







文章目录
一、语音识别产品对比
近二十年来,语音识别技术取得显著进步。人工智能的新宠ChatGPT聊天机器人模型更进一步推动了语音识别技术的发展。很多专家都认为语音识别技术是2000年至2010年间信息技术领域十大重要的科技发展技术之一。
当你的业务场景想要音频转文字、语音转文字,比如直播、字幕识别等等,这时候就要用到语音识别技术了,这里我们先针对市面上目前相对通用的百度、华为、阿里云、科大讯飞、有道等几款语音识别产品的技术对接方案、套餐、价格、超时后费用、直接购买还是预付费、官网说明、业务场景等进行简单比对:
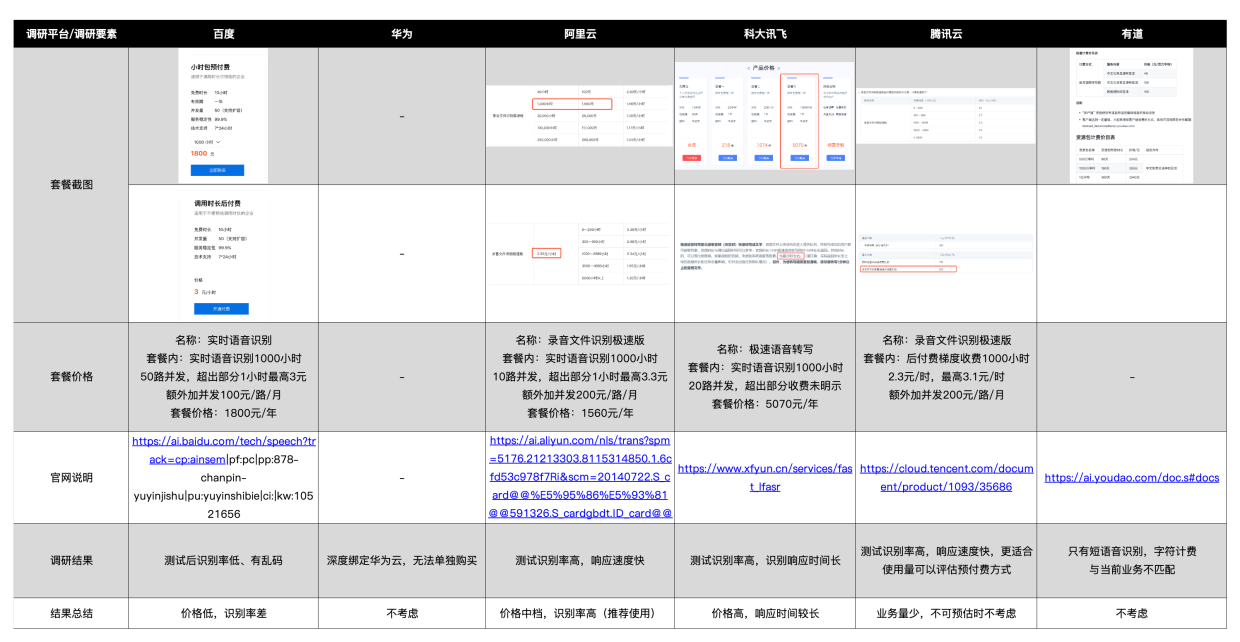
上述为个人结合自身业务场景调研结果,可供参考。
调研业务背景:实现脚本视频跟拍功能,处理音频流、视频流、以及语音识别为字幕等。
二、百度语音识别产品
1、套餐及价格:
名称:实时语音识别套餐内:实时语音识别1000小时50路并发,超出部分1小时最高3元额外加并发100元/路/月
套餐价格:1800元/年
特点:是支持预付费,也支持后付费


2、官网
3、调研结果
测试后识别率低、有乱码
三、华为语音识别产品
调研结果由于深度绑定华为云,无法单独购买,暂时不考虑。
四、阿里云语音识别产品
1、套餐及价格:
名称:录音文件识别极速版
套餐内:实时语音识别1000小时
10路并发,超出部分1小时最高3.3元额外加并发200元/路/月
套餐价格:1560元/年
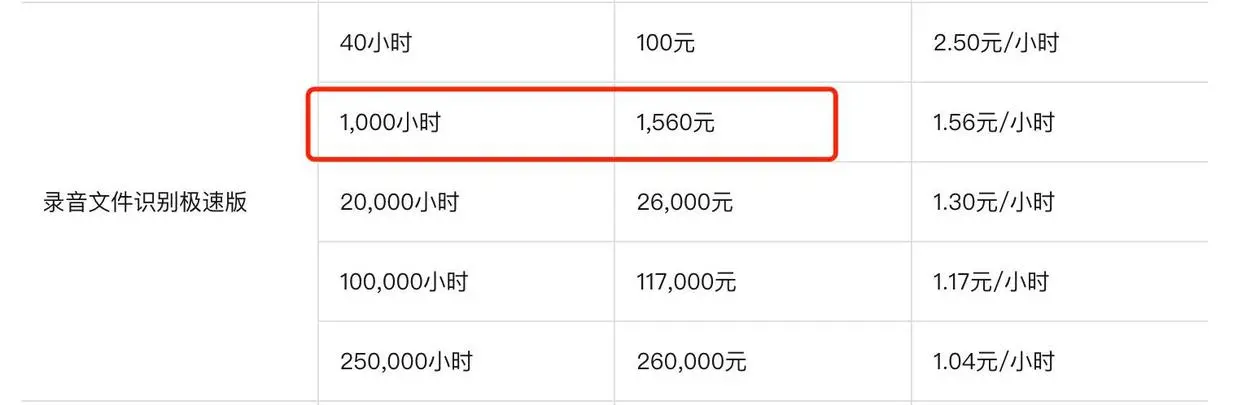
超出后价格:
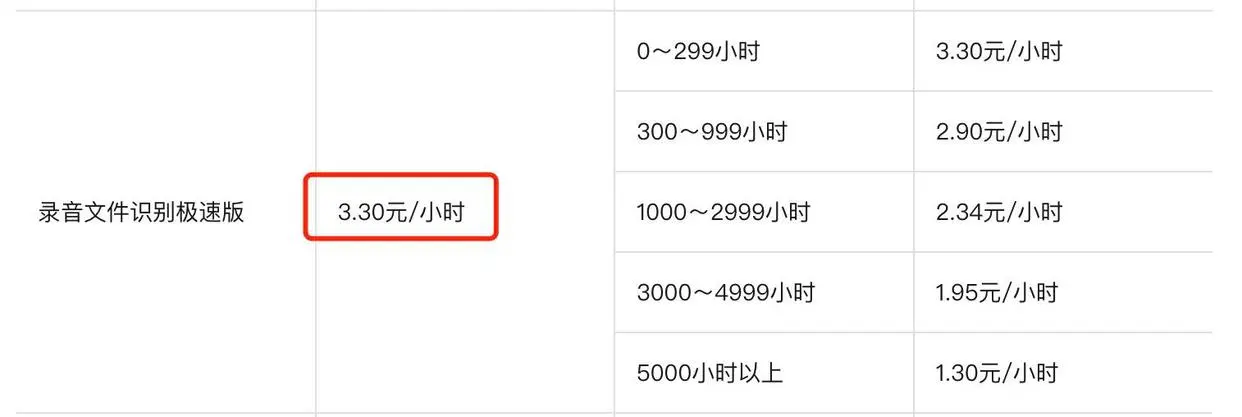
2、官网地址
3、调研结果
测试识别率高,响应速度快
五、腾讯云语音识别产品
1、套餐及价格
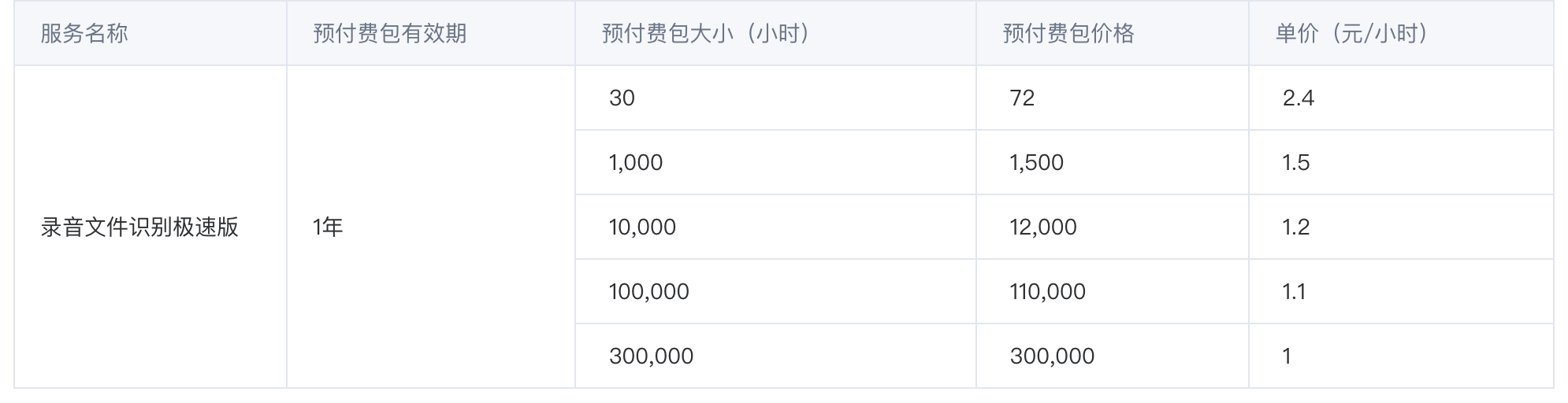
名称:录音文件识别极速版
功能:对用户上传的五小时之内的录音文件进行识别;可应用于呼叫中心语音质检、视频字幕生成,会议语音资料转写等场景。
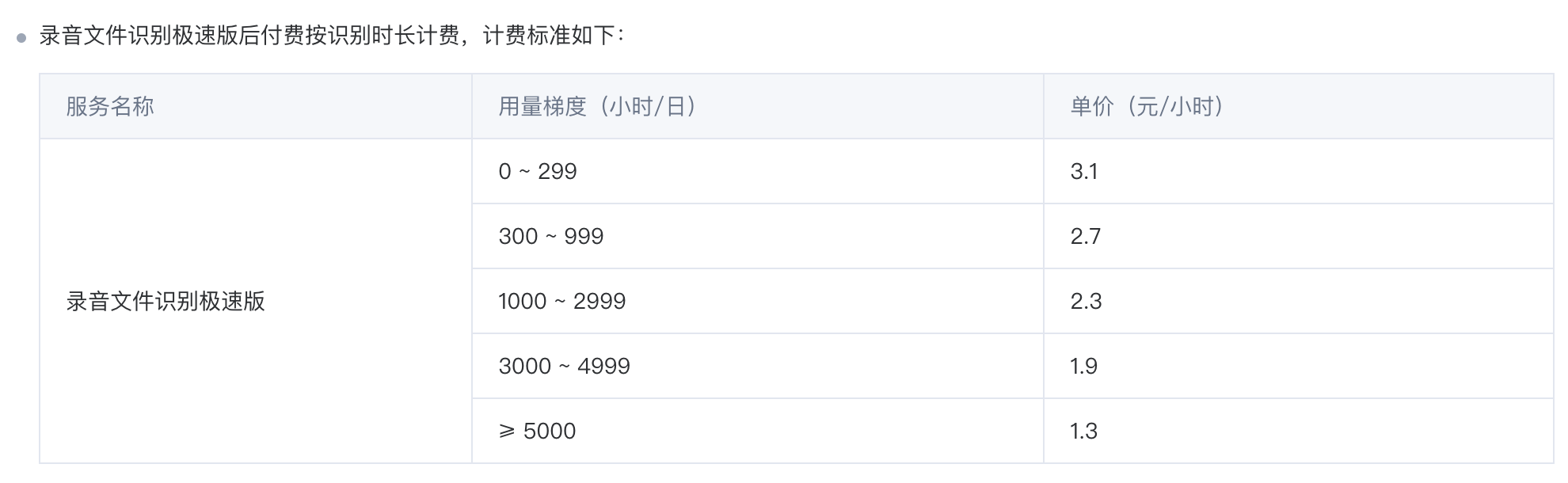
套餐内:预付费1500元/年,1000小时。后付费梯度计费,超出部分按识别时长梯度计费,1000小时为2.3,最高3.1元。
录音文件识别极速版并发叠加包200元/路/月
套餐价格:
特点:腾讯云语音识别 ASR 提供预付费和后付费两种计费模式,开通服务后默认使用后付费的计费模式
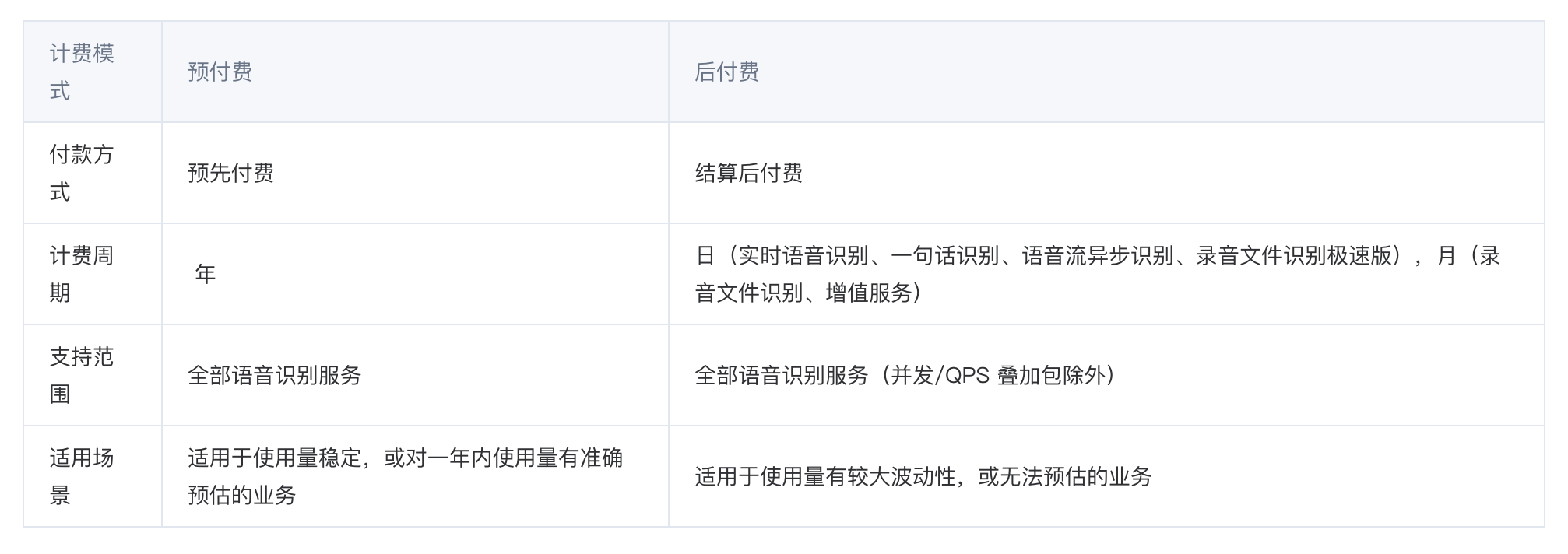
套餐详情:
2、官网
https://cloud.tencent.com/document/product/1093/35686
3、调研结果
测试识别率高,响应速度快,但对于使用量无法预估场景,后付费方式相对业务量小时会费用较高。所以更适合使用量可以准确评估,然后预付费方式使用。
六、科大讯飞语音识别产品
我们知道科大讯飞在语音识别领域做的比较成熟,比较有名了,所以也相对比较贵。
1、套餐及价格:
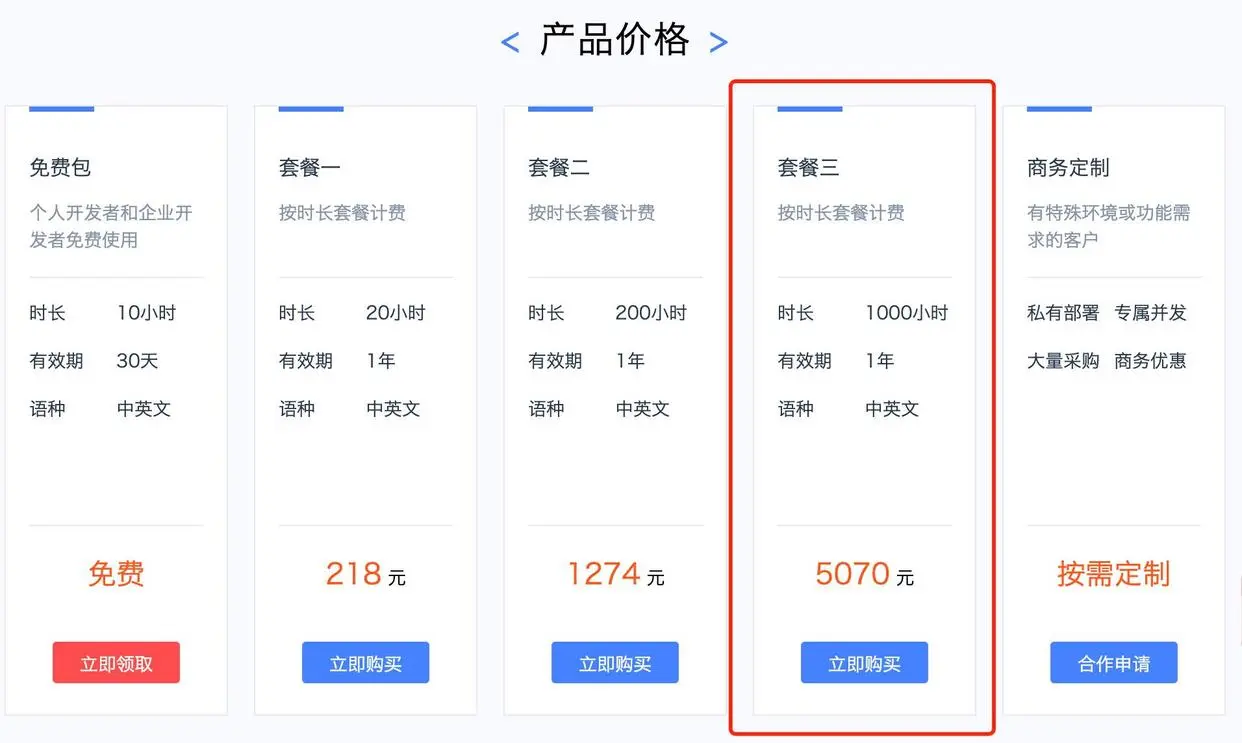
名称:极速语音转写
套餐内:实时语音识别1000小时
20路并发,超出部分收费未明示
套餐价格:5070元/年

2、官网
https://www.xfyun.cn/services/fast_lfasr
3、调研结果
测试识别率高,识别响应时间长
七、有道语音识别产品
1、套餐及价格

2、官网
https://ai.youdao.com/doc.s#docs
3、调研结果
只有短语音识别,字符计费,与当前业务不匹配
八、结论

请结合自身业务参选择。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











