







 DeepTraLog是一种结合日志和追踪数据的微服务异常检测方法,它利用图神经网络(GGNN)和深度SVDD模型来学习微服务系统调用链和日志事件的统一表示。通过构建轨迹事件图(TEG),该方法能捕获调用结构和日志事件的复杂性,从而提高异常检测的准确性。实验表明,DeepTraLog在准确率和召回率上优于基于跟踪和日志的传统方法,并且在处理复杂调用结构和并行/异步调用时表现更优。
DeepTraLog是一种结合日志和追踪数据的微服务异常检测方法,它利用图神经网络(GGNN)和深度SVDD模型来学习微服务系统调用链和日志事件的统一表示。通过构建轨迹事件图(TEG),该方法能捕获调用结构和日志事件的复杂性,从而提高异常检测的准确性。实验表明,DeepTraLog在准确率和召回率上优于基于跟踪和日志的传统方法,并且在处理复杂调用结构和并行/异步调用时表现更优。
Trace-Log Combined Microservice Anomaly Detection through Graph-based Deep Learning
基于图神经网络的微服务系统调用链和日志融合异常检测方法
- 论文来源丨ICSE 2022
- 论文作者:复旦大学的张晨曦、彭鑫、沙朝锋、张可、傅震卿、吴茜雅,微软亚洲研究院的林庆维、张冬梅
- 论文链接丨https://cspengxin.github.io/publications/icse22-DeepTraLog.pdf
论文解析
基础知识
微服务架构
- 微服务架构是一种软件架构模式,用于构建复杂的应用程序。在微服务架构中,一个应用程序被拆分成一组小型、独立的服务单元,每个服务单元都是相对独立的,拥有自己的业务功能和数据存储。
- 微服务架构的关键思想是将应用程序拆分为多个小型服务,每个服务都能够独立部署、扩展和管理。这些服务通过轻量级通信机制(例如HTTP/REST)进行通信,通过网络协同工作,共同构建整体的应用程序。每个微服务都专注于解决特定的业务问题,可以使用不同的编程语言、技术栈和数据存储。
微服务架构的优劣势
- 独立开发和部署:每个微服务可以由独立的团队开发和部署,提高开发速度和灵活性。
- 弹性和可伸缩性:每个微服务可以根据需求独立进行扩展,提高系统的弹性和可伸缩性。
- 高可用性和容错性:由于微服务是独立的,一个服务的故障不会影响整个应用程序的正常运行,提高了系统的可用性和容错性。
- 技术多样性:不同的微服务可以使用不同的技术栈和编程语言,根据需求选择最适合的技术和工具。
- 可维护性和可扩展性:微服务的拆分使得应用程序的代码更加模块化,提高了代码的可维护性和可扩展性。
然而,微服务架构也带来了一些挑战,如服务间通信的复杂性、分布式事务的管理、服务的发现和监控等。因此,在采用微服务架构时需要仔细考虑这些挑战并选择适当的工具和技术来解决。
微服务架构的工业应用
在工业界,微服务架构已经广泛应用于各个领域和行业。以下是一些常见的工业界微服务系统的例子:
- 电子商务平台:许多大型电子商务平台采用微服务架构来构建其核心业务。例如,亚马逊、eBay和阿里巴巴等公司的电子商务平台都使用微服务架构,将核心功能(如订单处理、库存管理、支付服务等)拆分为独立的微服务。
- 金融服务:金融机构和支付服务提供商也广泛采用微服务架构来构建其系统。例如,PayPal、Stripe和Square等公司使用微服务架构来处理支付交易、风险管理和账单管理等关键功能。
- 物流和运输:物流和运输行业也在采用微服务架构来实现更高效的服务。例如,Uber和滴滴等出行平台使用微服务架构来处理实时位置跟踪、订单调度和路线规划等功能。
- 通信服务提供商:通信服务提供商使用微服务架构来构建其通信平台和应用程序。例如,Twilio和Nexmo等公司提供基于云的通信服务,使用微服务来处理电话呼叫、短信发送和实时通信等功能。
- 健康保健:健康保健行业也开始采用微服务架构来构建医疗信息系统和健康管理平台。例如,医院和医疗机构使用微服务来管理患者信息、预约和医疗服务。
名词解释
-
调用链与日志
-
- trace:记录了服务之间的调用关系
- log:记录服务内部的行为模式
- 二者可以通过在logging时插入traceid和spanid关联起来
-
已有工作
-
-
trace anomaly detection
-
- 通常采用深度学习方法,把每一条trace看作是服务调用的序列。但是实际中服务调用会有层级结构,存在异步、并行等情况,所以trace的结构比较复杂
- 没有考虑每个服务内部的日志
-
log anomaly detection
-
- 通常把日志看作是log event(模板)的序列,但是在分布式系统中,每个请求都涉及到多个节点的日志,通常按照时间排序。但是微服务系统中,这种方式忽略了复杂的调用结构
-
论文核心内容
核心思想采用一个统一的图表示框架(a unified graph representation),trace event graph (TEG)可以同时建模调用链结构和调用中涉及的日志
-
算法流程:(DeepTraLog不依赖标注,只要求输入的训练数据大部分是正常样本)
-
- 首先,对输入的trace和log进行parse,提取span event和log event
- 其次,对span event和log event 进行向量表示,并对每一个trace构造一个TEG
- 训练基于deep SVDD (Support Vector Data Description) 的gated graph neural networks (GGNNs) based 模型,来学习每个TEG的隐藏表示
- 在线检测:对线上的trace和log进行同样的处理,输入到训练好的模型中,得到该trace的隐藏表示,从而计算得到异常分数。
- 贡献:将trace和log进行融合用于微服务系统的异常检测,并且设计了一个统一的图表示框架
论文的创新点
该论文的创新点主要包括以下几个方面:
- 结合了追踪和日志数据:该方法利用了微服务架构中的两种重要数据源,即追踪数据和日志数据。追踪数据记录了微服务之间的调用和依赖关系,而日志数据包含了微服务的运行状态和事件信息。通过结合这两种数据,DeepTraLog能够综合考虑微服务之间的依赖关系和行为模式,提高异常检测的准确性。
- 基于图形的深度学习:DeepTraLog使用了图卷积神经网络(GCN)作为核心模型,来学习微服务之间的表示和依赖关系。相比传统的基于特征提取的方法,GCN能够更好地捕捉微服务之间的复杂依赖关系,并能够自动学习特征表示,减少了手工特征工程的需求。
- 生成对抗网络(GAN)生成模拟数据:为了提高模型的泛化能力,论文引入了基于GAN的方法来生成模拟的正常行为日志数据。这样可以扩充训练集,并增加对正常行为的覆盖范围,从而使得模型在异常检测任务上表现更好。
- 针对微服务异常检测的有效性:DeepTraLog在微服务异常检测任务上进行了实验评估,并与传统方法和基于深度学习的方法进行了比较。实验结果表明,DeepTraLog相对于其他方法在异常检测准确性方面表现更好,能够有效地捕捉各种类型的异常情况。这证明了DeepTraLog在微服务环境下的有效性和潜力。
综上所述,DeepTraLog的创新点在于将追踪和日志数据相结合,利用基于图形的深度学习技术进行微服务异常检测,并引入生成对抗网络生成模拟数据,从而提高了异常检测的准确性和泛化能力。
论文的总体思想
该论文的总体思想是利用追踪和日志数据,通过基于图形的深度学习方法来进行微服务异常检测。微服务架构中的系统由多个独立的组件(微服务)组成,它们通过网络相互通信。当存在异常情况时,例如性能下降或错误行为,这些异常往往会在追踪和日志数据中留下痕迹。
DeepTraLog的关键思想是将追踪和日志数据结合起来,构建一个有向图模型来表示微服务之间的依赖关系和行为模式。该方法利用图卷积神经网络(GCN)学习节点的表示,将追踪和日志数据的特征编码到节点表示中。通过GCN,DeepTraLog能够捕捉微服务之间复杂的依赖关系,从而提高异常检测的准确性。
另外,论文还提出使用生成对抗网络(GAN)生成模拟的正常行为日志数据。通过生成模拟数据并与真实数据混合,DeepTraLog可以增加训练集的样本数量,并提升模型对正常行为的识别能力,增强了模型的泛化能力。
总的来说,DeepTraLog的总体思想是将追踪和日志数据相结合,利用基于图形的深度学习方法来建模微服务之间的依赖关系和行为模式,并通过生成对抗网络增强模型的泛化能力,从而实现准确和可靠的微服务异常检测。
论文的methodology是什么
DeepTraLog论文的方法学主要包括以下步骤:
- 数据准备:首先,收集微服务系统中的追踪数据和日志数据。追踪数据包含微服务之间的调用和依赖关系,日志数据记录了微服务的运行状态和事件信息。
- 构建有向图模型:将追踪和日志数据转换为一个有向图,其中节点表示微服务,边表示微服务之间的依赖关系。通过将追踪数据和日志数据结合起来,构建一个综合的图形模型,能够捕捉微服务之间的依赖关系和行为模式。
- 图卷积神经网络(GCN)的训练:使用图卷积神经网络对构建的有向图进行训练。GCN能够学习节点的表示,将追踪和日志数据的特征编码到节点表示中。通过多层GCN的堆叠,能够更好地捕捉微服务之间的复杂依赖关系。
- 异常检测:利用训练好的GCN模型对新的微服务数据进行异常检测。通过计算节点的异常分数,可以识别出异常的微服务。异常分数可以基于重构误差或其他定义的指标进行计算。
- 生成对抗网络(GAN)生成模拟数据:为了提高模型的泛化能力,论文引入了基于GAN的方法来生成模拟的正常行为日志数据。通过训练生成器和判别器网络,生成模拟数据以及与真实数据进行混合,扩充训练集,并增加对正常行为的覆盖范围。
- 性能评估:通过实验评估来验证DeepTraLog的性能。使用真实的异常数据集和正常数据集进行训练和测试,比较DeepTraLog与传统方法和基于深度学习的方法在微服务异常检测方面的准确性和可靠性。
总的来说,DeepTraLog的方法学包括数据准备、构建有向图模型、使用GCN进行训练和异常检测、利用GAN生成模拟数据以及性能评估。这些步骤相互配合,构成了该方法的核心方法学。
论文的模型是什么?
DeepTraLog的模型主要基于图卷积神经网络(GCN)。GCN是一种基于图结构数据的深度学习模型,用于学习节点的表示和捕捉节点之间的依赖关系。
在DeepTraLog中,首先构建一个有向图模型,其中节点表示微服务,边表示微服务之间的依赖关系。然后,通过GCN对这个有向图进行训练和表示学习。GCN通过多层的图卷积层将节点的特征进行传递和更新,从而学习到微服务之间的复杂依赖关系和行为模式。
GCN的基本操作是在每个节点上聚合其邻居节点的特征并进行更新。聚合操作可以通过加权平均、池化等方式进行,以捕捉节点的上下文信息。然后,更新的节点表示可以传递到下一层的GCN中进行进一步的特征学习和表示。
在DeepTraLog中,GCN模型接收有向图作为输入,并通过多层的GCN层来学习节点的表示。这些节点表示将追踪和日志数据的特征编码到图中的节点上。通过学习到的节点表示,DeepTraLog能够捕捉微服务之间的复杂依赖关系和行为模式,从而实现微服务异常的检测和识别。
除了GCN模型之外,DeepTraLog还可以使用生成对抗网络(GAN)生成模拟数据来增强模型的泛化能力。GAN模型由生成器和判别器组成,通过对抗训练的方式生成模拟的正常行为日志数据,扩充训练集,增加对正常行为的覆盖范围。
综上所述,DeepTraLog的模型主要基于图卷积神经网络(GCN),通过学习节点的表示来捕捉微服务之间的依赖关系和行为模式,以实现微服务异常的检测和识别。
论文的应用是什么?
DeepTraLog的应用是用于微服务环境下的异常检测。在现代软件架构中,微服务架构已经广泛应用,它将复杂的应用程序拆分为小型、独立的服务单元,这些服务单元之间通过网络进行通信。然而,微服务架构的复杂性和分布性使得异常检测变得更加困难。
DeepTraLog的方法通过结合追踪和日志数据,并利用基于图的深度学习技术,旨在提高微服务环境下的异常检测的准确性和可靠性。它的应用范围涵盖了微服务架构中的各种应用领域,例如:
- 云计算平台:在云计算平台中,微服务通常被用于构建和管理各种云服务,如存储、计算、网络等。DeepTraLog可以应用于云平台,帮助检测异常行为,提高云服务的性能和可靠性。
- 分布式系统:在分布式系统中,各个组件通过网络通信协同工作,形成一个整体。DeepTraLog可以用于检测分布式系统中的异常情况,帮助提高系统的稳定性和可靠性。
- 物联网(IoT):在物联网应用中,微服务通常用于处理大规模传感器数据和设备之间的通信。DeepTraLog可以应用于物联网中,帮助检测设备或传感器的异常行为,提高物联网系统的安全性和可靠性。
- 微服务架构应用:在各种使用微服务架构的应用中,DeepTraLog可以用于监控和检测微服务之间的异常行为,例如电子商务、在线支付、社交媒体等应用。
总的来说,DeepTraLog的应用范围广泛,适用于各种微服务架构下的应用领域,旨在提高异常检测的准确性和可靠性,从而帮助提高系统的性能、稳定性和安全性。
实现思路
DeepTraLog的实现思路如下:
- 数据准备:首先,从微服务系统中收集追踪数据和日志数据。追踪数据包含了微服务之间的调用和依赖关系,日志数据记录了微服务的运行状态和事件信息。
- 构建有向图模型:将追踪数据和日志数据转化为一个有向图结构,其中图的节点表示微服务,边表示微服务之间的依赖关系。构建有向图时,需要考虑微服务之间的调用关系、依赖关系以及时间顺序等信息,以捕捉微服务之间的复杂关系。
- 图卷积神经网络(GCN)训练:将构建的有向图输入到GCN模型中进行训练。GCN模型通过多层的图卷积层来学习节点的表示,将追踪和日志数据的特征编码到节点表示中。通过传递和更新节点表示,GCN能够捕捉微服务之间的依赖关系和行为模式。
- 异常检测:利用训练好的GCN模型对新的微服务数据进行异常检测。通过计算节点的异常分数,可以识别出异常的微服务。异常分数可以基于重构误差或其他定义的指标进行计算。阈值可以根据实际情况进行设置,以确定何时将节点标记为异常。
- 生成对抗网络(GAN)生成模拟数据:为了增强模型的泛化能力,可以使用GAN生成模拟的正常行为日志数据。通过训练生成器和判别器网络,生成模拟数据以及与真实数据进行混合,扩充训练集,并增加对正常行为的覆盖范围。生成器可以根据随机噪声生成类似于正常行为的日志数据。
- 性能评估:通过实验评估来验证DeepTraLog的性能。使用真实的异常数据集和正常数据集进行训练和测试,比较DeepTraLog与传统方法和基于深度学习的方法在微服务异常检测方面的准确性和可靠性。可以使用常见的评估指标如精确度、召回率、F1分数等来衡量模型的性能。
综上所述,DeepTraLog的实现思路包括数据准备、构建有向图模型、使用GCN进行训练和异常检测、利用GAN生成模拟数据以及性能评估。这些步骤共同构成了DeepTraLog方法的实际实现过程。
论文翻译
摘要
工业界的微服务系统通常是由几十到几千个服务运行在不同的机器上组成的大规模分布式系统。系统的异常往往可以体现在trace和log中,分别记录服务间的交互和服务内的行为。现有的跟踪异常检测方法将跟踪视为一系列服务调用。他们忽略了由其调用层次结构和并行/异步调用带来的跟踪的复杂结构。另一方面,现有的日志异常检测方法将日志视为一系列事件,无法处理分布在大量交互复杂的服务中的微服务日志。在本文中,我们提出了 DeepTraLog,一种基于深度学习的微服务异常检测方法。 DeepTraLog 使用统一的图形表示来描述跟踪的复杂结构以及嵌入结构中的日志事件。基于图形表示,DeepTraLog 通过组合轨迹和日志来训练基于 GGNN 的深度 SVDD 模型,并检测新轨迹和相应日志中的异常。对微服务基准的评估表明,DeepTraLog 实现了高精度 (0.93) 和召回率 (0.97),优于最先进的跟踪/日志异常检测方法,F1 分数平均提高 0.37。它还验证了 DeepTraLog 的效率、统一图形表示的贡献以及一些关键参数配置的影响。
目前微服务系统中的 Trace 和 Log 异常检测方法不能捕获到 Trace 和 Log 间复杂的层次调用和交互特征,因此这篇文章中结合 Log 和 Trace 数据提出了一种基于 GNN 深度学习方法 DeepTraLog,可以把 Trace 间复杂的调用结构和服务的日志时间统一建模到图结构中,然后用 Deep SVDD 模型进行异常检测。实验部分证明 DeepTraLog 相比于其它 baselines 在基准服务中可以达到较高的 precision (0.93) 和 recall (0.97)。
1 简介
-
微服务架构是一种将单个应用程序开发为一组小型服务的方法,每个服务都在自己的进程中运行并通过轻量级机制进行通信 [15]。工业界的微服务系统通常是一个大规模的分布式系统,有几十到几千个服务运行在不同的机器上。在高度不确定和动态的环境中运行,微服务系统经常因各种基础设施问题或应用程序故障而失败,例如硬件故障、不正确的配置、实施故障以及服务交互中的不正确协调 [42, 43]。为了让工程师能够及时对潜在的故障做出反应,希望能够在运行时自动检测到微服务系统的异常。
-
在 OpenTracing [27] 等规范和 SkyWalking [33] 等基础设施相关的支持下,分布式跟踪 [32] 已在工业微服务系统中得到广泛采用。每个产生的轨迹描述了请求通过服务实例的执行过程(即调用链),其中的每个操作(即服务调用)称为一个跨度。同时,日志记录也被开发者广泛使用来记录各个服务的行为。日志记录各种关键点的重要消息,用于调试和根本原因分析 [7]。跟踪可以包括几个到数百个服务调用(即跨度),并且在每次调用期间,调用的服务实例会生成一系列日志消息。工业分布式跟踪系统可以通过将跟踪 ID 和跨度 ID 注入到不同服务实例产生的日志消息中来链接同一跟踪的日志消息。
-
最近的研究 [20, 26] 使用基于深度学习的跟踪分析方法来检测微服务系统的运行时异常。这些方法将跟踪视为一系列服务调用。但是,跟踪可以具有由服务调用的层次结构和并行/异步调用形成的复杂结构。现有的轨迹异常检测方法忽略了轨迹的复杂结构。此外,他们不考虑描述跟踪中涉及的各个服务实例的行为的日志消息。因此,这些方法不能很好地捕获微服务异常。
-
另一方面,日志在分布式系统的异常检测中得到了广泛的应用。现有的日志异常检测方法 [7、24、40] 从正常执行中学习日志模式,并在日志模式偏离训练模型时检测异常。这些方法将日志视为一系列日志事件,它们是一组相似日志消息的抽象 [12]。对于分布式系统,通过将来自请求中涉及的不同节点的日志消息按时间戳排序,为每个请求生成日志。而对于微服务系统来说,一个请求对应一个调用链,可能涉及到很多服务实例以及它们之间复杂的调用。如果我们以类似的方式为请求生成日志,则它无法很好地捕获其调用链的复杂结构。
-
在本文中,我们提出了 DeepTraLog,一种基于深度学习的微服务异常检测方法。 DeepTraLog 使用称为跟踪事件图 (TEG) 的统一图形表示来描述跟踪的复杂结构以及嵌入结构中的日志事件。它以跟踪和日志作为输入,并训练基于图形的深度学习模型以进行跟踪异常检测。首先,它解析输入跟踪和日志,并分别从中提取跨度关系和日志事件。其次,它为跨度事件和日志事件生成矢量表示,同时为每个轨迹构建一个 TEG。第三,它训练基于门控图神经网络 (GGNN) 的深度 SVDD(支持向量数据描述)模型,该模型学习每个 TEG 的潜在表示和最小化数据封闭超球体。当用于异常检测时,DeepTraLog 以类似的方式分析轨迹和相关日志,并使用经过训练的模型为轨迹生成潜在表示。然后,它根据其异常分数确定轨迹是否异常,即从轨迹的潜在表示到超球体的最短距离。请注意,DeepTraLog 不依赖于跟踪标记,只要求训练集中的大部分跟踪是在系统正常执行时产生的。此外,它能够捕获不同类型的异常。
-
为了评估 DeepTraLog 的有效性和效率,我们对微服务基准系统进行了一系列实验研究。结果表明,DeepTraLog 在准确率和召回率方面分别优于现有的基于跟踪和基于日志的异常检测方法,平均分别高出 64.94% 和 101.59%。统一的图形表示极大地促进了 DeepTraLog 的改进,使其在精度和召回率方面分别比使用序列表示的 DeepTraLog 变体平均高出 7.64% 和 26.03%。 DeepTraLog 在模型训练和测试方面非常高效,它在异常检测中的响应时间随着迹线的大小线性增加。
-
总之,本文做出了以下贡献:
- 跟踪和日志的统一图形表示,有助于对它们进行组合分析;
- 用于微服务异常检测的基于GGNN 的深度SVDD 模型;
- 一系列实验研究验证了DeepTraLog 的有效性和效率,以及统一图形表示的贡献和一些关键参数配置的影响。
-
意义:
- 我们的工作提供了一种新的有效方法来组合跟踪和日志以进行微服务异常检测,其性能优于现有的日志/跟踪异常检测方法。它为服务间交互和服务内行为定义了统一的基于图形的表示。该表示可以促进各种不同的微服务分析任务,例如异常检测、根本原因分析和架构理解。
2 背景和动机
在本节中,我们首先介绍有关跟踪和日志的背景,然后通过一个例子来激发我们的工作。
2.1 背景
-
作为一种大规模分布式系统,微服务系统广泛使用分布式跟踪[27、32]来分析和监控它们的执行。跟踪是请求在分布式系统中移动时的执行过程的描述 [27]。对于微服务系统,trace描述了一个请求通过服务实例的执行过程,即服务调用链。跟踪中的服务调用最初由单个服务实例记录,然后收集并恢复到跟踪中。如图 1 所示,一个 trace 由树形结构中的一组 span 组成,每个 span 对应一个服务调用。每个跟踪都有一个唯一的跟踪 ID,每个跨度都有一个唯一的跨度 ID。跨度记录了调用者和被调用的服务实例,并有一个操作名称指示要执行的操作。例如,REST 调用跨度的操作名称可以是 POST /api/v1/foodservice/orders。每个跨度(根跨度除外)都有一个启动当前跨度的父跨度。例如图1中的Span A是一个同步调用,它在执行过程中发起了两次同步调用,分别对应Span B和Span D。因此,跨度 A 是跨度 B 和跨度 D 的父级。分布式跟踪一直是微服务基础架构的重要组成部分,并得到开源解决方案(例如 Zipkin [35]、Jeager [13] 和 SkyWalking [33])的支持) 和云服务提供商(例如,亚马逊的 X-Ray [3] 和阿里云的 ARMS [1])。
-
异步调用和并行调用在微服务系统中被广泛使用,以获得更好的性能和可用性。跟踪可以包括几个到数百个跨度(即服务调用)。因此,由于停机时间的倍增效应,同步调用通常被认为是有害的 [15]。异步调用通常通过基于消息的通信来实现,并且被认为是实现高可用性系统的一种方式,因为调用者在等待时不会阻塞。并行调用意味着同时调用多个服务以减少整体响应时间。它们通常通过在多个线程中进行服务调用来实现。
-
如图 1 所示,每次服务调用期间都会生成日志消息。这些日志消息是由服务开发人员编写的日志语句生成的。它们记录被调用服务实例的内部状态和行为。日志消息是一个非结构化的句子,它包含一个常量部分(日志事件)和几个可变部分(日志参数)。例如,日志消息“[assignSeat] Requested seat type is T1 and number is 2”包含一个日志事件“[assignSeat] Requested seat type is <> and number is <>”和两个日志参数 SeatType 和 SeatNumber。日志事件提取一直是日志解析中的标准步骤。日志解析后,将日志转换为一系列日志事件。
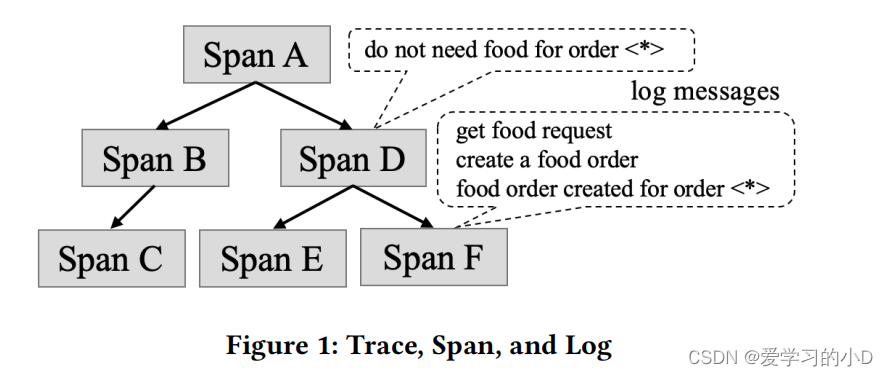
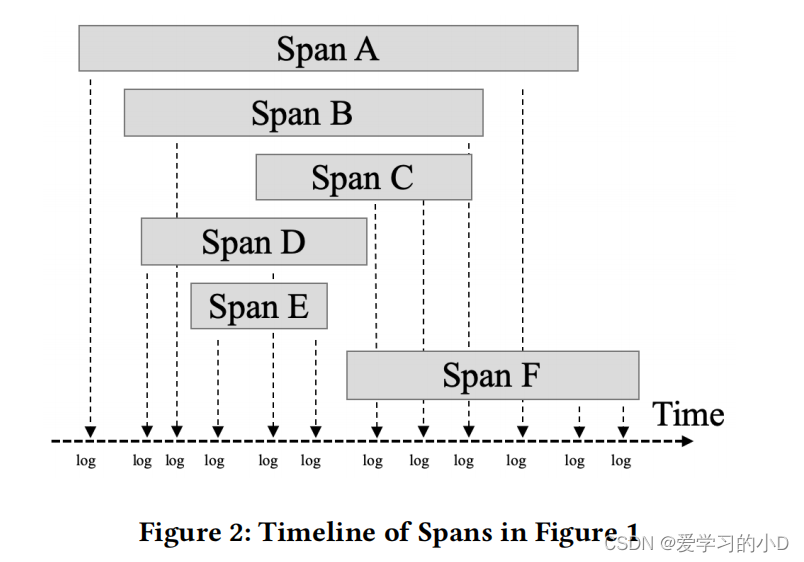
- 如上图所示,一条trace是由多个span组成的树形结构,一个span表示一次服务调用。每条trace对应由唯一的traceID,每个span对应由唯一的spanID。每个span包含了调用方、被调用方和operation name,并且除了根节点之外都有对应的parent span
- tracing工具:Zipkin, Jeager, SkyWalking等
- log是在每个服务被调用过程中打印的,记录了被调用服务实例的状态和行为。log通常包含常量部分(log event)和变量部分(log parameters)
- trace与log的关联:由于一个服务实例会同时为多个request提供服务,因此为了区分开来,监控工具通常会在log中记录对应的traceID和spanID,从而可以根据ID进行关联
- 可以结合跟踪和日志来分析微服务系统的运行时行为。跟踪描述请求的服务交互,而日志记录单个服务实例中的内部状态和行为。由于一个服务实例可能同时为多个请求服务,它的日志文件中会留下不同请求的日志消息。为了支持组合分析,一些分布式跟踪系统(例如,SkyWalking [33]、Alibaba ARMS [1])将跟踪 ID 和跨度 ID 注入到日志消息中,因此服务实例的日志消息可以与不同的请求相关联。例如,SkyWalking 使用 Java 日志记录框架(例如 Log4j [2]、Logback [21])的映射诊断上下文机制来注入跟踪 ID 和跨度 ID 以记录消息。
2.2 动机
- 图2显示了图1中span的时间线。Span B和Span D是由Span A生成的两个并行调用,因此它们在时间线上有一些重叠。 Span F 是由 Span D 生成的异步调用,因此它在 Span D 之后结束。
- 现有的跟踪异常检测方法 [20, 26] 将跟踪视为一系列服务调用,而现有的日志异常检测方法 [7, 24, 40] 将日志视为一系列日志事件。由于以下两个原因,这些方法不能很好地支持微服务系统的异常检测。
- 首先,需要结合不同服务实例的日志进行异常检测。现有的轨迹异常检测方法没有考虑日志,因此只能检测轨迹结构中反映的异常。图 1 显示了日志级别异常的示例。 Span D中的日志消息显示火车票订单不需要食物,但Span F中的日志消息显示为此火车票订单创建了食物订单。这种异常只能通过组合 Span D 和 F 的日志消息来检测。
- 其次,跟踪可能具有复杂的结构,涉及调用层次结构和并行/异步调用。跟踪具有树结构。如果所有跨度都是同步调用,则跟踪可以由按开始时间排序的一系列服务调用来表示。即便如此,基于序列的表示不能反映父子跨度之间的因果关系以及相同跨度的日志事件之间的时间关系。例如,跨度 A 中的两个相邻日志事件可能在基于序列的表示中相距很远,因为跨度 A 的后代跨度的日志事件被插入其中。此外,跟踪可能包括并行或异步调用。图 1 和图 2 中显示的跟踪包括两个并行调用(跨度 B 和跨度 D)和一个异步调用(跨度 F)。因此,跨度 B 和跨度 D(及其后代跨度)中的日志事件可以以任何顺序交错;类似地,Span F 中的日志事件和 Span D 中的部分日志事件可以以任何顺序交错。如果我们将不同跨度的日志事件组合成一个序列(例如,按开始时间),就会失去并行或异步调用的特性。
- 根据分析,我们可以看到一个trace的不同跨度的日志事件需要以一种能够保持trace结构的方式进行组合。因此,我们提出了一种统一的图形表示,可以描述跟踪的结构以及嵌入结构中的日志事件,以促进异常检测。
3.方法
DeepTraLog 的目标是自动准确地检测微服务系统的异常痕迹。它将跟踪和日志作为输入并训练基于图形的深度学习模型。当用于异常检测时,它以类似的方式分析跟踪和关联的日志,并使用模型为跟踪生成表示以计算其异常分数。 DeepTraLog 的概述如图 3 所示,其中包括六个步骤。日志解析解析输入日志并从日志消息中提取日志事件。 Trace Parsing 对输入的trace进行解析,将其span转化为span events,与log events一起分析。事件嵌入为跨度事件和日志事件生成矢量表示。 Graph Construction 为每个轨迹构建一个轨迹事件图 (TEG),以表示轨迹的跨度/日志事件之间的各种关系。模型训练训练基于门控图神经网络 (GGNN) 的深度 SVDD(支持向量数据描述)模型,该模型学习每个 TEG 的潜在表示和包含 TEG 表示的最小化超球体。异常检测根据其异常分数(即从其 TEG 的潜在表示到超球体的最短距离)确定轨迹是否异常。
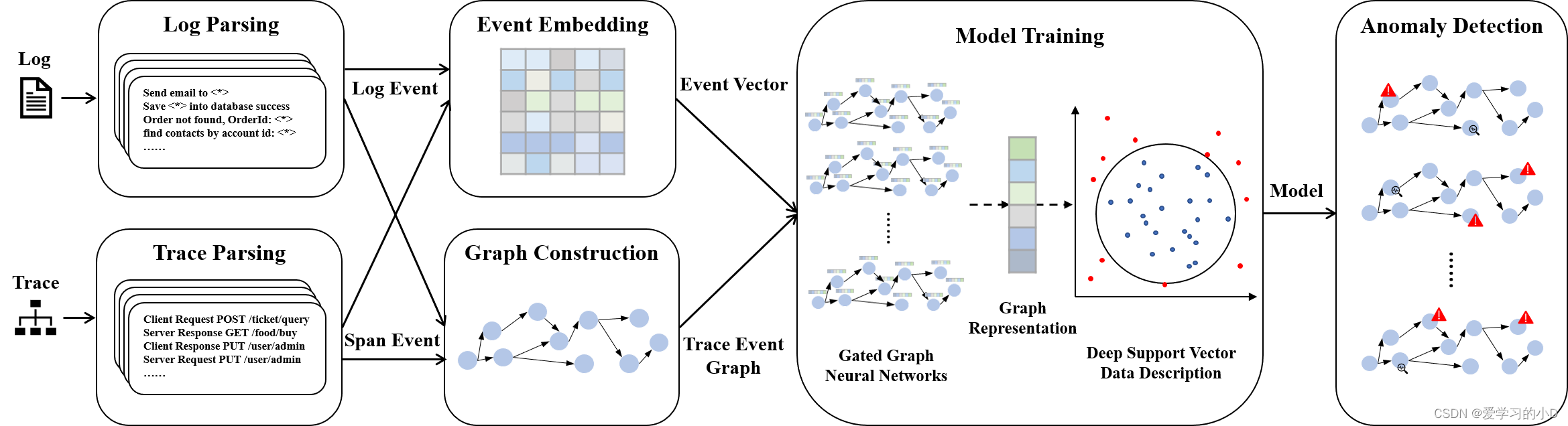
Figure 3: DeepTraLog Overview
主要想法:对于每个 Trace,span 作为节点,每个 span 的对应的 log 通过 TF-IDF 嵌入作为特征向量,以此构建 TEG(trace event graph),示例如下
- DeepTraLog的目标是自动准确地检测微服务系统的异常轨迹。它将轨迹和日志作为输入,并训练基于图的深度学习模型。当用于异常检测时,它以类似的方式分析轨迹和相关日志,并使用该模型生成轨迹的表示,以计算其异常分数。
- DeepTraLog的概述如图3所示,其中包括六个步骤:
- 日志解析解析输入日志,并从日志消息中提取日志事件。
- 轨迹解析解析输入跟踪,并将其span转换为span事件,这些事件将与日志事件一起进行分析。
- 事件嵌入为span事件和日志事件生成矢量表示。
- Graph Construction为每个轨迹构建一个轨迹事件图(TEG),表示轨迹的span/log事件之间的各种关系。
- 模型训练训练基于门控图神经网络(GGNN)的深度SVDD(支持向量数据描述)模型,该模型学习每个TEG的潜在表示和包围TEG的表示的最小化超球体。
- 异常检测根据轨迹的异常分数(即从其TEG的潜在表示到超球体的最短距离)来确定轨迹是否异常。
3.1Log Parsing
- 提取traceID和spanID
- 采用Drain算法进行模板提取
继现有的日志异常检测研究[24,40]之后,我们采用了最先进的日志解析方法Drain[11]。它可以以流式和及时的方式解析日志,具有很高的解析精度和效率。为了支持与轨迹的组合分析,我们在日志解析之前提取并记录每个日志消息的轨迹ID和span ID。在日志解析之后,轨迹ID和span ID与提取的每个日志事件一起附加,用于进一步分析。
3.2 Trace Parsing
-
服务实例的日志事件构成一个事件序列。为了将轨迹和日志结合起来进行异常检测,我们需要将轨迹的span转换为span事件。Span事件是一种特殊的事件,表示服务调用的请求和响应。当与日志事件一起分析时,span事件可以指示服务调用的开始和结束。
-
对于轨迹的每个span,我们根据其类型(客户端/服务器或生产者/消费者)将其转换为相关跨度的多个跨度事件。
- 客户端/服务器span表示同步调用,对于客户端/服务器跨度,我们分别为当前跨度(服务器)及其父跨度(客户端)生成一个请求事件和一个响应事件。客户端(服务器)的请求事件和响应事件分别表示服务调用的发送(接收)和调用响应的接收(发送)。
- 生产者/消费者span表示异步调用。对于生产者/消费者span,我们为当前span(消费者)生成消费者事件,为当前span的父span(生产者)生成生产者事件。生产者事件和消费者事件分别表示消息的发送和接收。
-
两种类型:span event的内容包含两部分:event type 和 operation names。一个是事件类型,另一个是操作名称。
-
Client/Server 客户端/服务器: 同步调用
- 当前的span是server,生成request event(发送方)和response event(接收方)
- 父亲span是client,同样生成两个event
- 举例:对于一个operation name是“POST /api/v1/foodservice/orders”的CS span
- 当前该span有两个event: “Server Request POST /api/v1/foodservice/orders” 和“Server Response POST /api/v1/foodservice/orders”
- 父亲space有两个event: “Client Request POST /api/v1/foodservice/orders” 和 “Client Response POST /api/v1/foodservice/orders”
-
Producer/Consumer 生产者/消费者:异步调用
-
-
举例:对于一个operation name是“RabbitMQ/Topic/Queue/email/sendEmail”
-
- 当前span: “Consumer RabbitMQ/Topic/Queue/email/sendEmail”
- 父亲span: “Producer RabbitMQ/Topic/Queue/email/sendEmail”
-
-
每个跨度事件都有一个从跨度记录中获得的时间戳。例如,客户端请求事件的时间戳是客户端服务实例发送服务调用的时间。
-
3.3 Event Embedding
参考日志异常检测中常用的文本embedding方法
- Preprocessing:分词,去除停用词、符号等噪声信息
- Word Embedding:预训练模型GloVe
- Sentence Embedding:使用TF-IDF对词向量进行加权,句子的向量由所有单词的向量加权平均得到
日志事件嵌入广泛应用于日志异常检测。它为每个日志事件生成一个向量表示。矢量表示可以识别语义相似的日志事件,也可以区分不同的日志事件[40]。在 DeepTraLog 中,跨度事件与日志事件一起分析以进行异常检测。因此,我们的事件嵌入为日志事件和跨度事件生成向量表示。每个日志事件或跨度事件都是一个英文单词序列,因此可以被视为一个句子。遵循日志事件嵌入的常见做法,DeepTraLog 分三步实现事件嵌入。
-
Step 1. Preprocessing:日志事件和跨度事件包含非字符标记(例如“/”和“,”等分隔符、IP 地址)、停用词(例如“a”、“the”、“is”)和复合词(例如,“verifycode”、“tripid”)。继之前的工作 [24、40] 之后,我们通过删除非语言符号和停用词并将复合词拆分为单独的词来预处理日志事件和跨度事件。例如,跨度事件“Client Request POST /api/v1/foodservice/orders”被预处理为“client request post api v1 food service orders”。
-
Step 2. Word Embedding:我们使用广泛使用的预训练 GloVe 模型 [29] 为日志事件和跨度事件中的每个单词生成向量表示。特别是,我们使用在 Wikipedia 和 Gigaword 5 数据 [9] 上训练的 GloVe 300 维词向量。因此,对于每个单词,我们可以获得一个 300 维向量作为其表示。
-
Step 3. Sentence Embedding“句子嵌入基于词嵌入为每个日志事件和跨度事件生成向量表示。这些事件中的话并不同样重要。有些词(例如,“api”、“get”)更常见,因此在句子嵌入中不如其他词(例如,“food”、“submit”)重要。因此,我们遵循以前的工作 [40],使用 T F − I D F TF-IDF TF−IDF [31] 来衡量句子嵌入中每个单词的权重。词 w w w在事件 e e e中的TF(词频),衡量其在 e e e中的重要性,计算公式为 T F w , e = L w , e L e , L e 是 e 中的单词数 TF_{w,e} = \frac{L_{w,e}}{L_e},L_e是e中的单词数 TFw,e=LeLw,e,Le是e中的单词数。单词w的IDF(逆文档频率),衡量它在所有事件中的频率,计算公式为 I D F w = l o g L L w IDF_w=log\frac{L}{L_w} IDFw=logLwL,其中𝐿是事件总数, L w 是包含 w 的事件数 L_w是包含w的事件数 Lw是包含w的事件数。然后一个词 w 在一个事件 e w在一个事件e w在一个事件e中的权重可以通过它的TF-IDF分数来衡量,如 W w , e = T F w , e ⋅ I D F w W_{w,e} = TF_{w,e} \cdot IDF_w Ww,e=TFw,e⋅IDFw。因此,事件 e e e的向量表示可以计算为其所有词的向量表示的加权和,如下所示,其中 N e 是 e 中不同词的数量 N_e是e中不同词的数量 Ne是e中不同词的数量, V w 是词 w 的向量表示 V_w是词w的向量表示 Vw是词w的向量表示。
V e = 1 N e ∑ w = 1 N e W w , e ⋅ V w V_e = \frac{1}{N_e} \sum_{w=1}^{N_e}W_{w,e}\cdot V_w Ve=Ne1w=1∑NeWw,e⋅Vw -
请注意,日志事件和跨度事件具有完全不同的特征,因此我们分别计算日志事件和跨度事件的TF-IDF分数和词权重。
3.4 Graph Construction
TEG图上的四种关系:
- Sequence序列:表示两个连续span/log之间的前置/后继关系
- Synchronous Request 同步请求:表示从父亲span到其儿子span的同步请求
- Synchronous Response 同步响应 :表示来自同步请求的响应
- Asynchronous Request异步请求:表示从父亲span到其儿子span的异步请求
构建步骤
- 关联日志:找到span的对应日志,并按照时间排序,构成序列关系
- 插入span event
- 连接span
-
跟踪事件图(TEG)由跟踪的日志事件和跨度事件及其关系组成。 TEG 中的关系可以是以下四种类型之一。
-
Sequence序列:序列关系表示同一跨度的两个连续跨度/日志事件之间的先驱/后继关系。
-
Synchronous Request同步请求:同步请求关系表示从父跨度到其子跨度的同步请求。
-
Synchronous Response同步响应:同步响应关系表示从跨度到其父跨度的同步请求的响应。
-
Asynchronous Request异步请求:异步请求关系表示从父跨度到其子跨度的异步请求。
-
给定轨迹,我们分三步构建 TEG。
- Step 1: Connection of Log Events第 1 步:连接日志事件。对于跟踪的每个跨度,获取属于该跨度的所有日志事件。然后按时间戳对日志事件进行排序,并添加从每个日志事件到它旁边的事件的顺序关系。
- Step 2: Insertion of Span Events第 2 步:插入 Span 事件。对于跟踪的每个跨度,获取属于该跨度的所有跨度事件。然后对于每一个获取到的span事件,根据其时间戳将其插入到当前span的日志事件序列中,并添加其与前导/后继事件的序列关系。
- Step 3: Connection of Spans第 3 步:跨度连接。对于每个跨度,按以下方式将其与其父跨度连接起来。如果span是Client/Server span,则添加从其父span对应的client请求事件到当前span对应的server请求事件的同步请求关系,和当前span对应的server响应事件的同步响应关系跨度到其父跨度的相应客户端响应事件。如果span是Producer/Consumer) span,则添加从其父span对应的producer事件到当前span对应的consumer事件的异步请求关系。
- 图 4 显示了 TEG 的示例,它对应于图 1 和图 2 中所示的迹线。在图中,彩色矩形角和未着色矩形分别表示跨度事件和日志事件。不同颜色的span事件是不同的类型,包括client/server request、client/server response、producer/consumer。请注意,图 4 中表示跨度的虚线圆角矩形不是 TEG 的节点,只是用于说明。这些跨度在 TEG 中由从服务器请求事件开始的事件序列隐式表示。不同颜色的箭头代表不同类型的关系。该图可以很好地描述迹线的结构以及其中的各种关系。同一跨度内的日志事件和跨度事件按时间戳组成一个序列。因此,可以在异常检测中描述和考虑服务间交互(跨度事件)和服务内行为(日志事件)之间的时间关系。不同跨度的事件是分开的,仅通过跨度事件之间的请求/响应关系连接。跟踪的结构体现在这些请求/响应关系中:同步调用由一对请求和响应关系反映;异步调用由请求关系反映,没有相应的响应关系。例如,可以看出 Span B 和 Span D 是并行同步调用,因为它们在 Span A 中的请求/响应范围重叠; Span F 是由 Span D 发起的异步调用,因为没有从 Span F 到 Span D 的响应。
a n s ( h g ) = ∣ ∣ h g − c ∣ ∣ 2 − R ^ 2 其中 : c 为 S V D D 的球心 R ^ 为球面半径。值大于 0 说明为异常, T r a c e 中每个 s p a n 的注意力权重为每个 s p a n 的异常分数。 ans(h_g) = ||h_g-c||^2-\hat R^2\\ 其中: c 为SVDD 的球心\\ \hat R为球面半径。值大于 0 说明为异常,\\Trace 中每个 span 的注意力权重为每个 span 的异常分数。 ans(hg)=∣∣hg−c∣∣2−R^2其中:c为SVDD的球心R^为球面半径。值大于0说明为异常,Trace中每个span的注意力权重为每个span的异常分数。
Figure 4: An Example of Trace Event Graph (TEG)
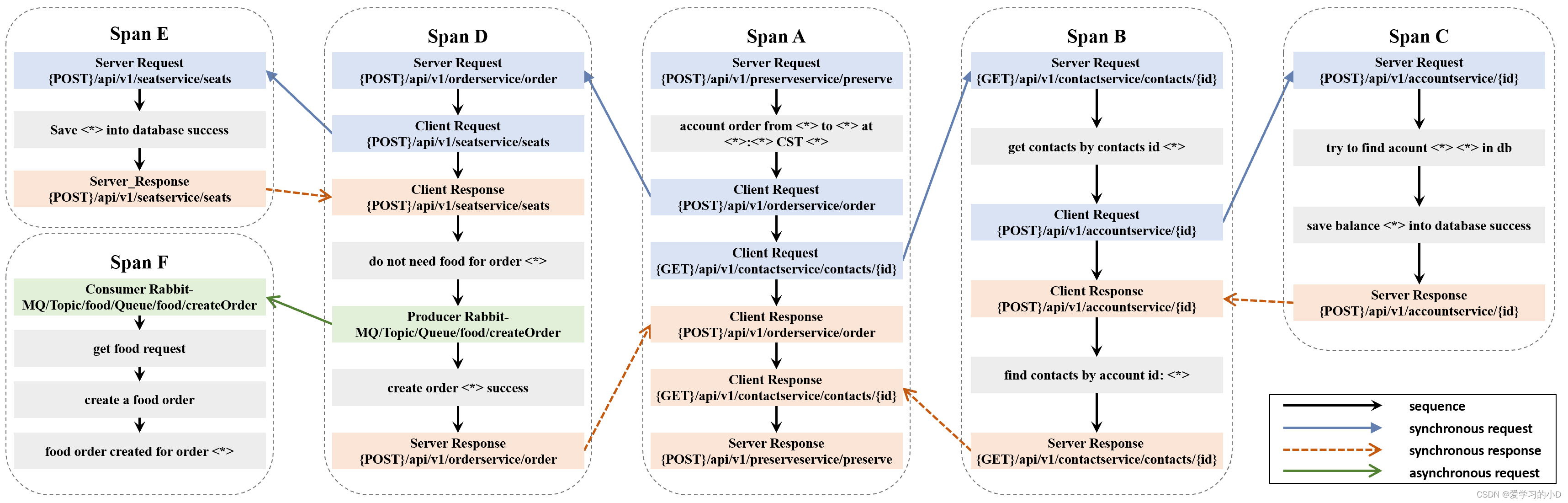
3.5 模型训练
- 把异常检测定义为单分类问题,训练数据基本都是正常样本
- 单分类模型采用SVDD,基于训练数据学习一个最小化超球空间(hypersphere),原理这个空间中心的样本被认为是异常。一些深度学习的异常检测方法(比如基于重构误差)需要设置异常分数阈值,而阈值的选择具有挑战。相比之下,SVDD可以联合学习数据的隐藏表示和分类边界,不需要设置阈值
- 图模型采用GGNN
-
我们将跟踪日志结合微服务异常检测的任务框架化为一类分类问题。一类分类问题旨在学习一个能够准确描述被认为属于同一类的列车数据的模型。对于异常检测任务,大部分训练样本都是正常样本,可以被视为同一类,其他样本可以被识别为异常值(例如,我们工作中的异常痕迹)。
-
DeepTraLog 使用深度 SVDD [30] 来训练用于检测异常痕迹的单类分类模型。 Deep SVDD 学习训练数据的有用特征表示以及包含数据潜在表示的最小化超球面。因此,远离超球体中心的数据可以被认为是异常的。现有的基于深度学习的异常检测方法 [20, 26] 通常使用深度自动编码器根据数据的重建误差来检测异常。因此,异常检测依赖于根据经验确定的重建误差阈值,这通常具有挑战性。相反,深度 SVDD 联合学习数据的潜在表示和没有阈值的分类边界。标准深度 SVDD 使用多层感知 (MLP) 或卷积神经网络 (CNN) 来学习数据的潜在表示。然而,在我们的工作中,迹线由图 (TEG) 表示,MLP 或 CNN 无法很好地处理它。因此,我们使用门控图神经网络 (GGNN) 来学习迹表示,并联合训练具有深度 SVDD 的 GGNN。 GGNNs 基于神经消息传递机制实现,可以很好地处理多种类型的图,例如有向图、二部图和无向图。
在 DeepTraLog 中,轨迹由 TEG 表示,它是一个有向属性图 g = { V , A , X } g = \{V,A, X\} g={V,A,X}
-
其中: V V V 是一组节点(即事件); A A A 是图的邻接矩阵; X ∈ R ∣ V ∣ ⋅ d X \in R^{|V| \cdot d} X∈R∣V∣⋅d是节点属性矩阵,其中 X X X的每一行 x v x_v xv是节点 v ∈ V v \in V v∈V的属性(即事件向量), d d d是事件向量的维数。
-
GGNN 将图中的节点表示为神经网络的单元,并且这些单元根据图的邻接矩阵相互链接。 GGNNs 在每次迭代中将节点属性作为单元之间的消息传递,并使用 GRU [4] 来确定在消息传递过程中要记住或忘记哪些消息。节点的最终表示由其自身状态和相邻节点状态的组合决定。第 𝑡 次迭代后节点的表示由以下等式定义:
h v ( 0 ) = x v m v ( t ) = A v T [ h 1 ( t − 1 ) T . . . h ∣ V ∣ ( t − 1 ) T ] T + b h v ( t ) = G R U ( m v ( t ) , h v ( t − 1 ) ) h^{(0)}_v = x_v \\ m^{(t)}_v = A^T_v [h^{(t−1)T}_1 ...h^{(t −1)T}_{|V|}]^T + b \\ h^{(t)}_v = GRU(m^{(t)}_v , h^{(t−1)}_v ) hv(0)=xvmv(t)=AvT[h1(t−1)T...h∣V∣(t−1)T]T+bhv(t)=GRU(mv(t),hv(t−1))- 其中 h v ( i ) 是节点 v 在第 i 之后的表示迭代 h^{(i)}_v是节点 v 在第 i 之后的表示迭代 hv(i)是节点v在第i之后的表示迭代 ;
- x v 是节点 v 的初始事件向量 x_v是节点v的初始事件向量 xv是节点v的初始事件向量 ;
- A v = [ α v , : T , α : , v ] A_v = [\alpha^T_{v,:} , \alpha_{:,v} ] Av=[αv,:T,α:,v] 是邻接矩阵A中的行和列,
-
分别代表v的入边和出边; 是GRU 函数。最后,经过T次迭代后,TEG 中的每个节点都可以有一个向量作为潜在表示。 GGNNs 使用软注意机制基于节点向量表示计算 TEG 的向量表示。 soft-attention机制以节点的向量表示作为输入,通过注意力函数计算每个节点的权重(attention score),给对图分类贡献大的节点赋予更高的权重。 TEG𝑔 的图形表示通过以下等式计算:
h g = t a n h ( ∑ v ∈ V ϕ ( f i ( h v ( T ) , x v ) ) ⊙ t a n h ( ( f j ( h v ( T ) , x v ) ) h_g = tanh(\sum_{v \in V}\phi(f_i(h_v^{(T)},x_v)) ⊙tanh((f_j(h_v^{(T)},x_v)) hg=tanh(v∈V∑ϕ(fi(hv(T),xv))⊙tanh((fj(hv(T),xv))- 其中 h g 是 T E G g 的矢量表示 h_g 是 TEG \ g 的矢量表示 hg是TEG g的矢量表示;
- f j ( h v ( T ) , x v ) 是软注意力机制 f_j(h_v^{(T)},x_v)是软注意力机制 fj(hv(T),xv)是软注意力机制;
- f i 和 f j f_i和f_j fi和fj是神经网络;
- T T T 是 GGNN 的层数;
- ⊙是逐元素乘法。
- 读者可以参考 [17] 了解有关 GGNN 的更多详细信息。
-
DeepTraLog 使用以下损失函数训练 GGNN,它表达了学习最小化超球面以包含 TEG 向量表示的目标:
L o s s = R 2 + 1 μ N g ∑ g = 1 N g m a x { 0 , ∣ ∣ h g − c ∣ ∣ 2 } + λ 2 ∑ l = 1 N l ∣ ∣ θ N l ∣ ∣ F 2 ) Loss = R^2 + \frac{1}{\mu N_g}\sum_{g = 1}^{N_g}max\{0,||h_g-c||^2\}+ \frac{\lambda}{2}\sum_{l=1}^{N_l}||\theta^{N_l}||_F^2) Loss=R2+μNg1g=1∑Ngmax{0,∣∣hg−c∣∣2}+2λl=1∑Nl∣∣θNl∣∣F2)- 其中 c 是超球面的中心 c是超球面的中心 c是超球面的中心;
- R 是超球体的半径 R是超球体的半径 R是超球体的半径;
- ∣ ∣ h g − c ∣ ∣ 2 是从 T E G g 到 c 的潜在表示的距离 ||h_g − c||^2 是从 TEG g到 c 的潜在表示的距离 ∣∣hg−c∣∣2是从TEGg到c的潜在表示的距离;
- N g 是 T E G 的数量 N_g 是 TEG的数量 Ng是TEG的数量;
- N l 是 G G N N 中的网络层数 N_l 是 GGNN 中的网络层数 Nl是GGNN中的网络层数;
- 超参数 μ 控制超球体积和边界违反之间的权衡 超参数\mu控制超球体积和边界违反之间的权衡 超参数μ控制超球体积和边界违反之间的权衡,这允许一些训练数据映射到超球外(即,允许训练集中的一些异常数据);
- λ 2 ∑ l = 1 N l ∣ ∣ θ N l ∣ ∣ F 2 ) \frac{\lambda}{2}\sum_{l=1}^{N_l}||\theta^{N_l}||_F^2) 2λ∑l=1Nl∣∣θNl∣∣F2)是 GGNN 参数 𝜃 和超参数 𝜆 的权重衰减正则化项。
-
在训练阶段,我们联合优化等式 3 中的 GGNNs 参数𝜃 和超球体半径 R R R。我们使用 Adam [14] 在每个 epoch 中优化 GGNNs 参数 θ \theta θ。由于半径 𝑅 不是 GGNN 的内部参数,我们使用如下不同的方法对其进行优化。我们在前几个时期用固定的R优化 θ \theta θ,在每个k时期之后,我们通过线性搜索计算R的优化值。每次更新 𝑅 时,其值都计算为当前纪元中所有 TEG 距离的 (1 − 𝜇) 百分位数。在初始前向传递之后,超球面中心c设置为所有 TEG 向量表示的平均值。
3.6 异常检测
- 异常分数用TEG的表示到学习到的hypersphere最小距离来衡量
-
DeepTraLog 训练了一个基于 GGNNs 的深度 SVDD 模型用于异常检测。给定一个新的轨迹和相应的异常检测日志,DeepTraLog 遵循与训练阶段相同的过程(即日志解析、轨迹解析、事件嵌入和图形构建)来生成 TEG 及其事件嵌入轨迹。然后 DeepTraLog 将 TEG 馈送到训练模型中以生成 TEG 的潜在表示,并使用潜在表示来计算异常分数
-
异常分数定义为从 TEG 的潜在表示到学习的超球面的最短距离,通过以下等式计算:
a n s ( h g ) = ∣ ∣ h g − c ∣ ∣ 2 − R ^ 2 ans(h_g) = ||h_g-c||^2-\hat R^2 ans(hg)=∣∣hg−c∣∣2−R^2-
TEG g的矢量表示; c是学习到的超球面的中心; R ^ \hat R R^是学习到的超球面的最终半径。
-
对于轨迹的 T E G g TEG \ g TEG g,如果其异常分数(即 a n s ( h g ) ans(h_g) ans(hg))大于 0,则将其视为异常。
-
-
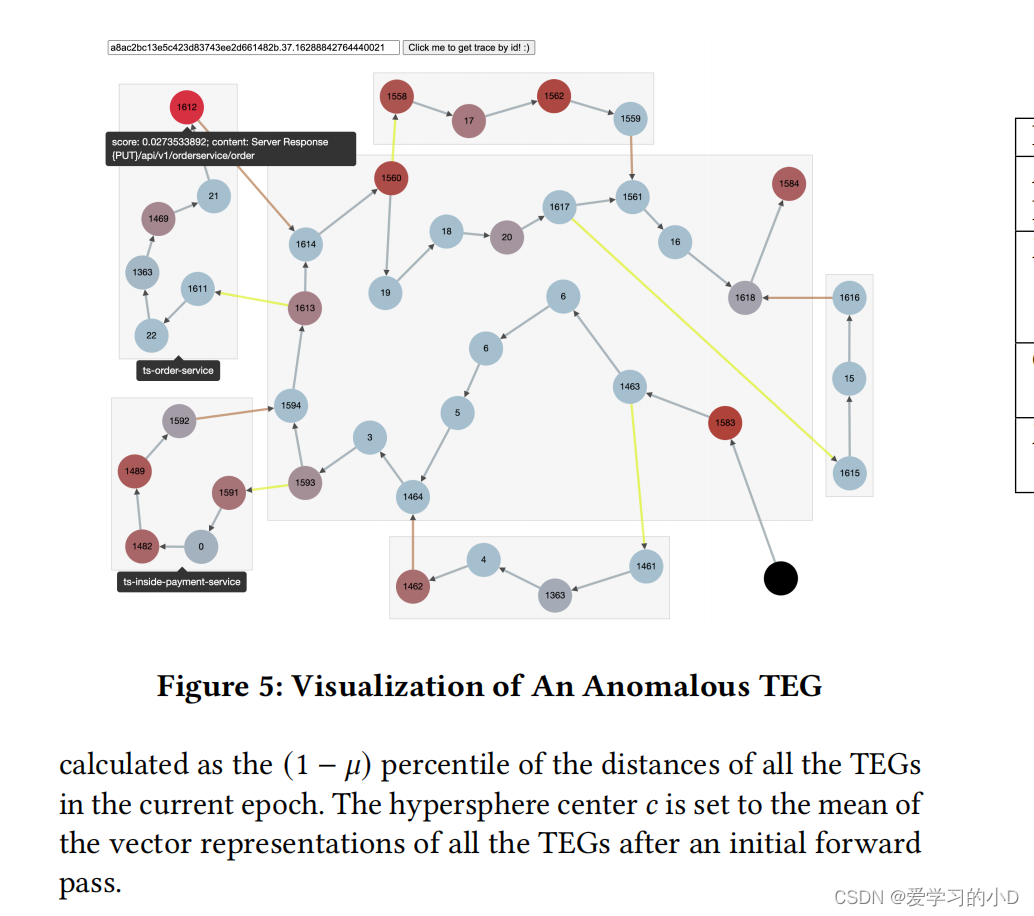
为了帮助用户了解异常检测的结果,DeepTraLog 提供了异常痕迹的 TEG 可视化。图 5 显示了异常 TEG 的可视化示例。具体来说,DeepTraLog 会突出显示 TEG 中使用公式 5 计算出的注意力得分较高的节点,这有助于用户快速定位轨迹的异常部分。
-
为了帮助用户了解异常检测的结果,DeepTraLog 提供了异常痕迹的 TEG 可视化。图 5 显示了异常 TEG 的可视化示例。具体来说,DeepTraLog 会突出显示 TEG 中使用公式 5 计算出的注意力得分较高的节点,这有助于用户快速定位轨迹的异常部分。
4 评估
我们使用 Python 3.8.8、PyTorch 1.8.0 和 PyTorch Geometric 1.7.2(用于 GGNN 学习)实现 DeepTraLog。为了对其进行评估,我们进行了一系列实验研究来回答以下研究问题:
- RQ1:与基线方法相比,DeepTraLog 在微服务异常检测中的有效性如何?统一的图形表示对 DeepTraLog 的有效性有多大贡献?
- RQ2:与基线方法相比,DeepTraLog 在模型训练和异常检测方面的效率如何? DeepTraLog 在在线预测中如何随迹线大小缩放?
- RQ3:基于GGNN 的深度SVDD 模型的不同配置如何影响DeepTraLog 的有效性?
4.1 实验设计
4.1.1 基准系统和数据集。
-
我们的研究是在 TrainTicket1 [42、44] 的最新版本 V0.2.0 上进行的。它是一个用于火车票预订的中型开源微服务系统,已广泛用于微服务架构、基础设施和 AIOps(IT 运营人工智能)[20、41、43] 的研究。它有 45 种由不同语言(例如 Java、JavaScript、Python)编写的服务,并通过同步 REST 调用和异步消息传递进行通信。
-
TrainTicket从工业微服务系统中复制了多种不同类型的故障案例,并提供了不同故障分支的故障案例。最新版本的TrainTicket提供了14种不同类型的兼容故障案例,如表1所示。每个故障案例可能包括不同服务中的多个故障实例。故障类型包括[43]:
- Asynchronous Interaction异步交互——由异步服务调用的缺失或不当协调引起的故障;
- Multi-Instance多实例——与运行时同一服务的多个实例存在相关的故障;
- Configuration配置——服务和/或环境(例如,容器和虚拟机)配置不当或不一致导致的故障;
- Monolithic 整体式——由单个服务的内部实现引起的故障,即使应用程序部署在整体模式下也可能导致故障。
-
因此我们可以有一个正常版本的 TrainTicket 和 14 个故障版本,每个版本对应一个故障案例的分支。我们在具有 8 个虚拟机的 Kubernetes 集群上部署了不同版本的 TrainTicket,每个虚拟机具有 16 核 3.0GHz CPU 和 32GB RAM。我们使用 Python 来实现一个可以执行自动化测试用例的执行控制器。对于每个版本,我们使用执行控制器通过执行自动化测试用例来模拟用户请求。我们使用 Apache SkyWalking [33] 作为分布式跟踪框架来收集跟踪和日志,并使用 ElasticSearch [8] 来存储收集的跟踪和日志。结果数据集包括 132,485 条跟踪和 7,705,050 条日志消息。在这些痕迹中,有 23,334 条 (17.6%) 异常痕迹是由位于不同服务中的 14 个故障案例中的 73 个故障引起的。该数据集用于整个实验研究。它在我们的复制包 [5] 中可用。
4.1.2 基线
-
我们使用以下四种最先进的基于日志或基于跟踪的异常检测方法作为基线。
-
TraceAnomaly [20] 是一种跟踪异常检测方法,它只考虑服务级别跟踪(不考虑操作)。它采用基于后验流的变分自动编码器(VAE)来检测异常痕迹。
-
MultimodalTrace [26] 是一种跟踪异常检测方法,它将跟踪视为跨度序列和响应时间序列。它采用多模态 LSTM(长短期记忆)模型来学习正常轨迹的顺序模式。
-
DeepLog [7] 是一种日志异常检测方法,将日志视为事件序列。它采用 LSTM 模型来预测序列中的下一个日志事件并识别可能的异常。
-
LogAnomaly [24] 是一种日志异常检测方法,它将日志视为事件序列,并将不同日志事件的计数视为附加功能。它采用 LSTM 模型来学习顺序和定量模式。与 DeepLog 类似,它通过预测下一个日志事件来检测异常。
-
-
由于 TraceAnomaly 和 MultimodalTrace 仅考虑轨迹,因此我们在使用它们时仅将轨迹提供给它们。 LogAnomaly 和 DeepLog 仅考虑日志并将其视为事件序列。因此,我们将跟踪的不同跨度的所有事件(包括跨度事件和日志事件)组合成按时间戳排序的单个事件序列,并提供所有跟踪的事件序列作为这两种方法的输入。 TraceAnomaly 和 DeepLog 提供了开源实现 [22, 34],我们直接使用它们。其他两种方法没有公开可用的实现,因此我们根据他们的论文开发了自己的实现。
-
为了评估跟踪和日志的统一图形表示(即 TEG)的贡献,我们推导出 DeepTraLog 的一个变体,称为基于 GRU 的 Deep SVDD,它将跟踪的所有事件表示为按时间戳排序的事件序列,并使用 GRU 代替的 GGNN。对于所有这些基线方法,我们通过实验选择最佳参数并使用它们的最佳结果进行比较。
4.1.3 指标
我们使用精度、召回率和 F1 分数来衡量基于𝑇𝑃(真阳性)、𝐹𝑃(假阳性)和𝐹𝑁(假阴性)的异常检测的有效性。
- Precision精度:异常迹线在所有被检测为异常的迹线中所占的百分比,表示为 p r e c i s i o n = T P T P + F P precision = \frac{TP}{TP+FP} precision=TP+FPTP
- Recall召回率:被检测为异常的所有异常痕迹的百分比,表示为 r e c a l l = T P T P + F N recall = \frac{TP}{TP +FN} recall=TP+FNTP 。
- F1-Score:准确率和召回率的调和平均值,表示为 F 1 = 2 ⋅ p r e c i s i o n ⋅ R e c a l l p r e c i s i o n + R e c a l l F1 = \frac{2·precision·Recall}{precision+Recall} F1=precision+Recall2⋅precision⋅Recall。
4.1.4 设置
- 所有实验均在配备 Intel Core i9-10900X 3.70GHz CPU、128GB RAM、RTX 3090 和 24GB GPU 内存并运行 Ubuntu 18.04.5 的 Linux 服务器上进行。 DeepTraLog 的设置如下:每个事件的嵌入大小设置为 300,GGNN 的隐藏层设置为 3,每个隐藏层的隐藏大小设置为 300,公式 6 中的𝜆和𝜇设置为 0.001 和 0.05分别,批量大小设置为 32。按照 [30] 中的做法,我们采用简单的两阶段学习率计划,前 60 个时期的初始学习率为 0.0001,随后在最后 40 个时期为 0.00001。对于每种方法,我们利用 60% 的正常轨迹作为训练集,10% 的正常轨迹作为验证集,其余轨迹(包括其余 30% 的正常轨迹和所有异常轨迹)作为测试集。
4.2 RQ1:有效性
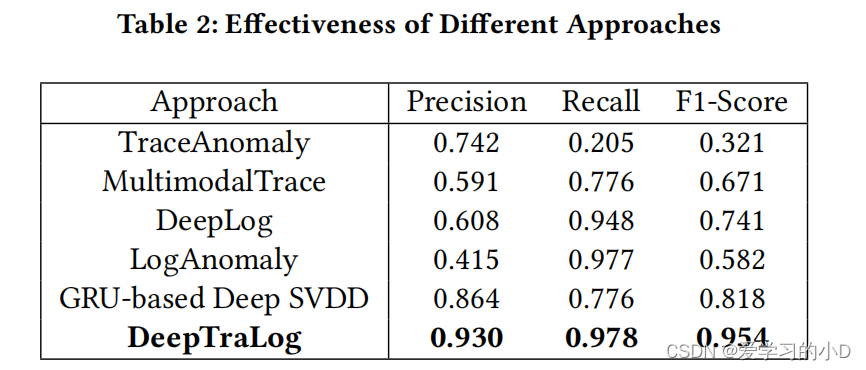
- 表2显示了不同方法的有效性评估结果。 DeepTraLog 优于所有基线方法,并实现了高精度 (0.930)、召回率 (0.978) 和 F1 分数 (0.954)。
-
两种基于跟踪的方法(即 TraceAnomaly 和 MultimodalTrace)实现了低精度和召回率。这两种方法不考虑日志,因此无法检测日志事件中的异常。由于他们使用基于序列的跟踪表示并特别关注响应时间,因此他们只能检测对跨度序列或响应时间分布有重大影响的异常。
-
两种基于日志的方法(即 DeepLog 和 LogAnomaly)实现了高召回率和低精度。这两种方法都考虑了跨度内的事件(我们为它们提供了跨度事件和日志事件),因此可以检测跨度序列和日志事件序列中的异常。然而,它们依赖于事件序列滑动窗口中下一个事件的预测,因此没有轨迹及其结构的全局视图。因此,他们很可能将看不见的事件子序列错误地报告为异常。实际上,这种日志异常检测方法通常适用于单个日志事件序列,例如 HDFS 数据集 [38]。因此,它们不能很好地用于涉及并行和异步服务调用中的许多服务实例和分布式日志事件的微服务异常检测。
-
基于 GRU 的 Deep SVDD 比四种基线方法实现了更好的精度和召回率。它考虑了跟踪的所有跨度事件和日志事件,因此比依赖基于滑动窗口的日志分析的日志异常检测方法性能更好。然而,其基于序列的跨度事件和日志事件表示忽略了它们的调用层次结构和并行/异步调用带来的复杂跟踪结构。因此,它的性能不如 DeepTraLog。
-
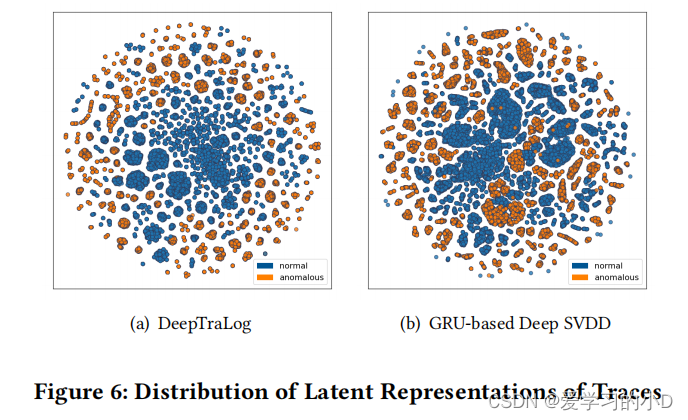
图 6 显示了 Deep TraLog 和基于 GRU 的深度 SVDD 产生的结果的比较。我们使用 t-SNE [36] 通过将它们投影到 2D 空间来可视化测试集中轨迹的潜在表示。可以看出,DeepTraLog 可以学习到一个超球体,它可以更好地包围正常轨迹,并将异常轨迹与正常轨迹区分开来。我们认为改进是由跟踪和日志的统一图形表示带来的。
-
总之,DeepTraLog 在微服务异常检测方面非常有效,并且在准确率和召回率方面分别比现有的基于跟踪和日志的异常检测方法平均高出 64.94% 和 101.59%。统一的图形表示极大地促进了 DeepTraLog 的改进,使其在精度和召回率方面分别优于使用序列表示的 DeepTraLog 变体 7.64% 和 26.03%。
4.3 RQ2:效率
- 使用每种方法,我们使用训练集(包括 65,490 条轨迹)训练异常检测模型,并使用测试集(包括 56,080 条轨迹)测试模型。表 3 显示了每种方法的训练时间和测试时间。这些方法需要 30-816 分钟来训练模型,需要 77-3,136 秒来完成测试。一般来说,除 LogAnomaly 之外的所有方法都是高效的,例如在大约 30-138 分钟内训练模型并在 77-278 秒内完成测试(整个测试集)。 DeepTraLog 比两种基于跟踪的方法(即 TraceAnomaly 和 MultimodalTrace)慢,但在模型训练中比其他方法快得多。它比所有其他测试方法快得多。
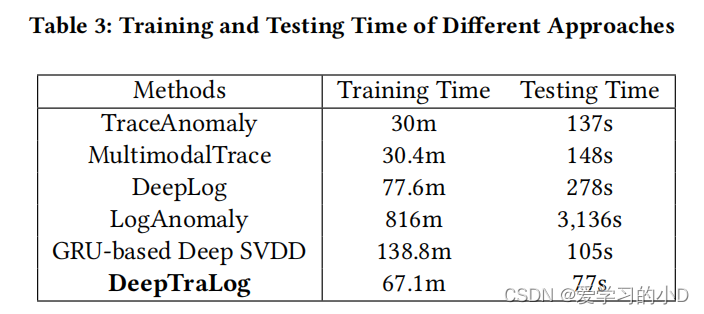
- 两种基于轨迹的方法(即 TraceAnomaly 和 Multi modalTrace)在训练中比 DeepTraLog 快得多,因为它们只考虑轨迹。 DeepTraLog 同时考虑了跟踪和日志,因此在训练中使用了更多时间。然而,DeepTraLog 在测试方面比他们快得多。原因是网络参数 𝜃 完全表征了异常检测模型,并且不需要存储用于异常检测的数据 [30]。
- 两种基于日志的方法(即 DeepLog 和 LogAnomaly)使用滑动窗口来分割事件序列,从而产生大量用于训练和测试的子序列。此外,LogAnomaly 为每个子序列使用一个额外的计数向量序列,计数向量的维度由日志事件的数量决定。公共日志数据集通常包含少量日志事件。例如,HDFS 日志数据集 [38] 仅包含大约 40 个日志事件。相比之下,我们的数据集有超过 800 个日志/跨度事件,导致 LogAnomaly 的维数灾难。微服务系统普遍存在大量日志/跨度事件,传统的日志异常检测方法无法很好地适用于微服务系统。
- 基于 GRU 的 Deep SVDD 使用更简单的序列表示来表示轨迹和日志,但在训练和测试方面都比 DeepTraLog 慢。原因是 GGNNs 将图中的节点(事件)视为网络单元并并行进行消息传递,而 GRU 以很长的序列串行处理每个事件。
- 在线预测的响应时间对于实现及时的异常检测非常重要。它在很大程度上取决于跟踪的大小,即其中的跨度/日志事件的数量。为了通过跟踪大小评估 DeepTraLog 的可扩展性,我们对响应时间随事件数量的增加而变化进行了实验。我们将事件编号 0-900 分为九个范围,例如 0-100、100-200,并针对每个范围随机抽取事件编号在该范围内的 100 条迹线。对于每条轨迹,我们运行异常检测模型 300 次并计算预测的平均响应时间。我们比较了 Deep TraLog 和基于 GRU 的 Deep SVDD 对不同大小痕迹的平均响应时间。图 7 显示了结果。可以看出,两种方法的响应时间都随着迹线的大小线性增加,并且 DeepTraLog 总是比基于 GRU 的 Deep SVDD 更快。
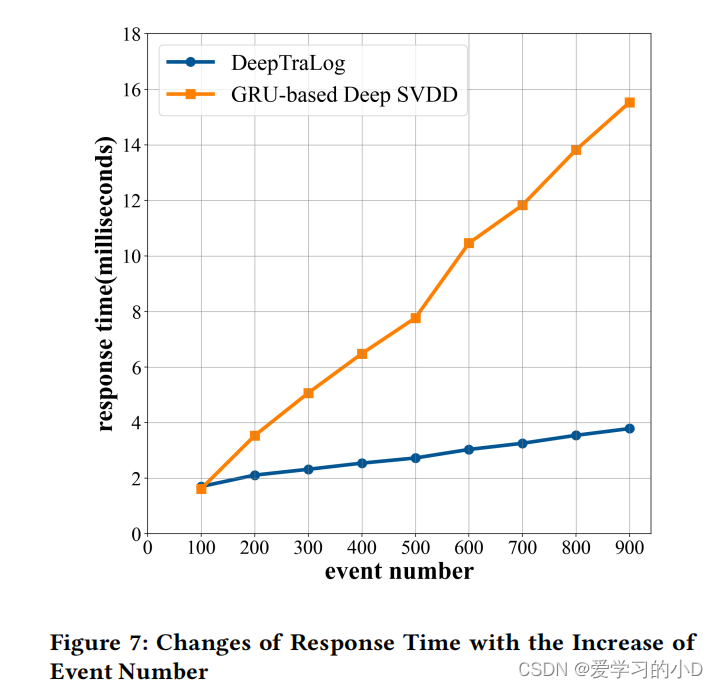
- 总之,DeepTraLog 在训练中比基于跟踪的方法慢 122.19%,比基于日志的方法快 52.65%;在测试中,它比基于跟踪的方法快 45.88%,比基于日志的方法快 84.92%。此外,DeepTraLog 的响应时间随着轨迹的大小线性增加,当轨迹包含 800-900 个事件时,DeepTraLog 花费大约 4 毫秒来进行预测。
4.4 RQ3:配置的影响
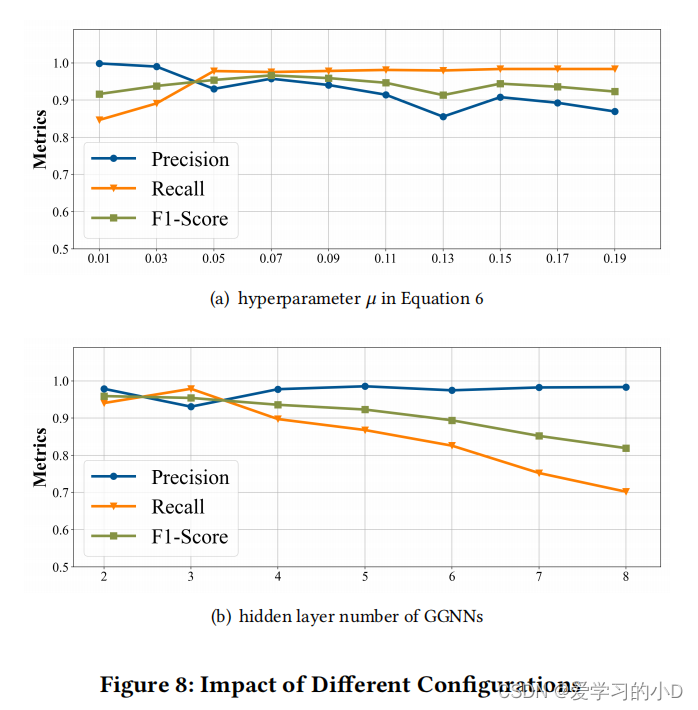
- 损失函数中的超参数𝜇(见公式6)和GGNNs的隐藏层数是基于GGNNs的深度SVDD模型的两个重要参数。如第 3.5 节所述,𝜇 控制超球体体积和违反边界之间的权衡。 GGNN 的隐藏层数决定了 TEG 中节点之间消息传递的迭代次数,因此对 TEG 的潜在表示有很大影响。公式 6 中的正则化参数 𝜆 通常可以根据经验设置(例如,在我们的实现中为 0.001),如之前的工作 [30]。
- 图 8(a) 显示了𝜇 对 DeepTraLog 的精度、召回率和 F1 分数的影响。在深度 SVDD 中,𝜇 通常可以取 0.01 到 0.1 之间的值 [30]。较大的 𝜇 通常会导致较低的精度和较高的召回率,因为它会产生较小的超球体,包含较少的正常轨迹和异常轨迹。根据结果,𝜇 = 0.07 在 F1 分数方面实现了最佳权衡。请注意,𝜇 的最佳配置在很大程度上取决于数据集的特征。通常可以根据对准确率和召回率的偏好来确定。图 8(b) 显示了 GGNN 的隐藏层数的影响。通常设置为二到四。可以看出,recall 和 F1-score 都随着隐藏层数的增加而降低。这通常是因为更多的隐藏层更容易导致过度平滑,这使得特征难以区分,从而损害分类精度[16]。
4.5 对有效性的威胁
- 内部有效性的威胁主要在于基线方法的实施和配置以及数据集生成的过程。我们自己实现了 MultimodalTrace 和 LogAnomaly,因为它们没有公开可用的实现。这两种方法基于标准深度学习(例如 LSTM)和日志事件提取(例如 FT-Tree)组件。我们按照他们的论文并以相同的方式组装组件。关于配置的影响,我们通过实验为所有基线方法选择最佳配置。对于 DeepTraLog,我们通过实验研究了一些关键参数对其有效性的影响并报告了结果。我们数据集中的正常和异常轨迹是通过分别自动执行基准系统的正常和故障版本生成的。因此,正常轨迹可能包含潜在异常。为了减轻威胁,我们在执行前仔细测试了正常版本的涉及场景,并在执行后手动检查一组采样轨迹的质量。
- 对外部效度的威胁主要在于基准体系和故障案例。我们的方法仅在 TrainTicket 及其故障案例上进行评估。目前尚不清楚是否可以有效地用于更复杂的工业微服务系统和故障案例。这些威胁从两个方面得到缓解。首先,我们构建的数据集包含复杂的跟踪信息,包括大约 900 个事件并涉及并行和异步服务调用。通常,工业微服务系统中的跟踪涉及数十个服务调用和数百个日志事件。因此,迹线的大小是可比较的。其次,TrainTicket的故障案例是从工业系统中的真实故障中复制而来的,涵盖了不同类型的典型故障[42]。因此,评估中使用的故障案例具有代表性。
5 相关工作
-
传统的软件异常检测方法主要基于日志 [7、12、18、23、24、37、39、40]。通常日志异常检测包括两个阶段。首先,它通过日志解析从日志消息中提取日志事件。广泛使用的日志解析方法包括 Drain [11] 和 Spell [6]。其次,它对日志事件序列进行异常检测。早期的研究使用数值向量来表示日志序列,通常是通过统计日志序列中各种日志事件的个数来生成日志序列。卢等人。 [23] 提出了一种挖掘日志事件之间不变关系以进行异常检测的方法。许等。 [37] 使用主成分分析 (PCA) 来检测日志异常。林等。 [18] 使用层次聚类技术来识别日志异常和 He 等人。 [12] 通过识别日志和系统指标之间的相关性来扩展他们的工作。
-
最近,有一些使用深度学习来检测日志异常的方法。杜等人。 [7] 提出了一种称为 DeepLog 的日志异常检测方法,它通过使用 LSTM 预测下一个日志事件来检测异常。同样,Meng 等人。 [24] 提出了一种称为 LogAnomaly 的日志异常检测方法。它结合了词嵌入产生的语义向量和数字向量,使用 LSTM 预测下一个日志事件。张等。 [40] 还使用语义向量来表示日志事件,并使用 BiLSTM 以监督的方式检测整个日志序列的异常。杨等。 [39] 将 [40] 扩展到半监督方法,该方法使用 PU 学习估计日志序列的标签。这些日志异常检测方法基于日志事件的序列表示,因此不能很好地检测涉及复杂结构的异常痕迹。
-
在微服务系统中,跟踪被广泛用于异常检测和根本原因分析 [10、19、20、25、26、28]。传统方法 [10, 42] 依靠痕迹的可视化来支持手动痕迹分析。周等。 [42] 对微服务故障分析和调试的工业实践进行了实证研究,并提出了一种改进的跟踪可视化方法。郭等。 [10] 提出了一种使用跟踪聚合和可视化来帮助分析错误传播链的方法。
-
最近,一些研究人员提出了用于跟踪异常检测的自动化方法。周等。 [43] 提出了一种基于从痕迹中提取的一组特征来检测异常痕迹的监督方法。它依靠故障注入产生大量用于训练的正常和异常轨迹以及从不同方面提取的一组预定义轨迹特征。其他方法通过从正常执行产生的痕迹中学习模式来检测各种类型的异常 [20、25、26]。内德尔科斯基等人。 [25] 通过训练自动编码变分贝叶斯模型来检测微服务系统中的响应时间异常。内德尔科斯基等人。 [26] 将每个轨迹表示为一个跨度序列和一个响应时间序列,并设计一个多模态 LSTM 模型来检测异常轨迹。刘等人。 [20] 使用服务跟踪向量来表示每个跟踪,它将每个可能的路径视为向量中的一个维度。这些跟踪异常检测方法不考虑日志。此外,它们通常将迹线表示为序列,而没有考虑迹线的复杂结构。
6 结论
- 在本文中,我们提出了 DeepTraLog,这是一种基于深度学习的微服务异常检测方法。它使用统一的图形表示来描述跟踪的复杂结构以及嵌入结构中的日志事件。基于表示,我们设计了一个基于 GGNN 的深度 SVDD 模型,它可以学习每个轨迹的潜在表示和最小化的数据封闭超球体。我们使用该模型通过计算它们到超球体中心的距离来检测异常痕迹。我们已经在微服务基准测试中评估了 DeepTraLog。结果表明,DeepTraLog 明显优于最先进的跟踪/日志异常检测方法。我们未来的工作将扩展 DeepTraLog 以支持更多不同类型的微服务系统异常,例如响应时间异常,另一方面评估 DeepTraLog 与不同类型的微服务系统。 7 数据可用性 所有数据和工作结果都可以在我们的复制包中找到 [5]

















 9228
9228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









