







一、什么是奇异值



二、核心思想:

三、奇异值的主要应用
1、降维:

2、数据压缩:
原理:图像可以表示为一个矩阵,矩阵的元素对应图像的像素值。对这个图像矩阵进行 SVD 分解后,小的奇异值对图像的主要结构贡献很小,它们往往对应于图像中的细节和噪声。通过丢弃这些小的奇异值,只保留较大的奇异值及其对应的列向量,再用保留的部分重建图像矩阵,就可以在尽量保持图像主要内容的同时,大幅减少存储图像所需的数据量。
3、去噪:
在很多实际数据中,噪声往往表现为在各个方向上的微小干扰,反映在奇异值上就是一些较小的奇异值。通过丢弃这些小的奇异值及其对应的奇异向量,然后用剩下的较大奇异值部分重建数据矩阵,就可以有效地去除噪声,提高数据的质量。
4、推荐系统:
在推荐系统中,用户-物品评分矩阵通常存在很多缺失值,对评分矩阵R进行SVD分解后,保留前k个较大的奇异值及其对应的U、V的部分列向量,构建低秩矩阵来近似R。这样就可以利用已知的评分来预测缺失的评分值,从而为用户推荐可能感兴趣的内容。
四、矩阵代码实例
import numpy as np
# 创建一个矩阵 A (5x3)
A = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12],
[13, 14, 15]])
print("原始矩阵 A:")
print(A)
# 进行 SVD 分解
# full_matrices=False表示不计算完整的 U 和 V 矩阵,而是计算经济规模的分解,用于降维场景
U, sigma, Vt = np.linalg.svd(A, full_matrices=False)
print("\n奇异值 sigma:")
print(sigma)
# 分别保留前 k 个奇异值进行降维
for k in [1, 2, 3]:
U_k = U[:, :k] # 取 U 的前 k 列,因为要保持行数不变
sigma_k = sigma[:k] # 取前 k 个奇异值
Vt_k = Vt[:k, :] # 取 Vt 的前 k 行,因为要保持列数不变
# 近似重构矩阵 A,p.diag() 将 sigma_k 转换为对角矩阵。@ 运算符表示矩阵乘法。
A_approx = U_k @ np.diag(sigma_k) @ Vt_k
# 近似误差等于差异程度的弗罗贝尼乌斯范数(fro 值)占原始矩阵fro值的比例。
error = np.linalg.norm(A - A_approx, 'fro') / np.linalg.norm(A, 'fro')
print(f"k={k} 时的近似误差: {error:.6f}")

k=1 时:原始3维列空间降为1维,使用U的第1列和Vt的第1行,结合第一个奇异值,重新拟合原矩阵,近似误差仅为4.19%。
k=2 时:原始3维列空间降为2维,使用U的前2列Vt的前2行,结合前两个奇异值,重新拟合原矩阵,此时已完全重构原始矩阵(误差为0)。
k=3 时:使用全部3个左/右奇异向量,但第三个奇异值为0,没有额外价值。

想象一个三维数据点云,SVD 分解会找到三个正交方向:
- 第一个方向(对应最大奇异值):数据方差最大的方向,即数据点最 “伸展” 的方向。
- 第二个方向(次大奇异值):与第一个方向正交且方差次大的方向。
- 第三个方向(最小奇异值):与前两个方向正交且方差最小的方向。
当用 k=1 降维时,相当于将数据投影到第一个方向上,保留最主要的特征。如果选择第三个方向(最小奇异值),则会丢失所有重要信息。
五、机器学习代码实例
1、如何确保测试集和训练集降维到同 k 个特征空间?
训练集和测试集需经过相同变换来保证数据分布一致,这是确保模型评估和泛化有效性的关键。
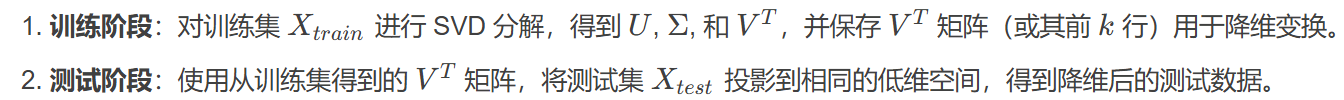
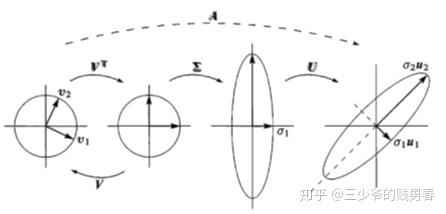

任何线性变换(如矩阵乘法)都可以分解为旋转 → 缩放 → 再旋转三个步骤。
为什么使用右奇异向量而不是左奇异向量?


2、代码实例
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 设置随机种子以便结果可重复
np.random.seed(42)
# 模拟数据:1000 个样本,50 个特征
n_samples = 1000
n_features = 50
# 随机生成特征数据,并改变数据尺度,使范围大致在均值 0 附近,标准差变为 10
X = np.random.randn(n_samples, n_features) * 10
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 模拟二分类标签
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")
# 对训练集进行 SVD 分解
U_train, sigma_train, Vt_train = np.linalg.svd(X_train, full_matrices=False)
print(f"Vt_train 矩阵形状: {Vt_train.shape}")
# 选择保留的奇异值数量 k
k = 10
Vt_k = Vt_train[:k, :] # 保留前 k 行,形状为 (k, 50)
print(f"保留 k={k} 后的 Vt_k 矩阵形状: {Vt_k.shape}")
# 降维训练集:X_train_reduced = X_train @ Vt_k.T
X_train_reduced = X_train @ Vt_k.T
print(f"降维后训练集形状: {X_train_reduced.shape}")
# 使用相同的 Vt_k 对测试集进行降维:X_test_reduced = X_test @ Vt_k.T
X_test_reduced = X_test @ Vt_k.T
print(f"降维后测试集形状: {X_test_reduced.shape}")
# 训练模型(以逻辑回归为例)
model = LogisticRegression(random_state=42)
model.fit(X_train_reduced, y_train)
# 预测并评估
y_pred = model.predict(X_test_reduced)
accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率: {accuracy}")
# 计算训练集的近似误差(可选,仅用于评估降维效果)
X_train_approx = U_train[:, :k] @ np.diag(sigma_train[:k]) @ Vt_k
error = np.linalg.norm(X_train - X_train_approx, 'fro') / np.linalg.norm(X_train, 'fro')
print(f"训练集近似误差 (Frobenius 范数相对误差): {error}")
六、注意的问题
1、标准化数据
不同特征可能具有不同的量纲(比如一个特征表示年龄,范围可能是 0 - 100,另一个特征表示收入,可能是 0 - 1000000),如果不进行标准化,具有较大数值范围的特征可能会在 SVD 计算中占据主导地位,从而影响降维结果。
标准化可以将所有特征转化到相同的尺度,使得每个特征对降维的贡献更加公平。可以使用 sklearn.preprocessing.StandardScaler。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
对测试集 X_test调用transform方法,使用在训练集上计算得到的均值和方差对测试集数据进行标准化。不能在测试集上使用fit_transform,否则会导致数据泄漏,会使模型评估结果过于乐观。
2、选择合适的 k
可以通过累计方差贡献率(explained variance ratio)选择 k ,通常选择解释 90%-95% 方差的 k 值,它可以帮助我们确定保留多少个奇异值能够解释大部分的数据方差。
# 表示前k个奇异值所解释的方差(奇异值平方的累积和)占总方差的比例。
explained_variance_ratio = np.cumsum(sigma_train**2) / np.sum(sigma_train**2)
print(f"前 {k} 个奇异值的累计方差贡献率: {explained_variance_ratio[k-1]}")
3、使用 sklearn 的 TruncatedSVD
对于大规模数据,完整的 SVD 计算可能非常耗时且占用大量内存。TruncatedSVD类专门用于高效降维,它直接计算前k个奇异值和向量,避免了完整 SVD 的计算开销,提高了计算效率。
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=k, random_state=42)
X_train_reduced = svd.fit_transform(X_train)
X_test_reduced = svd.transform(X_test)
print(f"累计方差贡献率: {sum(svd.explained_variance_ratio_)}")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









