







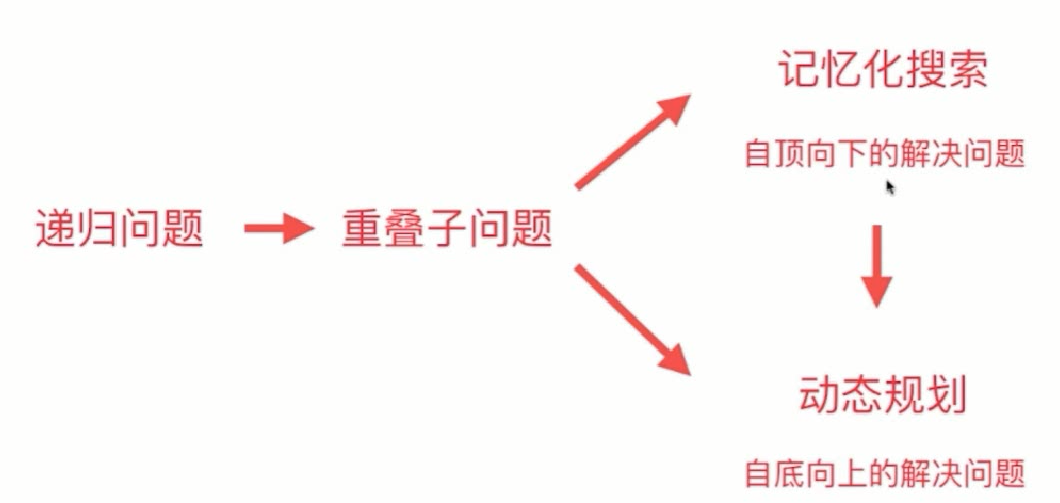
一:记忆化搜索
递归搜索 + 保存计算结果 = 记忆化搜索
1:斐波那契
…,a,b,c,… c=a+b;
某一个位置
i的值是前两个数的和,即:f(i)=f(i-1)+f(i-2)
题目暴力递归存在大量的重复操作,而且复杂度是指数,所以只要某一个分支求过了就保存结果,下一次不必进入递归树求解,这样就能极大地优化速度。
这种操作也叫“剪枝”

class Solution {
public:
int fib(int n) {
this->n=n;
//这里取-1是因为中途结果不可能出现-1
memo=vector<int>(n+1,-1);//可以取n
return getFib(n);
}
private:
int n;
vector<int> memo;//用于记忆结果
int getFib(int index){
//递归结果
if(index==0) return 0;
if(index==1) return 1;
//记忆化return
if(memo[index]!=-1) return memo[index];
//递归求结果
memo[index]=getFib(index-1)+getFib(index-2);
return memo[index];
}
};
记忆化也叫自上而下解决问题:
- 初始状态一般作为递归出口,保证程序可结束
- 中间状态就是递归过程
- 把终点作为参数传递
从最终地不能再分解的子问题,根据递推方程(f(n) = f(n-1) + f(n-2))逐渐求它上层的问题,上上层问题,最终求得一开始的问题,这种求解问题的方式就叫自底向上。
记忆化搜索和动态规划关系:
2:爬楼梯
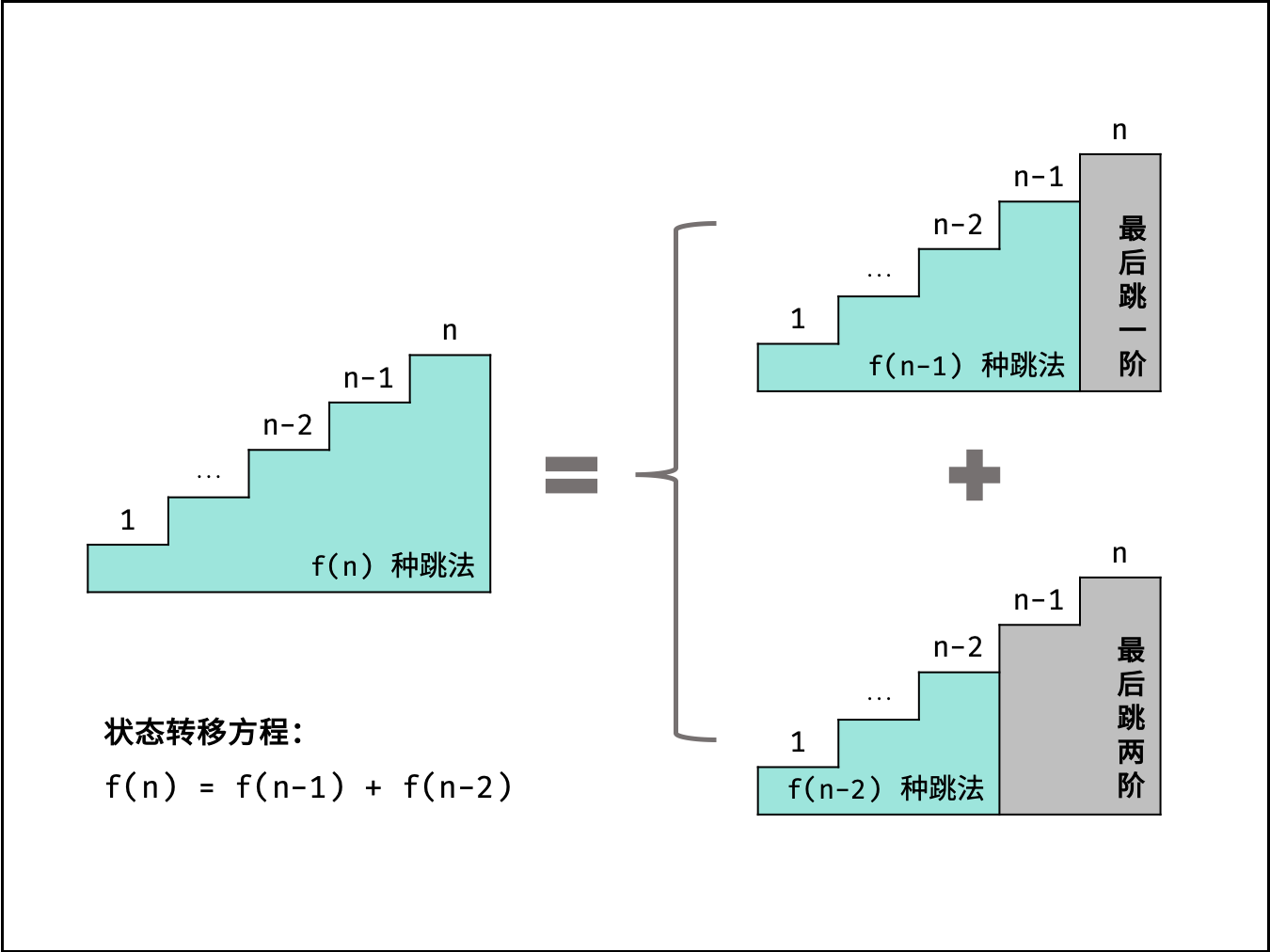
这道题倒着考虑比正向考虑简单很多
比如你已经在第n个台阶,那么你的上一步可能为:
- 从n-1个台阶走一步到达
- 从n-2个台阶走两步到达
也就是递归结构为:f(n)=f(n-1)+f(n-2)
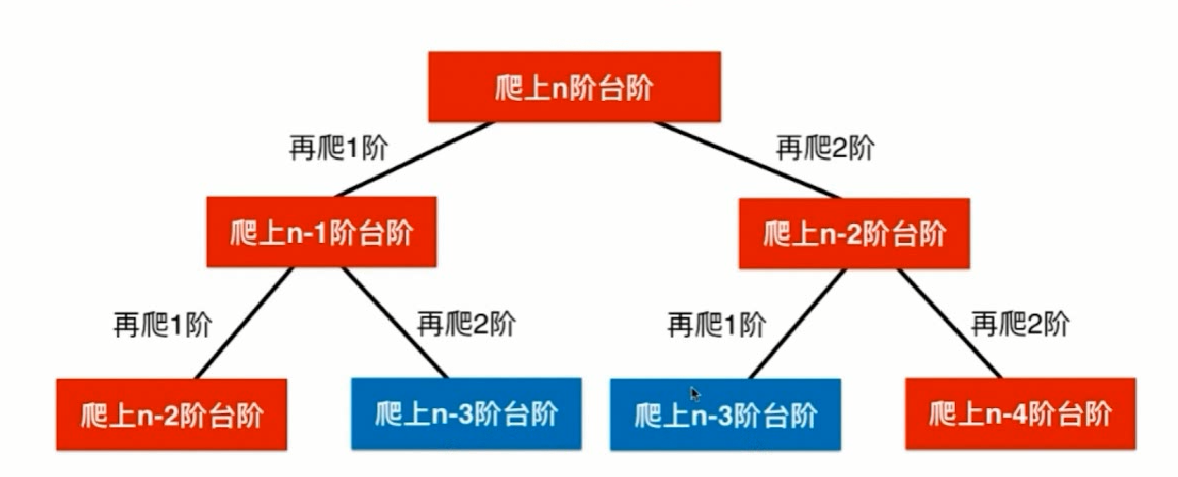
同样的—题目的递归树不同分支存在多种相同的计算,比如:爬上n-3阶台阶
class Solution {
public:
int climbStairs(int n) {
this->n = n;
memo = vector<int>(n + 1, -1);
return getChoose(n);
}
private:
int n;
vector<int> memo;
int getChoose(int index) {
// if(index==0) return 1;这里是没有台阶只有一种可能
if (index == 1)
return 1;
if (index == 2)
return 2;
if (memo[index] == -1) // 没有记录过
memo[index] = getChoose(index - 1) + getChoose(index - 2);
return memo[index];
}
};
递归终止条件可以选择:1,2(2个台阶有2种解法)
或者选择0和1,这里0对应1(2=1+1)
3:打家劫舍
思路:
选定一端开始,其实每一个元素都有两种选择,选不选:
-
选了,那么就要放弃与它相邻元素的值,累加上与他相隔的那个元素
-
不选,那么直接延续它的上一个元素结果即可
class Solution {
public:
int rob(vector<int>& nums) {
this->m=nums.size();
this->nums=nums;
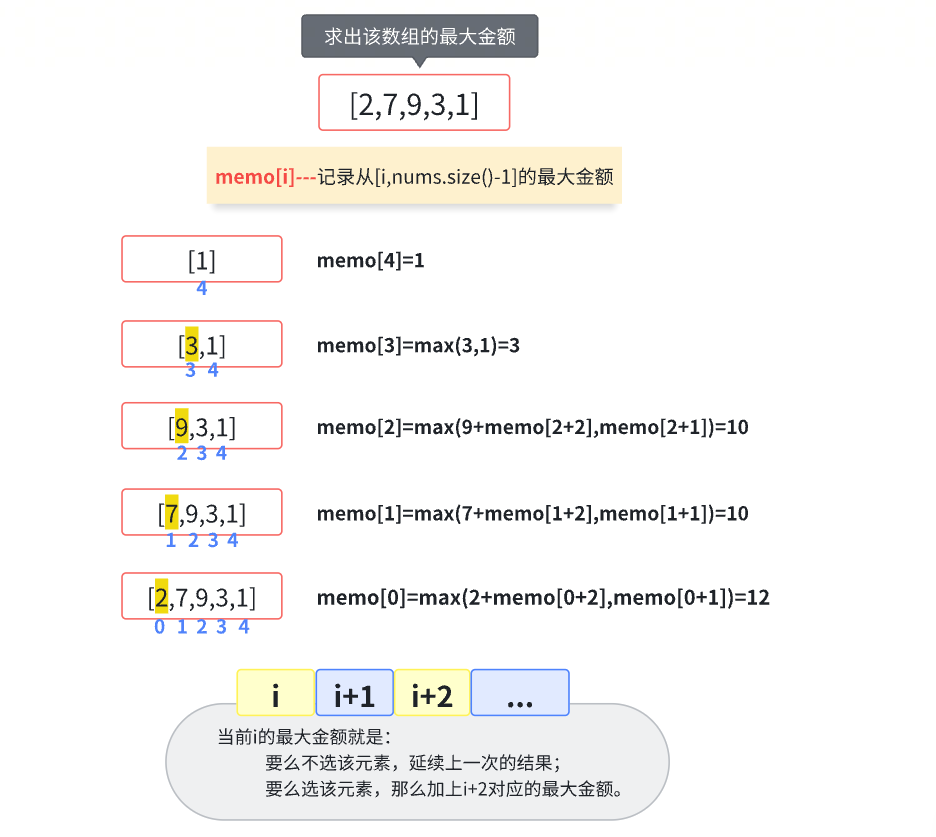
//memo[i]:记录[i,..,m-1]的最大金额
//初始化为-1,表明还没计算到该值
this->memo=vector<int>(m,-1);
return tryRob(0);
}
private:
int m;
vector<int> nums;
vector<int> memo;
//计算[index,..,m-1]的最大价值
int tryRob(int index){
if(index>=m){
//index=m-2时候:index+2=m
//index=m-1时候:index+2=m+1
//所以是>=
return 0;
}
if(memo[index]!=-1){
return memo[index];
}
//计算memo[index]
memo[index]=max(nums[index]+tryRob(index+2),tryRob(index+1));
return memo[index];
}
};
这里有大量重复的步骤,因为最大值说白了只关心当前值和与它隔一个值或者直接取它的上一个值
所以用memo数组记录已经计算过的值
其实两端没有要求,也可以用memo[i]计算[0,...,i]的最大值
class Solution {
public:
int rob(vector<int>& nums) {
this->m=nums.size();
//memo[i]:记录[0,..,i]的最大金额
this->memo=vector<int>(m,-1);
return tryRob(nums,m-1);
}
private:
int m;
vector<int> memo;
//计算[index,..,m-1]的最大价值
int tryRob(vector<int>& nums,int index){
if(index<0){
return 0;
}
if(memo[index]!=-1){
return memo[index];
}
//计算memo[index]
memo[index]=max(nums[index]+tryRob(nums,index-2),\
tryRob(nums,index-1));
return memo[index];
}
};
记忆化就是搜索树的分支之间存在大量重复,把每个分支结果记录下来只计算一边
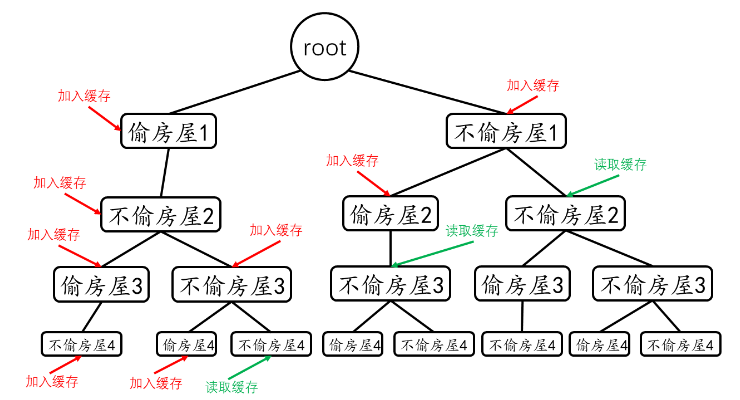
方法:通过for来求出memo[i]
class Solution {
public:
int rob(vector<int>& nums) {
this->m=nums.size();
this->memo=vector<int>(m,-1);
return tryRob(nums,0);
}
private:
int m;
vector<int> memo;
int tryRob(vector<int>& nums,int index){
if(index>=m) return 0;
if(memo[index]!=-1) return memo[index];
int res=0;
for(int i=index;i<m;i++){
res=max(res,nums[i]+tryRob(nums,i+2));
}
memo[index]=res;
return memo[index];
}
};

4:三角形最小路径
其实可以看成一个类似树的结构,每一个结点都有左右孩子,只不过左右孩子有重叠所以可以得到递归结构:
当前路径最小值=当前结点值+min(左路经最小,右路径最小)
如图3和4交会到5后,5往下的路径属于重复,所以需要
记忆化
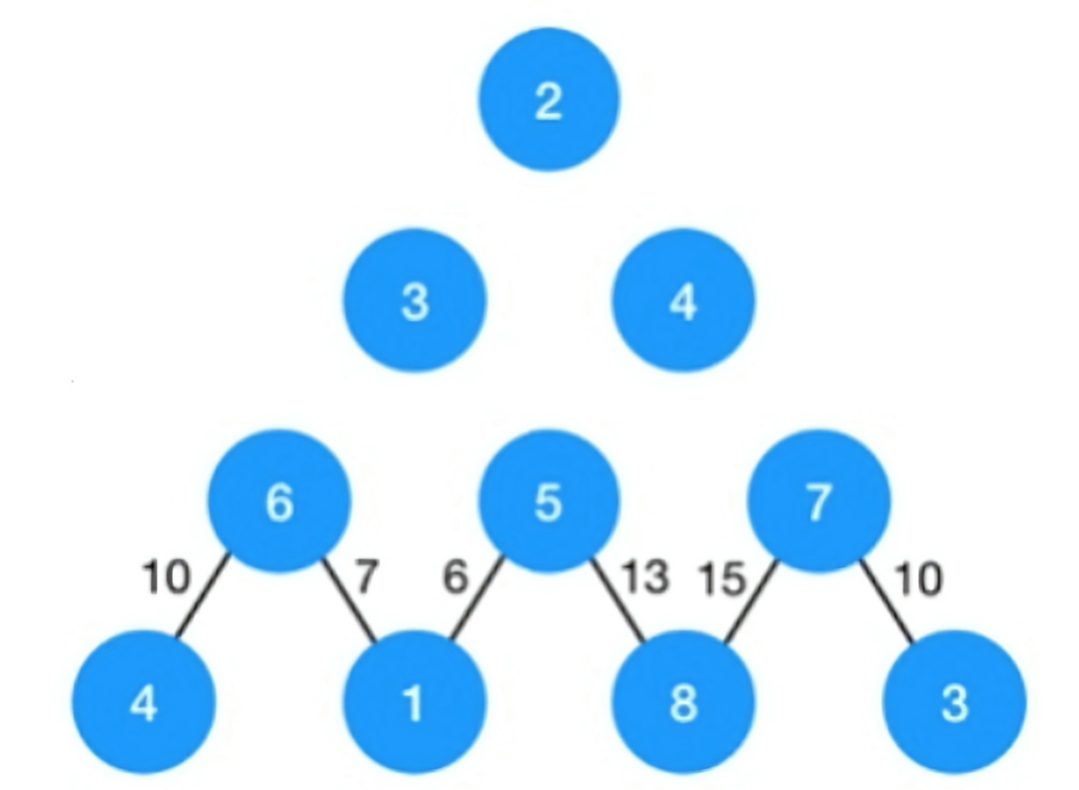
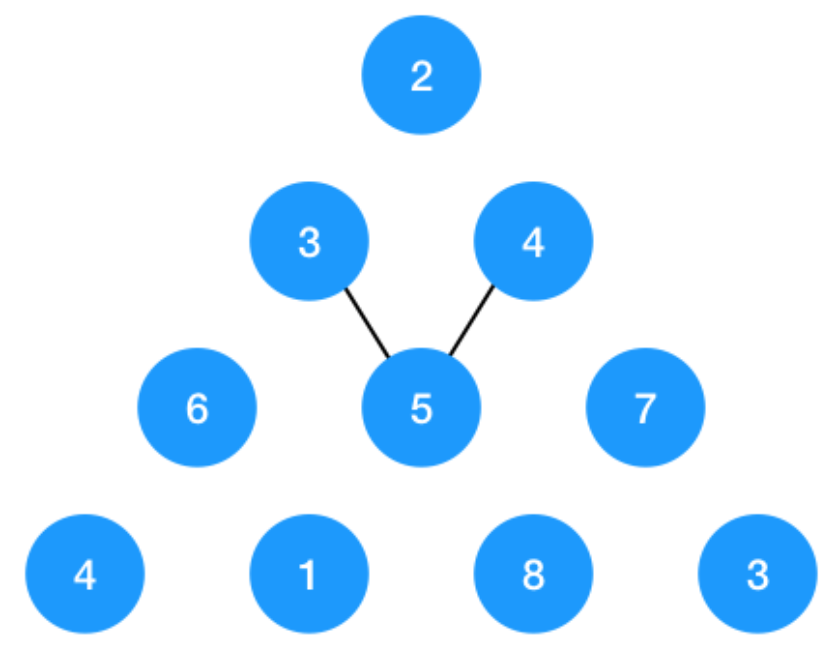
递归方式一定是从根即最上面顶点往下进行递归
class Solution {
public:
int minimumTotal(vector<vector<int>>& triangle) {
this->m=triangle.size();
this->tri=triangle;
this->memo=vector<vector<int>>(m,vector<int>());
for(int i=0;i<m;i++){
for(int j=0;j<=i;j++){
memo[i].push_back(-1);
}
}
return getPath(0,0);
}
private:
int m;
vector<vector<int>> tri;
vector<vector<int>> memo;
//[0,0]开始向下递归
int getPath(int x,int y){
if(x>=m) return 0;
if(memo[x][y]!=-1) return memo[x][y];
memo[x][y]=tri[x][y]+\
min(getPath(x+1,y),getPath(x+1,y+1));
return memo[x][y];
}
};
memo的初值可以选择:INT_MAX
可以用map进行记忆化
//用map进行记忆化,因为pair次序有要求,用map map<pair<int,int>,int> mp; int getPath(int x,int y){ if(x>=m) return 0; if(mp.count({x,y})) return mp[{x,y}]; mp[{x,y}]=tri[x][y]+\ min(getPath(x+1,y),getPath(x+1,y+1)); return mp[{x,y}]; }
5:矩阵最小路径
每个点只能向下走或向右走,可以抽象成图
颠倒一下类似上面的上角形
只不过这时候不可走的路径一定要返回INT_MAX,这样才能准确找到最小
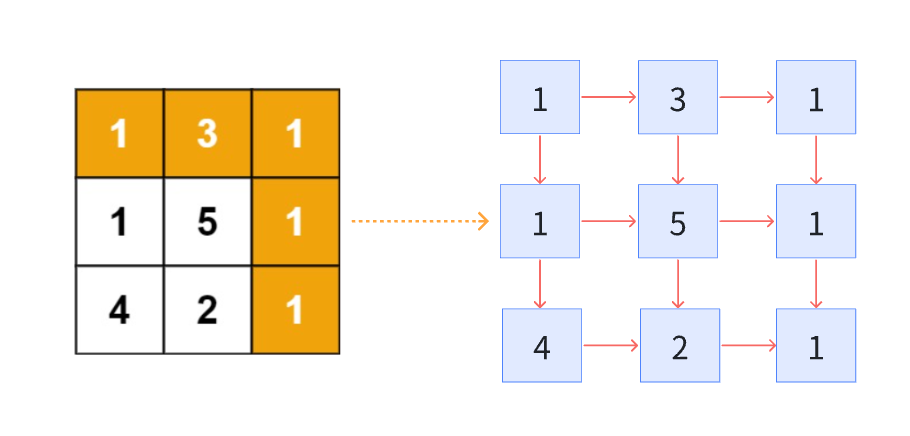

从起点(0,0)到达终点(m-1,n-1)
因为是求最小值,所以不在搜索范围内的边界必须返回INT_MAX
而且必须遇到终点值,返回其值
class Solution {
public:
int minPathSum(vector<vector<int>>& grid) {
this->m = grid.size();
this->n = grid[0].size();
this->grid = grid;
this->memo = vector<vector<int>>(m, vector<int>(n, -1));
return getPath(0, 0);
}
private:
int m, n;
vector<vector<int>> grid;
vector<vector<int>> memo;
int getPath(int x, int y) {
if (x >= m || y >= n)
return INT_MAX;
// 终点返回节点值
if (x == m - 1 && y == n - 1)
return grid[x][y];
if (memo[x][y] != -1)
return memo[x][y];
memo[x][y] = grid[x][y] +\
min(getPath(x + 1, y), getPath(x, y + 1));
return memo[x][y];
}
};
终点值可以提前给,声明就改变
class Solution { public: int minPathSum(vector<vector<int>>& grid) { this->m = grid.size(); this->n = grid[0].size(); this->grid = grid; this->memo = vector<vector<int>>(m, vector<int>(n, -1)); memo[m-1][n-1]=grid[m-1][n-1];//声明终点值 return getPath(0, 0); } private: int m, n; vector<vector<int>> grid; vector<vector<int>> memo; int getPath(int x, int y) { if (x >= m || y >= n) return INT_MAX; if (memo[x][y] != -1) return memo[x][y]; memo[x][y] = grid[x][y] +\ min(getPath(x + 1, y), getPath(x, y + 1)); return memo[x][y]; } };
这里起点和终点没区别,可以递归到起点
记得路径改变为:向上或者向左
class Solution {
public:
int minPathSum(vector<vector<int>>& grid) {
this->m = grid.size();
this->n = grid[0].size();
this->grid = grid;
this->memo = vector<vector<int>>(m, vector<int>(n, -1));
return getPath(m-1, n-1);
}
private:
int m, n;
vector<vector<int>> grid;
vector<vector<int>> memo;
int getPath(int x, int y) {
if (x < 0 || y < 0)
return INT_MAX;
// 终点是:(0,0)
if (x == 0 && y == 0)
return grid[x][y];
if (memo[x][y] != -1)
return memo[x][y];
//倒着:向上或者向左
memo[x][y] = grid[x][y] +\
min(getPath(x -1, y), getPath(x, y - 1));
return memo[x][y];
}
};
6:矩阵最长路径
按照题意,可以把矩阵画成有向无环图
在有向图中寻找最长路径
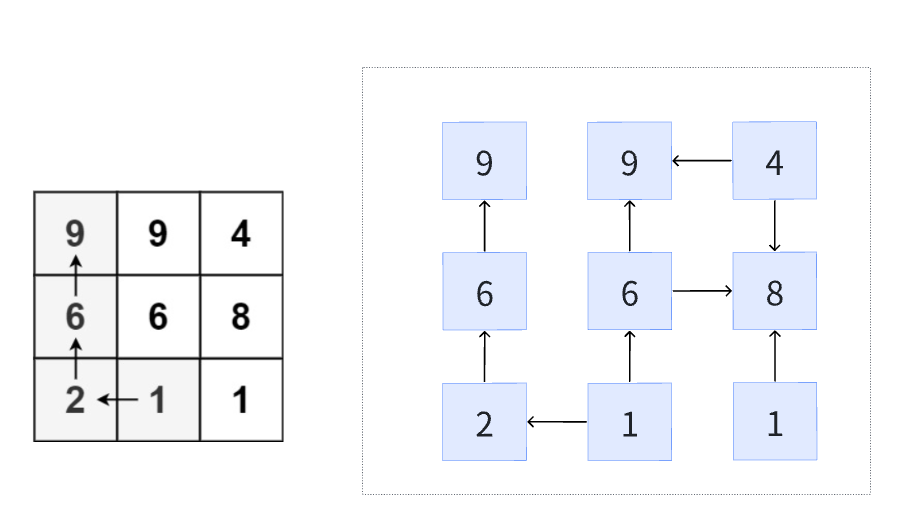
-
memo[i] [j]表示从 i与j 出发能达到的最大递增路径子问题:从某一个位置出发能走多远
每当你达到(i, j)这个位置的时候,要计算上下左右四个方向,选四个方向中最长的路径长度将其记录进memo [i] [j]
如果从位置(a,b)到位置(c,d)数值上满足递增:
memo [a] [b]=1+dfs(c,d)
class Solution {
public:
int longestIncreasingPath(vector<vector<int>>& matrix) {
m=matrix.size();
n=matrix[0].size();
this->matrix=matrix;
memo=vector<vector<int>>(m,vector<int>(n,-1));
//从整个图去搜索
int res=1;
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
if(memo[i][j]!=-1){
res=max(res,memo[i][j]);
}
else{
res=max(res,dfs(i,j));
}
}
}
return res;
}
private:
int m,n;
vector<vector<int>> matrix;
vector<vector<int>> memo;
bool isInArea(int x,int y){
return x>=0 && y>=0 && x<m && y<n;
}
int d[4][2]={{1,0},{-1,0},{0,1},{0,-1}};
int dfs(int x,int y){
if(memo[x][y]!=-1) return memo[x][y];
//最小为1
memo[x][y]=1;
for(int i=0;i<4;i++){
int nx=x+d[i][0];
int ny=y+d[i][1];
if(isInArea(nx,ny) && matrix[x][y]<matrix[nx][ny]){
memo[x][y]=max(memo[x][y],1+dfs(nx,ny));
}
}
return memo[x][y];
}
};
主程序也可以不去管memo[x] [y]是否存在,子函数会调用函数返回
for(int i=0;i<m;i++){ for(int j=0;j<n;j++){ res=max(res,dfs(i,j)); } }
当然也可以先递归后判断条件,但是这里要求后一个比前一个大,所以需要需要传入前驱
int dfs(int x,int y,int pre){
//不再范围或者不递增
if(!isInArea(x,y)||matrix[x][y]<=pre){
return 0;
}
if(memo[x][y]!=-1) return memo[x][y];
//最小为1
memo[x][y]=1;
for(int i=0;i<4;i++){
int nx=x+d[i][0];
int ny=y+d[i][1];
int val=dfs(nx,ny,matrix[x][y]);//递归后的值
memo[x][y]=max(memo[x][y],1+val);
}
return memo[x][y];
}
二:二叉堆
堆是一种高校维护集合中最大值或最小值的数据结构
二叉堆的定义
- 结构上要求:必须是完全二叉树
- 树值上要求:
父节点大于等于孩子结点或父节点小于等于孩子结点
堆有大顶堆和小顶堆两种类型
也可以叫:大根堆,小根堆
只有父子结点有数值上的关系,兄弟间大小无要求
堆也可以用其他数据结构实现,用二叉树实现堆的性质的堆叫二叉堆
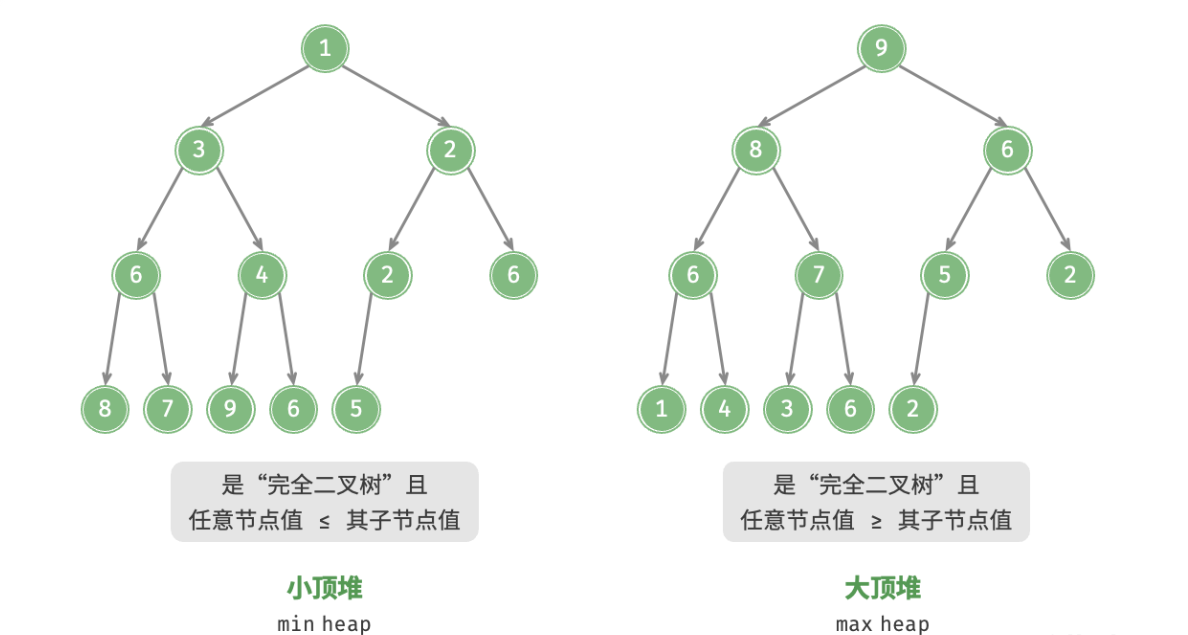
二叉堆的本质----满足父子数值关系的一种完全二叉树
堆:从根到叶子的一条路径满足单调性
二叉堆的存储
完全二叉树非常适合用数组来表示,所以可以用一堆数组来存储二叉堆
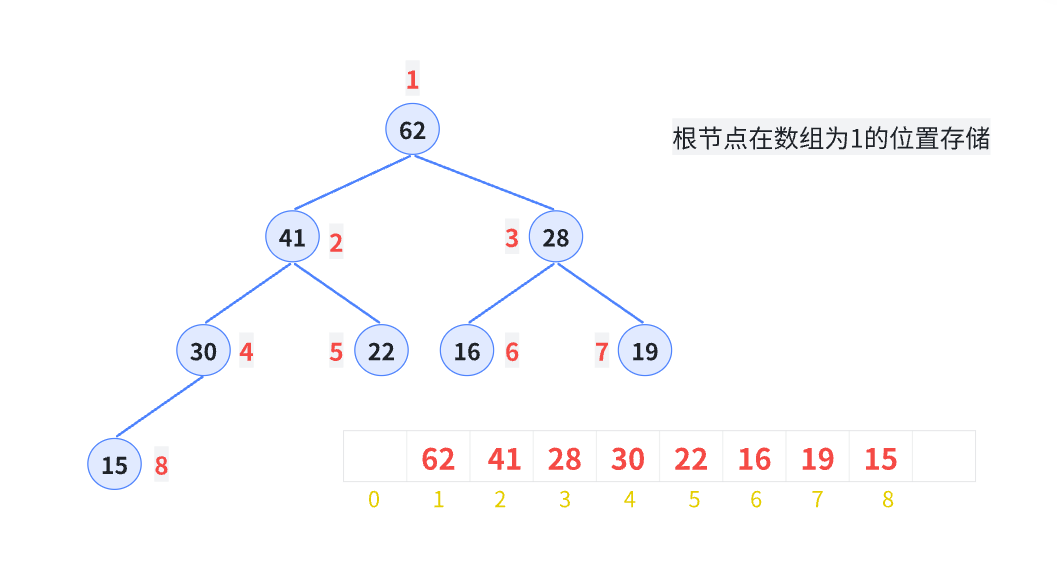
如果数组位置从1开始存储,且父节点索引为p:
- p的左儿子结点为:2*p
- p的右儿子结点为:2*p+1
如果儿子结点为p,则其父亲节点为:p/2
如果从0存储:
索引为p的父节点:—左儿子索引:2*i+1
—右儿子索引:2*i+2
索引为p的儿子结点,其父节点索引为:(p-1)/2
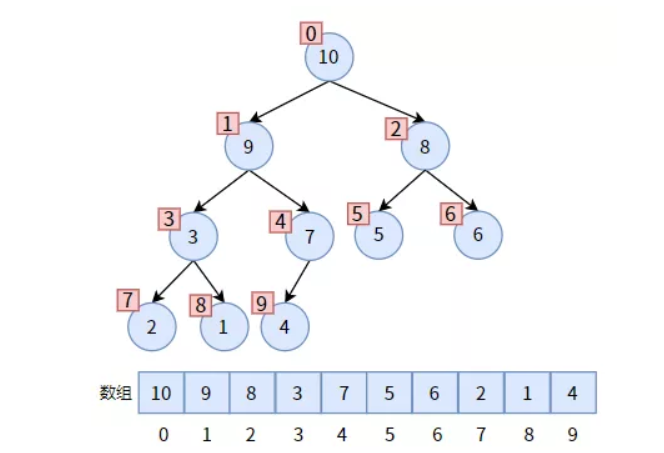
二叉堆的操作
插入
新结点直接插入在堆的尾部,然后向上调整,最多到父节点结束
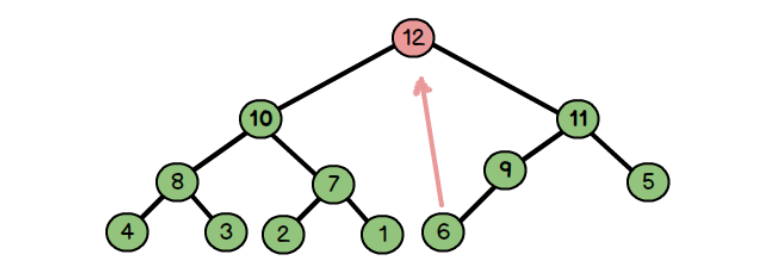
把新的元素直接放入堆的尾部,比如这里的12,然后不断和其父节点比较数值
因为:父节点6比儿子12小,所以交换12和6
因为父节点9比儿子节点大,所以交换9和12
同理:交换11和12
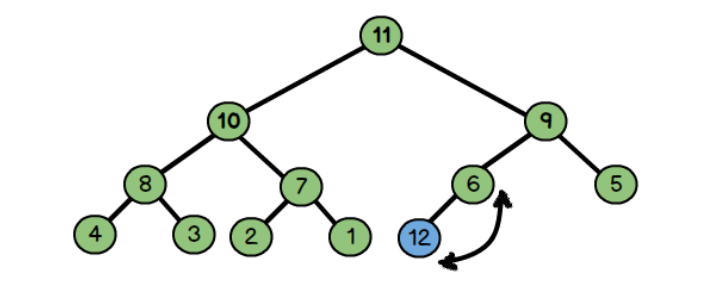
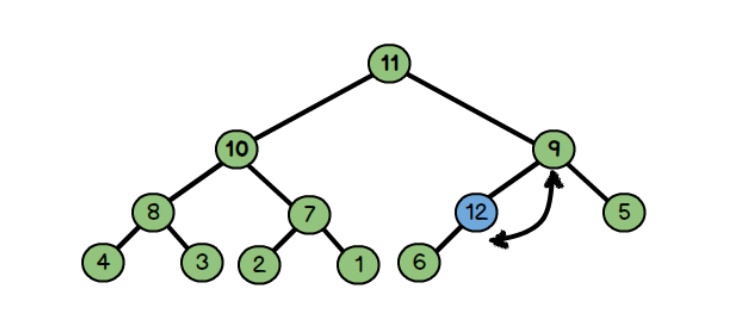
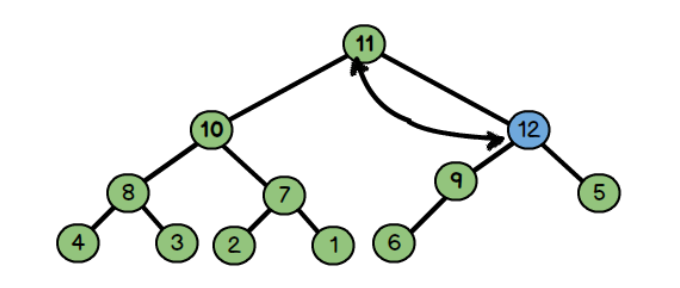
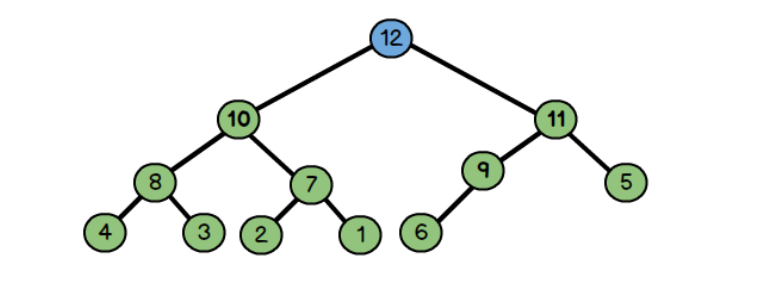
向上调整:
- 如果到达了根节点就停止
- 如果满足了大根堆性质:
data[index/2]>data[index]停止 - 不满足的话,就交换data[index/2]和data[index],然后index=index/2,继续调整
删除
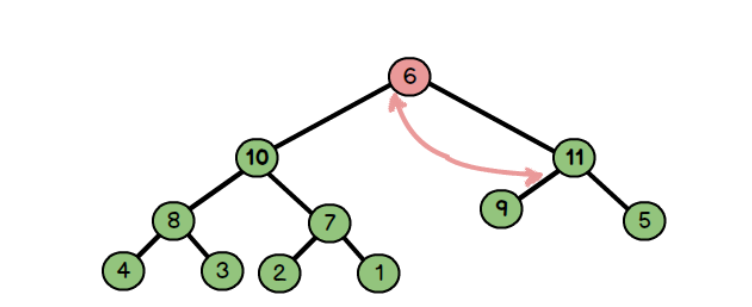
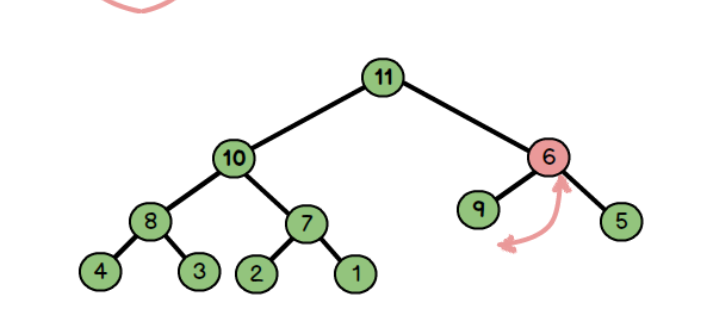
这里只有最大值最小值有意义,所以删除这里规定只删除根节点
向下调整:
- 首先把尾部结点放置到根节点位置
- 然后进行向下调整,每次比较该结点和左右孩子的大小
尾部6替换根12
6和max(10,11)交换
6和max(9,5)交换
最终结果


代码实现
入堆
// 入堆的向上调整,给出尾部索引
void shiftUp(int index){
// index父节点索引:index/2
int val = data[index];
for (; index > 1 && data[index / 2] < val; index /= 2)
{
data[index] = data[index / 2]; // 子=父
}
data[index] = val;
}
// 入堆
void enHeap(const int &x)
{
data[++cursize] = x; // 插入尾部,从1开始存储
shiftUp(cursize);
}
出堆
// 出堆的向下调整,根索引为1
void shiftDown(int index = 1){
int val = data[index];//赋值
// 左孩子是必须存在的
while(index * 2 <= cursize){
// p是index的左孩子
int p = index * 2;
// 右孩子存在,且右孩子最大,p指向右孩子
if ((p + 1) <= cursize && data[p] < data[p + 1])
p += 1;
// 判断根和data[p]
if (val < data[p])//采用交换才是data[k]
data[index] = data[p];
else{
break;
}
//更新index
index = p;
}//while
data[index] = val;//赋值
}
// 出堆
int deHeap(){ // 根节点出堆
int x = data[1];
data[1] = data[cursize--];
shiftDown();
return x;
}
完整代码:
#include <iostream>
using namespace std;
class maxHeap{
public:
// 构造函数
maxHeap(int n){
data = new int[n];
cursize = 0;
}
// 入堆
void enHeap(const int &x){
data[++cursize] = x; // 插入尾部,从1开始存储
shiftUp(cursize);
}
// 出堆
int deHeap(){ // 根节点出堆
int x = data[1];
data[1] = data[cursize--];
shiftDown();
return x;
}
// 输出
void visit(){
for (int i = 1; i <= cursize; i++)
{
cout << data[i] << " ";
}
cout << endl;
}
private:
int *data;
int cursize;
// 入堆的向上调整,给出尾部索引
void shiftUp(int index){
// index父节点索引:index/2
int val = data[index];
for (; index > 1 && data[index / 2] < val; index /= 2)
{
data[index] = data[index / 2]; // 子=父
}
data[index] = val;
}
// 出堆的向下调整,根索引为1
void shiftDown(int index = 1)
{
int val = data[index];//默认是根,可以指定索引
// 左孩子是必须存在的
while(index * 2 <= cursize){
// p是index的左孩子
int p = index * 2;
// 右孩子存在,且右孩子最大,p指向右孩子
if ((p + 1) <= cursize && data[p] < data[p + 1])
p += 1;
// 判断根和data[p]
if (val < data[p])
data[index] = data[p];
else
break;
//更新index
index = p;
}//while
data[index] = val;
}
};
int main(){
maxHeap hp(20);
int arr[10] = {129, 833, 55, 67, 1233, 495, 910, 2, 132, 77};
for (int i = 0; i < 10;i++){
hp.enHeap(arr[i]);
}
//hp.visit();
for (int i = 0; i < 10;i++){
cout<<hp.deHeap()<<" ";
}
return 0;
}
还可以定义数组的构造函数
最后从每一个非叶子节点(父节点)挨个出发,进行向下调整,此时下标不一定是根
// 用数组构造二叉堆
maxHeap(int a[], int n){
data = new int[n + 1];
cursize = n;
for (int i = 1; i <= n; i++){
data[i] = a[i - 1];
}
for (int j = n / 2; j >= 1; j--){ // 根节点也要进行,堆为1
shiftDown(j);
}
}
程序测试:
int arr[10] = {129, 833, 55, 67, 1233, 495, 910, 2, 132, 77};
maxHeap hp(arr, 10);
插入和删除的递归写法
向上调整递归
void shiftUP(int k){
//到达根节点结束递归
if(k<=1) return;
if(data[k/2]<data[k]){//父节点小于子节点
swap(data[k / 2], data[k]);
shiftUP(k / 2);
}
}
向下调整递归1
//向下调整
void shiftDown(int k){
if(k*2>cursize)
return;
int p = k * 2;
if(p+1<=cursize && data[p+1]>data[p])
p += 1;
if(data[k]<data[p]){
swap(data[k], data[p]);
shiftDown(p);
}
}
向下调整递归2
//删除1
void shiftDown(int k){
int p = k;
//左孩子存在且比根大,根指向左孩子
if(p*2<=cursize && data[p*2]>data[k])
k = p * 2;
//右孩子存在且比max(根,左孩子)大,更新右孩子
if(p*2+1<=cursize && data[p*2+1]>data[k])
k = p * 2 + 1;
if(p==k)//根没有左右孩子
return;
swap(data[k], data[p]);
shiftDown(k);//注意传入更新后
}
堆排序
对数组进行原地调整大顶堆,然后把堆顶移到最后,使得数据从小到大输出
void shiftDown(int a[],int n,int k){
while(k*2+1<n){
int p = k * 2 + 1;
//<=n-1
if(p+1<n && a[p+1]>a[p])
p += 1;
if(a[k]<a[p])
swap(a[k], a[p]);
else
break;
k = p;
}
}
void heapSort(int a[],int n){
//从非叶子结点逐个向上调整,索引为0
//n-1的父节点是:[(n-1)-1]/2
for (int i = (n - 2) / 2; i >= 0;i--){
shiftDown(a,n,i);
}
//从小到达输出,每次把根a[0]移动到最后
for (int i = n - 1; i > 0;i--){
swap(a[0], a[i]);
shiftDown(a,i,0);
}
}
这里就是原地堆排序的局部:
-
首先把原数组变成堆结构,然后nums[0]对应最大值
-
i=n-1,交换nums[0]和nums[i],然后堆结构,此时nums[0]是第二大元素
也就是:i=n-2结束后,nums[0]是第三大元素
i=n-k+1结束后,nums[0]是第k大元素,也就是i要取到n-k+1
要注意传入的索引,这里默认n=nums.size(),取不到
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
int n = nums.size();
for (int i = (n - 2) / 2; i >= 0; --i) {
shiftDown(nums, n, i);
}
cout<<n<<endl;
/*i=n-1
nums[0]第二大
i=n-2
nums[0]第三大
i=n-3
nums[0]第四大*/
for (int i = n-1; i >= n- k + 1; --i) {
swap(nums[0], nums[i]);
shiftDown(nums, i, 0); // 必须是i,因为取不到
}
return nums[0];
}
private:
// 大顶堆,从索引k向下调整到n
void shiftDown(vector<int>& nums, int n, int k) {
while (k * 2 + 1 < n) {
int p = k * 2 + 1;
if (p + 1 < n && nums[p + 1] > nums[p])
p += 1;
if (nums[k] < nums[p]) {
swap(nums[k], nums[p]);
} else {
break;
}
// 更新k
k = p;
}
}
};
三:自定义优先队列的比较
priority_queue是包含在头文件#include<queue>中
基本操作:
队列基本操作相同:
top()访问对头元素empty()队列是否为空size()返回队列内元素个数push()插入元素到队尾,并排序emplace()原地构造一个元素并插入队列pop()弹出队头元素swap()交换内容
优先队列定义
priority_queue<Type, Container, Functional>
-
Type是数据类型 -
Container是容器类型,Container必须是用数组实现的容器。STL里默认用vector
vector,dequeue等都可以作为容器类型,但是不能用list。
-
Functional是比较的方式。
自定义排序
重载运算符
大顶堆,重载<(小的沉底)
bool operator <(const student& stu) const{}
必须加const
- 小顶堆我们也只采用重载小于<,但是在函数体内定义>
不管是大顶堆还是小顶堆,我们都会重载<,c++堆的底层实现也是如此
#include <iostream>
#include <string>
#include <queue>
using namespace std;
class student{
public:
string name;
int age;
student(string name,int age):name(name),age(age){}
//大顶堆,重载<(小的沉底)
bool operator <(const student& stu) const{//必须加const
if(name==stu.name){
return age < stu.age;
}
return name < stu.name;//也是<
}
};
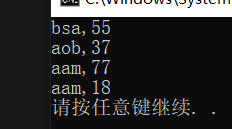
int main(){
student a("aam", 77);
student b("aam", 18);
student c("aob", 37);
student d("bsa", 55);
//对应<
priority_queue<student, vector<student>,less<student> > pq;
pq.push(a);
pq.push(b);
pq.push(c);
pq.push(d);
while(!pq.empty()){
auto [name,age] = pq.top();
cout << name << "," << age << endl;
pq.pop();
}
return 0;
}
#include <iostream>
#include <string>
#include <queue>
using namespace std;
class student{
public:
string name;
int age;
student(string name,int age):name(name),age(age){}
//小顶堆,重载<
bool operator <(const student& stu) const{//必须加const
//但是类内比较用>
return age > stu.age;
}
};
int main(){
student a("aam", 77);
student b("aam", 18);
student c("aob", 37);
student d("bsa", 55);
//对应<
priority_queue<student, vector<student>,less<student> >pq;
pq.push(a);
pq.push(b);
pq.push(c);
pq.push(d);
while(!pq.empty()){
auto [name,age] =pq.top();
cout << name << "," << age << endl;
pq.pop();
}
return 0;
}

仿函数
struct cmp1{
bool operator ()() { }
};
class cmp2{
public:
bool operator ()() { }
};
#include <iostream>
#include <string>
#include <queue>
using namespace std;
class student{
public:
string name;
int age;
student(string name,int age):name(name),age(age){}
//大顶堆,重载<(小的沉底)
};
//struct 类
struct cmp1{
bool operator ()(const student& a,const student& b) {
return a.age > b.age;
}
};
class cmp2{
public:
bool operator ()(const student& a,const student& b) {
return a.name < b.name;
}
};
int main(){
student a("aam", 77);
student b("aam", 18);
student c("aob", 37);
student d("bsa", 55);
//传入类名
priority_queue<student, vector<student>, cmp1> pq1;
pq1.push(a);
pq1.push(b);
pq1.push(c);
pq1.push(d);
while(!pq1.empty()){
auto [name,age] = pq1.top();
cout << name << "," << age << endl;
pq1.pop();
}
priority_queue<student, vector<student>, cmp2> pq2;
pq2.push(a);
pq2.push(b);
pq2.push(c);
pq2.push(d);
while(!pq2.empty()){
auto [name,age] = pq2.top();
cout << name << "," << age << endl;
pq2.pop();
}
return 0;
}
普通函数
decltype()是用于获得函数指针的类型的。在模板中也要传入它们的类型。decltype()要传入的是一个对象的地址,因此需要对函数名加取值符,&函数名为对象的地址
priority_queue<student, vector<student>, decltype(&cmp1)> pq1(cmp1);
#include <iostream>
#include <string>
#include <queue>
using namespace std;
class student{
public:
string name;
int age;
student(string name,int age):name(name),age(age){}
//大顶堆,重载<(小的沉底)
};
bool cmp1(const student& a,const student& b) {
return a.age > b.age;
}
bool cmp2(const student& a,const student& b) {
return a.name < b.name;
}
int main(){
student a("aam", 77);
student b("aam", 18);
student c("aob", 37);
student d("bsa", 55);
//传入类名
priority_queue<student, vector<student>, decltype(&cmp1)> pq1(cmp1);
pq1.push(a);
pq1.push(b);
pq1.push(c);
pq1.push(d);
while(!pq1.empty()){
auto [name,age] = pq1.top();
cout << name << "," << age << endl;
pq1.pop();
}
priority_queue<student, vector<student>, decltype(&cmp2)> pq2(cmp2);
pq2.push(a);
pq2.push(b);
pq2.push(c);
pq2.push(d);
while(!pq2.empty()){
auto [name,age] = pq2.top();
cout << name << "," << age << endl;
pq2.pop();
}
return 0;
}
lamdba形式
auto cmp1 = [](const student &a, const student &b) -> bool {
return a.age > b.age;
};
//传对象,所以lambda不需要&
priority_queue<student, vector<student>, decltype(cmp1)> pq1(cmp1);
#include <iostream>
#include <string>
#include <queue>
using namespace std;
class student{
public:
string name;
int age;
student(string name,int age):name(name),age(age){}
//大顶堆,重载<(小的沉底)
};
int main(){
student a("aam", 77);
student b("aam", 18);
student c("aob", 37);
student d("bsa", 55);
//传入类名
auto cmp1 = [](const student &a, const student &b) -> bool
{
return a.age > b.age;
};
priority_queue<student, vector<student>, decltype(cmp1)> pq1(cmp1);
pq1.push(a);
pq1.push(b);
pq1.push(c);
pq1.push(d);
while(!pq1.empty()){
auto [name,age] = pq1.top();
cout << name << "," << age << endl;
pq1.pop();
}
auto cmp2 = [](const student &a, const student &b) -> bool
{
return a.name < b.name;
};
priority_queue<student, vector<student>, decltype(cmp2)> pq2(cmp2);
pq2.push(a);
pq2.push(b);
pq2.push(c);
pq2.push(d);
while(!pq2.empty()){
auto [name,age] = pq2.top();
cout << name << "," << age << endl;
pq2.pop();
}
return 0;
}
四:堆的习题
1:合并升序链表
思路一:
遍历这K个链表,把指针加入堆中,然后堆元素出队来创建链表
- 小顶堆+尾插法
ListNode* mergeKLists(vector<ListNode*>& lists) {
//lambda表达式
auto cmp=[](const ListNode* a,const ListNode* b)->bool{
return a->val > b->val;//小顶堆
};
priority_queue<ListNode*,vector<ListNode*>,decltype(cmp)> pq(cmp);
//把lists所有元素装入小顶堆中
for(auto aa:lists){
while(aa){
pq.push(aa);
aa=aa->next;
}
}
//对小顶堆进行尾插法
ListNode* dummyHead=new ListNode(-1);//虚拟头节点
ListNode* p=dummyHead;
while(!pq.empty()){
ListNode* cur=new ListNode(pq.top()->val);
pq.pop();//出堆
p->next=cur;
p=cur;
}
return dummyHead->next;
}
- 大顶堆+头插法
ListNode* mergeKLists(vector<ListNode*>& lists) {
//lambda表达式
auto cmp=[](const ListNode* a,const ListNode* b)->bool{
return a->val < b->val;//大顶堆
};
priority_queue<ListNode*,vector<ListNode*>,decltype(cmp)> pq(cmp);
//把lists所有元素装入小顶堆中
for(auto aa:lists){
while(aa){
pq.push(aa);
aa=aa->next;
}
}
//对大顶堆进行头插法
ListNode* dummyHead=new ListNode(-1);//虚拟头节点
while(!pq.empty()){
ListNode* cur=new ListNode(pq.top()->val);
pq.pop();//出堆
cur->next=dummyHead->next;
dummyHead->next=cur;
}
return dummyHead->next;
}
当然可以把头插法用一句话描述
while(!pq.empty()){ dummyHead->next=new ListNode(pq.top()->val,dummyHead->next); pq.pop();//出堆 }
- 创建结点时,直接让其next指针指向虚拟头结点的next指向
- 然后把虚拟头节点指向指向新结点
也可以用普通函数,只不过有时候需要加上static关键字,而且取地址要加上&
static bool cmp(const ListNode* a,const ListNode* b){//有static return a->val < b->val;//大顶堆 } ListNode* mergeKLists(vector<ListNode*>& lists) { //... priority_queue<ListNode*,vector<ListNode*>,decltype(&cmp)> pq(cmp); //... }
用仿函数重载()形式
struct cmp { bool operator()(const ListNode* a, const ListNode* b) { return a->val < b->val; // 大顶堆 } }; ListNode* mergeKLists(vector<ListNode*>& lists) { //... priority_queue<ListNode*, vector<ListNode*>, cmp> pq;//无() //... }
思路二:
只将链表第一个结点装入队列,然后每次取最小,然后把移动的最小的指针后移。控制成链。
ListNode* mergeKLists(vector<ListNode*>& lists) {
auto cmp=[](const ListNode* a,const ListNode* b){
return a->val>b->val;//小顶堆
};//lambda表达式需要有;
priority_queue<ListNode*,vector<ListNode*>,decltype(cmp)> pq(cmp);
for(auto head:lists){
if(head) //必须存在
pq.push(head);
}
ListNode* dummyhead=new ListNode(-1);
ListNode* cur=dummyhead;
while(!pq.empty()){
auto tmp=pq.top();
pq.pop();
//尾插法
cur->next=tmp;
cur=tmp;
//类比左右孩子,取出的链下一个结点存在就更新
if(tmp->next){
pq.push(tmp->next);
}
}
return dummyhead->next;
}
虚拟头节点可以不用指针
ListNode dummyhead; ListNode* cur=&dummyhead; //... return dummyhead.next;
不可以用大顶堆+尾插,因为此时堆中最大值是局部最大
加入头节点必须判断是否为NULL
for(auto head:lists){ if(head) //必须存在 pq.push(head); }
2:k个高频单词
思路很简单:
-
首先用map统计频次,
map[string]=int -
用堆记录频次,装入
<int,string>pair对因为要求int排序,同时还有字母排序,所以需要自定义堆排序比较函数
-
最后:把堆的前k个string结果返回即可
vector<string> topKFrequent(vector<string>& words, int k) {
//利用map统计频次
unordered_map<string,int> mp;
for(auto val:words){
mp[val]++;
}
//利用堆输出前k个
using pr=pair<int,string>;
//lambda
auto cmp=[](const pr& a,const pr& b)->bool{
if(a.first==b.first){
return a.second>b.second;//字典排序,小顶堆
}
return a.first<b.first;//大顶堆
};
priority_queue<pr,vector<pr>,decltype(cmp)> pq(cmp);
for(auto& [k,v]:mp){
pq.push({v,k});
}
//输出结果
vector<string> res;
while(k--){
res.push_back(pq.top().second);
pq.pop();
}
return res;
}
还可以用伪函数,注意public
class Solution { public: using pr = pair<int, string>; class cmp { public://别忘了public bool operator()(const pr& a, const pr& b) { if (a.first == b.first) { return a.second > b.second; // 字典排序,小顶堆 } return a.first < b.first; // 大顶堆 } }; vector<string> topKFrequent(vector<string>& words, int k) { //... priority_queue<pr, vector<pr>, cmp> pq; for (auto& [k, v] : mp) { pq.push({v, k}); } //... } };
map和multimap
multimap在底层用二叉搜索树(红黑树)来实现:
在内部,multimap中的元素总是通过其内部比较对象,按照指定的特定
严格弱排序标准对key进行排序的。
map要求key不同,但是multimap中key可以相同,但是不同key之间有顺序
注意:unordered_map是哈希表实现的,所以不同key之间无顺序
例子:
//严格字母排序,降序 map<string,int> mp1; //key之间无序 unordered_map<string,int> mp2; for(auto val:words){ mp1[val]++; mp2[val]++; } for(auto& [k,v]:mp1){ cout<<k<<","<<v<<endl; } cout<<"****"<<endl; for(auto& [k,v]:mp2){ cout<<k<<","<<v<<endl; }
发现map中key按字母排序了
所以还可以给map指定第三个参数,但是unordered_map指定会报错
//严格字母排序,升序 map<string,int,greater<string>> mp;//指定了greater for(auto val:words){ mp[val]++; } for(auto& [k,v]:mp){ cout<<k<<","<<v<<endl; }


本题可以用map对string严格字母排序,再利用multimap对int严格降序(int 可以相同用multimap)
解答:
vector<string> topKFrequent(vector<string>& words, int k) {
vector<string> res;
//严格字母排序,升序
map<string,int> mp;
for(auto val:words){
mp[val]++;
}
//用multimap,int降序
multimap<int,string,greater<int>> mmp;
for(auto [k,v]:mp){
mmp.insert({v,k});
}
//输出mmp前k个结果
auto it=mmp.begin();
while(k--){
res.push_back(it->second);
it++;
}
return res;
}
3:滑动窗口
把元素加入堆可以快速得到最大值,但是堆不支持任意元素的删除,所以何时知道最大值“过时”是关键
解决:存入堆的时候顺便存数组的下标,如果堆顶元素的下标和当前要存放值的下标大于k就说明:堆顶过时了
这个思路和单调队列很像,只有堆顶元素过时了才弹出

vector<int> maxSlidingWindow(vector<int>& nums, int k) {
vector<int> ans;
// 堆存放:元素值和数组下标
priority_queue<pair<int, int>> pq;
// 首先存放前k个元素
for (int i = 0; i < k; i++)
pq.push({nums[i], i});
ans.push_back(pq.top().first);
// 从k开始需要判断元素过时
for (int i = k ; i < nums.size(); i++) {
pq.push({nums[i],i});
//判断过时
while(i-pq.top().second+1>k){
pq.pop();
}
ans.push_back(pq.top().first);
}
return ans;
}
可以合并,只有i>=k时,ans才记录
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
vector<int> ans;
// 堆存放:元素值和数组下标
priority_queue<pair<int, int>> pq;
for (int i = 0; i < nums.size(); i++) {
pq.push({nums[i], i});
// 判断过时
while (i - pq.top().second + 1 > k) {
pq.pop();
}
//i=k-1才塞满了窗口
if (i >= k-1)
ans.push_back(pq.top().first);
}
return ans;
}














 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









