






需要完整代码和论文私信我
论文文件总览

实验数据分析图总览
window_tree总览
数据总览
目录

摘 要
电力系统的电力负荷预测在现实中有着重要的作用,其预测结果直接影响能源的合理利用和电力的供需平衡,以及给社会带来的经济效益与社会效益。本文使用ARIMA、Prophet、LightGBM、Xgboost、LSTM和GRU模型对未来10天的电力负荷进行预测,其中LSTM和GRU模型的预测精度的R²系数达到了0.96101和0.98527,效果非常好。本文还将各行业每天用电负荷相关数据与气象数据进行结合实现特征构建,构建出20个天气特征和时间特征,使用GRU模型对各行业的未来90天的电力系统负荷进行预测。由于可训练数据过少,在结合其他特征的情况下,发现大工业类型行业的最大值有功功率电力系统负荷预测精度R²系数有0.72082,在最小值有功功率预测的精度值R²系数仅有0.26212,其他行业的均普遍较低。本文简洁易操作的电力负荷分析预测平台和电力监控平台,帮助用户直接操作电力负荷数据和直观查看电力负荷历史数据情况和未来的预测情况。
关键词:电力系统负荷预测;时间序列;特征构建;循环神经网络;分析预测平台
城市电力负荷分析预测系统
1引言
1.1背景
电力系统的电力负荷预测在现实中有着重要的作用,其预测结果直接影响能源的合理利用和电力的供需平衡,以及给社会带来的经济效益与社会效益。电力系统负荷预测是需要根据电力负荷的历史数据,与相关历史天气数据等天气影响,经济状况、社会现状等基础数据作为预测支撑对未来一段时间内的系统负荷做出预测。电力系统负荷预测对于电力系统安全、可靠、经济运行具有重要意义。电力系统负荷预测一般以预测时间周期进行分类,一般有短期、中期和长期电力系统负荷预测。
电力系统负荷(电力需求量,即有功功率)预测是指充分考虑历史的系统负荷、经济状况、气象条件和社会事件等因素的影响,对未来一段时间的系统负荷做出预测。负荷预测是电力系统规划与调度的一项重要内容。短期(两周以内)预测是电网内部机组启停、调度和运营计划制定的基础;中期(未来数月)预测可为保障企业生产和社会生活用电,合理安排电网的运营与检修决策提供支持;长期(未来数年)预测可为电网改造、扩建等计划的制定提供参考,以提高电力系统的经济效益和社会效益。
复杂多变的气象条件和社会事件等不确定因素都会对电力系统负荷造成一定的影响,使得传统负荷预测模型的应用存在一定的局限性。同时,随着电力系统负荷结构的多元化,也使得模型应用的效果有所降低,因此电力系统负荷预测问题亟待进一步研究。
1.2本文工作
本文的工作主要是对短中期的电力系统负荷进行多模型对比,对比传统的ARIMA、Prophet模型,LightGBM与Xgboost机器学习模型和LSTM、GRU模型在电力系统负荷中短期预测上的预测精度,并且使用天气气象数据与时间数据进行时间序列特征构建,助于预测中期的电力系统负荷。
最后本文基于训练得到的模型,搭载应用到本文开发的城市电力负荷分析预测平台中,用于城市电力负荷数据的分析和预测;本文还开发一个城市电力负荷监控预测平台,目的在于监控城市四个主要行业的电力负荷情况和预测城市未来的电力负荷情况,助力城市走先智能化,帮助国家政府在电力方面做决策判断给予一个参考。
1.3本文意义
中国的电力行业还处在不断摸索和改革的过程中,随着电力系统负荷结构的多元化,也使得模型应用的效果有所降低。本文利用各行业的电荷数据,通过数据挖掘技术手段挖掘其中潜在的有用信息,建立起一套高效的电力系统负荷预测方法,对掌握各行业的生产和经营状况、复工复产和后续发展走势有着重要的意义。
除此之外,本有将有助于为电力系统调度运行提供依据,对于短期预测结果,可用于对各发电厂电量来合理安排发电机组的启停,并作为拟定用户发电计划的参考依据。对于中期预测结果,可用于调整月度发电计划、制定机组的大修计划等。通过本文的数据预测模型,电力系统负荷的预测结果得到大幅度提高,甚至无需具备专业的电力系统知识,即能做出正确的预测,规避不必要的浪费和风险。
从研究方法论的角度看,在大数据的时代进程之下,各种预测方法也随之愈加发展成熟,不断搜寻更新更好的算法注入到新环境下有着很大的实用价值。深度学习方法相较于传统负荷预测模型而言,打破了其应用的局限性,对提升精度具有极大的价值。而随着电力系统负荷结构的多元化,深度学习技术的快速发展,无疑为电力系统负荷预测研究提供了新的方法支持。
2数据介绍
2.1数据来源
本文的所使用的实验数据来源于第十届数据挖掘挑战赛泰迪杯B题的数据,主要有附件1、附件2和附件3三份数据。附件1数据是某地区间隔15min记录的电力负荷情况,详情可见下图。
图1 数据详情
附件2主要是包含了该地区主要的四个行业的电力负荷数据,四个行业包括大工业、商业、普通工业和非普工业,数据详情可见下图。
图2 数据详情
附件3指的是该地区在上述数据时间内的天气情况,电力负荷情况在一定的情况下与当地的天气情况有关,数据详情可见下图。
图3 数据详情
2.2数据可视化
数据可视化可以了解一个数据的总体规模和分布情况,有助于后面的数据预处理和数据分析,非常重要。例如各行业用电情况(除2019年)分别是大工业>商业>普通工业>非普工业,前两个行业用电负荷突破了千万级别,而且大工业的用电负荷占据了二分之一,如图5.16所示。相比与前两个行业,普通工业和非普工业用电负荷则显得微不足道。
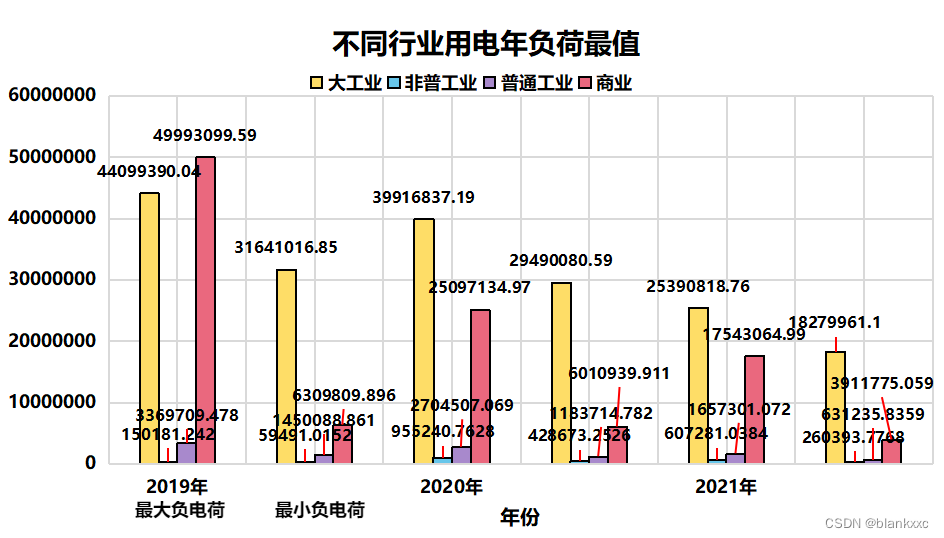
图4 不同行业用电年负荷最值
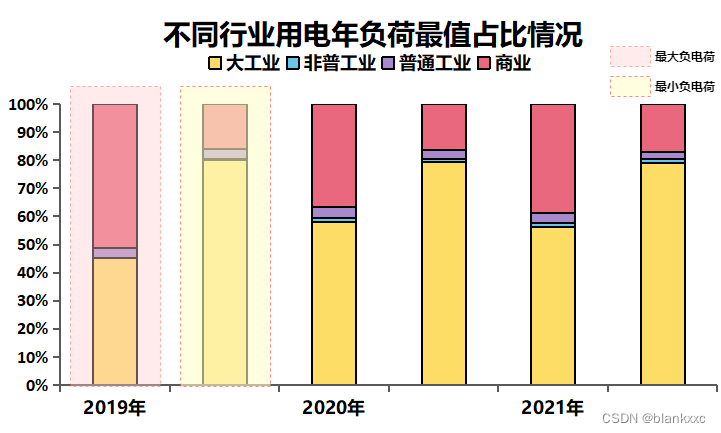
图5 不同行业用电年负荷最值占比情况
我们知道,元旦、春节、清明节、劳动节、端午节、中秋节、国庆节是法定节假日,周末是休息日,在这些时间段,各行业的电力用电负荷情况都是会受到影响的。这里本文休息日以11月份为例,节假日以春节和国庆节为例,通过绘制折线图将突变点呈现出来。
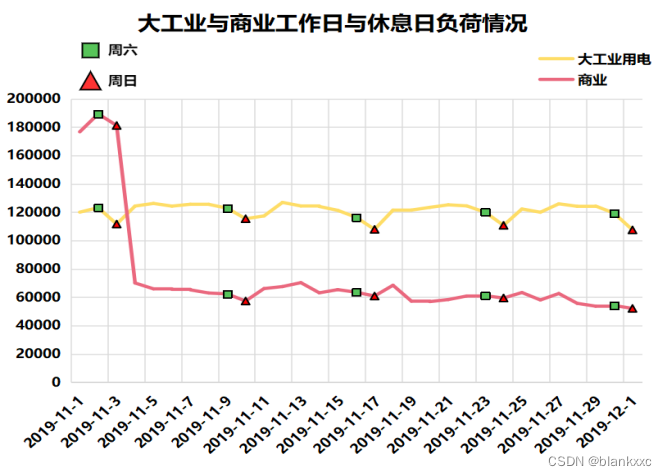
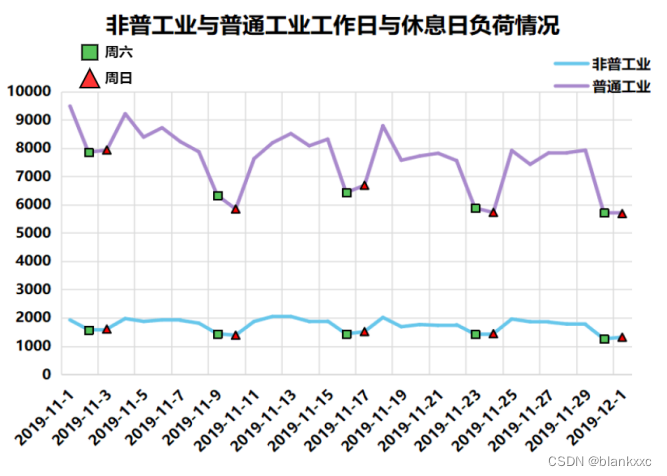
图6 各个行业工作日与休息日负荷情况
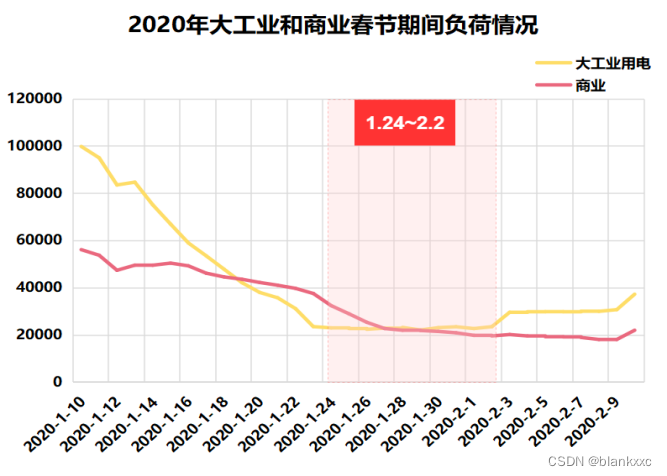
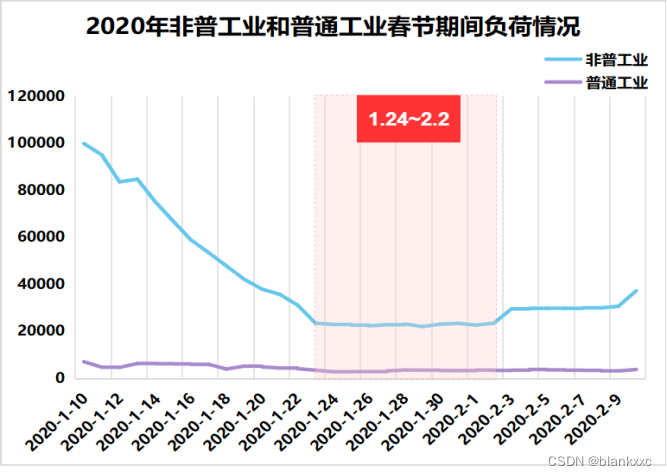
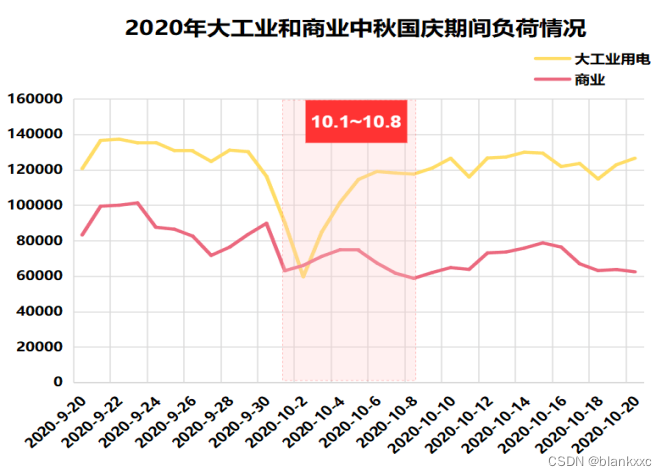
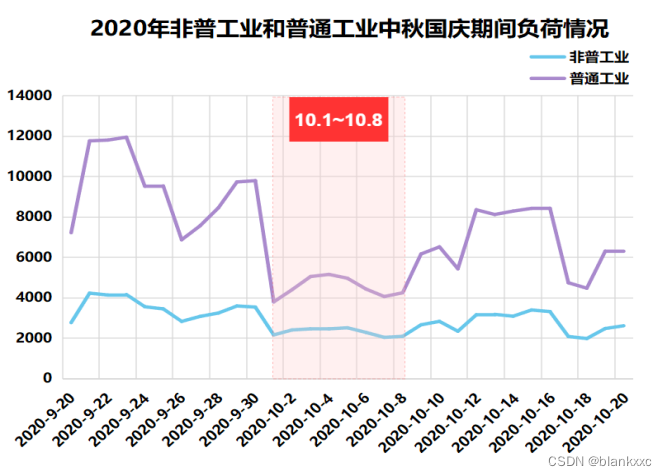
图7 各个行业节假日负荷情况
3理论介绍
3.1缺失值处理
最常用的处理缺失值的方法包括数据删除和数据填补两种。一般来说,我们更倾向于保留数据而不是删除。
(1)数据删除
直接删除有缺失值的时间段。
(2)数据填补
基于完整数据集的其他值填补缺失值。
- 移动平均法
移动平均法是一种简单平滑预测技术,它的基本思想是:根据时间序列资料、逐项推移,依次计算包含一定项数的序时平均值,以反映长期趋势的方法。因此,当时间序列的数值由于受周期变动和随机波动的影响,起伏较大,不易显示出事件的发展趋势时,使用移动平均法可以消除这些因素的影响,显示出事件的发展方向与趋势,然后依趋势线分析预测序列的长期趋势。其计算方法如下公式所示:
Ft=At-1+At-2+At-3+…+At-nn#1
其中,F_t表示对下一期的预测值,n表示移动平均的时期个数A_(t-1)表示前期实际值,A_(t-2),A_(t-3),A_(t-n)代分别表示前两期、前三期直至前n期的实际值。
- 插值法
插值法根据已知的数据序列,找到其中的规律,然后根据找到的这个规律,来对其中尚未有数据记录的点进行数值估计。选取已知的两点(x_0,y_0)和(x_1,y_1),假设缺失值与两点存在未知线性函数f的拟合分布,则缺失点处值如公式所示:
fx,y=fx0+wfx1-fx0#2
3.2归一化处理
Xnorm=X-XminXmax-Xmin#3
其中,X_norm为归一化后的数据,X为原始数据,X_max、X_min分别为原始数据集的最大值和最小值。
3.3模型评价指标
客观全面地分析预测结果,对于评价负荷预测模型的效果有着重要意义。本文基于人工智能算法构建主预测模型,采用误差大小和模型训练时间作为评价预测模型的标准。误差越小、训练时间越短,表明该模型的预测精确度越高、性能越好。
文中采用MSE、RMSE、MAE和TT作为评价预测结果优劣的标准,具体表示形式如下:
(1)均方误差(MSE)
MSE=1ni=1nyi-yi2#4
(2)均方根误差(RMSE)
RMSE=1ni=1nyi-yi2#5
(3)平均绝对误差(MAE)
MAE=1ni=1nyi-yi#6
(4)R²分数
R2=1-i=1nyi-yi2i=1nyi-yi2#7
(5)训练时间(TT)
TT=T2-T1#8
其中,n
表示样本数量,yi
表示第i
个样本的真实值,yi
表示第i
个样本的预测值,T2
为训练结束的实时时间,T1
为训练开始时的实时时间。
3.4 Prophet
prophet算法采用的是加性模型,由四个项组成:
yt=gt+st+ht+ϵt#9
其中,g(t)
表示趋势项,它表示时间序列在非周期上面的变化趋势;s(t)
表示周期项,或者称为季节项,一般来说是以周或者年为单位;h(t)
表示节假日项,表示时间序列中那些潜在的具有非固定周期的节假日对预测值造成的影响;ϵ(t)
即误差项或者称为剩余项,表示模型未预测到的波动,ϵ(t)
服从高斯分布。
Prophet算法就是通过拟合这几项,然后最后把它们累加起来就得到了时间序列的预测值。
(1)趋势项模型g(t)
趋势项有两个重要的函数,一个是基于逻辑回归函数的,另一个是基于分段线性函数的。
①基于逻辑回归的趋势项
gt=Ct1+exp-k+atTδ∙t-m+atTγ#10
at=a1t,⋯,aStT,δ=δ1,…,δST,γ=γ1,…,γST#11
其中,C(t)
表示承载量,它是一个随时间变化的函数,限定了所能增长的最大值。
k
表示增长率。m
表示偏移量,当增长率k调整后,每个changepoint点对应的偏移量m
也应该相应调整以连接每个分段的最后一个时间点,表达式如下:
γj=sj-m-l<jγl∙1-k+l<jδlk+l≤jδl#12
②基于分段线性函数的趋势项
gt=k+atTδ∙t+m+atTγ#13
其中,k表示增长率,δ
表示增长率的变化量,m
表示偏移量。
(2)季节性趋势s(t)
由于时间序列中有可能包含多种天,周,月,年等周期类型的季节性趋势,因此,傅里叶级数可以用来近似表达这个周期属性。
使用傅立叶级数来模拟时间序列的周期性:假设P表示时间序列的周期,P=365.25表示以年为周期,P=7表示以周为周期。它的傅立叶级数的形式都是:
st=n=1Nancos2πntP+bnsin2πntP#14
N表示希望在模型中使用的这种周期的个数,较大的N值可以拟合出更复杂的季节性函数,然而也会带来更多的过拟合问题。
(3)节假日效应h(t)
对于第i个节假日来说,Di
表示该节假日的前后一段时间。为了表示节假日效应,需要一个相应的节假日函数,同时需要一个参数κi
来表示节假日的影响范围。假设有L个节假日,那么节假日效应模型就是:
ht=Ztκ=i=1Lκi∙1t∈Di#15
Zt=1t∈D1},…,1t∈DL}#16
κ=κ1,…,κLT#17
其中,κ~Normal(0,v2)
并且该正太分布是受到v=holidays_prior_scale这个指标影响的。
3.5 ARIMA
ARIMA模型的全称是自回归移动平均模型,是用来预测时间序列的一种常用的统计模型,一般记作ARIMA(p,d,q)。其中p是数据本身的滞后数,是AR模型即自回归模型中的参数。d是时间序列数据需要几次差分才能得到稳定的数据。q是预测误差的滞后数,是MA模型即滑动平均模型中的参数。
(1)p参数与AR模型
AR模型描述的是当前值与历史值之间的关系,滞后p阶的AR模型可以表示为:
yt=u+θ1yt-1+θ2yt-2+…+θpyt-p+et#18
其中u
是常数,et
代表误差。
(2)q参数与MA模型
MA模型描述的是当前值与自回归部分的误差累计的关系,滞后q阶的MA模型可以表示为:
yt=u+et+θ1et-1+…+θqet-q#19
其中u
是常数,et
代表误差。
(3)d参数与差分
yt=Yt-Yt-1#20
一阶差分:
yt=Yt-Yt-1-Yt-1-Yt-2#21
二阶差分:
yt=u+θ1yt-1+θ2yt-2+…+θpyt-p+et+θ1et-1+…+θqet-q#22
(4)ARIMA=AR+MA
ARIMA模型使用步骤:
①获取时间序列数据;
②观测数据是否为平稳的,否则进行差分,化为平稳的时序数据,确定d;
③通过观察自相关系数ACF与偏自相关系数PACF确定q和p。
3.6 XGBoost
XGBoost是一种Boosting型的树集成模型,在梯度提升决策树GBDT基础上扩展,能够进行多线程并行计算,通过迭代生成新树,即可将多个分类性能较低的弱学习器组合为一个准确率较高的强学习器。XGBoost采用随机森林对字段抽样,将正则项引入损失函数中,从而防止模型过拟合,并降低模型计算量。具体算法步骤如下:
①优化目标。假设模型具有k个决策树,即:
yi=i=1kfkxi,fk∈F#23
其中,xi
是第i个输入样本,yi
为经过映射关系fk
计算出的预测值;F为所有映射关系集合。优化目标以及损失函数为:
Lt=i=1nlyi,yt-1i+ftxi+Ωft#24
其中,L(t)
为第t次迭代时目标函数,n为样本数量,y(t-1)i
为第t-1次迭代时模型的预测值,ft(xi
)为新加入的函数,Ω(ft
)为正则项。
②对L(t)
进行二阶泰勒展开和移除常数项操作后可得:
Lt≅j=1Ti∈Ijdiwj+12i∈Ijgi+λwj2+γN#25
其中,di
为l对y(t-1)i
的一阶导数,gi
为对y(t-1)i
的二阶导数,N为叶子节点个数,Ij
为每个叶子节点上样本集合,wj2
为每个叶子节点分数的L2
模的平方,λ
和γ
为比重系数,防止产生过拟合。
3.7 LightGBM
LightGBM 是一个梯度Boosting框架,使用基于决策树的学习算法。它可以说是分布式的,高效的,有以下优势:
①更快的训练效率;
②低内存使用;
③更高的准确率;
④支持并行化学习。
实验证明,在某些数据集上使用LightGBM并不损失精度,甚至有时还会提升精度。以下为两种主要算法。
(1)GOSS 算法
输入:训练数据,迭代步数d,大梯度数据的采样率 a,小梯度数据的采样率b,损失函数和若学习器的类型(一般为决策树);
输出:训练好的强学习器;
①根据样本点的梯度的绝对值对它们进行降序排序;
②对排序后的结果选取前 a*100%的样本生成一个大梯度样本点的子集;
③对剩下的样本集合(1-a)*100%的样本,随机的选取b*(1-a)*100% 个样本点,生成一个小梯度样本点的集合;
④将大梯度样本和采样的小梯度样本合并;
⑤将小梯度样本乘上一个权重系数;
⑥使用上述的采样的样本,学习一个新的弱学习器;
⑦不断地重复①~⑥步骤直到达到规定的迭代次数或者收敛为止。
通过上面的算法可以在不改变数据分布的前提下不损失学习器精度的同时大大的减少模型学习的速率。
(2)EFB算法
步骤如下:
①将特征按照非零值的个数进行排序;
②计算不同特征之间的冲突比率;
③遍历每个特征并尝试合并特征,使冲突比率最小化。
3.8 LSTM
LSTM通过引入了三个门来控制信息的传递,分别是遗忘门ft![]() 、输入门it
、输入门it![]() 和输出门ot
和输出门ot![]() ,三个门的作用为:
,三个门的作用为:
(1)遗忘门:控制上一时刻的内部状态ct-1![]() 需要遗忘多少信息;
需要遗忘多少信息;
(2)输入门:控制当前时刻的候选状态ct![]() 有多少信息需要保存;
有多少信息需要保存;
(3)输出门:控制当前时刻的内部状态ct![]() 有多少信息需要输出给外部状态ht
有多少信息需要输出给外部状态ht![]() 。
。
原理如图所示。
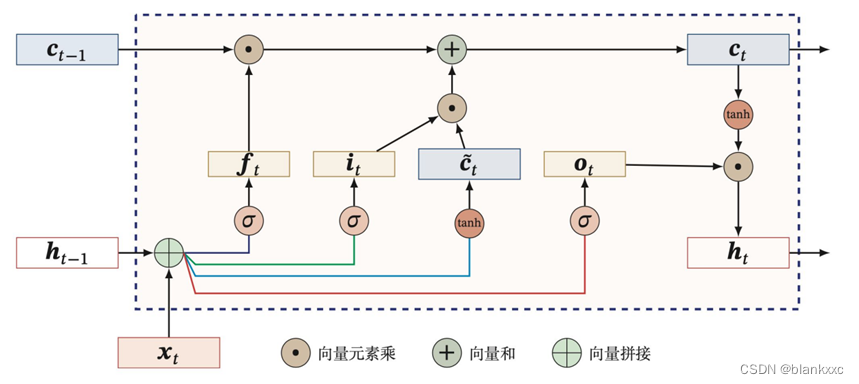 图8 LSTM模型结构图
图8 LSTM模型结构图
计算步骤如下:
①先利用上一时刻的外部状态ht-1![]() 和当前时刻的输入xt
和当前时刻的输入xt![]() ,计算出三个门的值,以及候选状态ct
,计算出三个门的值,以及候选状态ct![]() ;
;
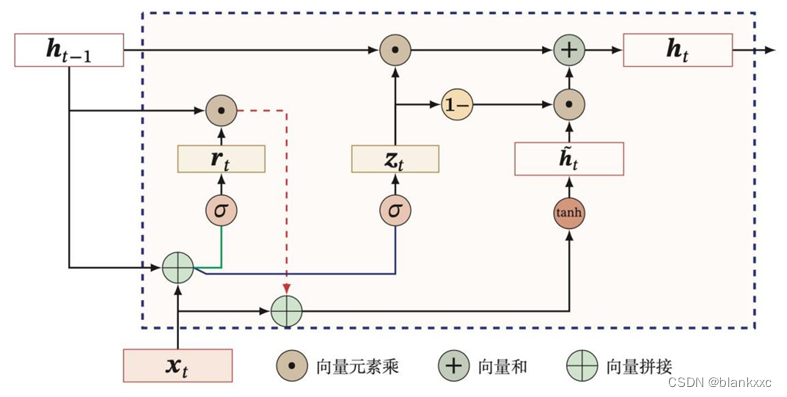
3.9 GRU
GRU的结构比LSTM更为简单一些,GRU只有两个门,更新门zt
和重置门rt
。
(1)更新门:控制当前状态ht
需要从上一时刻状态ht-1
中保留多少信息,以及需要从候选状态ht
中接受多少信息;
(2)重置门:用来控制候选状态ht
的计算是否依赖上一时刻状态ht-1
。
4数据预处理
4.1数据获取和分析
本文通过Jupyter的python接口对数据进行读取,结果共包含三种类型的数据:区域15分钟负荷数据、行业日负荷数据、气象数据。其中,区域15分钟负荷数据,记录了128156条某地区电网2018年1月1日至2021年8月31日间隔15分钟,一天共记录96次的电力系统负荷数据;行业日负荷数据,包含了该地区四个行业总计3610条从2019 年1月1日至2021年8月31日用电日负荷最大值和最小值数据;气象数据,包含了该地区2018年1月1日至2021年8月31日主要的气象数据,记录了1345条天气状况、最高温度、最低温度、白天风力风向、夜晚风力风向等气象指标。
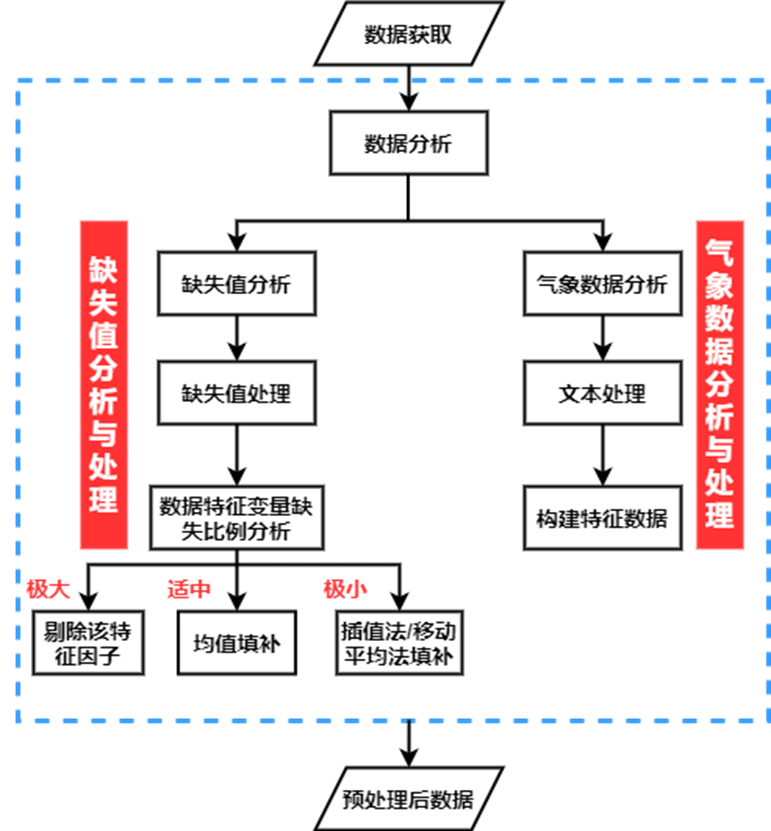
图10 数据预处理流程图
本文所用数据存在着大量的缺失,严重影响到数据挖掘建模的执行效率,甚至可能导致挖掘结果的偏差,所以进行数据清洗就显得尤为重要,数据清洗完成后接着进行或者同时进行数据集成、转换、规约等一系列的处理,这就是数据预处理的过程。数据预处理一方面是要提高数据的质量,另一方面是要让数据更好地适应特定的挖掘技术或工具。特征构建则是通文本处理等方法初步构建出对建模有用的数据指标因子,进一步提高建模效率。本章描述数据预处理及特征构建的过程,其流程图如上图所示。
4.2缺失值统计
对区域15分钟负荷数据分析,如下图3.2所示,面积图中出现大量白色坑洼的形状,说明该时间段内存在缺失值,所以在对数据进行预处理时,要考虑时间序列对缺失值的影响,选择适当的填补方法。
对区域15分钟负荷数据分析,如下图3.2所示,面积图中出现大量白色坑洼的形状,说明该时间段内存在缺失值,所以在对数据进行预处理时,要考虑时间序列对缺失值的影响,选择适当的填补方法。

图11 数据缺失情况
对行业日负荷数据最小值占比情况分析,如下图3.3和3.4所示,用电日负荷最高的行业是大工业,占比达到80%;其次是商业,占比16%;第三的是普通工业,占比3%;最后是非普工业,占比1%。其中,非普工业存在大量的数据缺失,而且各个行业日用电负荷比例不均衡,所以在对数据进行预处理时,按行业分别处理。

图12 数据缺失情况

图13 行业数据占比
每个特征因子或多或少都存在缺失值,如果某个特征因子缺失的样本比例极大,则采取剔除的方式处理。因为如果使用其他方式进行填补将会极大降低整体数据的可信性,故需要剔除。
如果某个特征因子缺失的样本比例适中,则采用填补的方式进行处理。同时考虑到不同行业对各项指标缺失值衡量的标准是不统一的。因此对处于该区间数据的缺失值,将0值当作空白值,同时对行业进行分类,对需要填充缺失值的行业数据进行均值填补。
如果某个特征因子缺失的样本较少,则根据不同附件中缺失值数据的特点,采用插值或移动平均法进行填补。
处理缺失值的数学模型如下:
Γ极大,剔除该特征因子Γ适中,用均值填补Γ极小,用插值法/移动平均法填补

其中,Γ

表示样本的缺失比例。
4.3缺失值处理
对于提供的附件数据,本文采用上述的三种方法对缺失值进行处理。
步骤 1:剔除缺失比例极大的数据
行业日负荷数据中非普工业的数据从2019年1月1日到2019年10月9日开始缺失,缺失比例为29%,对于小型数据来说是属于缺失比例较大的,为保证时间的完整性,故将其剔除。同时对于四个行业共同缺失2021年1月24日的数据,缺失数目较少,故用插值法对其填补。经过数据填充,行业日负荷数据由3610条增加到3614条。行业日负荷数据缺失值如图3.5所示。

图14 行业数据情况
步骤 2:移动平均法填补缺失值
区域15分钟负荷数据中一个小时有4个数据,则一天有96个数据,考虑到移动平均法的核心思想是取出缺失值发生之前的一段滚动时间内的值,计算其平均值或中位数来填补缺失值,符合该附件数据的时间特性,故对其缺失值进行移动平均法进行填充。经过数据填补,区域15分钟负荷数据由128156条增加到128544条。区域15分钟负荷数据缺失值如下图3.6所示。同时观察到2018年9月份前的某地区电网负荷数据没有与后面的数据那样呈现出季节性,如下图3.7所示,考虑到负荷降低可能是国家颁布的某些政策或其他因素影响,故后续预测时只考虑2018年9月之后的负荷数据。

图15 数据缺失情况

图16 数据缺失情况
4.4重复值处理
气象数据中没有缺失值,但是有重复值,为了避免影响建模效果,故将其剔除。重复的气象数据如表3.1所示。
表1 天气特征数据
| 日期 | 天气状况 | 最高温度 | 最低温度 | 白天风力风向 | 夜晚风力风向 | 重复个数 |
| 2018年1月1日 | 多云/多云 | 22℃ | 12℃ | 无持续风向<3级 | 无持续风向<3级 | 2 |
| 2020年7月4日 | 雷阵雨/雷阵雨 | 27℃ | 27℃ | 无持续风向1-2级 | 无持续风向1-2级 | 2 |
| 2020年7月5日 | 多云/多云 | 35℃ | 27℃ | 无持续风向1-2级 | 无持续风向1-2级 | 2 |
| 2020年12月3日 | 晴/晴 | 21℃ | 11℃ | 北风1-2级 | 北风1-2级 | 2 |
| 2021年6月4日 | 大雨/小雨 | 28℃ | 23℃ | 北风1-2级 | 北风1-2级 | 3 |
4.5特征构建
对于数据特征的构建的部分数据可见如下表,特征标签除了“行业类型”、“日期”、“有功功率最大值(kw)”、“有功功率最小值(kw)”、“日期1”,其他的均为构建的特征数据。特征名称及特征解释可见如下表3.2。
表2 特征解释
| 特征名称 | 特征解释 | 特征名称 | 特征解释 |
| 最高温度 | 当天的最高温度 | 每天第n小时 | 每天的第几个小时 |
| 最低温度 | 当天的最低温度 | 每周第n天 | 每周的第几天 |
| 天气1_0 | 当天的天气情况1 | 每年第n周 | 每年的第几个星期 |
| 天气2_0 | 当天的天气情况2 | 每天第n时间段 | 每天的第几个时间段 |
| 天气状况 | 当天的天气情况 | 第n季节 | 每年的第几个季节 |
| 白天风力风向 | 当天白天的风力风向 | 是否月初 | 当天是否在每月第一天 |
| 夜晚风力风向 | 当天夜晚的风力风向 | 是否月末 | 当天是否在每月最后一天 |
| 第n年 | 第几年 | 是否季初 | 是否在季节的第一天 |
| 每年第n月 | 每年的第几个月 | 是否季末 | 是否在季节的最后一天 |
| 每年第n天 | 每年的第几天 | 是否周末 | 是否在每一周最后一天 |
5实验分析
5.1任务思路
在本文中我们主要是分为城市的总电力负荷预测和行业电力负荷预测两种任务,一种是针对整个城市某一时刻的电力负荷预测;另外一种是针对该城市每个行业某一个时刻的电力负荷进行预测。
首先第一种任务,我们主要是预测未来10天的数据进行预测分析,由于数据每个时刻点都是间隔15min,时间间隔太短,无需加入天气特征数据进行辅助预测。而在时间序列预测中可以分为单步预测和多步预测,可见下图。即预测的对象是一个对象还是多个对象,可以选择使用一个对象数据或多个对象数据预测单个对象数据,也可以使用一个对象数据、多个数据对象来预测多个对象数据。

图17 单步与多步预测
在第一种任务中我们主要是使用多个对象数据预测一个对象数据,即单步预测,因为我们在第一种任务预测中没有加入天气特征数据加以辅助预测,数据的联系会比较弱,不宜多步预测。我们还需要对电力负荷数据进行归一化处理,消除奇异电力负荷样本数据导致的不良影响,可以提升模型的预测精度。
我们选取已有数据的后1000条数据作为我们的测试样本,检查模型预测的精度。测试样本数据不能放入到模型中训练,容易导致模型在测试中出现过拟合的现象,因为如果你的测试数据已经在模型中训练过了,在测试的时候会出现“信息泄露”的情况,这是由于模型在训练的时候已经对测试数据进行了“学习”。测试数据选择在训练数据之后的数据,因为我们需要保证数据的时序性。
由于机器学习模型无法直接对时间序列数据进行训练预测,所以我们需要将时间序列数据转换成机器学习中的监督学习的实验数据,例如我们拥有时间序列数据:[1,2,3,4,5],我们需要设计算法对其进行转换,假如我们使用前2步的数据实现预测后一步的数据,那上述的数据将变成X=[1,2],Y=[3];X=[2,3],Y=[4];X=[3,4],Y=[5],将时间序列数据转换成机器学习中的监督学习数据,用于机器学习模型的训练。
由于在数据分析时发现,每天的电力负荷数据都有一个周期性的特征,所以在第一小问中我们使用96条数据(1天)预测后一条的数据。第一种任务的思路流程图可见如下。对于LSTM、GRU等模型我们都将模型设定在本地环境或者是云服务器环境的GPU(图形处理器)上训练,加快模型的训练速度和预测速度。

图18 任务一流程图
第二个任务是对每个行业未来电力负荷预测,寻找每天各个行业的电力负荷最大值和最小值预测,用于帮助政府分析城市每个行业的电力负荷情况。由于每个行业我们每天只需要预测出两个值,一个电力负荷最大值和一个电力负荷最小值(即间隔15min的960条数据中的最大最小值),我们需要预测未来多天各行业的最大最小电力负荷,为了加强数据之间的联系,我们需要使用附件3中的天气数据,作为特征数据输入模型中,加强模型预测的记忆力和预测能力。对于特征的构建我们考虑了两种特征,第一种是天气特征,第二种是时间特征。
其中第一种特征分两种小特征:
1、连续型的天气特征,例如最高温度和最低温度,
2、离散型的天气特征,例如风力状况、天气状况等。
第二种时间特征也与上类似。
1、连续型的时间特征,例如每天第n个小时、每年第n天、每年第n月等
2、离散型的时间特征,例如是否在月初、是否在周末、是否在月末等。
以上的特征都充分考虑到了时间序列中的周期性特征,该部分特征无论是在普通的机器学习模型中还是深度学习的循环神经网络中都能很容易学习到数据的周期性特征。
由于在此任务中我们具有多种特征数据,所以我们可以尝试使用多步预测,即可多个数据输入预测输出多个数据。 多步预测即输入过去单天或是多天的单维或多维的时间序列特征数据,实现一次性预测未来多天数据的方法。该方法也需要对时间序列数据以及其特征数据进行转换,转成机器学习中的监督学习类型的特征数据,具体实现的方法与第一种任务类似,只是加入了多种特征变量数据。步预测方法可以在GRU模型和LSTM模型中实现,我们需要对模型的数据输入与数据输出进行更改,模型的输入一般为[samples,timesteps,n_features],我们需要更改的为时间步长与特征维度,也就是timesteps,n_features,对于模型的输出我们直接设定为我们需要预测的时间步长即可。多步预测的代价是算力成本与内存成本,虽然多步预测没有递归预测的误差累积,可是在计算方面的代价非常大。该任务的思路可见下图。

图19 任务二流程图
5.2总电力负荷预测
ARIMA模型分析
ARIMA(自回归综合移动平均线)是两个模型AR(自回归)和MA(移动平均线)的组合。它有3个超参数-P(自回归滞后),d(微分阶),Q(移动平均),分别来自AR,I和MA分量。AR部分是前期与当前时间段之间的相关性。为了消除噪声,使用了MA部分。I部分结合在一起的AR和MA部分。所以我们需要实现ARIMA算法并且去预测的时候,我们需要确定三个参数P、D和Q。我们需要借助ACF(自相关函数)和PACF(部分自相关函数)绘图。ACF和PACF图用于求ARIMA的P和Q值。我们需要检查,在x轴上的哪个值,在y轴上第一次下降到0,则一般P和Q值选择为当前的x,即从PACF(y=0)得到P,从ACF(y=0)得到Q。
查看ACF和PACF,确定P和Q,我们可以发现P和Q都可以选择为1。

图20 ACF和PACF图
参数选择好后,使用Python自带的statsmodels库实现ARIMA模型,使用的参数如上所述,模型的拟合效果可见如下图,其中蓝色的部分属于真实数据,黄色部分的数据属于拟合数据。我们可以很明显发现模型的拟合效果并不好,在某些部分模型的拟合状态表现并不出色,它未能学习实验数据中的规律,在预测的时候可能模型带有线性预测的方式预测数据,显得模型在某些阶段的拟合效果都呈“线性”。

图21 ARIMA预测结果
选择数据的后1000条数据作为测试数据,用于评估模型的精度,因为我们需要评估未来10天(960条15min)的数据,其他的数据选择上述的参数继续重新的训练。得到1000条测试数据预测的误差结果可见如下表。
表3 模型预测结果分析
| 指标 | MSE | RMSE | MAE | R² | 训练时间 |
| 数值大小 | 94321321.45316 | 12352.86842 | 10322.35323 | 0.16247 | 192s |
Prophet模型分析
本文使用实现该模型的编程语言是Python,基于facebook开源的Fprophet库实现。我们首先将前述部分处理好的实验数据,切分后1000条的数据作为测试集,其他的数据作为训练数据输入到模型中进行训练。
模型训练效果图可见如下,蓝色的数据除了后1000条数据其他的都为模型的拟合数据,红色的全部均为真实数据,蓝色数据的后1000条的数据为测试数据,是属于在模型训练拟合完毕之后进行模型预测得到的。

图22 Prophet预测结果
由于模型的预测效果较好,为了直观展示数据的预测效果,取出后1000条预测的数据进行展示,效果可见如下图。我们发现数据的预测情况都比较好,除了一些高峰预测效果不足。个人认为这是模型在预测的过程中具有“保守”的机制,在一些过于高或者是过于低的点,预测得到的数据都不会太高或者是太低。

图23 Prophet预测结果
对于全部1000条测试数据预测的误差结果可见如下表。我们可以看到R²系数达到0.86336,比上述的ARIMA模型的精度高许多,是因为prophet模型对于周期性特征比较明显的时间序列数据的训练和预测效果都很好,它擅长处理具有季节性特征大规模的时间序列数据,在电力系统负荷数据中,数据本身含有较多的季节性特征。
表4 模型预测结果分析
| 指标 | MSE | RMSE | MAE | R² | 训练时间 |
| 数值大小 | 76587037.94186 | 8751.40206 | 7005.21820 | 0.86336 | 546s |
LightGBM模型分析
使用LightGBM模型对训练数据进行训练,对测试数据进行预测,分析精度,模型的预测效果可见如下,我们可以很明显发现该模型对于周期性特征标明显的时间序列数据拟合效果非常差,从另外一种角度看,可能是该模型对于时间序列的特征数据学习得还不足够。

图24 LightGBM预测结果
我们直接查看模型的预测精度,我们可以看到R²系数非常低,只有0.03062,比上述的ARIMA模型的预测精度还低。
表5 模型预测结果分析
| 指标 | MSE | RMSE | MAE | R² | 训练时间 |
| 数值大小 | 625101763.51921 | 25002.03519 | 21756.22483 | 0.03062 | 18.3s |
XGBoost模型分析
使用XGBoost对训练数据进行训练,对测试数据进行预测,模型的预测效果可见如下图。我们可以发现该模型的预测效果与LightGBM模型的预测效果非常类似。

图25 XGBoost预测结果
在具体的预测精度上,Xgboost的R²系数与LightGBM的R²系数相差不大,说明了传统的机器学习模型在单纯时间序列数据中的学习效果并不好,需要加入其他的时间序列特征数据辅佐学习。
表6 模型预测结果分析
| 指标 | MSE | RMSE | MAE | R² | 训练时间 |
| 数值大小 | 618028569.01498 | 24860.18039 | 21647.86006 | 0.0332 | 15.1s |
LSTM模型分析
使用tensorflow框架实现RNN系列的LSTM模型,对训练数据进行输入,预测测试数据,我们可以看到1000条测试数据的预测情况可见如下图。对比上述4个模型,LSTM的模型的效果是最好的,我们可以看到1000条数据的总体预测效果都与真实值非常接近。

图26 LSTM预测结果
为了更加明显查看模型的预测效果,我们直接查看测试数据的最后100条数据的预测效果,可见如下图,我们仔细看还是可以看到LSTM模型的预测得到的数据的规律特征基本与真实数据的一直,并且预测得到的预测数据均在真实数据的上方。

图27 LSTM预测结果
为了对比模型的训练时间,直接把模型的迭代次数epoch全部设置为50次,模型数据读取的数据样本批次batch_size都设定为64。我们可以看到模型在前几个epoch的loss就已经接近平稳了。

图28 LSTM训练损失情况
查看LSTM模型的预测精度,我们可以发现R²系数已经达到了0.96101,模型的训练时间为48.4s,因为模型在GPU上运行,所以运行时间会比较快。
表7 模型预测结果分析
| 指标 | MSE | RMSE | MAE | R² | 训练时间 |
| 数值大小 | 24057649.22168 | 4904.85976 | 3864.78760 | 0.96101 | 48.4s |
GRU模型分析
我们使用RNN系列的另外一个模型GRU对训练数据进行训练,对测试数据进行预测,我们可以看到总体的预测效果要比LSTM模型的要较好一些。

图29 GRU预测结果
我们直接选择预测数据的后100条数据进行查看,我们可以很明显发现,GRU模型的预测效果要比LSTM模型的要好,预测值与真实值之间非常的接近。

图30 GRU预测结果

图31 GRU训练损失情况
对比LSTM的预测精度,我们可以看到GRU模型的预测精度R²系数已经达到了0.98527,要比LSTM的要大约0.02,并且训练时间也要比LSTM模型的要短。这是因为GRU只含有两个门控结构,且在超参数全部调优的情况下,与LSTM的性能相当,但是GRU结构更为简单,参数比LSTM 少,模型训练样本就会较少,所以模型的训练时间要比LSTM的短,但是模型的精度并不比LSTM逊色,此次实验中GRU在精度和速度上都要比LSTM好。
表8 模型预测结果分析
| 指标 | MSE | RMSE | MAE | R² | 训练时间 |
| 数值大小 | 9091717.41301 | 3015.24749 | 1571.40683 | 0.98527 | 17.5s |
表9 模型对比分析
| 指标 | MSE | RMSE | MAE | R² | 训练时间 | |
| 模型 | ARIMA | 94321321.45316 | 12352.86842 | 10322.35323 | 0.16247 | 192s |
| Prophet | 76587037.94186 | 8751.40206 | 7005.21820 | 0.86336 | 546s | |
| XGBoost | 618028569.01498 | 24860.18039 | 21647.86006 | 0.0332 | 15.1s | |
| LightGBM | 625101763.51921 | 25002.03519 | 21756.22483 | 0.03062 | 18.3s | |
| LSTM | 24057649.22168 | 4904.85976 | 3864.78760 | 0.96101 | 48.4s | |
| GRU | 9091717.41301 | 3015.24749 | 1571.40683 | 0.98527 | 17.5s |
5.3行业电力负荷预测
我们此处选择第一种任务中预测效果最好的模型GRU对各个行业进行多步训练预测,我们此处直接使用GRU读入电力负荷数据和相关的天气特征数据来预测未来90天的电力负荷数据(约3个月)。我们先对大工业类型的用电负荷进行分析,查看该行业的有功功率最大值和有功功率最小值的用电负荷情况。我们先对大工业用电负荷的有功功率最大值进行预测分析。

图32 大工业电力负荷情况
本任务直接使用GRU模型对各个类型行业的用电负荷最大最小值进行预测并且分析其精度。我们将已有的大工业行业的电力负荷数据进行分割,选择最后的90个数据(约3个月)作为我们的测试集,其他的数据用于模型训练。
使用GRU模型对大工业的有功功率最大值数据进行训练,其中大工业的有功功率最大值的预测效果可见如下图。

图33 GRU预测结果
我们选择模型预测的后60天数据进行查看。

图34 GRU预测结果
查看模型训练过程中的损失情况

图35 GRU训练损失情况
查看模型在90天测试数据中的预测精度,我们可以发现R²系数只有0.72082,经过多次的模型参数调整和天气特征的重新构建,精度最高也只有0.72082。
表10 模型预测结果分析
| 指标 | MSE | RMSE | MAE | R² | 训练时间 |
| 数值大小 | 22431622.86413 | 4736.20342 | 3816.31042 | 0.72082 | 62.2s |
我们对大工业有功功率电力负荷最小值进行预测。

图36 GRU预测结果

图37 GRU预测结果

图38 GRU训练损失情况
表11 模型预测结果分析
| 指标 | MSE | RMSE | MAE | R² | 训练时间 |
| 数值大小 | 123602472.06916 | 11117.66487 | 6363.04293 | 0.26212 | 57.1s |
对于其他的行业的做法与上一致,此处不再展开一一展示
6平台搭建
6.1分析预测平台
本次可视化界面用到PyQt5库来搭建。PyQt是一个用于创建GUI应用程序跨平台工具包,它将Python与Qt库融为一体。也就是说,PyQt允许使用Python语言调用Qt库中的API。由于目前最新的PyQt版本是5.X,所以习惯上称PyQt为PyQt5。
此外,借助了Qt Designer来设计界面。Qt designer是专门用来制作PyQt程序中UI界面的工具,通过拖曳和点击就可以完成复杂的界面设计,而且还可以随时预览查看效果图。Qt designer可以将设计好的用户界面保存为.ui文件,其实是XML格式的文本文件。为了在 PyQt中使用.ui文件,可以通过 pyuic5命令将.ui文件转换为.py文件件,然后将.py文件引入到自定义的Python代码中。
数据导入
该可视化界面主要实现两个功能,一个是数据导入,主要实现数据导入和数据展示的功能。详情和展示可见下图,对其中的一个数据进行导入显示。


图39 界面详情
数据分析
数据分析分为添加数据、预处理和图表制作三个部分。添加数据部分是对上面导入的数据进行读取,可见下图。

图40 界面详情
点击“添加导入的数据”即可对上面导入的数据进行读取,并将读取的数据存储在左侧列表框中。要进行接下来的数据预处理或者图表制作时则需要先选中列表中读取的数据。

图41 界面详情
数据预处理部分主要包括对数据进行描述性统计、缺失值统计、缺失值处理以及异常值处理,界面详情可见下图。

图42 界面详情
例如对数据进行展示以及统计性分析,详情可见下图。

图43 界面详情
导入有缺失值的数据,测试缺失值统计和缺失值填充,如下,首先缺失值统计结果有12个缺失值,接着选择一种缺失值填充,这里用的均值填充,可以看到缺失值已经填充上,最后再进行一次缺失值统计。


图44 界面详情
图表制作部分,包括绘制散点图、折线图、饼状图以及热力图。界面详情可见如下

图45 界面详情
在导入的数据列中选择x和y,选择颜色,就可以绘制散点图,例如我们可以绘制附件1中的总有功功率散点图。

图46 界面详情
我们可以绘制2018-2021年区域15分钟负荷的折线图,结果可见如下。

图47 界面详情
我们可以对附件2中的每个行业的数据比例进行展示,使用饼状图,具体可见如下图。

图48 界面详情
我们可以对处理完的特征数据使用热力图进行展示。

图49 界面详情
我们可以对未来的电力负荷数据进行预测分析,即预测结果可视化展示,预测结果可视化展示区域15分钟负荷预测的详情可见如下图。

图50 界面详情
绘制该区域大工业行业的未来每天最大最小电力负荷数据,使用折线图。


图51 界面详情
我们还可以对不同行业未来的有功功率最大值和最小值预测结果进行展示。


图52 界面详情
6.2监控预测平台
本平台可以从上述的分析预测平台中处理过后和预测得到的数据进行展示分析,主要目的是对得到过去的旧数据和未来的预测数据进行展示分析,直观展示在大家的眼中。本台是基于帆软实现的,详情可见下图。


图53 界面详情
本平台主要分为两部分,详情可见下图,第一部分是监控部分,即监控每个行业和该城市总的电力负荷前7天的情况;第二部分是预测部分,即是对每个行业未来7天的电力负荷情况的预测。监控的数据来源自分析预测平台,分析预测平台将各个行业每天的电力负荷数据和该城市每天的总电力负荷数据处理分析完,由监控预测平台读取进行显示。而预测的数据即来源自分析预测平台对每个行业和该城市总的电力负荷未来7天预测结果进行读取显示。

图54 界面详情
7总结
电力系统负荷预测的精度对于整个电力系统的可靠性运行来说是非常重要的。电力负荷预测准确度的提高,不仅保证了电力系统负荷预测的可靠性,还能够保证社会电力能源例如企业生产和社会用电稳定供应。电力系统负荷预测还能对于电网改造等计划的制定具有良好的参考性,能够提高电网公司的经济效益,达到节能减排,降低成本的效果,同时还能提高电力系统的经济效益和社会效益。
在本文中,本文使用深度学习的LSTM、GRU模型与传统的ARIMA、Prophet模型以及Xgboost和LightGBM机器学习模型进行对比,在电力系统负荷预测中,深度学习模型LSTM、GRU模型的预测精度都比其他模型要高。在预测未来10天的电力系统负荷总有功功率中,LSTM模型的预测精度R²系数达到0.96101,而GRU模型的预测精度R²系数已经达到了0.98527,效果非常好。
在本文中,GRU模型的预测精度要比LSTM模型的要好,而且GRU模型的参数相对于LSTM模型而言,GRU 的模型结构更为简单,而且参数量比LSTM 少,模型训练样本就会较少,GRU模型的训练时间要比LSTM的短,在算力成本与时间成本上都要优于LSTM模型,而且本文中的GRU模型的预测精度并不比LSTM逊色。
本文还实现了城市电力负荷分析预测平台和城市电力负荷监控预测平台,可以对城市的电力负荷数据进行分析、监控以及预测。城市电力负荷监控预测平台可以从城市电力负荷分析预测平台分析得到的数据进行读取展示,显示当前电力负荷情况,以及未来的电力负荷发展趋势。
本文使用深度学习模型与其他模型进行对电力系统负荷进行预测对比,发现深度学习模型在本文的实验中都具有良好的效果,对未来电力系统负荷预测的预测精度非常高,为未来的电力系统负荷预测研究提供了可靠的参考性。基于上述分析和实验,本文可以提供基于各个相关行业提出针对性建议,能够让它们在未来电力系统发展中受到的影响较少,提高各个行业的经济效益。
8参考文献
[1] 王闯,兰程皓,凌德祥,等. LSTM模型在电力系统负荷预测中的应用[J]. 电力大数据,2021,24(1):17-24.
[2] 王大庆,吴学志. 电力系统负荷预测研究综述与发展[J]. 建筑工程技术与设计,2018(25):2814.
[3] 周伊玲. 电力系统短期负荷预测方法研究综述[J]. 百科论坛电子杂志,2020(12):1692-1693. DOI:10.12253/j.issn.2096-3661.2020.12.3622.
[4] 余俊杰. 基于改进EMD和GRU的短期电力负荷预测研究[D]. 湖北:湖北工业大学,2021.
[5] 金航. 基于改进深度循环神经网络的短期电力系统负荷预测方法[D]. 华北电力大学,2021.
[6] 郝洪全. 基于深度学习的电厂负荷短期预测研究[D]. 天津:天津理工大学,2021.
[7] 李松岭. 基于TensorFlow的LSTM循环神经网络短期电力负荷预测[J]. 上海节能,2018(12):974-977. DOI:10.13770/j.cnki.issn2095-705x.2018.12.007.
[8] 罗育辉. 基于深度学习的电力负荷预测方法研究[D]. 广东:广东工业大学,2020.
[9] 孟醒,邵剑飞. 基于深度学习的电力负荷预测方法综述[J]. 电视技术,2022,46(1):44-51. DOI:10.16280/j.videoe.2022.01.012.
[10] 董彦军,王晓甜,马红明,等. 基于随机森林与长短期记忆网络的电力负荷预测方法[J]. 全球能源互联网,2022,5(2):147-156. DOI:10.19705/j.cnki.issn2096-5125.2022.02.006.
[11] 宁欣. 基于深度学习的短期电力负荷预测模型[D]. 天津:天津工业大学,2020.
[12] 魏健,赵红涛,刘敦楠,等. 基于注意力机制的CNN-LSTM短期电力负荷预测方法[J]. 华北电力大学学报(自然科学版),2021,48(1):42-47. DOI:10.3969/j.ISSN.1007-2691.2021.01.05.
[13] 周朝勉. 基于注意力机制与时间卷积的短期电力负荷预测研究[D]. 江西:南昌大学,2021.
[14] 龚飘怡,罗云峰,方哲梅,等. 基于Attention-BiLSTM-LSTM神经网络的短期电力负荷预测方法[J]. 计算机应

















 1130
1130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









