










 本文详细介绍了如何在Java环境中下载和配置CoreNLP,重点在于如何处理中文情感分析,包括下载对应版本的中文模型,启动服务,发送HTTP请求到服务端进行情感分类,并提示注意中文模型版本的兼容性问题。
本文详细介绍了如何在Java环境中下载和配置CoreNLP,重点在于如何处理中文情感分析,包括下载对应版本的中文模型,启动服务,发送HTTP请求到服务端进行情感分类,并提示注意中文模型版本的兼容性问题。
网上的corenlp教程通篇一律的都是词性标注,句法分析,分词等,几乎没有关于情感分析的教程,经过探索,把自己总结的完整经验分享给大家!
1.下载jdk
因为CoreNLP是用java编写的,运行需要java环境,下载地址为https://www.oracle.com/cn/java/technologies/downloads/#jdk21-windows https://www.oracle.com/cn/java/technologies/downloads/#jdk21-windows,我这里下载的是jdk21。
https://www.oracle.com/cn/java/technologies/downloads/#jdk21-windows,我这里下载的是jdk21。
![]()
2.下载并设置CoreNLP
进入CoreNLP官网:https://stanfordnlp.github.io/CoreNLP/https://stanfordnlp.github.io/CoreNLP/我这里下载的是4.5.6版本,因为模型默认的是英文版本,如果需要处理中文的话还需要下载对应的中文模型。如下图所示: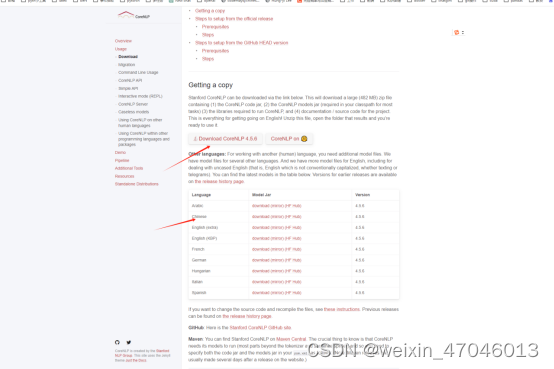
3.将中文的jar包移动到文件夹CoreNLP的根目录
将第二步骤下载的中文模型jar包移动到CoreNLP的根目录中。如图所示。
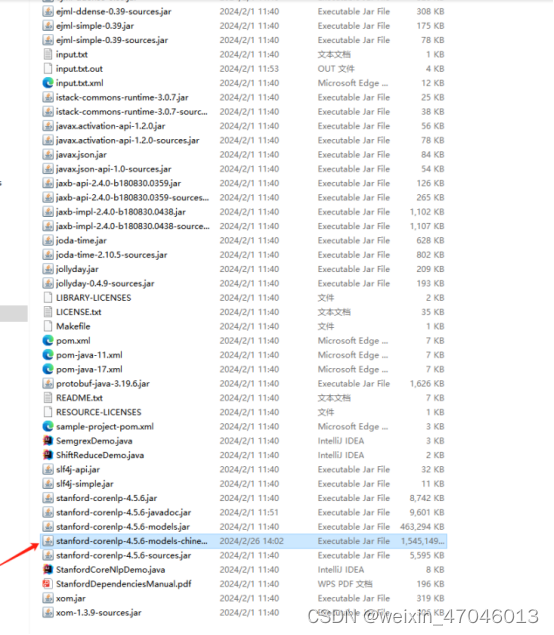
4.启动服务
命令行进入CoreNLP的根目录,
例如我的CoreNLP根目录: E:\jiedan\stanford-corenlp-4.5.6\stanford-corenlp-4.5.6>
然后执行命令启动服务:java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 4454
其中端口4454是自己设置的,只要不和主机的其他端口所冲突就可以。
5.向服务端发送请求,完成情感分类等需求
我这里使用的是requests库发送http请求。具体代码如下::
import requests
#服务端地址
corenlp_url = 'http://localhost:4454/?properties={"annotators":"sentiment","outputFormat":"json"}'
def analyze_sentiment(text):
data = text.encode('utf-8')
# 发送 POST 请求
response = requests.post(corenlp_url, data=data, headers={'Connection': 'close'})
# 解析响应
if response.status_code == 200:
json_response = response.json()
# 进行情感分类
sentiment = json_response['sentences'][0]['sentiment']
return sentiment
else:
print("Error:", response.status_code)
return None运行代码:
if __name__ == "__main__":
text = "今天吃的午饭很香!。"
sentiment = analyze_sentiment(text)
print("情感分析结果:", sentiment)6.结果
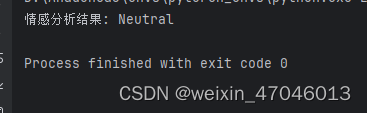

















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









