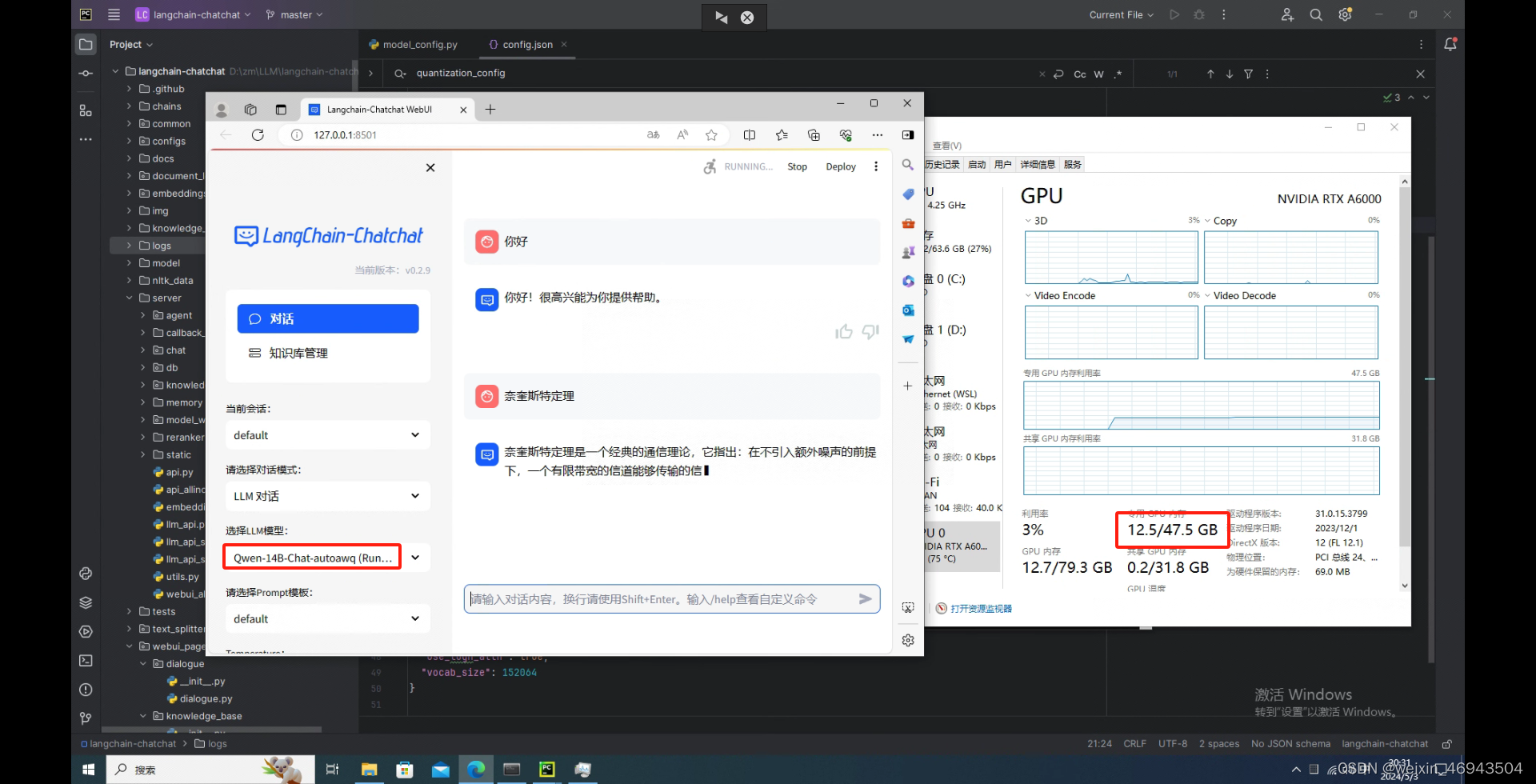
- autoawq量化的72B-1.5
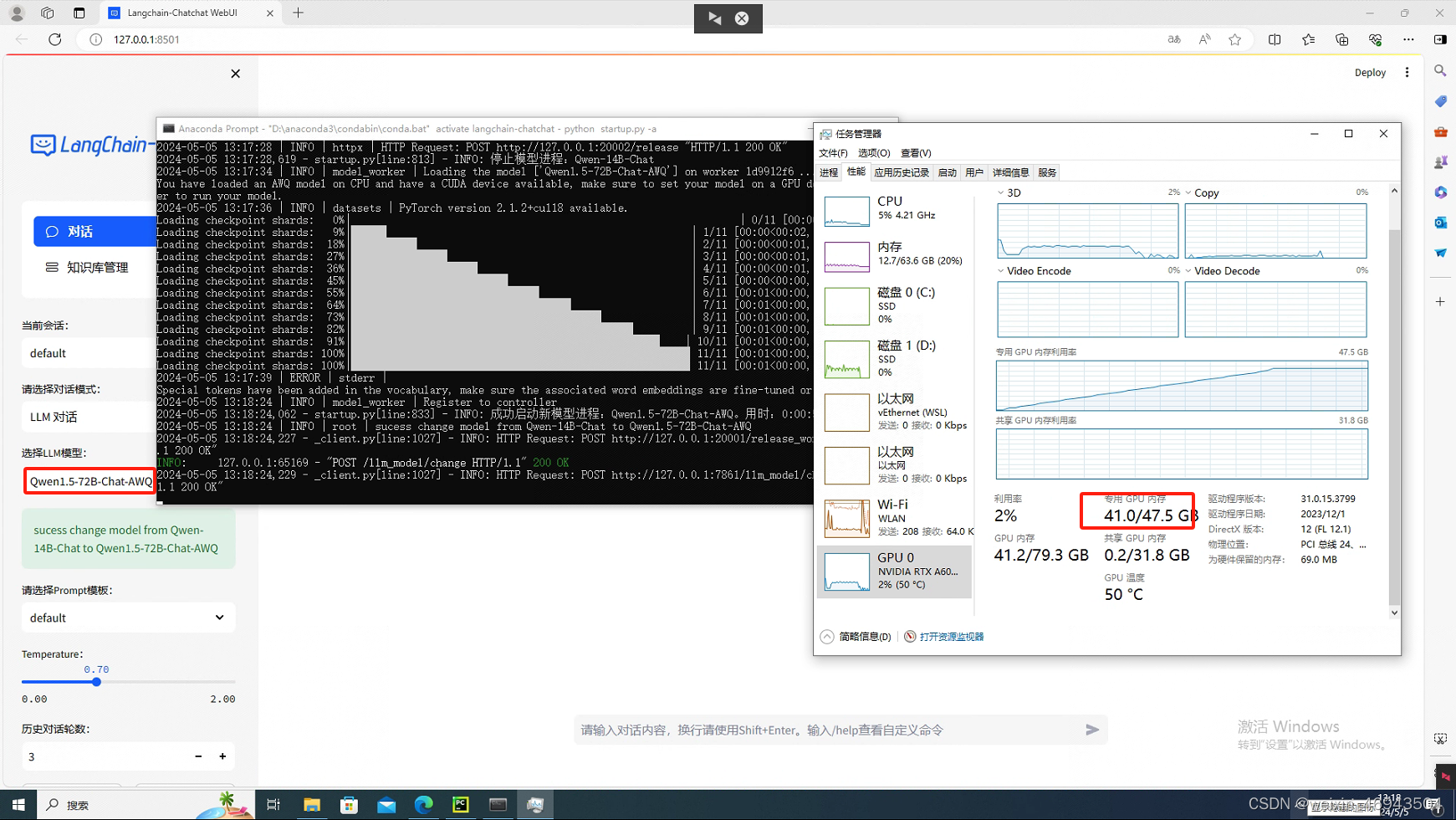
回答问题时,很慢。一个一个字蹦出来,大约10s钟出1个字这种
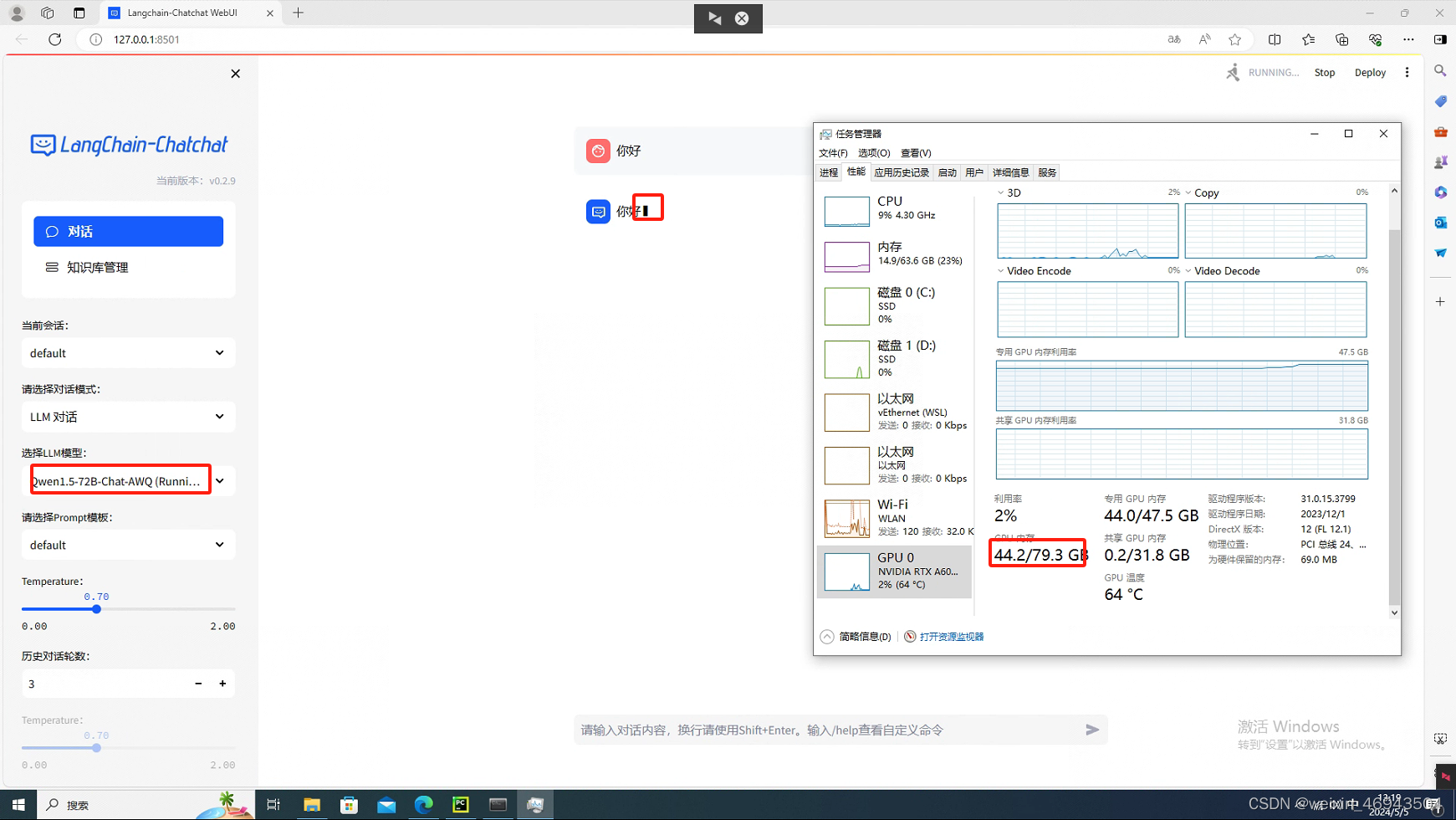
- 使用量化的32B-1.5

对话时,虽然显存占用少,但是回答却很慢,5秒1个字
















 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









