







文章目录
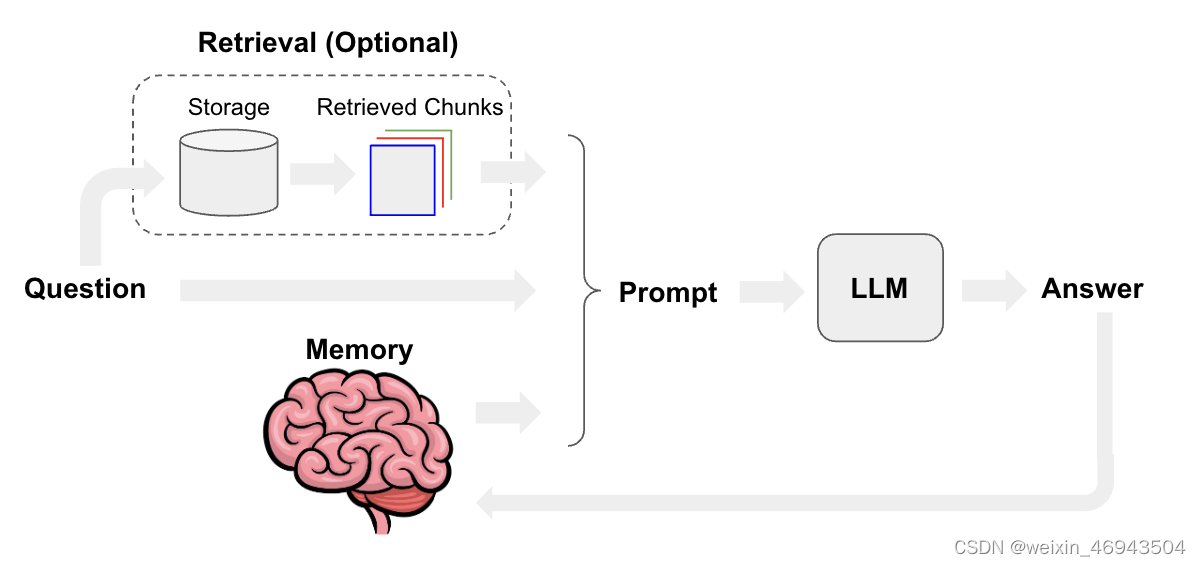
chatbot流程图
(下面我们写的代码基本也是这个框架图)
图源于官网给出的一个chatbots的示例
一、chatbot(在线Qwen)
https://python.langchain.com/docs/use_cases/question_answering/quickstart
1.langchian检索的代码
用chain实现——检索生成(langchain实现检索)+返回源信息+使用历史对话
- 第一种: 直接把chat history、检索到的内容、question拼接到prompt里,让llm基于拼接后的prompt做出回答
from langchain_community.llms import Tongyi
# from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.embeddings import FakeEmbeddings
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
llm = Tongyi(model_name="qwen-max") # Qwen
embeddings = FakeEmbeddings(size=1352)
# embeddings = DashScopeEmbeddings(model="text-embedding-v1") # embedding模型
import bs4 # Beautiful Soup是一个Python库,用于从HTML和XML文件中提取数据
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableParallel, RunnableLambda
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage, get_buffer_string
from langchain_core.prompts import format_document
from langchain.prompts import ChatPromptTemplate
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header") # 只要类名是指定这些的
)
),
)
# 加载
docs = loader.load()
# 分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 向量化并存储
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# 检索器
retriever = vectorstore.as_retriever()
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 第1种做法:直接把documents、chat history拼接到prompt里
template = """
You are an assistant for question-answering tasks.
Use the following pieces of retrieved documents and chat history to answer the question.
Please tell me how you infer answer like 'using chat history'、'using retrieved documents'、'using either of them'
Use three sentences maximum and keep the answer concise.
Question: {question}
Chat History: {chat_history}
Documents: {docs}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
# 创建一个用于存储历史对话的容器
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
answer_dict = {"answer": prompt | llm | StrOutputParser(),
"docs": itemgetter('docs'),
"question": itemgetter('question')}
rag_chian = RunnableParallel(
{ # 输入的{"question": question}会同时给每一个键
"question": RunnablePassthrough(),
"chat_history": RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
"docs": retriever | format_docs,
}
) | answer_dict
question = "I like milk"
ai_msg = rag_chian.invoke({"question": question})
memory.save_context({"question": question}, {"answer": ai_msg["answer"]})
question = "What do I like?"
ai_msg = rag_chian.invoke({"question": question})
print(ai_msg)
memory.save_context({"question": question}, {"answer": ai_msg["answer"]}) # 目前对话记录还需要自己手动存储
- 对第一种做一点优化,让大模型无论如何都用中文输出结果:
from langchain_community.llms import Tongyi
# from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.embeddings import FakeEmbeddings
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
llm = Tongyi(model_name="qwen-max") # Qwen
embeddings = FakeEmbeddings(size=1352)
# embeddings = DashScopeEmbeddings(model="text-embedding-v1") # embedding模型
import bs4 # Beautiful Soup是一个Python库,用于从HTML和XML文件中提取数据
from langchain import hub
from langchain.document_loaders import PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableParallel, RunnableLambda
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage, get_buffer_string
from langchain_core.prompts import format_document
from langchain.prompts import ChatPromptTemplate
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
# Load, chunk and index the contents of the blog.
loader = PyPDFLoader("test.pdf") # 加载文档
# 加载
docs = loader.load()
# 分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 向量化并存储
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# 检索器
retriever = vectorstore.as_retriever()
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 第1种做法:直接把documents、chat history拼接到prompt里
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个中文问答助手,你要使用中文回答问题。请你根据给出的'检索信息'和'历史对话'做出回答,请在3句话以内回答问题。",
),
("human", """
检索信息: {docs}
历史对话: {chat_history}
问题: {question}
回答:
"""),
]
)
prompt_language = ChatPromptTemplate.from_template("请将{answer}翻译成中文,如果已经是中文,直接返回它")
# 创建一个用于存储历史对话的容器
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
answer_dict = {"answer": prompt | llm | StrOutputParser(),
"docs": itemgetter('docs'),
"question": itemgetter('question')}
rag_chian = (RunnableParallel(
{ # 输入的{"question": question}会同时给每一个键
"question": RunnablePassthrough(),
"chat_history": RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
"docs": retriever | format_docs,
}
) | answer_dict)
question = "请为我解释一下:Prognostic and Health Management,PHM"
ai_msg = rag_chian.invoke({"question": question})
# print("问:", question)
print("答", ai_msg["answer"])
memory.save_context({"question": question}, {"answer": ai_msg["answer"]})
question = "我刚刚问的是什么?"
ai_msg = rag_chian.invoke({"question": question})
print("问", question)
print("答", ai_msg["answer"])
memory.save_context({"question": question}, {"answer": ai_msg["answer"]}) # 目前对话记录还需要自己手动存储
- 第二种:基于chat history和用户输入的问题让llm生成一个新的问题,基于新的问题做检索,再将检索到的内容、用户输入的问题拼接成prompt,输入到llm中,得到最终回答
from langchain_community.llms import Tongyi
# from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.embeddings import FakeEmbeddings
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
llm = Tongyi(model_name="qwen-max") # Qwen
embeddings = FakeEmbeddings(size=1352)
# embeddings = DashScopeEmbeddings(model="text-embedding-v1") # embedding模型
import bs4 # Beautiful Soup是一个Python库,用于从HTML和XML文件中提取数据
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableParallel, RunnableLambda
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage, get_buffer_string
from langchain_core.prompts import format_document
from langchain.prompts import ChatPromptTemplate
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header") # 只要类名是指定这些的
)
),
)
# 加载
docs = loader.load()
# 分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 向量化并存储
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# 检索器
retriever = vectorstore.as_retriever()
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 创建一个用于存储历史对话的容器
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
# memory.load_memory_variables:从memory中加载出历史记录:{"history":[]}
loaded_memory = RunnablePassthrough.assign(
chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
)
system_template = """
Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is.
"""
newQ_template = """
Chat History:{chat_history}
Question:{question}
standalone question:
"""
newQ_prompt = ChatPromptTemplate.from_messages(
[
("system", system_template),
("human", newQ_template),
]
)
qa_template = """
You are an assistant for question-answering tasks.
Use the following pieces of retrieved documents and chat history to answer the question.
Please tell me how you infer answer like 'using chat history'、'using retrieved documents'、'using either of them'
Use three sentences maximum and keep the answer concise.
Question: {question}
Documents: {docs}
Answer:
"""
qa_prompt = ChatPromptTemplate.from_template(qa_template)
answer_dict = {"answer": qa_prompt | llm | StrOutputParser(),
"docs": itemgetter('docs'),
"question": itemgetter('question')}
new_question_retrieve_chain = ( # 根据新问题检索,最终得到的是一系列documents对象
{"question": RunnablePassthrough(),
"chat_history": RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
}
| newQ_prompt
| llm
| StrOutputParser() # 这里输出的是新问题的字符串
| retriever
| format_docs # 这里输出的是一系列documents对象
)
rag_chain = (
# assign会把前面的{"question":xx}给new_question_retrieve_chain,并将前后结果拼接得到{"question":xx, "docs":xx}
RunnablePassthrough.assign(docs=new_question_retrieve_chain)
| answer_dict # 这里相当于是一个输入给了answer_dict中的每一个键
)
question = "I like milk"
ai_msg = rag_chain.invoke({"question": question})
print(1, ai_msg)
memory.save_context({"question": question}, {"answer": ai_msg["answer"]})
print(1, memory.load_memory_variables({}))
question = "What do I like?"
ai_msg = rag_chain.invoke({"question": question})
print(ai_msg)
memory.save_context({"question": question}, {"answer": ai_msg["answer"]}) # 目前对话记录还需要自己手动存储
- 第三种:基于chat history和用户输入的问题让llm生成一个新的问题,基于新的问题做检索,再将检索到的内容、新的问题拼接成prompt,输入到llm中,得到最终回答
from langchain_community.llms import Tongyi
# from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.embeddings import FakeEmbeddings
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
llm = Tongyi(model_name="qwen-max") # Qwen
embeddings = FakeEmbeddings(size=1352)
# embeddings = DashScopeEmbeddings(model="text-embedding-v1") # embedding模型
import bs4 # Beautiful Soup是一个Python库,用于从HTML和XML文件中提取数据
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableParallel, RunnableLambda
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage, get_buffer_string
from langchain_core.prompts import format_document
from langchain.prompts import ChatPromptTemplate
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header") # 只要类名是指定这些的
)
),
)
# 加载
docs = loader.load()
# 分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 向量化并存储
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# 检索器
retriever = vectorstore.as_retriever()
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 创建一个用于存储历史对话的容器
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
# memory.load_memory_variables:从memory中加载出历史记录:{"history":[]}
loaded_memory = RunnablePassthrough.assign(
chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
)
system_template = """
Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is.
"""
newQ_template = """
Chat History:{chat_history}
Question:{question}
standalone question:
"""
newQ_prompt = ChatPromptTemplate.from_messages(
[
("system", system_template),
("human", newQ_template),
]
)
qa_template = """
You are an assistant for question-answering tasks.
Use the following pieces of retrieved documents and chat history to answer the question.
Please tell me how you infer answer like 'using chat history'、'using retrieved documents'、'using either of them'
Use three sentences maximum and keep the answer concise.
Question: {new_question}
Documents: {docs}
Answer:
"""
qa_prompt = ChatPromptTemplate.from_template(qa_template)
answer = {"answer": qa_prompt | llm | StrOutputParser(),
"docs": itemgetter('docs'),
"new_question": itemgetter('new_question')}
rag_chian = (RunnableParallel({ # RunnableParallel包裹的范围里是求new_question,最终输出的是{"new_question":xxx}
"new_question": ({
"question": RunnablePassthrough(),
"chat_history": RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
}
| newQ_prompt
| llm
| StrOutputParser())
}).assign(docs=retriever | format_docs) # .assgin是把{"new_question":xxx}输入给retriever,并将生成的{"docs":xxx}添加到{"new_question":xxx}中
| answer) # 给answer输入的是{"new_question":xxx, "docs":xxx}
question = "I like milk"
ai_msg = rag_chian.invoke({"question": question})
print(1, ai_msg)
memory.save_context({"question": question}, {"answer": ai_msg["answer"]})
print(1, memory.load_memory_variables({}))
question = "What do I like?"
ai_msg = rag_chian.invoke({"question": question})
print(ai_msg)
memory.save_context({"question": question}, {"answer": ai_msg["answer"]}) # 目前对话记录还需要自己手动存储
用agent实现——检索问答+历史对话(langchain实现检索)
把检索做成一个工具,再prompt加入”根据检索的结果回答问题“让大模型自己能去调用这个我们的检索工具。
现在的检索是检索文章,以后把外部elasticsearch做成一个tool之后,检索的就是聊天记录了。
以后把聊天记录存成sql,给模型提供2个检索tools,一个检索文章、一个检索聊天记录。
'''
检索做成工具,让大模型去调用
'''
from langchain_community.llms import Tongyi
# from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.embeddings import FakeEmbeddings
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
llm = Tongyi(model_name="qwen-max") # Qwen
embeddings = FakeEmbeddings(size=1352)
# embeddings = DashScopeEmbeddings(model="text-embedding-v1") # embedding模型
import bs4 # Beautiful Soup是一个Python库,用于从HTML和XML文件中提取数据
from langchain import hub
from langchain.document_loaders import PyPDFLoader, TextLoader, JSONLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableParallel, RunnableLambda
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, PromptTemplate
from langchain_core.messages import AIMessage, HumanMessage, get_buffer_string
from langchain_core.prompts import format_document
from langchain.tools.retriever import create_retriever_tool
from langchain.prompts import ChatPromptTemplate
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent, load_tools
# Load, chunk and index the contents of the blog.
loader = TextLoader("text.txt", encoding='utf-8') # 加载文档
# 加载
docs = loader.load()
# 分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 向量化并存储
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# 检索器
retriever = vectorstore.as_retriever()
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 第1种做法:直接把documents、chat history拼接到prompt里
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个中文问答助手,你要使用中文回答问题。请你根据给出的'检索信息'和'历史对话'做出回答,请在3句话以内回答问题。",
),
("human", """
检索信息: {docs}
历史对话: {chat_history}
问题: {question}
回答:
"""),
]
)
prompt_language = ChatPromptTemplate.from_template("请将{answer}翻译成中文,如果已经是中文,直接返回它")
# 创建一个用于存储历史对话的容器
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
question = "请为我解释一下:Prognostic and Health Management,PHM"
memory.save_context({"question": question}, {
"answer": "Prognostic and Health Management(PHM)是一种先进的工程技术,主要用于系统或设备的健康管理。"})
tool = create_retriever_tool(
retriever,
"search_aerospace_knowledge",
"Searches and returns information about aerospace knowledge",
)
tools = [tool]
# 让大模型学会调用工具的提示词
prompt = hub.pull("hwchase17/react-chat")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 让大模型把聊天记录和检索到的航天知识作为更高优先级的回答选项
template = """请根据检索到的航天知识回答:{question}"""
prompt_first = PromptTemplate.from_template(template)
question_list = ["请问我刚刚问了什么?", "请问载人航天器系统由哪些模块组成?",
"请问我刚刚问了什么?", "你是谁?"]
for q in question_list:
ans = agent_executor.invoke({
"input": prompt_first.invoke({"question": q}).to_string(),
"chat_history": memory.load_memory_variables({})["history"]
})
memory.save_context({"question": q}, {"answer": ans["output"]})
gradio界面(可对话、无文件上传、langchain检索)
接口代码
先写好llm用agent问答的代码,命名为myInterface.py。这里的检索用的是langchain实现。
'''
检索做成工具,让大模型去调用
'''
from langchain_community.llms import Tongyi
from langchain_community.embeddings import FakeEmbeddings
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
llm = Tongyi(model_name="qwen-max") # Qwen
embeddings = FakeEmbeddings(size=1352)
from langchain.document_loaders import PyPDFLoader, TextLoader, JSONLoader
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, PromptTemplate
from langchain.tools.retriever import create_retriever_tool
from langchain.prompts import ChatPromptTemplate
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent, load_tools
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
def rag_QA(question, memory):
loader = TextLoader("text.txt", encoding='utf-8') # 加载文档
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
retriever = vectorstore.as_retriever()
tool = create_retriever_tool(
retriever,
"search_aerospace_knowledge",
"Searches and returns information about aerospace knowledge",
)
tools = [tool]
prompt = hub.pull("hwchase17/react-chat")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
template = """请根据检索到的航天知识回答:{question}"""
prompt_first = PromptTemplate.from_template(template)
ans = agent_executor.invoke({
"input": prompt_first.invoke({"question": question}).to_string(),
"chat_history": memory.load_memory_variables({})["history"]
})
return ans["output"]
gradio界面代码
仅能对话,无上传文件按钮
import gradio as gr
import time
from langchain.memory import ConversationBufferMemory
from myInterface import rag_QA
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.ClearButton([msg, chatbot])
# 创建一个用于存储历史对话的容器
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
def respond(question, chat_history):
bot_message = rag_QA(question, memory)
memory.save_context({"question": question}, {"answer": bot_message})
chat_history.append((question, bot_message))
time.sleep(2)
return "", chat_history
msg.submit(respond, [msg, chatbot], [msg, chatbot])
if __name__ == "__main__":
demo.launch()
探索本地的文本向量化模型
把chatbot接入elastic后,这个本地向量化模型应该就不需要了,因为elastic直接就把结果返回了。
在接入agent的代码中,将embedding换成HuggingFaceBgeEmbeddings
这个第一次需要联网从huggingface上下载模型文件,后面就可以直接用保存下来的了。
'''
检索做成工具,让大模型去调用
'''
from langchain_community.llms import Tongyi
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
llm = Tongyi(model_name="qwen-max") # Qwen
model_name = "BAAI/bge-reranker-base"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": True}
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name, model_kwargs=model_kwargs, cache_folder="./embedding_model", encode_kwargs=encode_kwargs
)
import bs4 # Beautiful Soup是一个Python库,用于从HTML和XML文件中提取数据
from langchain import hub
from langchain.document_loaders import PyPDFLoader, TextLoader, JSONLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableParallel, RunnableLambda
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, PromptTemplate
from langchain_core.messages import AIMessage, HumanMessage, get_buffer_string
from langchain_core.prompts import format_document
from langchain.tools.retriever import create_retriever_tool
from langchain.prompts import ChatPromptTemplate
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent, load_tools
loader = TextLoader("text.txt", encoding='utf-8') # 加载文档
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
retriever = vectorstore.as_retriever()
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 第1种做法:直接把documents、chat history拼接到prompt里
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个中文问答助手,你要使用中文回答问题。请你根据给出的'检索信息'和'历史对话'做出回答,请在3句话以内回答问题。",
),
("human", """
检索信息: {docs}
历史对话: {chat_history}
问题: {question}
回答:
"""),
]
)
prompt_language = ChatPromptTemplate.from_template("请将{answer}翻译成中文,如果已经是中文,直接返回它")
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
question = "请为我解释一下:Prognostic and Health Management,PHM"
memory.save_context({"question": question}, {
"answer": "Prognostic and Health Management(PHM)是一种先进的工程技术,主要用于系统或设备的健康管理。"})
tool = create_retriever_tool(
retriever,
"search_aerospace_knowledge",
"Searches and returns information about aerospace knowledge",
)
tools = [tool]
# 让大模型学会调用工具的提示词
prompt = hub.pull("hwchase17/react-chat")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 让大模型把聊天记录和检索到的航天知识作为更高优先级的回答选项
template = """请根据检索到的航天知识回答:{question}"""
prompt_first = PromptTemplate.from_template(template)
question_list = ["请问我刚刚问了什么?", "请问载人航天器系统由哪些模块组成?"]
for q in question_list:
ans = agent_executor.invoke({
"input": prompt_first.invoke({"question": q}).to_string(),
"chat_history": memory.load_memory_variables({})["history"]
})
memory.save_context({"question": q}, {"answer": ans["output"]})
2.elasticsearch检索的代码
现在有的思路是只要能把elasticsearch做成一个工具,就能让大模型去调用。
自定义tool的方法
- @tool
函数名就是tool名字、函数的docstring作为description、返回值就是调用这个tool之后,llm能拿到的东西 - 使用BaseTool子类
- 使用StructuredTool子类
不用自己定义tool,langchain在检索这里已经内置了支持elasticsearch的方法,这里面通过本地部署的elastic的url链接elastic,并且将其变成一个retirever。我就可以直接用create_retriever_tool来将其变成一个tool,这个方法见上述”chatbot中接入agent“
- 只要把这个做成tool,大模型会自己去调用的然后检索的
- 问题在于怎么把文件上传到elastic里去。
- 在页面上加一个上传文件的按钮,然后点击上传后,用http发一个请求给elastic?
遇到的问题
- 要上传pdf、word、ppt、xls等文件类型时,elasticsearch仅支持base64格式的、而且对上传的base64的大小有限制,这些在官方文档里有说。
因此,在往elastic里上传文件的时候要用到elastic里的attachment机制。langchain中原生的ElasticSearchBM25Retriever不支持attachment,所以自己把源码改了一下,把按contrl+点ElasticSearchBM25Retriever跳到的elastic_search_bm25.py改了:
原来的样子:
"""Wrapper around Elasticsearch vector database."""
from __future__ import annotations
import uuid
from typing import Any, Iterable, List
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetriever
class ElasticSearchBM25Retriever(BaseRetriever):
"""`Elasticsearch` retriever that uses `BM25`.
To connect to an Elasticsearch instance that requires login credentials,
including Elastic Cloud, use the Elasticsearch URL format
https://username:password@es_host:9243. For example, to connect to Elastic
Cloud, create the Elasticsearch URL with the required authentication details and
pass it to the ElasticVectorSearch constructor as the named parameter
elasticsearch_url.
You can obtain your Elastic Cloud URL and login credentials by logging in to the
Elastic Cloud console at https://cloud.elastic.co, selecting your deployment, and
navigating to the "Deployments" page.
To obtain your Elastic Cloud password for the default "elastic" user:
1. Log in to the Elastic Cloud console at https://cloud.elastic.co
2. Go to "Security" > "Users"
3. Locate the "elastic" user and click "Edit"
4. Click "Reset password"
5. Follow the prompts to reset the password
The format for Elastic Cloud URLs is
https://username:password@cluster_id.region_id.gcp.cloud.es.io:9243.
"""
client: Any
"""Elasticsearch client."""
index_name: str
"""Name of the index to use in Elasticsearch."""
@classmethod
def create(
cls, elasticsearch_url: str, index_name: str, k1: float = 2.0, b: float = 0.75
) -> ElasticSearchBM25Retriever:
"""
Create a ElasticSearchBM25Retriever from a list of texts.
Args:
elasticsearch_url: URL of the Elasticsearch instance to connect to.
index_name: Name of the index to use in Elasticsearch.
k1: BM25 parameter k1.
b: BM25 parameter b.
Returns:
"""
from elasticsearch import Elasticsearch
# Create an Elasticsearch client instance
es = Elasticsearch(elasticsearch_url)
# Define the index settings and mappings
settings = {
"analysis": {"analyzer": {"default": {"type": "standard"}}},
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": k1,
"b": b,
}
},
}
mappings = {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25", # Use the custom BM25 similarity
}
}
}
# Create the index with the specified settings and mappings
es.indices.create(index=index_name, mappings=mappings, settings=settings)
return cls(client=es, index_name=index_name)
def add_texts(
self,
texts: Iterable[str],
refresh_indices: bool = True,
) -> List[str]:
"""Run more texts through the embeddings and add to the retriever.
Args:
texts: Iterable of strings to add to the retriever.
refresh_indices: bool to refresh ElasticSearch indices
Returns:
List of ids from adding the texts into the retriever.
"""
try:
from elasticsearch.helpers import bulk
except ImportError:
raise ValueError(
"Could not import elasticsearch python package. "
"Please install it with `pip install elasticsearch`."
)
requests = []
ids = []
for i, text in enumerate(texts):
_id = str(uuid.uuid4())
request = {
"_op_type": "index",
"_index": self.index_name,
"content": text,
"_id": _id,
}
ids.append(_id)
requests.append(request)
bulk(self.client, requests)
if refresh_indices:
self.client.indices.refresh(index=self.index_name)
return ids
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
query_dict = {"query": {"match": {"content": query}}}
res = self.client.search(index=self.index_name, body=query_dict)
docs = []
for r in res["hits"]["hits"]:
docs.append(Document(page_content=r["_source"]["content"]))
return docs
修改后的样子:
"""Wrapper around Elasticsearch vector database."""
from __future__ import annotations
import uuid
from typing import Any, Iterable, List
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetriever
class ElasticSearchBM25Retriever(BaseRetriever):
"""`Elasticsearch` retriever that uses `BM25`.
To connect to an Elasticsearch instance that requires login credentials,
including Elastic Cloud, use the Elasticsearch URL format
https://username:password@es_host:9243. For example, to connect to Elastic
Cloud, create the Elasticsearch URL with the required authentication details and
pass it to the ElasticVectorSearch constructor as the named parameter
elasticsearch_url.
You can obtain your Elastic Cloud URL and login credentials by logging in to the
Elastic Cloud console at https://cloud.elastic.co, selecting your deployment, and
navigating to the "Deployments" page.
To obtain your Elastic Cloud password for the default "elastic" user:
1. Log in to the Elastic Cloud console at https://cloud.elastic.co
2. Go to "Security" > "Users"
3. Locate the "elastic" user and click "Edit"
4. Click "Reset password"
5. Follow the prompts to reset the password
The format for Elastic Cloud URLs is
https://username:password@cluster_id.region_id.gcp.cloud.es.io:9243.
"""
client: Any
"""Elasticsearch client."""
index_name: str
"""Name of the index to use in Elasticsearch."""
@classmethod
def create(
cls, elasticsearch_url: str, index_name: str, k1: float = 2.0, b: float = 0.75
) -> ElasticSearchBM25Retriever:
"""
Create a ElasticSearchBM25Retriever from a list of texts.
Args:
elasticsearch_url: URL of the Elasticsearch instance to connect to.
index_name: Name of the index to use in Elasticsearch.
k1: BM25 parameter k1.
b: BM25 parameter b.
Returns:
"""
from elasticsearch import Elasticsearch
# Create an Elasticsearch client instance
es = Elasticsearch(elasticsearch_url)
# Define the index settings and mappings
settings = {
"analysis": {"analyzer": {"default": {"type": "standard"}}},
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": k1,
"b": b,
}
},
}
mappings = {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25", # Use the custom BM25 similarity
}
}
}
# Create the index with the specified settings and mappings
es.indices.create(index=index_name, mappings=mappings, settings=settings)
return cls(client=es, index_name=index_name)
def add_texts(
self,
texts: Iterable[str],
name:str='', # name是后来自己加的
refresh_indices: bool = True,
) -> List[str]:
"""Run more texts through the embeddings and add to the retriever.
Args:
texts: Iterable of strings to add to the retriever.
refresh_indices: bool to refresh ElasticSearch indices
Returns:
List of ids from adding the texts into the retriever.
"""
try:
from elasticsearch.helpers import bulk
except ImportError:
raise ValueError(
"Could not import elasticsearch python package. "
"Please install it with `pip install elasticsearch`."
)
requests = []
ids = []
for i, text in enumerate(texts):
_id = str(uuid.uuid4())
request = {
"_op_type": "index",
"_index": self.index_name,
"content": text,
"_id": _id,
"name":name # "name":name是后来自己加的
}
ids.append(_id)
requests.append(request)
# bulk(self.client, requests)
bulk(self.client, requests, pipeline='attachment') # 这句话是自己改动的,原版在上面一句
if refresh_indices:
self.client.indices.refresh(index=self.index_name)
return ids
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
# query_dict = {"query": {"match": {"attachment.content": query}}}
query_dict = {"query": {"match": {"attachment.content": query}}} # 这句话是自己改动的,原版在上面一句
res = self.client.search(index=self.index_name, body=query_dict)
docs = []
for r in res["hits"]["hits"]:
# docs.append(Document(page_content=r["_source"]["content"]))
docs.append(Document(page_content=r["_source"]["attachment"]["content"])) # 这句话是自己改动的,原版在上面一句
return docs
- 遇到的第二个问题:如果是整篇文章当作一块上传到elastic中,elastic不会对其切分,而是将整篇文章当作一条数据。当我检索的内容在某条数据中时,会把整条数据返回给我,因此elsatic返回的是整篇文章。这就不符合要求了,我想要的只是跟问题有关的一部分内容。所以在把文件上传到elastic之前,要先自己对文件进行分割,对分割的每一小块进行base64编码,然后把base64编码再发给elastic。实现的代码如下:
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
import base64
def strToBase64(s):
''' 将字符串转换为base64字符串 '''
strEncode = base64.b64encode(s.encode('utf8'))
return str(strEncode, encoding='utf8')
def fileToBase64Splits(path):
""" 加载文本、分割文本、文本块转base64 """
if path.endswith(".pdf"):
loader = PyPDFLoader(path) # 加载文档
elif path.endswith(".txt"):
loader = TextLoader(path, encoding='utf-8') # 加载文档
elif path.endswith(".docx"):
loader = Docx2txtLoader(path) # 加载文档
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
res = []
for split in splits:
res.append(strToBase64(split.page_content))
return res
# print(fileToBase64Splits("./text.txt"))
接口代码
from langchain_community.llms import Tongyi
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
llm = Tongyi(model_name="qwen-max") # Qwen
from langchain_core.prompts import PromptTemplate
from langchain.tools.retriever import create_retriever_tool
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.retrievers import (
ElasticSearchBM25Retriever,
)
import elasticsearch
from langchain.tools import tool
from config import elasticsearch_url, INDEX_NAME
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
def rag_QA(question, memory):
elastic_retriever = ElasticSearchBM25Retriever(client=elasticsearch.Elasticsearch(elasticsearch_url),
index_name=INDEX_NAME)
tool_elastic = create_retriever_tool(
elastic_retriever,
"search_aerospace_knowledge",
"Searches and returns information about aerospace knowledge",
)
# @tool
# def search_aerospace_knowledge(query: str):
# """Searches and returns information about aerospace knowledge"""
# return "这是航天知识"
tools = [tool_elastic]
template = """
Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
TOOLS:
------
Assistant has access to the following tools:
{tools}
To use a tool, please use the following format:
```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
```
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
```
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}
"""
# prompt = hub.pull("hwchase17/react-chat")
prompt = PromptTemplate.from_template(template)
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
template = """请根据检索到的航天知识回答:{question}"""
prompt_first = PromptTemplate.from_template(template)
ans = agent_executor.invoke({
"input": prompt_first.invoke({"question": question}).to_string(),
"chat_history": memory.load_memory_variables({})["history"]
})
return ans["output"]
gradio界面代码(可对话、可文件上传、elasticsearch文本检索)
import gradio as gr
import time
from langchain.memory import ConversationBufferMemory
from langchain_community.retrievers import (
ElasticSearchBM25Retriever,
)
import elasticsearch
from myInterface import rag_QA
from utils import fileToBase64Splits
from config import elasticsearch_url, INDEX_NAME
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=1, variant='panel'): # 上传文件组件
inputs = gr.components.File(label="上传文件")
file_submit_btn = gr.Button('上传', variant='primary')
# clear_file = gr.ClearButton([inputs]) 清除上传的文件
with gr.Column(scale=5): # 对话框组件
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.ClearButton([msg, chatbot])
memory = ConversationBufferMemory( # 创建一个用于存储历史对话的容器
return_messages=True, output_key="answer", input_key="question"
)
def respond(question, chat_history):
""" 与大模型对话 """
bot_message = rag_QA(question, memory)
memory.save_context({"question": question}, {"answer": bot_message})
chat_history.append((question, bot_message))
time.sleep(2)
return "", chat_history
elastic_retriever = ElasticSearchBM25Retriever(client=elasticsearch.Elasticsearch(elasticsearch_url),
index_name=INDEX_NAME)
def generate_file(file_obj):
""" 上传文件 """
base64List = fileToBase64Splits(file_obj.name)
elastic_retriever.add_texts(base64List)
# print(type(file_obj), dir(file_obj), file_obj.name, file_obj.file)
return "上传文件"
msg.submit(respond, [msg, chatbot], [msg, chatbot])
file_submit_btn.click(generate_file, inputs)
if __name__ == "__main__":
demo.launch()
运行效果:
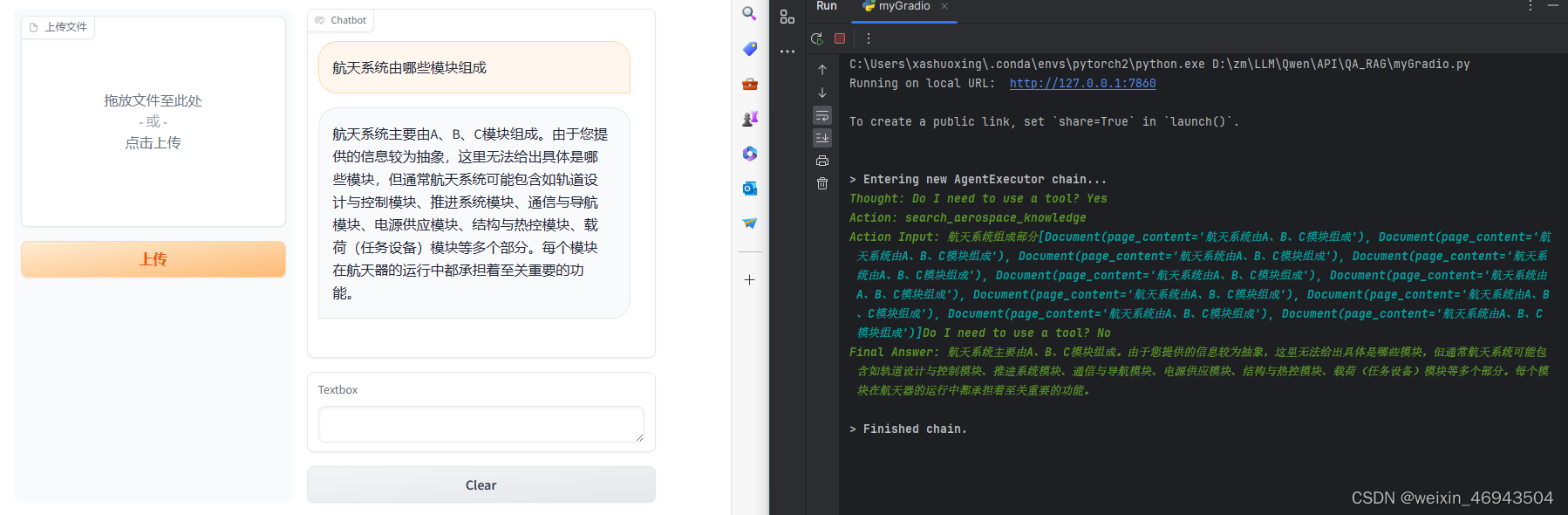
二、langchain+本地Qwen
- 运行open_ai.py
open_ai.py是基于本地部署的Qwen搭建起api接口
python open_ai.py
自定义myQwen
# 运行本文件前需要先运动open_ai.py
# 本文件是基于本地部署的Qwen API实现自己的大模型
from typing import Any, List, Mapping, Optional
import openai
openai.api_base = "http://localhost:8000/v1"
openai.api_key = "none"
from langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
class CustomLLM(LLM):
@property
def _llm_type(self) -> str:
return "custom"
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
response = openai.ChatCompletion.create(
model="myQwen",
messages=[
{"role": "user", "content": prompt}
],
stream=False,
stop=[] # 在此处添加自定义的stop words 例如ReAct prompting时需要增加: stop=["Observation:"]。
)
return response.choices[0].message.content
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {"model": "myQwen"}
# 与本地Qwen API实现简单对话
# llm = CustomLLM()
# print(llm.invoke("你好"))
myQwen做pdf检索
# 用自定义的Qwen实现文档检索
# 成功了!!!
from langchain.document_loaders import PyPDFLoader
from langchain.indexes.vectorstore import VectorstoreIndexCreator
from langchain_community.embeddings import DashScopeEmbeddings
from langchain.vectorstores import Chroma
from langchain.indexes.vectorstore import VectorStoreIndexWrapper
from myQwen import CustomLLM
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
local_persist_path = r"./vector_store"
embeddings = DashScopeEmbeddings(model="text-embedding-v1") # embedding模型
llm = CustomLLM() # Qwen
def get_index_path(index_name):
return os.path.join(local_persist_path, index_name)
def load_pdf_and_save_to_index(file_path, index_name):
loader = PyPDFLoader(file_path) # 加载文档
# VectorstoreIndexCreator能完成文档分割、向量化、存储
index = VectorstoreIndexCreator(embedding=embeddings,
vectorstore_kwargs={"persist_directory": get_index_path(index_name)}).from_loaders(
[loader])
index.vectorstore.persist() # 保存到本地
def load_index(index_name):
# 从磁盘中读取index
index_path = get_index_path(index_name)
vector_db = Chroma(
persist_directory=index_path,
embedding_function=embeddings
)
return VectorStoreIndexWrapper(vectorstore=vector_db)
def query_index_lc(index, query):
ans = index.query_with_sources(query, llm=llm, chain_type='map_reduce')
return ans["answer"]
index_name = 'first'
# load_pdf_and_save_to_index("./span.pdf", index_name)
index = load_index(index_name)
print(index.query_with_sources("entity", llm=llm, chain_type='map_reduce'))
myQwen结合agent
注意:myQwen的定义中_call里的stop要修改为 stop=["Observation:"]
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent, load_tools
from myChatQwen import CustomChatLLM
import os
os.environ["SERPAPI_API_KEY"] = "e905bf96a536438e84dd64e4efe75bc1624584995e530d78e49988a57d7996c8"
# 使用自定义的qwen
chatLLM = CustomChatLLM()
tools = load_tools(["serpapi", "llm-math"], llm=chatLLM)
# Get the prompt to use - you can modify this!
prompt = hub.pull("hwchase17/react")
# Construct the ReAct agent
agent = create_react_agent(chatLLM, tools, prompt)
# Create an agent executor by passing in the agent and tools
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
ans1 = agent_executor.invoke({"input": "谁是高启强的扮演者"})
print(ans1)
ans2 = agent_executor.invoke({"input": "《狂飙》里高启强的扮演者10年后多少岁?"})
print(ans2)
效果图
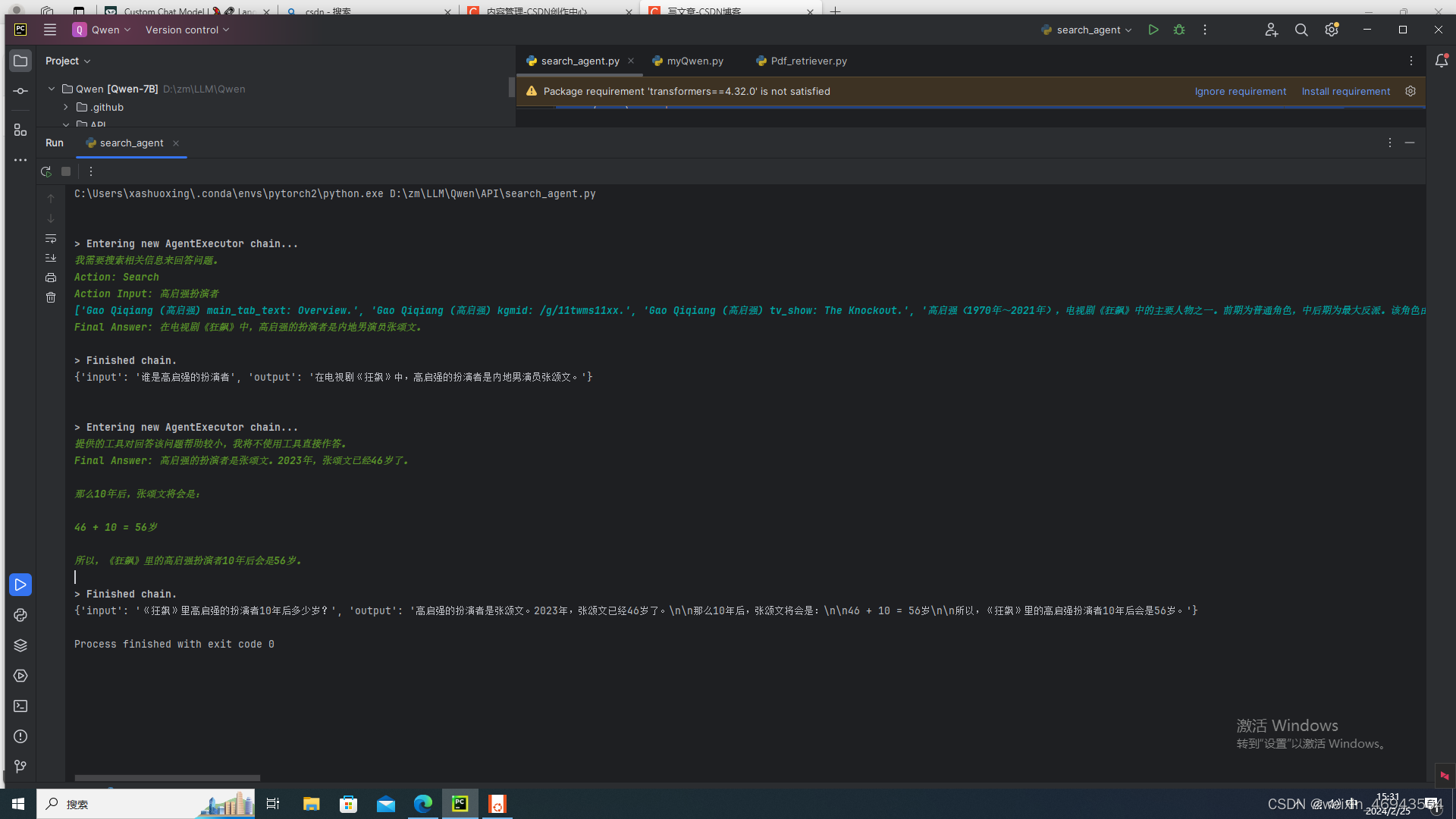
三、chatbot(用本地Qwen)
可对话、可文件上传、elasticsearch文件检索
- 第一步:先运行openai_api.py
接口代码
名字叫myInterface_with_localQwen.py
# from langchain_community.llms import Tongyi
# import os
# os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
# llm = Tongyi(model_name="qwen-max") # Qwen
from langchain_core.prompts import PromptTemplate
from langchain.tools.retriever import create_retriever_tool
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.retrievers import (
ElasticSearchBM25Retriever,
)
import elasticsearch
from langchain.tools import tool
from myQwen import CustomLLM
llm = CustomLLM()
from config import elasticsearch_url, INDEX_NAME
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
def rag_QA(question, memory):
elastic_retriever = ElasticSearchBM25Retriever(client=elasticsearch.Elasticsearch(elasticsearch_url),
index_name=INDEX_NAME)
tool_elastic = create_retriever_tool(
elastic_retriever,
"search_aerospace_knowledge",
"Searches and returns information about aerospace knowledge",
)
# @tool
# def search_aerospace_knowledge(query: str):
# """Searches and returns information about aerospace knowledge"""
# return "这是航天知识"
tools = [tool_elastic]
template = """
Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
TOOLS:
------
Assistant has access to the following tools:
{tools}
To use a tool, please use the following format:
```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
```
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
```
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}
"""
# prompt = hub.pull("hwchase17/react-chat")
prompt = PromptTemplate.from_template(template)
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
template = """请根据检索到的航天知识回答:{question}"""
prompt_first = PromptTemplate.from_template(template)
ans = agent_executor.invoke({
"input": prompt_first.invoke({"question": question}).to_string(),
"chat_history": memory.load_memory_variables({})["history"]
})
return ans["output"]
gradio界面代码
import gradio as gr
import time
from langchain.memory import ConversationBufferMemory
from langchain_community.retrievers import (
ElasticSearchBM25Retriever,
)
import elasticsearch
from myInterface_with_localQwen import rag_QA
from utils import fileToBase64Splits
from config import elasticsearch_url, INDEX_NAME
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=1, variant='panel'): # 上传文件组件
inputs = gr.components.File(label="上传文件")
file_submit_btn = gr.Button('上传', variant='primary')
# clear_file = gr.ClearButton([inputs]) 清除上传的文件
with gr.Column(scale=5): # 对话框组件
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.ClearButton([msg, chatbot])
memory = ConversationBufferMemory( # 创建一个用于存储历史对话的容器
return_messages=True, output_key="answer", input_key="question"
)
def respond(question, chat_history):
""" 与大模型对话 """
bot_message = rag_QA(question, memory)
memory.save_context({"question": question}, {"answer": bot_message})
chat_history.append((question, bot_message))
time.sleep(2)
return "", chat_history
elastic_retriever = ElasticSearchBM25Retriever(client=elasticsearch.Elasticsearch(elasticsearch_url),
index_name=INDEX_NAME)
def generate_file(file_obj):
""" 上传文件 """
base64List = fileToBase64Splits(file_obj.name)
elastic_retriever.add_texts(base64List)
# print(type(file_obj), dir(file_obj), file_obj.name, file_obj.file)
return "上传文件"
msg.submit(respond, [msg, chatbot], [msg, chatbot])
file_submit_btn.click(generate_file, inputs)
if __name__ == "__main__":
demo.launch()
本地、在线Qwen回答对比
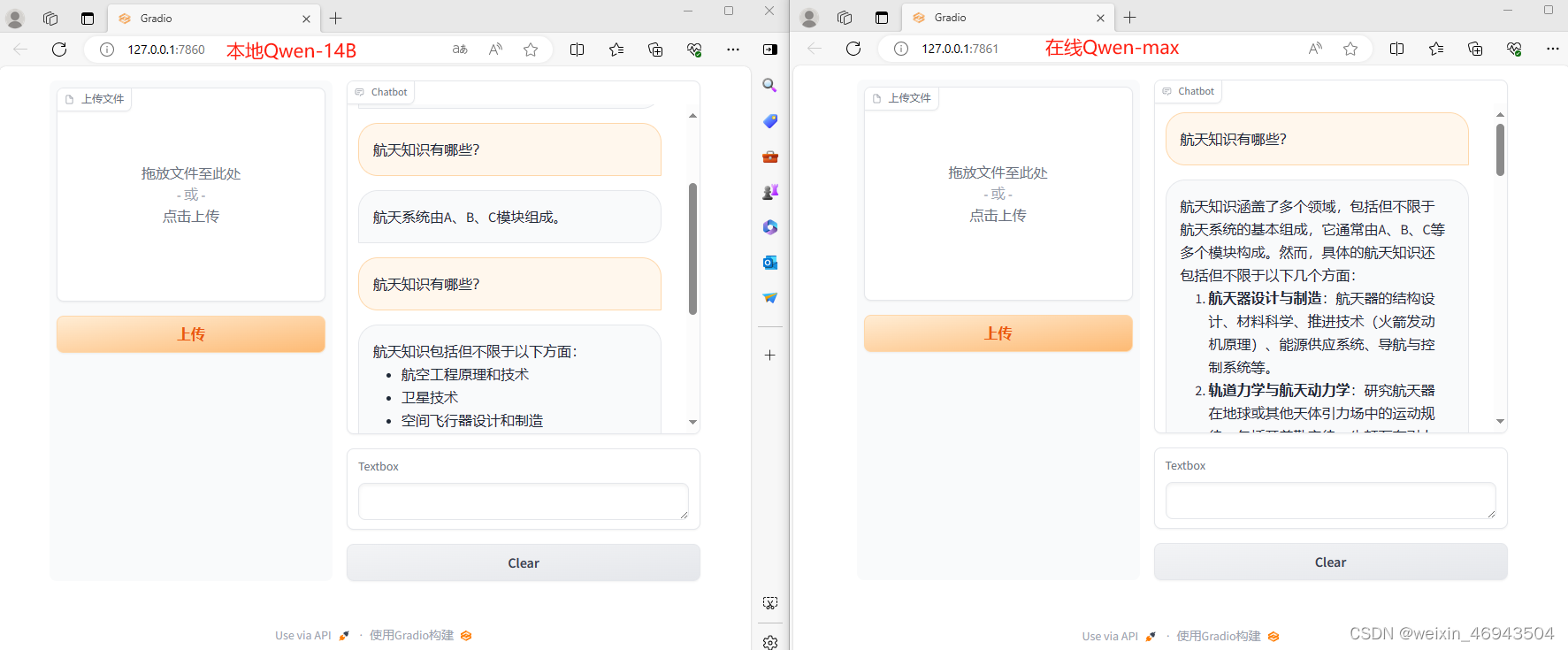
四、检索问答+总结(在线Qwen)
接口代码
from langchain_core.prompts import PromptTemplate
from langchain.tools.retriever import create_retriever_tool
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.retrievers import (ElasticSearchBM25Retriever)
import elasticsearch
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
from config import elasticsearch_url, INDEX_NAME, FILE_SAVE_PATH
from utils import getLoaderByfileType
from langchain_community.llms import Tongyi
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-dea0261124ec4df6999f6b2ccd26c9ea"
llm = Tongyi(model_name="qwen-max") # Qwen
# 检索回答
def rag_QA(question, memory):
"""检索问答"""
elastic_retriever = ElasticSearchBM25Retriever(client=elasticsearch.Elasticsearch(elasticsearch_url),
index_name=INDEX_NAME)
tool_elastic = create_retriever_tool(
elastic_retriever,
"search_aerospace_knowledge",
"Searches and returns information about aerospace knowledge",
)
# @tool
# def search_aerospace_knowledge(query: str):
# """Searches and returns information about aerospace knowledge"""
# return "这是航天知识"
tools = [tool_elastic]
template = """
Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
TOOLS:
------
Assistant has access to the following tools:
{tools}
To use a tool, please use the following format:
```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
```
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
```
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}
"""
# prompt = hub.pull("hwchase17/react-chat")
prompt = PromptTemplate.from_template(template)
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
template = """请根据检索到的航天知识回答:{question}"""
prompt_first = PromptTemplate.from_template(template)
ans = agent_executor.invoke({
"input": prompt_first.invoke({"question": question}).to_string(),
"chat_history": memory.load_memory_variables({})["history"]
})
return ans["output"]
# 从问题中抽取文件名
def getFilePath(question):
"""用大模型将包裹在《》中的文件名提取出来"""
template = """Extract the mentioned file names enclosed in "《》" without "《》" from the following questions:
question:{question}
file names:
"""
prompt = PromptTemplate.from_template(template)
getFileName_chain = (prompt | llm)
file_name = getFileName_chain.invoke({"question": question})
file_path = os.path.join(FILE_SAVE_PATH, file_name)
return file_path
# 总结文档
def summarize_text(question):
"""总结文档"""
prompt_template = """简要总结以下内容:
{text}
总结:"""
prompt = PromptTemplate.from_template(prompt_template)
refine_template = (
"你的任务是生成最终摘要\n"
"我们提供了一个现有摘要: {existing_answer}\n"
"现在有机会完善现有摘要(仅在需要时),下面有更多可用信息\n"
"------------\n"
"{text}\n"
"------------\n"
"在新信息的补充下,提炼原始摘要。如果信息没有用处,则返回原始摘要。"
)
refine_prompt = PromptTemplate.from_template(refine_template)
chain = load_summarize_chain(
llm=llm,
chain_type="refine",
question_prompt=prompt,
refine_prompt=refine_prompt,
return_intermediate_steps=True,
input_key="input_documents",
output_key="output_text",
)
file_path = getFilePath(question)
print("******用户提到的file_path********", file_path)
loader = getLoaderByfileType(file_path)
if loader is None:
return
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n"], chunk_size=1000, chunk_overlap=200,
length_function=len)
split_docs = loader.load_and_split(text_splitter=text_splitter)
result = chain({"input_documents": split_docs}, return_only_outputs=True)
return result["output_text"]
gradio界面
import gradio as gr
import time
from langchain.memory import ConversationBufferMemory
from langchain_community.retrievers import (
ElasticSearchBM25Retriever,
)
import elasticsearch
from myInterface import rag_QA, summarize_text
from utils import fileToBase64Splits, save_uploadFile
from config import elasticsearch_url, INDEX_NAME
memory = ConversationBufferMemory( # 创建一个用于存储历史对话的容器
return_messages=True, output_key="answer", input_key="question"
)
elastic_retriever = ElasticSearchBM25Retriever(client=elasticsearch.Elasticsearch(elasticsearch_url),
index_name=INDEX_NAME)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=1, variant='panel'): # 上传文件组件
inputs = gr.components.File(label="上传文件")
file_submit_btn = gr.Button('上传', variant='primary')
# clear_file = gr.ClearButton([inputs]) 清除上传的文件
with gr.Column(scale=5): # 对话框组件
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.ClearButton([msg, chatbot])
def respond(question, chat_history):
""" 与大模型对话 """
if "总结" in question:
# 总结文档
print("————————————————————正在总结文档————————————————————")
bot_message = summarize_text(question)
else:
# 检索问答
print("————————————————————正在检索问答————————————————————")
bot_message = rag_QA(question, memory)
memory.save_context({"question": question}, {"answer": bot_message})
chat_history.append((question, bot_message))
time.sleep(2)
return "", chat_history
def generate_file(file_obj):
""" 上传文件 """
save_uploadFile(file_obj.name)
base64List = fileToBase64Splits(file_obj.name)
if len(base64List) != 0:
elastic_retriever.add_texts(base64List)
# print(dir(file_obj))
return "上传文件"
msg.submit(respond, [msg, chatbot], [msg, chatbot])
file_submit_btn.click(generate_file, inputs)
if __name__ == "__main__":
demo.launch()
五、检索问答+总结(本地Qwen)
接口代码
from langchain_core.prompts import PromptTemplate
from langchain.tools.retriever import create_retriever_tool
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.retrievers import (ElasticSearchBM25Retriever)
import elasticsearch
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
from config import elasticsearch_url, INDEX_NAME, FILE_SAVE_PATH
from utils import getLoaderByfileType
from langchain_community.llms import Tongyi
import os
from myQwen import CustomLLM
llm = CustomLLM()
# 检索回答
def rag_QA(question, memory):
"""检索问答"""
elastic_retriever = ElasticSearchBM25Retriever(client=elasticsearch.Elasticsearch(elasticsearch_url),
index_name=INDEX_NAME)
tool_elastic = create_retriever_tool(
elastic_retriever,
"search_aerospace_knowledge",
"Searches and returns information about aerospace knowledge",
)
# @tool
# def search_aerospace_knowledge(query: str):
# """Searches and returns information about aerospace knowledge"""
# return "这是航天知识"
tools = [tool_elastic]
template = """
Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
TOOLS:
------
Assistant has access to the following tools:
{tools}
To use a tool, please use the following format:
```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
```
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
```
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}
"""
# prompt = hub.pull("hwchase17/react-chat")
prompt = PromptTemplate.from_template(template)
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
template = """请根据检索到的航天知识回答:{question}"""
prompt_first = PromptTemplate.from_template(template)
ans = agent_executor.invoke({
"input": prompt_first.invoke({"question": question}).to_string(),
"chat_history": memory.load_memory_variables({})["history"]
})
return ans["output"]
# 从问题中抽取文件名
def getFilePath(question):
"""用大模型将包裹在《》中的文件名提取出来"""
template = """Extract the mentioned file names enclosed in "《》" without "《》" from the following questions:
question:{question}
file names:
"""
prompt = PromptTemplate.from_template(template)
getFileName_chain = (prompt | llm)
file_name = getFileName_chain.invoke({"question": question})
file_path = os.path.join(FILE_SAVE_PATH, file_name)
return file_path
# 总结文档
def summarize_text(question):
"""总结文档"""
prompt_template = """简要总结以下内容:
{text}
总结:"""
prompt = PromptTemplate.from_template(prompt_template)
refine_template = (
"你的任务是生成最终摘要\n"
"我们提供了一个现有摘要: {existing_answer}\n"
"现在有机会完善现有摘要(仅在需要时),下面有更多可用信息\n"
"------------\n"
"{text}\n"
"------------\n"
"在新信息的补充下,提炼原始摘要。如果信息没有用处,则返回原始摘要。"
)
refine_prompt = PromptTemplate.from_template(refine_template)
chain = load_summarize_chain(
llm=llm,
chain_type="refine",
question_prompt=prompt,
refine_prompt=refine_prompt,
return_intermediate_steps=True,
input_key="input_documents",
output_key="output_text",
)
file_path = getFilePath(question)
print("******用户提到的file_path********", file_path)
loader = getLoaderByfileType(file_path)
if loader is None:
return
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n"], chunk_size=1000, chunk_overlap=200,
length_function=len)
split_docs = loader.load_and_split(text_splitter=text_splitter)
result = chain({"input_documents": split_docs}, return_only_outputs=True)
return result["output_text"]
gradio界面代码
import gradio as gr
import time
from langchain.memory import ConversationBufferMemory
from langchain_community.retrievers import (
ElasticSearchBM25Retriever,
)
import elasticsearch
from myInterface_with_localQwen import rag_QA, summarize_text
from utils import fileToBase64Splits, save_uploadFile
from config import elasticsearch_url, INDEX_NAME
memory = ConversationBufferMemory( # 创建一个用于存储历史对话的容器
return_messages=True, output_key="answer", input_key="question"
)
elastic_retriever = ElasticSearchBM25Retriever(client=elasticsearch.Elasticsearch(elasticsearch_url),
index_name=INDEX_NAME)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=1, variant='panel'): # 上传文件组件
inputs = gr.components.File(label="上传文件")
file_submit_btn = gr.Button('上传', variant='primary')
# clear_file = gr.ClearButton([inputs]) 清除上传的文件
with gr.Column(scale=5): # 对话框组件
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.ClearButton([msg, chatbot])
def respond(question, chat_history):
""" 与大模型对话 """
if "总结" in question:
# 总结文档
print("————————————————————正在总结文档————————————————————")
bot_message = summarize_text(question)
else:
# 检索问答
print("————————————————————正在检索问答————————————————————")
bot_message = rag_QA(question, memory)
memory.save_context({"question": question}, {"answer": bot_message})
chat_history.append((question, bot_message))
time.sleep(2)
return "", chat_history
def generate_file(file_obj):
""" 上传文件 """
save_uploadFile(file_obj.name)
base64List = fileToBase64Splits(file_obj.name)
if len(base64List) != 0:
elastic_retriever.add_texts(base64List)
# print(dir(file_obj))
return "上传文件"
msg.submit(respond, [msg, chatbot], [msg, chatbot])
file_submit_btn.click(generate_file, inputs)
if __name__ == "__main__":
demo.launch()
运行效果
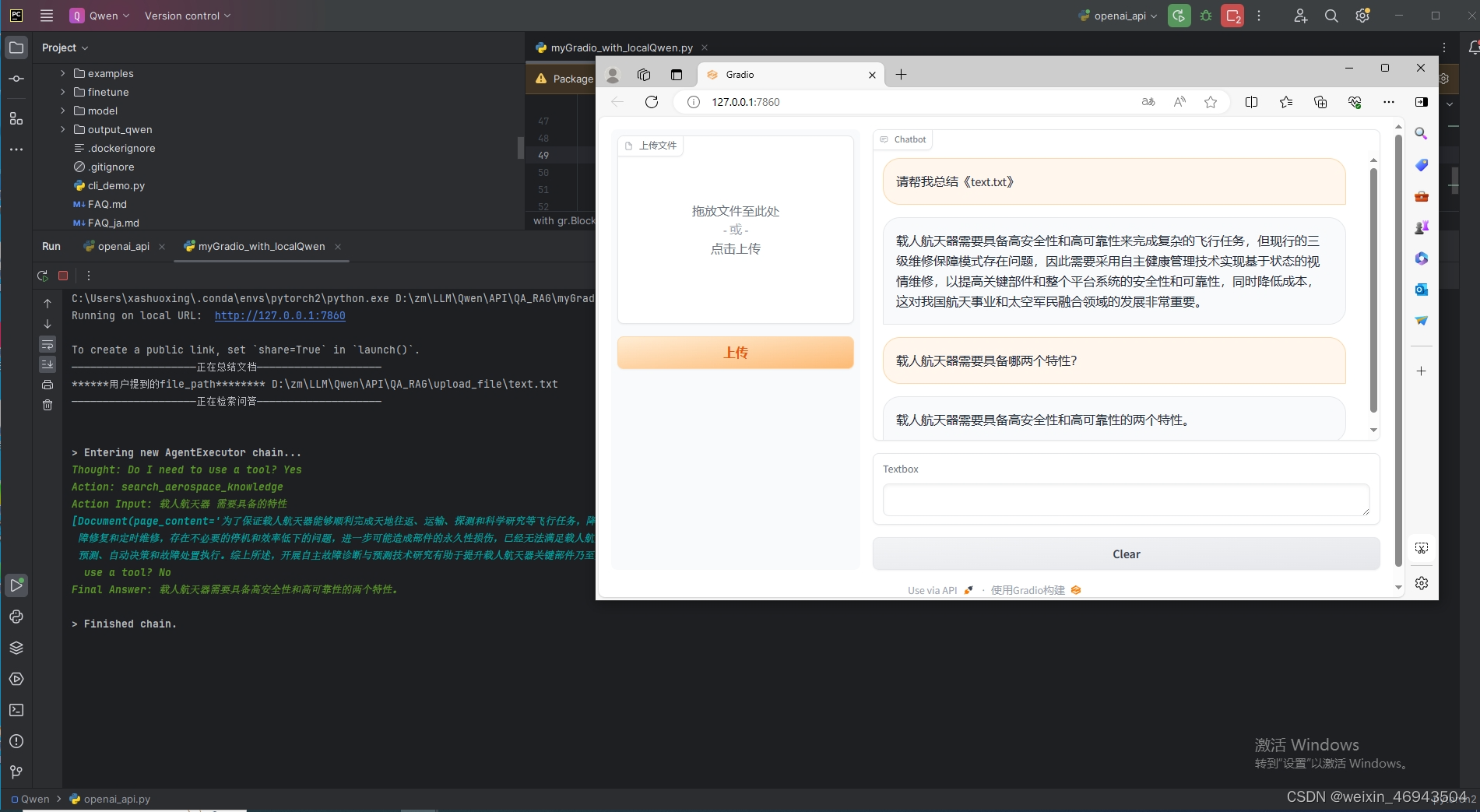
六、其他文件
utils.py
这里主要是一些工具函数
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
import base64
import shutil
import os
from config import FILE_SAVE_PATH
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
def strToBase64(s):
''' 将字符串转换为base64字符串 '''
strEncode = base64.b64encode(s.encode('utf8'))
return str(strEncode, encoding='utf8')
def getLoaderByfileType(path):
"""根据文件类型获得loader"""
if not os.path.exists(path):
print(f"{path}不存在")
return None
if path.endswith(".pdf"):
loader = PyPDFLoader(path) # 加载文档
elif path.endswith(".txt"):
loader = TextLoader(path, encoding='utf-8') # 加载文档
elif path.endswith(".docx"):
loader = Docx2txtLoader(path) # 加载文档
else:
print("不支持的文件类型,请使用['.pdf', '.txt', '.docx']")
return None
return loader
def fileToBase64Splits(path):
""" 加载文本、分割文本、文本块转base64 """
loader = getLoaderByfileType(path)
if loader is None:
return []
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
res = []
for split in splits:
res.append(strToBase64(split.page_content))
return res
def save_uploadFile(temp_file_path):
"""上传的文件保存到本地"""
file_name = os.path.basename(temp_file_path)
target_file_path = os.path.join(FILE_SAVE_PATH, file_name)
shutil.copy(temp_file_path, target_file_path)
print(file_name, "文件本地保存成功")
# print(fileToBase64Splits("./text.txt"))
config.py
这里写配置信息
import os
elasticsearch_url = "http://localhost:9200"
INDEX_NAME = 'docwrite'
FILE_SAVE_PATH = os.path.join(os.path.dirname(__file__), "upload_file")
















 1894
1894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









