







特征降维是指在数据分析和机器学习中,通过特定方法减少数据集中特征数量的过程 。但这个过程不是简单地删除特征,而是在尽量保留数据关键信息和原有结构的前提下,将高维数据转换为低维数据。
降维后计算量会随之减少,还可以去除冗余和噪声特征,避免过拟合。在高维数据降维之后,人们可以直观地观察数据的分布、聚类等特征,了解哪些原始特征对数据的变化影响较大,发现数据中的潜在模式和规律。
特征降维一般有2种策略:特征筛选(从n个特征中筛选出m个特征)和特征组合(从n个特征中组合出m个特征,如pca)
先运行之前的代码:
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('data.csv') #读取数据
# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {
'Own Home': 1,
'Rent': 2,
'Have Mortgage': 3,
'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)
# Years in current job 标签编码
years_in_job_mapping = {
'< 1 year': 1,
'1 year': 2,
'2 years': 3,
'3 years': 4,
'4 years': 5,
'5 years': 6,
'6 years': 7,
'7 years': 8,
'8 years': 9,
'9 years': 10,
'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)
# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:
if i not in data2.columns:
list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:
data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名
# Term 0 - 1 映射
term_mapping = {
'Short Term': 0,
'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表
# 连续特征用中位数补全
for feature in continuous_features:
mode_value = data[feature].mode()[0] #获取该列的众数。
data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。
# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多
# 所以这里我们还是只划分一次数据集
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# # 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))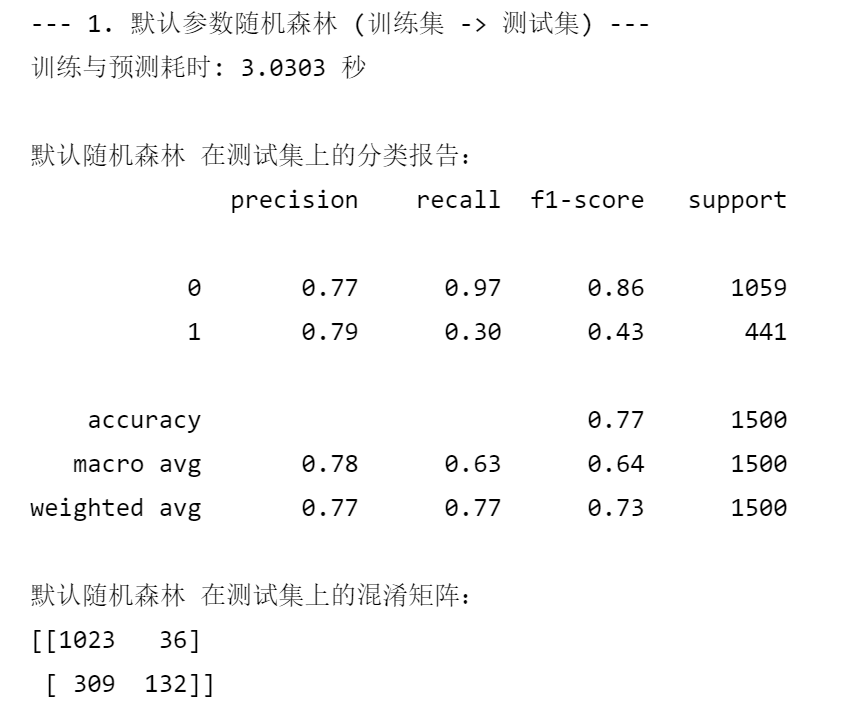 特征筛选
特征筛选
方差筛选
核心逻辑:特征的方差反映了数据的离散程度(变化程度),若一个特征在各个样本中的取值近乎相同,其方差必然极小。对模型区分类别或者预测结果帮助不大。
操作方式:通过设定一个方差阈值,剔除方差低于这个阈值的特征,保留那些变化较大的特征,从而减少特征数量,提高模型效率。
局限性:该方法单纯依据特征自身的方差来决定去留,并未考量特征与目标变量之间的关联。可能会误删一些低方差但有意义的特征。
代码实例:
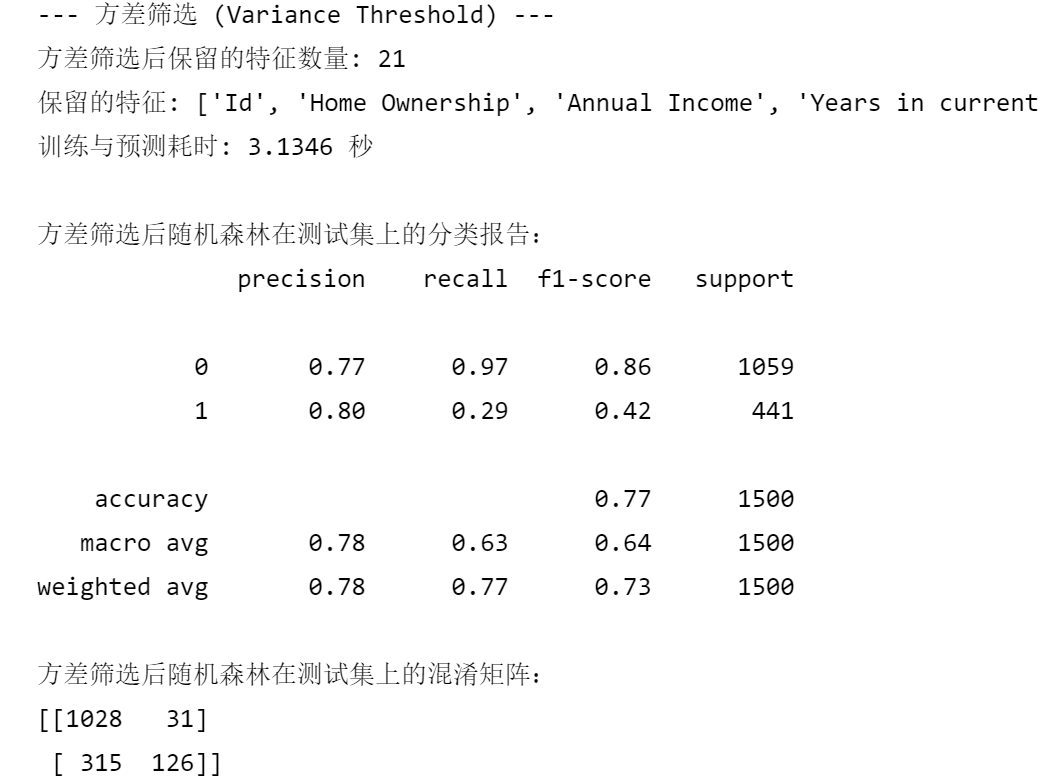
print("--- 方差筛选 (Variance Threshold) ---")
# 导入需要的工具库
# 方差筛选工具,用于剔除方差小的特征
from sklearn.feature_selection import VarianceThreshold
import time
# 记录开始时间,后面会计算整个过程耗时
start_time = time.time()
# 创建方差筛选器,设置方差阈值为0.01,阈值是指方差的最小值
selector = VarianceThreshold(threshold=0.01)
# 对训练数据进行方差筛选,fit_transform会计算每个特征的方差并剔除不满足阈值的特征
# X_train是原始训练数据,X_train_var是筛选后的训练数据
X_train_var = selector.fit_transform(X_train)
# 对测试数据应用同样的筛选规则,transform会直接用训练数据的筛选结果处理测试数据
X_test_var = selector.transform(X_test)
# 获取被保留下来的特征名称
# selector.get_support()返回一个布尔值列表,表示哪些特征被保留
# X_train.columns是特征的名称,结合布尔值列表可以提取保留特征的名字
selected_features_var = X_train.columns[selector.get_support()].tolist()
# 打印筛选后保留的特征数量和具体特征名称,方便查看结果
print(f"方差筛选后保留的特征数量: {len(selected_features_var)}")
print(f"保留的特征: {selected_features_var}")
# 创建一个随机森林分类模型,用于在筛选后的数据上进行训练和预测
# random_state=42是为了保证每次运行结果一致,方便教学和对比
rf_model_var = RandomForestClassifier(random_state=42)
# 在筛选后的训练数据上训练模型
rf_model_var.fit(X_train_var, y_train)
# 使用训练好的模型对筛选后的测试数据进行预测
rf_pred_var = rf_model_var.predict(X_test_var)
# 记录结束时间,计算整个训练和预测过程的耗时
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
# 打印模型在测试集上的分类报告,展示模型的性能
# 分类报告包括精确率、召回率、F1分数等指标,帮助评估模型好坏
print("\n方差筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_var))
# 打印混淆矩阵,展示模型预测的详细结果
# 混淆矩阵显示了真实标签和预测标签的对应情况,比如多少样本被正确分类,多少被错分
print("方差筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_var))
皮尔逊相关系数筛选
核心逻辑:皮尔逊相关系数筛选基于特征和目标变量之间的相关性,其取值范围在 -1 到 1 之间。值越大表示正相关越强,值越小表示负相关越强,接近0表示几乎无关。相关性高的特征对目标变量的变化有更显著的影响,有助于提升模型预测的准确性。
操作方式:根据相关系数绝对值大小,保留与目标变量相关性高的特征,剔除相关性低的特征。
适用场景:该方法特别适用于目标变量为连续型的情况,如预测温度、销售额等。面对分类问题,需要先对目标变量进行编码,例如将 “是” 编码为 1,“否” 编码为 0,使其转化为数值型数据(皮尔逊系数本质上要求数据是数值型的),然后就可以像处理连续型目标变量一样计算皮尔逊相关系数,进而进行特征选择。
局限性:皮尔逊相关系数只能捕捉线性相关关系,可能无法完全反映特征与目标变量之间复杂的非线性关系。
代码实例:
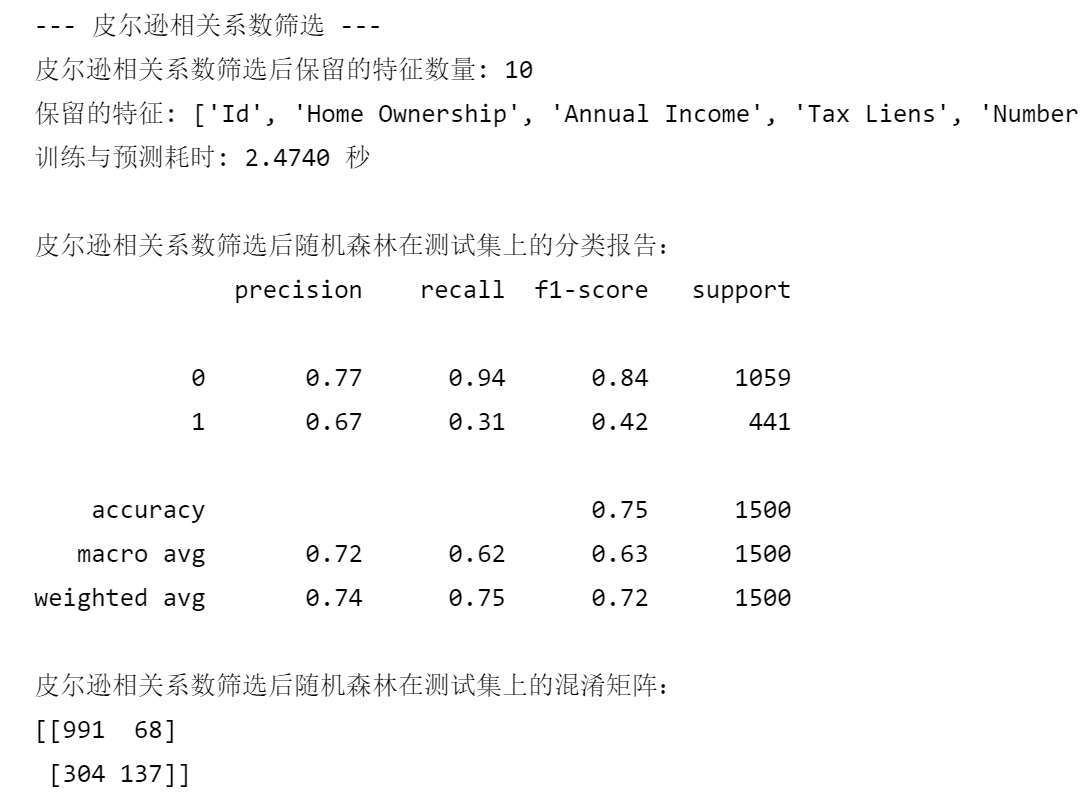
print("--- 皮尔逊相关系数筛选 ---")
# SelectKBest 是用于特征选择的类,会根据某个评分函数选择得分最高的 k 个特征。
# f_classif 是用于分类问题的评分函数,计算每个特征与目标变量之间的方差分析 F值
from sklearn.feature_selection import SelectKBest, f_classif
import time
start_time = time.time()
# 计算特征与目标变量的相关性,选择前k个特征(这里设为10个,可调整)
# 注意:皮尔逊相关系数通常用于回归问题(连续型目标变量),但如果目标是分类问题,可以用f_classif
k = 10
selector = SelectKBest(score_func=f_classif, k=k)
X_train_corr = selector.fit_transform(X_train, y_train)
# 使用相同的选择规则,从测试集中提取与训练集所选特征相同的特征子集。
X_test_corr = selector.transform(X_test)
# 获取筛选后的特征名
selected_features_corr = X_train.columns[selector.get_support()].tolist()
print(f"皮尔逊相关系数筛选后保留的特征数量: {len(selected_features_corr)}")
print(f"保留的特征: {selected_features_corr}")
# 训练随机森林模型
rf_model_corr = RandomForestClassifier(random_state=42)
rf_model_corr.fit(X_train_corr, y_train)
rf_pred_corr = rf_model_corr.predict(X_test_corr)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n皮尔逊相关系数筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_corr))
print("皮尔逊相关系数筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_corr))
lasso筛选(基于L1正则化)
核心逻辑:Lasso 回归将线性回归和特征选择过程整合在一起。在线性回归中,目标是找到一组系数,使得预测值与真实值之间的误差(如均方误差)最小化。而 Lasso 回归在此基础上添加了 L1 正则化项(即惩罚项)。

L1 正则化的作用:L1 正则化项是系数的绝对值之和。当这个正则化项被加入到损失函数中时,它会对系数施加一种 “收缩” 压力。随着正则化强度的增加,Lasso 回归倾向于将一些不重要特征的系数压缩至 0,从而在模型中 “剔除” 这个特征。
 作用:在处理高维数据时,Lasso 回归能够自动识别并去除这些不重要的特征,从而显著减少特征数量。又因为保留下来的特征通常是对目标变量有重要影响的。这使得模型更加简洁明了,解释性更强。
作用:在处理高维数据时,Lasso 回归能够自动识别并去除这些不重要的特征,从而显著减少特征数量。又因为保留下来的特征通常是对目标变量有重要影响的。这使得模型更加简洁明了,解释性更强。
代码实例:
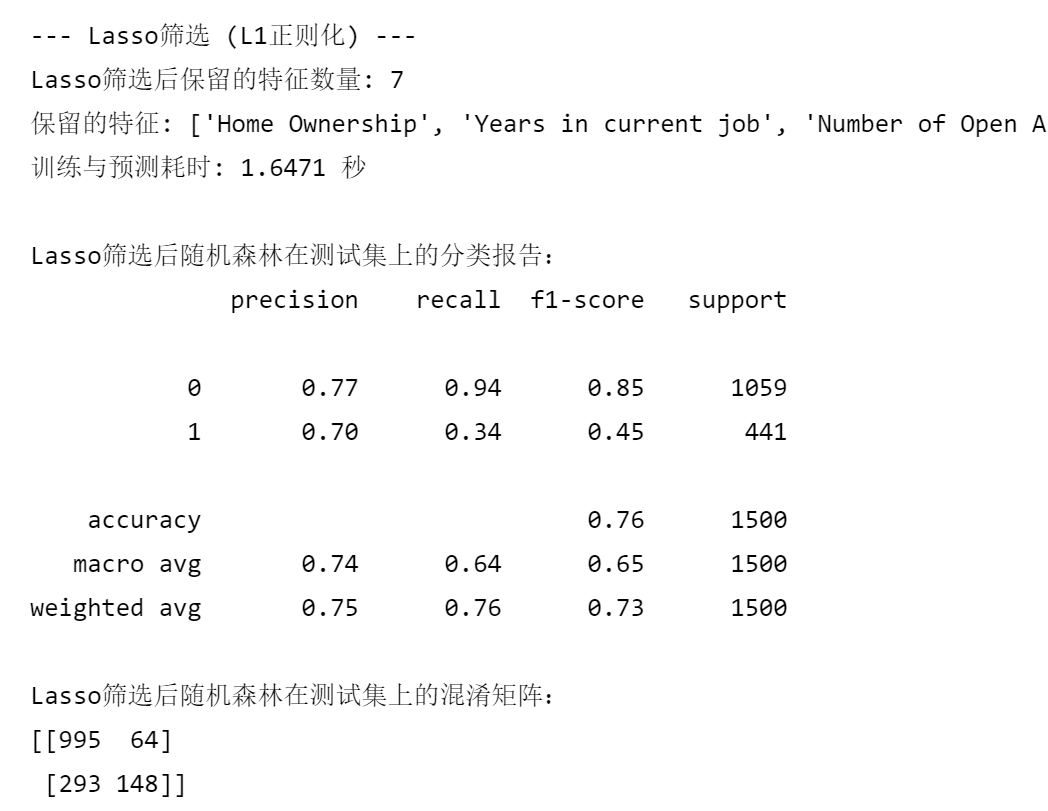
print("--- Lasso筛选 (L1正则化) ---")
from sklearn.linear_model import Lasso
# SelectFromModel可以基于某个模型(如Lasso模型)的系数来选择特征。
from sklearn.feature_selection import SelectFromModel
import time
start_time = time.time()
# 使用Lasso回归进行特征筛选
# alpha参数是正则化强度,值越大,正则化强度越高,更多系数会被压缩到0
lasso = Lasso(alpha=0.01, random_state=42)
selector = SelectFromModel(lasso)
selector.fit(X_train, y_train)
X_train_lasso = selector.transform(X_train)
X_test_lasso = selector.transform(X_test)
# 获取筛选后的特征名
selected_features_lasso = X_train.columns[selector.get_support()].tolist()
print(f"Lasso筛选后保留的特征数量: {len(selected_features_lasso)}")
print(f"保留的特征: {selected_features_lasso}")
# 训练随机森林模型
rf_model_lasso = RandomForestClassifier(random_state=42)
rf_model_lasso.fit(X_train_lasso, y_train)
rf_pred_lasso = rf_model_lasso.predict(X_test_lasso)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\nLasso筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_lasso))
print("Lasso筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_lasso))
树模型重要性
核心逻辑:以随机森林为例(决策树原理类似),在构建随机森林的过程中,每棵决策树在划分节点时会选择一个特征来最大化信息增益(或其他类似的准则,如基尼系数的减少)。随机森林模型会为每个特征计算出一个重要性得分:随机森林之特征选择 - 算法之道
基于这些得分,设置合适的阈值,就可以筛选出对模型预测最有帮助的特征,去除那些不重要的特征,从而简化模型、减少过拟合风险,并提高计算效率。

代码实例:
print("--- 树模型自带的重要性筛选 ---")
from sklearn.feature_selection import SelectFromModel
import time
start_time = time.time()
# 使用随机森林的特征重要性进行筛选
rf_selector = RandomForestClassifier(random_state=42)
# 在训练过程中,随机森林模型会计算每个特征的重要性。
rf_selector.fit(X_train, y_train)
# 设定所有特征重要性的平均值为选择特征的阈值
selector = SelectFromModel(rf_selector, threshold="mean")
X_train_rf = selector.transform(X_train)
X_test_rf = selector.transform(X_test)
# 获取筛选后的特征名
selected_features_rf = X_train.columns[selector.get_support()].tolist()
print(f"树模型重要性筛选后保留的特征数量: {len(selected_features_rf)}")
print(f"保留的特征: {selected_features_rf}")
# 训练随机森林模型
rf_model_rf = RandomForestClassifier(random_state=42)
rf_model_rf.fit(X_train_rf, y_train)
rf_pred_rf = rf_model_rf.predict(X_test_rf)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n树模型重要性筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_rf))
print("树模型重要性筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_rf))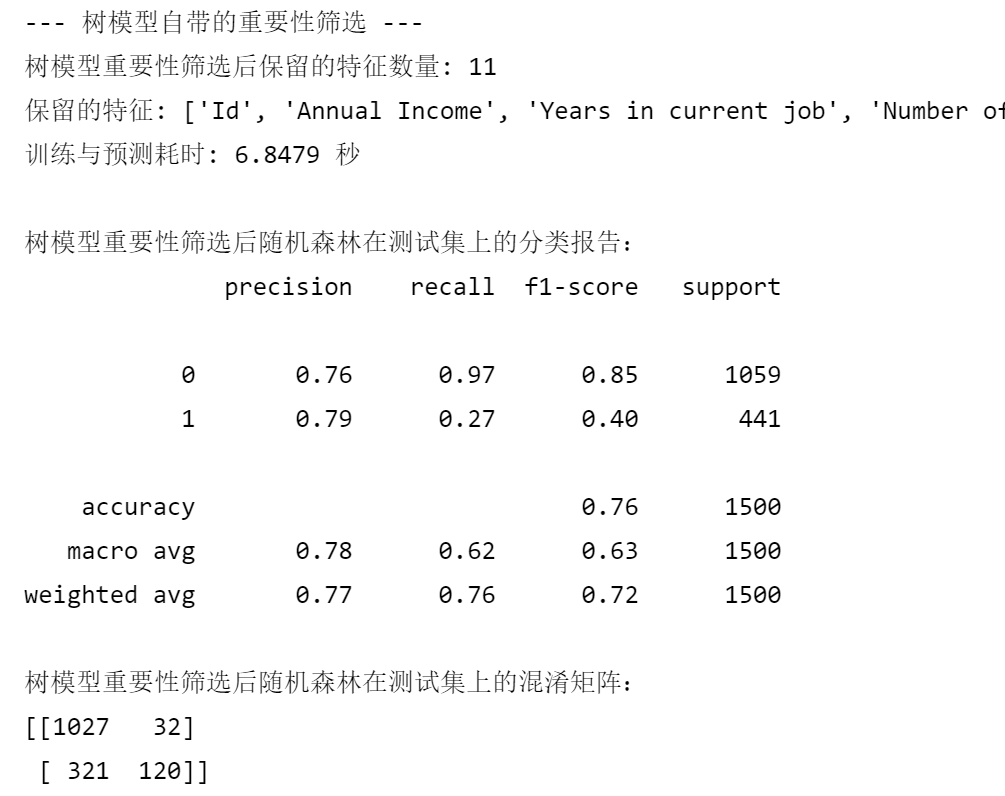
Shap重要性筛选
适用于多种模型:SHAP 值的计算不依赖于特定的模型类型。无论是线性模型、树模型(如决策树、随机森林),还是复杂的深度学习模型(如神经网络),都可以计算 SHAP 值来评估。
综合考虑特征交互:SHAP 值不仅能反映单个特征对预测结果的直接影响,还能考虑到特征之间的相互作用。SHAP 值通过对所有可能的特征组合进行平均计算,来确定每个特征的贡献。
代码实例:
print("--- SHAP重要性筛选 ---")
import shap
from sklearn.feature_selection import SelectKBest
import time
start_time = time.time()
# 使用随机森林模型计算SHAP值
rf_shap = RandomForestClassifier(random_state=42)
rf_shap.fit(X_train, y_train)
explainer = shap.TreeExplainer(rf_shap)
shap_values = explainer.shap_values(X_train)
# 计算每个特征的平均SHAP值(取绝对值的平均)
mean_shap = np.abs(shap_values[1]).mean(axis=0) # shap_values[1]对应正类
k = 10
# argsort()进行排序,返回从小到大排序后的索引。[-k:] 最后 k 个特征的索引
top_k_indices = np.argsort(mean_shap)[-k:]
X_train_shap = X_train.iloc[:, top_k_indices]
X_test_shap = X_test.iloc[:, top_k_indices]
# 获取筛选后的特征名
selected_features_shap = X_train.columns[top_k_indices].tolist()
print(f"SHAP重要性筛选后保留的特征数量: {len(selected_features_shap)}")
print(f"保留的特征: {selected_features_shap}")
# 训练随机森林模型
rf_model_shap = RandomForestClassifier(random_state=42)
rf_model_shap.fit(X_train_shap, y_train)
rf_pred_shap = rf_model_shap.predict(X_test_shap)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\nSHAP重要性筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_shap))
print("SHAP重要性筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_shap))

递归特征消除RFE
核心逻辑:RFE 从包含所有特征的完整集合开始。每次迭代,它基于一个已选定的模型来评估每个特征的重要性。评估方式通常依赖于模型提供的系数或特征重要性得分。然后移除得分最低(即最不重要)的特征,得到一个新的特征子集。接着,在这个新的特征子集上重新训练模型,再次评估特征重要性,继续移除最不重要的特征,如此递归进行。
停止条件:预设特征数量和基于模型性能指标(达到收敛值)。
局限性:每次迭代都要重新训练模型,对于大型数据集或复杂模型,计算量较大,耗时较长。另外RFE 筛选特征的结果依赖于所选择的模型。不同的模型对特征重要性的评估方式可能不同,导致筛选出的特征子集也会有所差异。
代码实例:
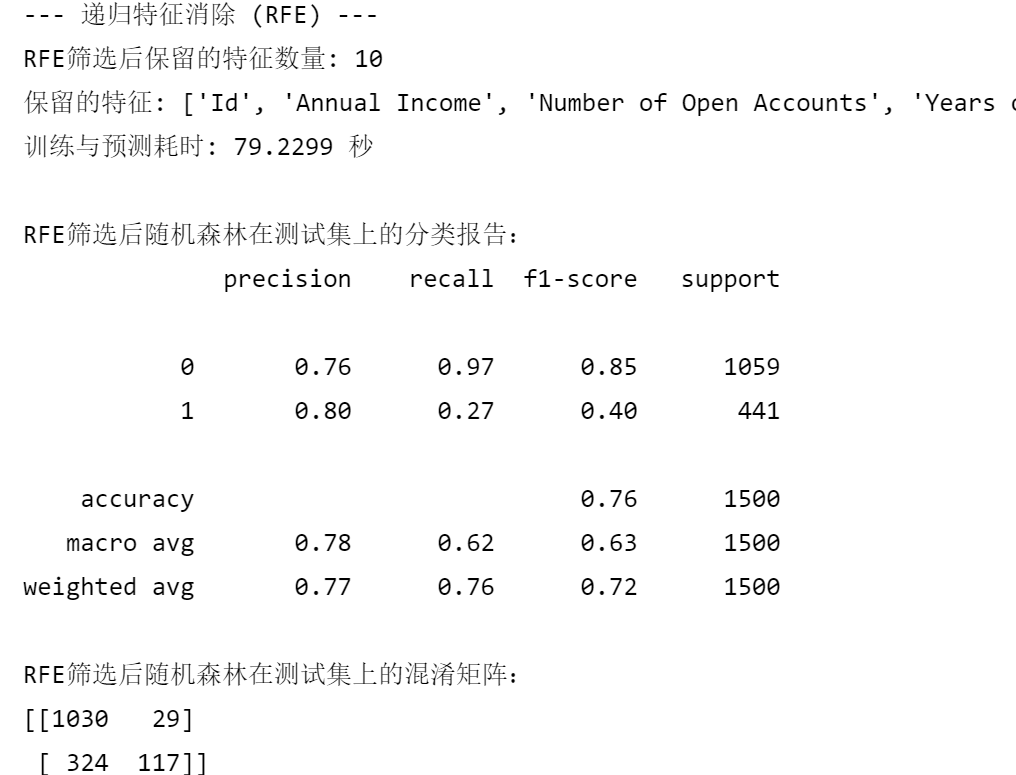
print("--- 递归特征消除 (RFE) ---")
from sklearn.feature_selection import RFE
import time
start_time = time.time()
# 使用随机森林作为基础模型进行RFE
base_model = RandomForestClassifier(random_state=42)
rfe = RFE(base_model, n_features_to_select=10) # 选择10个特征,可调整
rfe.fit(X_train, y_train)
X_train_rfe = rfe.transform(X_train)
X_test_rfe = rfe.transform(X_test)
# 获取筛选后的特征名
selected_features_rfe = X_train.columns[rfe.support_].tolist()
print(f"RFE筛选后保留的特征数量: {len(selected_features_rfe)}")
print(f"保留的特征: {selected_features_rfe}")
# 训练随机森林模型
rf_model_rfe = RandomForestClassifier(random_state=42)
rf_model_rfe.fit(X_train_rfe, y_train)
rf_pred_rfe = rf_model_rfe.predict(X_test_rfe)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\nRFE筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_rfe))
print("RFE筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_rfe))

















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









