







机器学习大框架
-
导入库:引入如
pandas(数据处理)、numpy(数值计算)、matplotlib或seaborn(数据可视化)以及scikit - learn(机器学习算法实现)等库,为后续操作提供工具。 -
读取数据查看数据信息 :在对数据处理前,读取数据并了解其结构(列名、形状)、数据类型、统计特性(均值、最值等),可以把握数据全貌,发现潜在问题,指导后续处理方向。
import pandas as pd import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns # 设置中文字体(解决中文显示问题)-Windows系统常用黑体字体 plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示负号 plt.rcParams['axes.unicode_minus'] = False data = pd.read_csv('data.csv') data.info() print(data.head()) -
缺失值处理:数据收集过程中常出现缺失值,若不处理会影响模型精度。处理方式有删除缺失严重的数据、用统计量(均值、中位数、众数)填充,或基于模型预测填充。
# 简单筛选数值型作为连续特征,把筛选出来的列名转换成列表 continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() # 连续特征用中位数补全 for feature in continuous_features: median_value = data[feature].median() data[feature].fillna(median_value, inplace=True) -
数据类型转换:将非数值类型转换为数值类型,方便后续的计算和模型处理。
# 先筛选字符串变量 discrete_features = data.select_dtypes(include=['object']).columns.tolist() discrete_features # 依次查看列值的类别计数,确定编码方式 for feature in discrete_features: print(f"\n{feature}的唯一值:") print(data[feature].value_counts()) -
异常值处理:异常值可能因测量误差或真实极端情况产生,会干扰模型训练。通过箱线图、Z - score 等方法识别后,可选择删除、修正或特殊编码处理。
-
离散特征处理:对于类别型离散变量,常需编码成数值形式,如独热编码(One - Hot Encoding);对于有序离散变量,可采用标签编码,使模型能够理解和利用这些特征。
# Home Ownership 标签编码 home_ownership_mapping = { 'Own Home': 1, 'Rent': 2, 'Have Mortgage': 3, 'Home Mortgage': 4 } data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping) # Years in current job 标签编码 years_in_job_mapping = { '< 1 year': 1, '1 year': 2, '2 years': 3, '3 years': 4, '4 years': 5, '5 years': 6, '6 years': 7, '7 years': 8, '8 years': 9, '9 years': 10, '10+ years': 11 } data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping) # Purpose 独热编码 data = pd.get_dummies(data, columns=['Purpose']) # 重新读取数据,用来做列名对比 data2 = pd.read_csv("data.csv") # 新建一个空列表,用于存放独热编码后新增的特征名 list_final = [] # 这里打印出来的就是独热编码后的特征名 for i in data.columns: if i not in data2.columns: list_final.append(i) # 这里的i就是独热编码后的特征名,将bool类型转换为数值 for i in list_final: data[i] = data[i].astype(int) # Term 0 - 1 映射 term_mapping = { 'Short Term': 0, 'Long Term': 1 } data['Term'] = data['Term'].map(term_mapping) # 重命名列 data.rename(columns={'Term': 'Long Term'}, inplace=True) -
删除无用列:数据中可能存在与目标变量无关、含大量缺失值或几乎无变化的列,删除它们可减少噪声,提升训练效率和模型性能。
-
划分数据集:为评估模型泛化能力,通常将数据分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调参,测试集用于最终评估模型性能。划分时要保证各子集数据分布相似。
# train_test_split 函数专门用于将数据集划分为训练集和测试集 from sklearn.model_selection import train_test_split # axis = 1 表示按列进行操作,axis = 0 则表示按行操作。 # 这里删除 'Credit Default' 列,即得到了所有特征变量 X = data.drop(['Credit Default'], axis=1) # 标签 y = data['Credit Default'] # 划分数据集,20%作为测试集。随机种子为42,确保每次划分结果相同 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 确认数据划分是否符合预期,并了解每个数据集的规模 print(f"训练集形状: {X_train.shape}, 测试集形状: {X_test.shape}") # 输出:训练集形状: (6000, 31), 测试集形状: (1500, 31) -
特征工程:此步骤通过对现有特征变换(标准化、归一化)、组合(特征交叉)或基于业务知识创造新特征,能显著提升模型表现。但要注意避免在划分数据集后进行可能导致数据泄露的特征工程操作,比如基于测试集数据创建新特征或填补缺失值。
准备工作:安装库(在 Anaconda Prompt 中)与导入库(注意内核环境)
# #安装xgboost库 # !pip install xgboost -i https://pypi.tuna.tsinghua.edu.cn/simple/ # #安装lightgbm库 # !pip install lightgbm -i https://pypi.tuna.tsinghua.edu.cn/simple/ # #安装catboost库 # !pip install catboost -i https://pypi.tuna.tsinghua.edu.cn/simple/# 支持向量机分类器 from sklearn.svm import SVC # K近邻分类器 from sklearn.neighbors import KNeighborsClassifier # 逻辑回归分类器 from sklearn.linear_model import LogisticRegression # XGBoost分类器 import xgboost as xgb # LightGBM分类器 import lightgbm as lgb # 随机森林分类器 from sklearn.ensemble import RandomForestClassifier # CatBoost分类器 from catboost import CatBoostClassifier # 决策树分类器 from sklearn.tree import DecisionTreeClassifier # 高斯朴素贝叶斯分类器 from sklearn.naive_bayes import GaussianNB # 用于评估分类器性能的指标 from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于生成分类报告和混淆矩阵 from sklearn.metrics import classification_report, confusion_matrix # 用于忽略警告信息 import warnings # 忽略所有警告信息 warnings.filterwarnings("ignore") -
模型训练:依据问题类型(回归、分类、聚类等)选择合适模型,如线性回归、决策树、支持向量机等,利用训练集数据训练模型,确定模型参数。
-
模型评估:使用验证集或测试集数据及相应评估指标(分类用准确率、精确率、召回率、F1 值等;回归用均方误差、平均绝对误差等)评估模型性能,判断模型是否符合预期。
# SVM # 模型实例化 svm_model = SVC(random_state=42) # 模型训练 svm_model.fit(X_train, y_train) # 模型预测 svm_pred = svm_model.predict(X_test) print("SVM 分类报告:") print(classification_report(y_test, svm_pred)) print("SVM 混淆矩阵:") print(confusion_matrix(y_test, svm_pred)) # 计算 SVM 评估指标,这些指标默认计算正类的性能 svm_accuracy = accuracy_score(y_test, svm_pred) svm_precision = precision_score(y_test, svm_pred) svm_recall = recall_score(y_test, svm_pred) svm_f1 = f1_score(y_test, svm_pred) print("SVM 模型评估指标:") print(f"准确率: {svm_accuracy:.4f}") print(f"精确率: {svm_precision:.4f}") print(f"召回率: {svm_recall:.4f}") print(f"F1 值: {svm_f1:.4f}")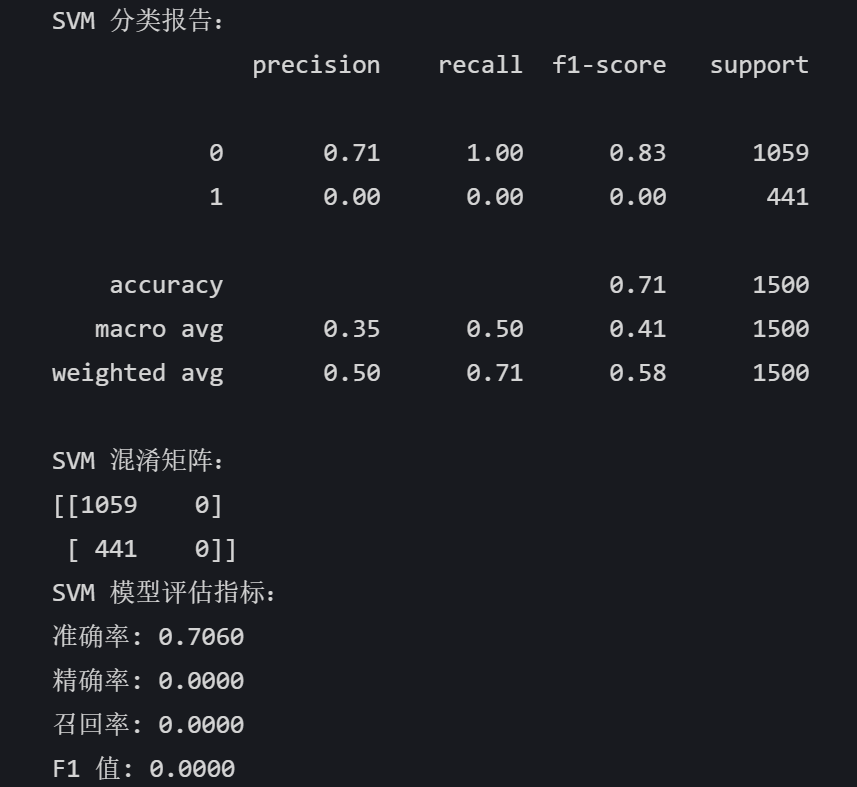
# KNN knn_model = KNeighborsClassifier() knn_model.fit(X_train, y_train) knn_pred = knn_model.predict(X_test) print("KNN 分类报告:") print(classification_report(y_test, knn_pred)) print("KNN 混淆矩阵:") print(confusion_matrix(y_test, knn_pred)) knn_accuracy = accuracy_score(y_test, knn_pred) knn_precision = precision_score(y_test, knn_pred) knn_recall = recall_score(y_test, knn_pred) knn_f1 = f1_score(y_test, knn_pred) print("KNN 模型评估指标:") print(f"准确率: {knn_accuracy:.4f}") print(f"精确率: {knn_precision:.4f}") print(f"召回率: {knn_recall:.4f}") print(f"F1 值: {knn_f1:.4f}")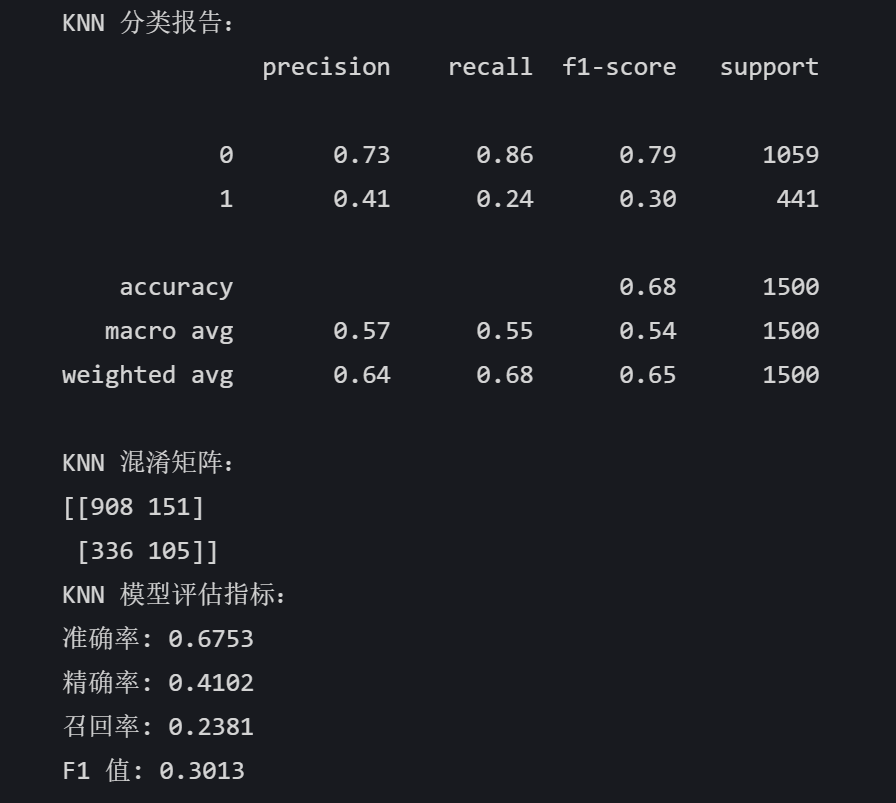
# 逻辑回归 logreg_model = LogisticRegression(random_state=42) logreg_model.fit(X_train, y_train) logreg_pred = logreg_model.predict(X_test) print("逻辑回归 分类报告:") print(classification_report(y_test, logreg_pred)) print("逻辑回归 混淆矩阵:") print(confusion_matrix(y_test, logreg_pred)) logreg_accuracy = accuracy_score(y_test, logreg_pred) logreg_precision = precision_score(y_test, logreg_pred) logreg_recall = recall_score(y_test, logreg_pred) logreg_f1 = f1_score(y_test, logreg_pred) print("逻辑回归 模型评估指标:") print(f"准确率: {logreg_accuracy:.4f}") print(f"精确率: {logreg_precision:.4f}") print(f"召回率: {logreg_recall:.4f}") print(f"F1 值: {logreg_f1:.4f}")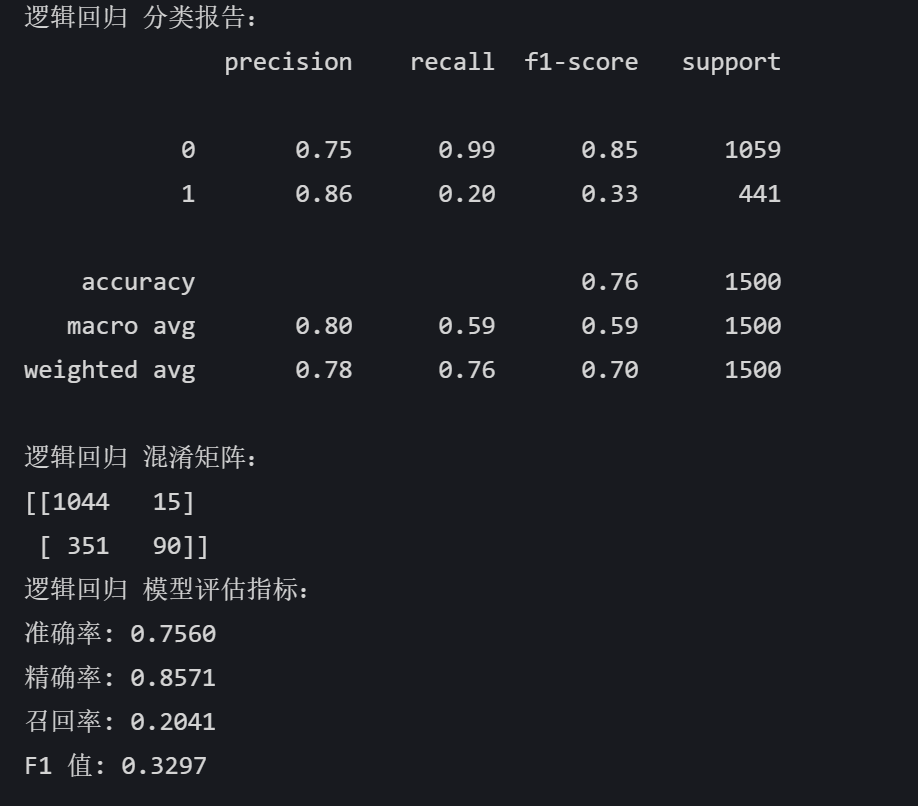
# 朴素贝叶斯 nb_model = GaussianNB() nb_model.fit(X_train, y_train) nb_pred = nb_model.predict(X_test) print("朴素贝叶斯 分类报告:") print(classification_report(y_test, nb_pred)) print("朴素贝叶斯 混淆矩阵:") print(confusion_matrix(y_test, nb_pred)) nb_accuracy = accuracy_score(y_test, nb_pred) nb_precision = precision_score(y_test, nb_pred) nb_recall = recall_score(y_test, nb_pred) nb_f1 = f1_score(y_test, nb_pred) print("朴素贝叶斯 模型评估指标:") print(f"准确率: {nb_accuracy:.4f}") print(f"精确率: {nb_precision:.4f}") print(f"召回率: {nb_recall:.4f}") print(f"F1 值: {nb_f1:.4f}")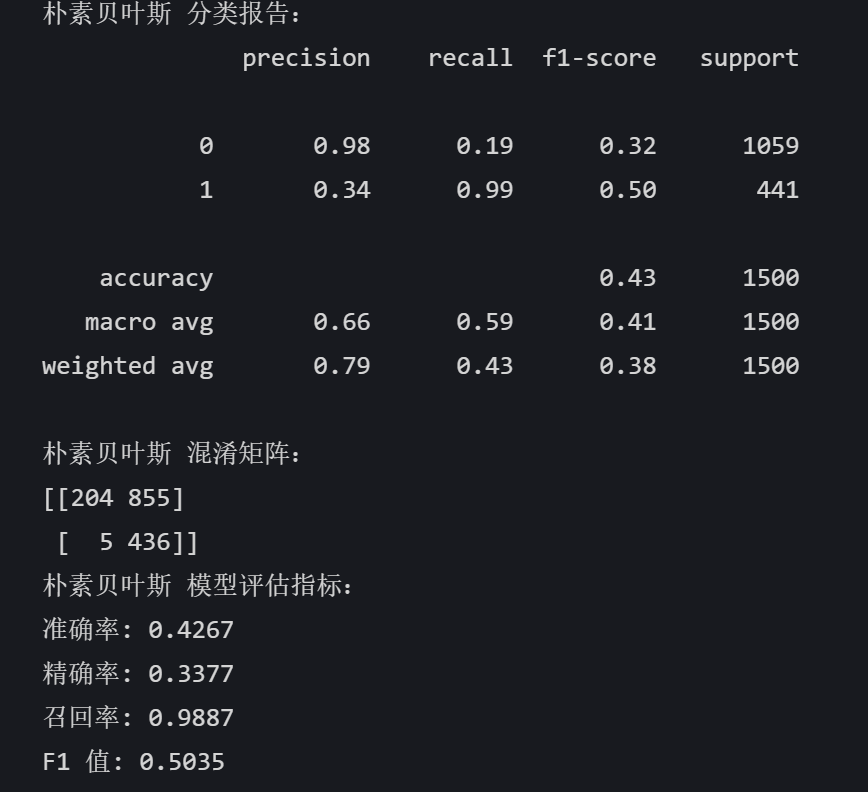
# 决策树 dt_model = DecisionTreeClassifier(random_state=42) dt_model.fit(X_train, y_train) dt_pred = dt_model.predict(X_test) print("决策树 分类报告:") print(classification_report(y_test, dt_pred)) print("决策树 混淆矩阵:") print(confusion_matrix(y_test, dt_pred)) dt_accuracy = accuracy_score(y_test, dt_pred) dt_precision = precision_score(y_test, dt_pred) dt_recall = recall_score(y_test, dt_pred) dt_f1 = f1_score(y_test, dt_pred) print("决策树 模型评估指标:") print(f"准确率: {dt_accuracy:.4f}") print(f"精确率: {dt_precision:.4f}") print(f"召回率: {dt_recall:.4f}") print(f"F1 值: {dt_f1:.4f}")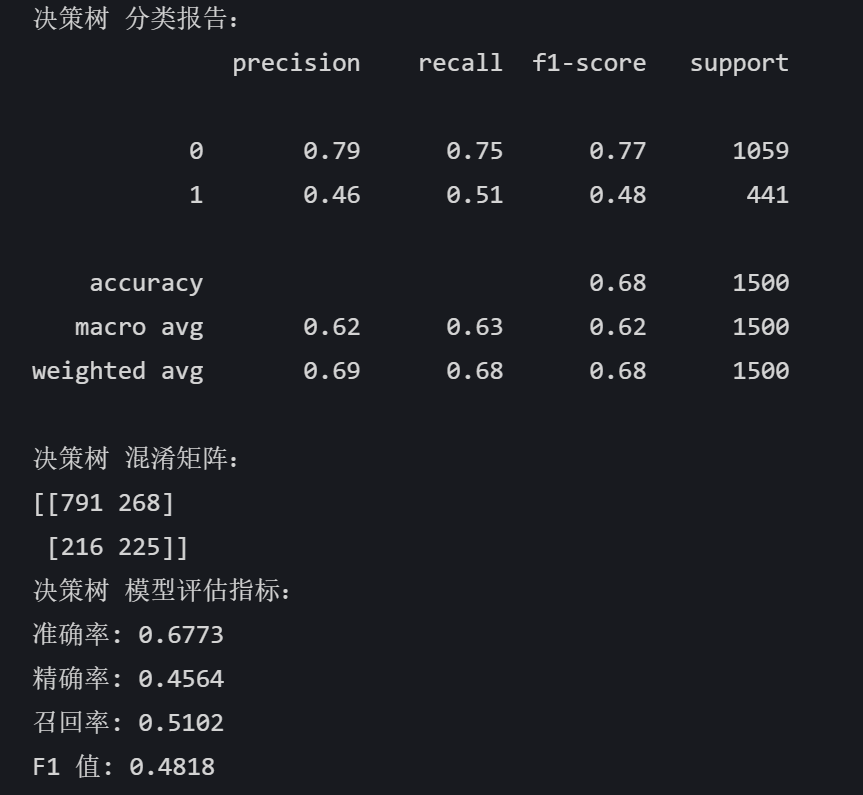
# 随机森林 rf_model = RandomForestClassifier(random_state=42) rf_model.fit(X_train, y_train) rf_pred = rf_model.predict(X_test) print("随机森林 分类报告:") print(classification_report(y_test, rf_pred)) print("随机森林 混淆矩阵:") print(confusion_matrix(y_test, rf_pred)) rf_accuracy = accuracy_score(y_test, rf_pred) rf_precision = precision_score(y_test, rf_pred) rf_recall = recall_score(y_test, rf_pred) rf_f1 = f1_score(y_test, rf_pred) print("随机森林 模型评估指标:") print(f"准确率: {rf_accuracy:.4f}") print(f"精确率: {rf_precision:.4f}") print(f"召回率: {rf_recall:.4f}") print(f"F1 值: {rf_f1:.4f}")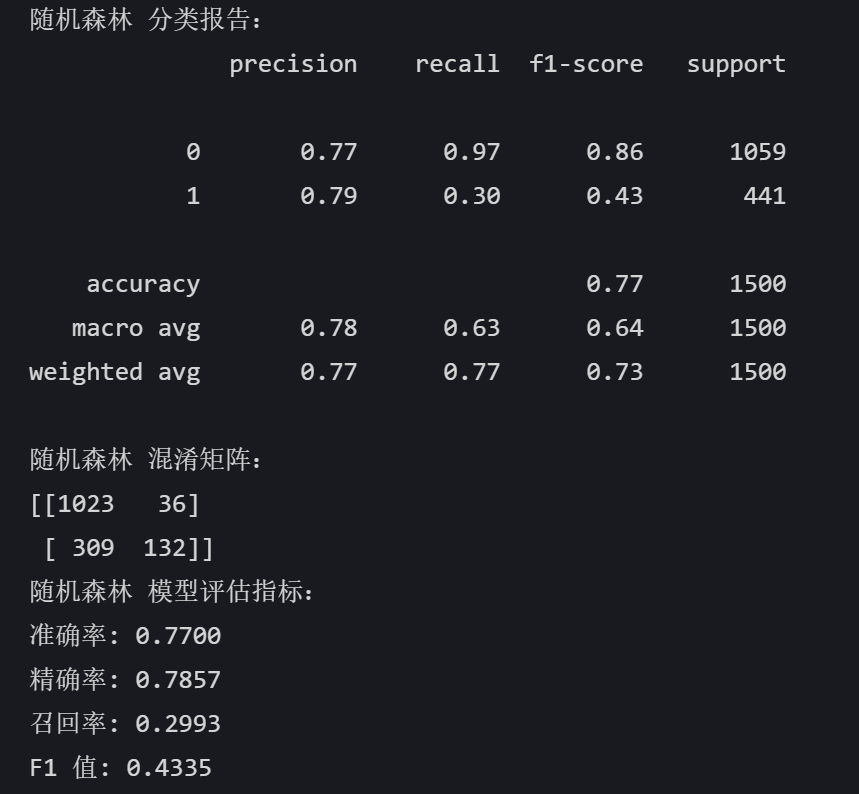
# XGBoost xgb_model = xgb.XGBClassifier(random_state=42) xgb_model.fit(X_train, y_train) xgb_pred = xgb_model.predict(X_test) print("XGBoost 分类报告:") print(classification_report(y_test, xgb_pred)) print("XGBoost 混淆矩阵:") print(confusion_matrix(y_test, xgb_pred)) xgb_accuracy = accuracy_score(y_test, xgb_pred) xgb_precision = precision_score(y_test, xgb_pred) xgb_recall = recall_score(y_test, xgb_pred) xgb_f1 = f1_score(y_test, xgb_pred) print("XGBoost 模型评估指标:") print(f"准确率: {xgb_accuracy:.4f}") print(f"精确率: {xgb_precision:.4f}") print(f"召回率: {xgb_recall:.4f}") print(f"F1 值: {xgb_f1:.4f}")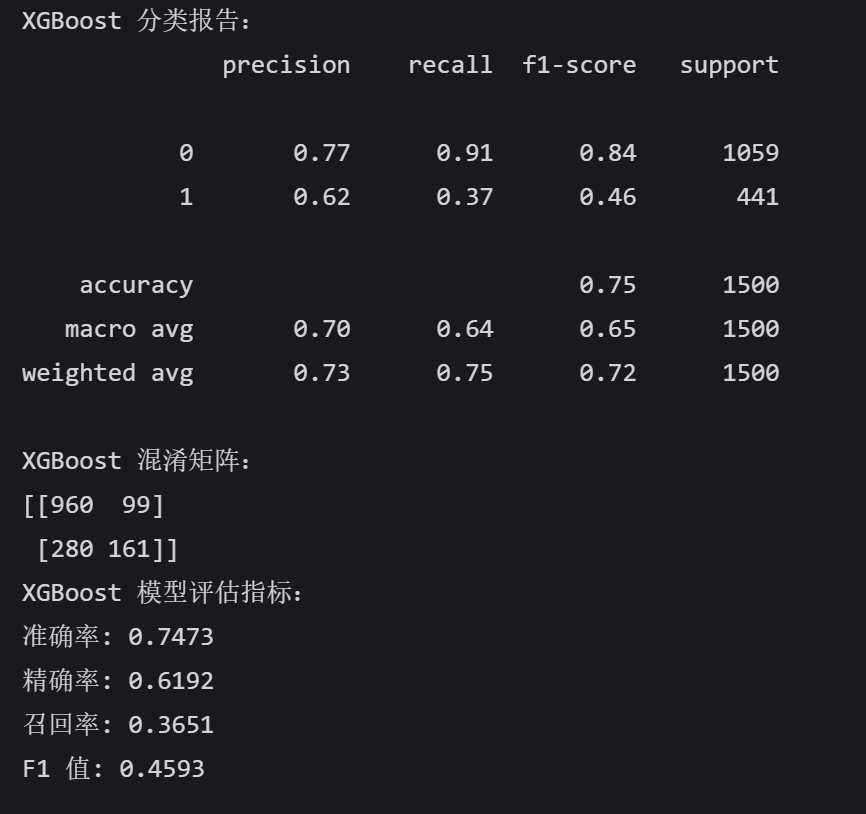
# LightGBM lgb_model = lgb.LGBMClassifier(random_state=42) lgb_model.fit(X_train, y_train) lgb_pred = lgb_model.predict(X_test) print("LightGBM 分类报告:") print(classification_report(y_test, lgb_pred)) print("LightGBM 混淆矩阵:") print(confusion_matrix(y_test, lgb_pred)) lgb_accuracy = accuracy_score(y_test, lgb_pred) lgb_precision = precision_score(y_test, lgb_pred) lgb_recall = recall_score(y_test, lgb_pred) lgb_f1 = f1_score(y_test, lgb_pred) print("LightGBM 模型评估指标:") print(f"准确率: {lgb_accuracy:.4f}") print(f"精确率: {lgb_precision:.4f}") print(f"召回率: {lgb_recall:.4f}") print(f"F1 值: {lgb_f1:.4f}")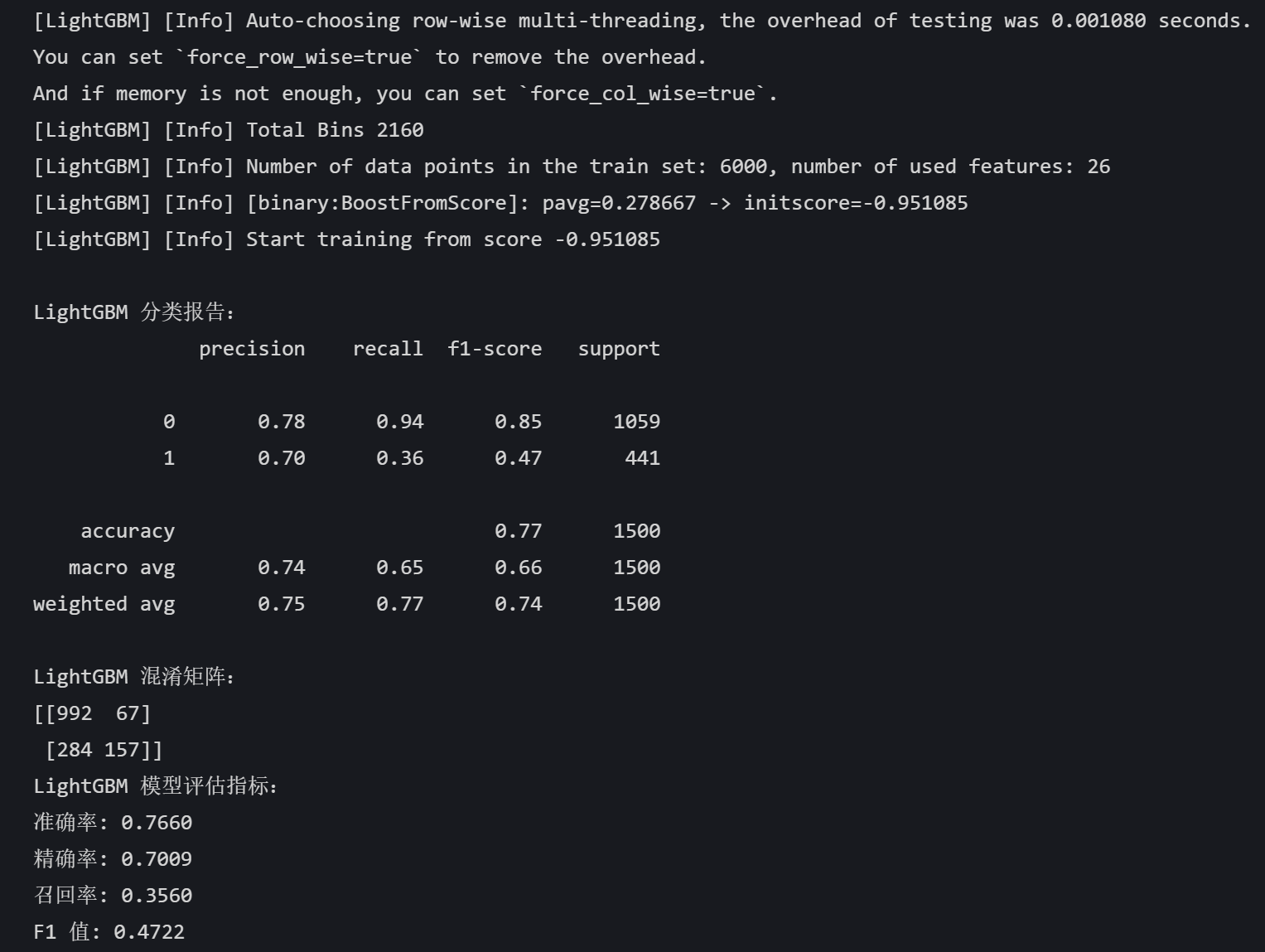
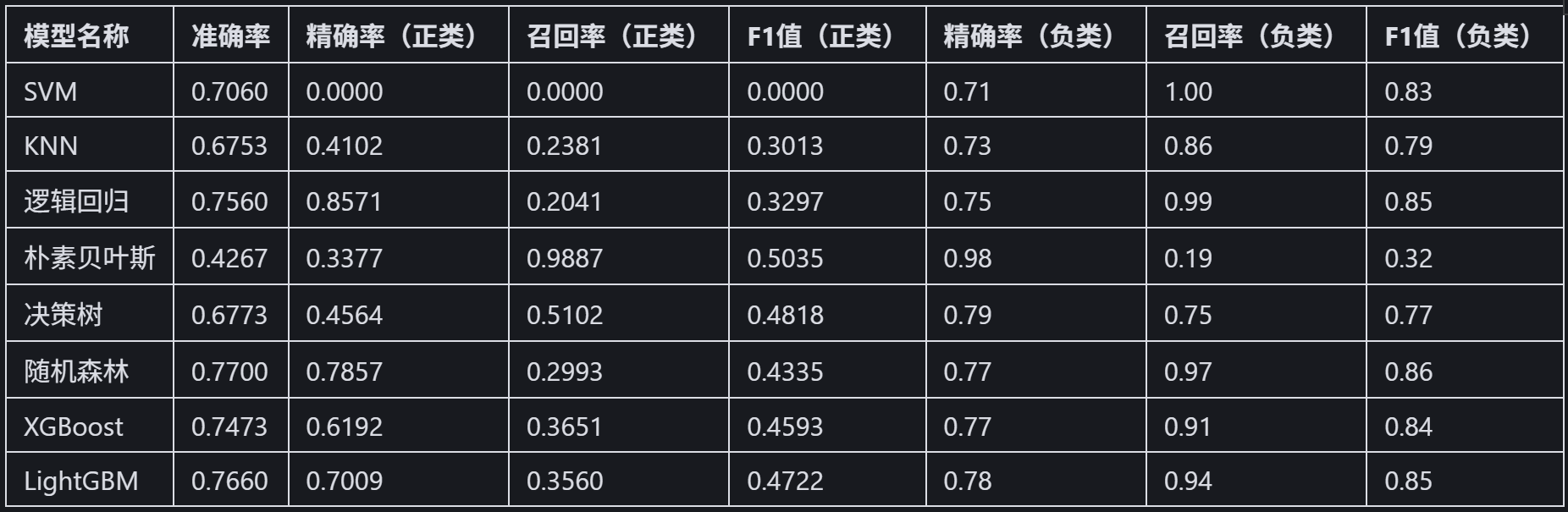




可以用下面代码输出对比表格: import pandas as pd # 定义数据 data = { '模型名称': ['SVM', 'KNN', '逻辑回归', '朴素贝叶斯', '决策树', '随机森林', 'XGBoost', 'LightGBM'], '准确率': [0.7060, 0.6753, 0.7560, 0.4267, 0.6773, 0.7700, 0.7473, 0.7660], '精确率(正类)': [0.0000, 0.4102, 0.8571, 0.3377, 0.4564, 0.7857, 0.6192, 0.7009] } # 创建 DataFrame df = pd.DataFrame(data) # 设置表格样式,添加框线 styled_df = df.style.set_table_styles([{ 'selector': 'th', 'props': [('border', '1px solid black')] }, { 'selector': 'td', 'props': [('border', '1px solid black')] }]) -
模型保存:将性能满意的模型保存,常用格式如
pickle(Python)或joblib,便于在实际应用中直接加载,避免重复训练。 -
模型预测:加载保存的模型对新数据预测,输出结果解决实际问题。
一些知识点
一、三行经典代码:
1. 模型实例化
2. 模型训练(代入训练集)
3. 模型预测 (代入测试集)
xxx_model = xxx(random_state=42)
xxx_model.fit(X_train, y_train)
xxx_pred = xxx_model.predict(X_test)二、为什么有的模型需要设定随机种子?
许多模型在训练过程中涉及到随机初始化或随机采样的步骤。例如:在神经网络中,权重通常是随机初始化的;在随机森林模型里,每次构建决策树时,样本的采样以及特征的选择也具有随机性;K - 均值聚类算法中,初始聚类中心的选择也是随机的。如果不设定随机种子,每次运行模型时,这些随机因素会导致模型的训练结果不同。设定随机种子可以固定这些随机过程,使得每次运行代码时,模型的初始化和随机操作都以相同的方式进行,从而保证实验的可重复性。这样在比较不同模型或者同一模型不同参数设置的性能时,结果更具可靠性。
朴素贝叶斯模型是基于贝叶斯定理和特征条件独立假设的分类方法。它的训练过程主要是计算各类别出现的概率以及在每个类别下各个特征出现的条件概率。这些计算不涉及随机初始化或随机采样步骤。给定相同的训练数据,朴素贝叶斯模型每次训练得到的参数(即各类别和特征的概率)都是相同的,所以不需要通过设定随机种子来保证可重复性。
三、评估指标
基于混淆矩阵,计算得到的准确率、召回率、F1值,这些都是固定阈值的评估指标。而AUC是基于不同阈值得到不同的混淆矩阵,然后计算每个阈值对应的FPR和TPR,将这些点连成线,最后求曲线下的面积,得到AUC值。
1、分类问题:
硬分类:将每个数据样本明确地划分到某一个类别中 。也就是说,对于一个给定的数据点,模型会做出一个确定性的决策,判断它只属于某一类,不存在模棱两可的情况。
软分类:并不把样本严格地划分到某一类,而是给出样本属于每个类别的概率或可能性,在一些对风险评估、决策支持要求较高的场景非常有用。
流程:训练逻辑回归模型→获取测试集的概率预测→尝试不同的阈值(一个数值标准,用于将样本不同预测概率结果划分至某个类别)→根据阈值进行分类
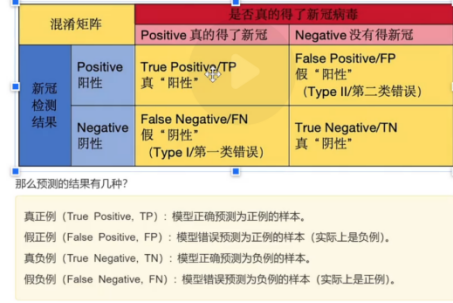
2、混淆矩阵:
二分类样本将答案转化为混淆矩阵(confusion Matrix),横轴为真实结果,竖轴为预测结果。

3、精确率:
模型预测为正例的样本中实际为正例的比例,关注是否有误报的情况(对号入座,严格)
4、召回率:
实际为正例的样本中,被模型正确预测为正例的比例,关注是否有漏报的情况(宁可错杀一千,不可放过一个)
5、F1分数:
精确率与召回率的调和平均数,取值范围0~1,越接近1,说明模型预测效果越好。
6、ROC曲线:
以 FPR(假阳性率,等于1-特异率) 为横轴,TPR (真阳性率,即召回率)为纵轴,对于不同阈值下计算得到的每一对(FPR, TPR)值,在坐标平面上绘制出相应的点,然后将这些点连接起来就得到了 ROC 曲线。AUC(Area Under Curve,ROC 曲线下的面积)常被用来量化模型综合性能,AUC 值越接近1,模型性能越好。
绘制步骤:收集数据→计算预测概率→设置阈值(将概率值转化为二分类预测结果:predict_proba函数与argmax函数)→计算TPR与FPR→绘制ROC曲线。

















 2044
2044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









