









 本文详细介绍了Linux系统中的父进程和子进程概念,以及如何使用fork函数创建子进程。通过示例代码展示了fork函数在父子进程中的行为差异,解释了Linux采用的写时拷贝技术,实现了读时共享、写时拷贝,从而有效管理内存和提高效率。同时,文中还提及了文件描述符在父子进程间的共享特性。
本文详细介绍了Linux系统中的父进程和子进程概念,以及如何使用fork函数创建子进程。通过示例代码展示了fork函数在父子进程中的行为差异,解释了Linux采用的写时拷贝技术,实现了读时共享、写时拷贝,从而有效管理内存和提高效率。同时,文中还提及了文件描述符在父子进程间的共享特性。
系列文章目录
该文章主要是针对面试做大致的了解,通俗易懂!!!
一、父进程、子进程的定义
1、父进程
指已创建一个或多个子进程的进程。在Linux里,除了进程0以外的所有进程都是由其他进程使用系统调用fork()函数创建的,这里调用fork()函数创建新进程的进程即为父进程,而相对应的为其创建出的进程则为子进程,因而除了进程0以外的进程都只有一个父进程,但一个进程可以有多个子进程。
2、子进程
指的是由另一进程(对应称之为父进程)所创建的进程。子进程继承了对应的父进程的大部分属性,如文件描述符。在Unix中,子进程通常为系统调用fork()函数的产物。在此情况下,子进程一开始就是父进程的副本,而在这之后,根据具体需要,子进程可以借助exec调用来链式加载另一程序。
二、创建子进程
1、创建子进程 fork 函数
// 创建子进程
pid_t pid = fork();
返回值:
fork()的返回值会返回两次。一次是在父进程中,一次是在子进程中。
在父进程中返回创建的子进程的ID,
在子进程中返回0
如何区分父进程和子进程:通过fork的返回值。
在父进程中返回-1,表示创建子进程失败,并且设置errno
父子进程之间的关系:
1.fork()函数的返回值不同
父进程中:返回值 >0 返回的子进程的ID
子进程中:返回值 =0
2.pcb中的一些数据
当前的进程的id pid
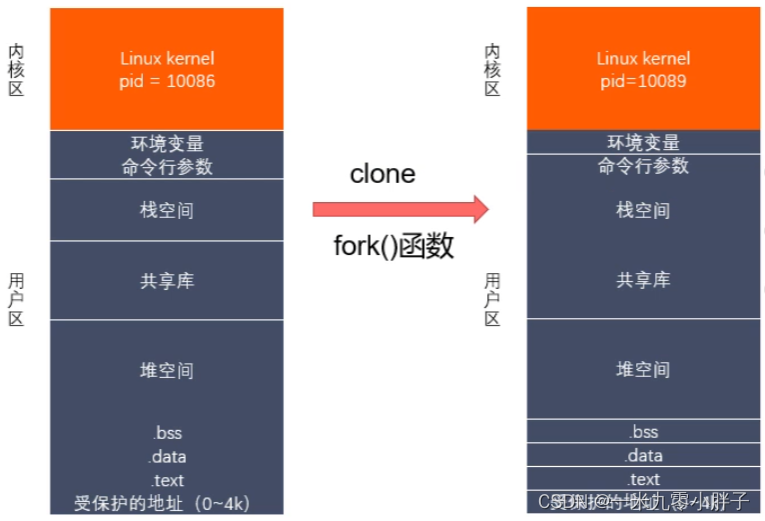
2、虚拟地址空间使用情况
(1)当调用fork()函数时会复制一份父进程的虚拟地址空间 ,即子进程的用户数据和父进程一样,内核区也会被拷贝过来,但是pid会略有不同;
(2)假设当前父进程pid=10086,子进程pid=10089;父进程(pid=10086)、子进程(pid=10089)内核区的pid是各自的进程id,而父进程栈空间的pid=10089(pid是子进程的id号),子进程栈空间的pid=0;
3、举例说明
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main() {
int num = 10;
// 创建子进程
pid_t pid = fork();
// 判断是父进程还是子进程
if(pid > 0) {
// printf("pid : %d\n", pid);
// 如果大于0,返回的是创建的子进程的进程号,当前是父进程
printf("i am parent process, pid : %d, ppid : %d\n", getpid(), getppid());
printf("parent num : %d\n", num);
num += 10;
printf("parent num += 10 : %d\n", num);
} else if(pid == 0) {
// 当前是子进程
printf("i am child process, pid : %d, ppid : %d\n", getpid(),getppid());
printf("child num : %d\n", num);
num += 100;
printf("child num += 100 : %d\n", num);
}
// for循环
for(int i = 0; i < 3; i++) {
printf("i : %d , pid : %d\n", i , getpid());
sleep(1);
}
return 0;
}说明:在执行 fork() 函数时,父进程的虚拟地址空间会被拷贝一份(pid会略有不同),而代码是在用户区的代码段(.text),所以父进程的代码也会被完整拷贝一份;虽然代码完全一样,但是父进程和子进程在执行代码时也会有所区别,父子进程都只能执行各自的部分;
1、父进程执行代码部分
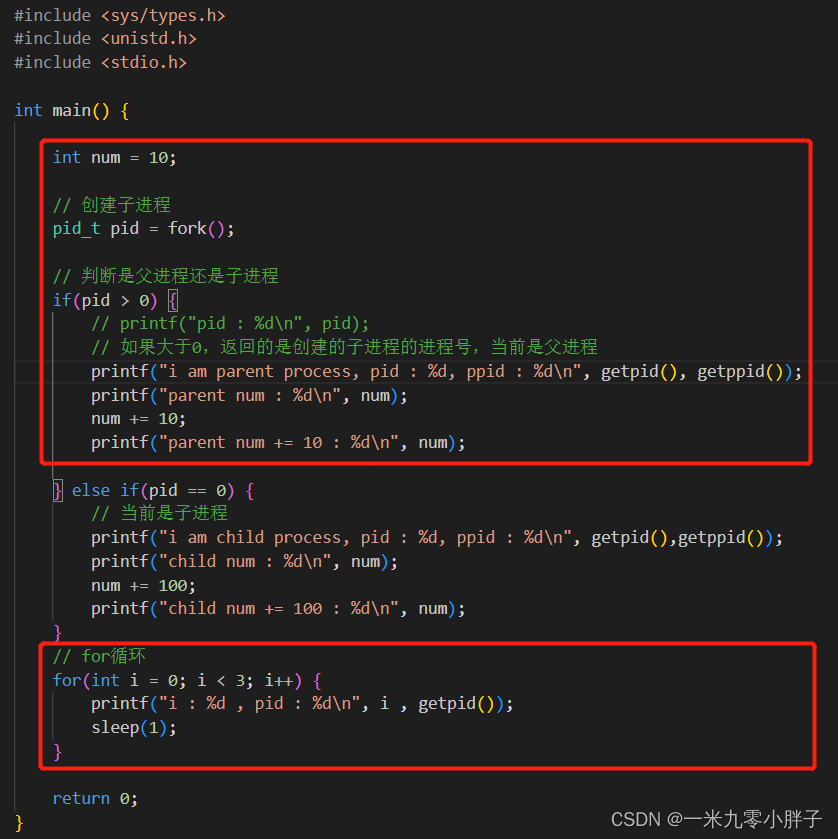
说明:父进程只执行红色方框内的代码;
2、子进程执行代码部分
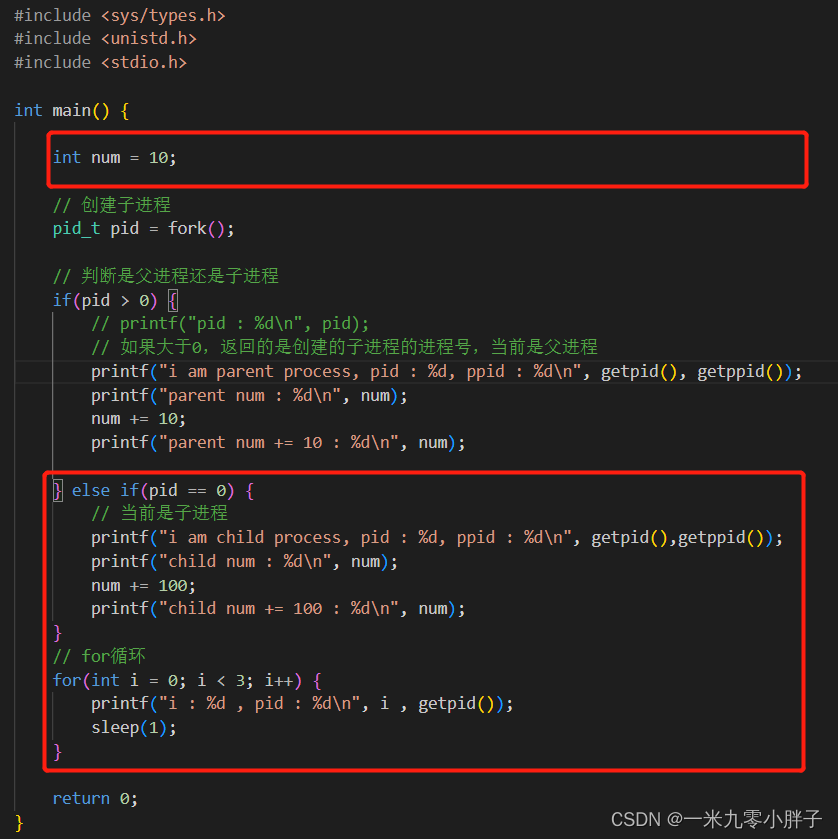
说明:子进程只会执行方框内的代码;
3、总结
(1)父、子进程代码执行情况
准确来说,Linux 的 fork() 使用是通过写时拷贝 (copy- on-write) 实现。写时拷贝是一种可以推迟甚
至避免拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址
空间。只用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间。
也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。
注意:fork之后父子进程共享文件,fork产生的子进程与父进程相同的文件文件描述符指向相同的
文件表,引用计数增加,共享文件偏移指针。
读时共享,写时拷贝;可以降低内存消耗、减少复制所使用的时间!
解释:
(1)读时共享:这个容易理解,即不涉及写操作时,子进程并不会复制父进程的地址空间,而是和父进程共享一块地址空间;
(2)写时拷贝:拿上述代码案例来说,父进程执行部分和子进程执行部分都会对变量num进行操作,但是父进程和子进程对变量num的操作是独立的、互不相干的,此时便需要子进程复制父进程的地址空间,然后父、子进程在各自空间中对变量num进行操作;
(2)代码执行结果
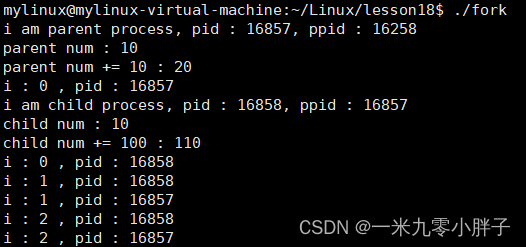
说明:由代码执行结果可以验证读时共享,写时拷贝;此外,父进程和子进程在执行的过程中是交替执行的,执行的先后顺序是不确定的,当一方的时间片执行结束后,便会执行另一方。


















 2489
2489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











