目录 Meta-Argument depends_on count for_each provider lifecycle 常用函数 concat flatten lookup element merge









 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




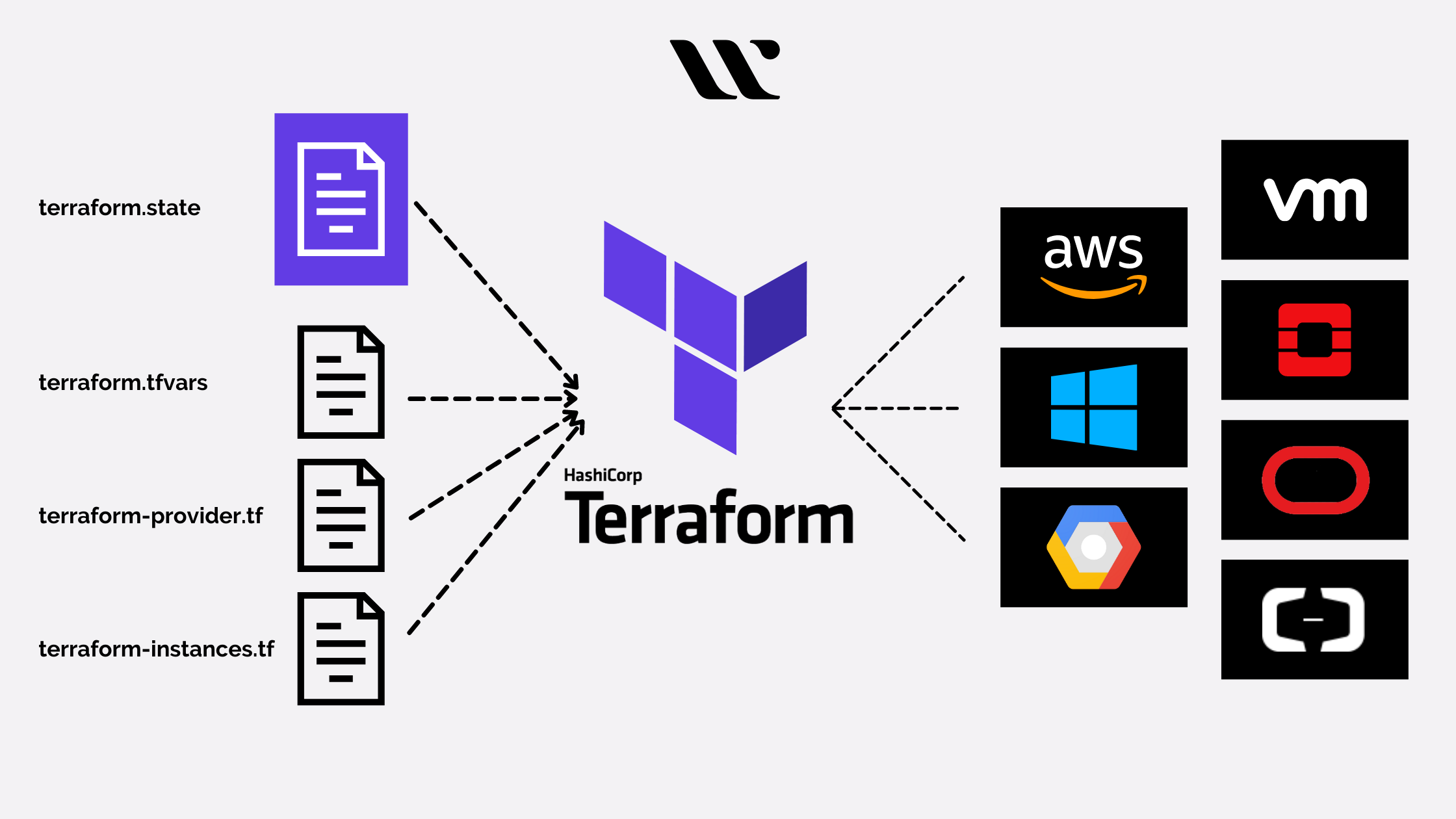
 本文介绍了Terraform中用于资源管理的关键元参数,如depends_on用于指定资源依赖,count和for_each用于创建多个资源实例,provider指定资源提供商,lifecycle控制资源生命周期,以及concat、flatten、lookup等常用函数的使用。这些概念和函数是理解和编写Terraform配置文件的基础。
本文介绍了Terraform中用于资源管理的关键元参数,如depends_on用于指定资源依赖,count和for_each用于创建多个资源实例,provider指定资源提供商,lifecycle控制资源生命周期,以及concat、flatten、lookup等常用函数的使用。这些概念和函数是理解和编写Terraform配置文件的基础。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 219
219





