






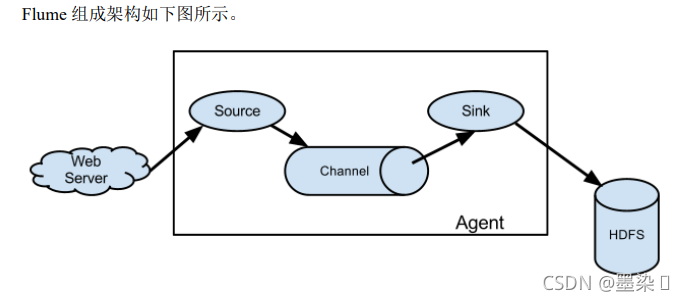
flume基本架构
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。
为什么要用flume,put也可以把日志上传到hdfs:
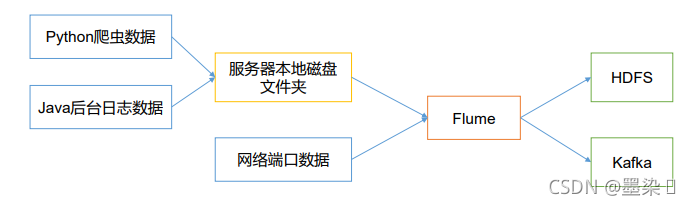
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS
Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的 Agent 由三部分组成:source,sink,channel
Source
其实就是用于接收数据到Agent的组件,接收来自不同数据源的数据
Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent
Channel
Channel是位于Source和Sink之间的缓冲组件,如果没有缓冲区,Source接收数据的速度和Sink上传数据到Hdfs的速度不一致,导致系统崩掉
因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source
的写入操作和几个Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
Event
当Source接收数据的时候,会将接收的数据封装成一个Event,也就是序列化,在Sink会解析
Event 由 Header 和 Body 两部分组成,Header 用来存放该 event 的一些属性,为 K-V 结构,Body 用来存放该条数据,形式为字节数组

SpoolingDirSource(监控一个目录)
- SpoolingDirSource指定本地磁盘的一个目录为"Spooling(自动收集)"的目录!这个source可以读取目录中新增的文件,将文件的内容封装为event!
- SpoolingDirSource在读取一整个文件到channel之后,它会采取策略,要么删除文件(是否可以删除取决于配置),要么对文件进程一个完成状态的重命名,这样可以保证source持续监控新的文件!
- SpoolingDirSource和execsource不同,SpoolingDirSource是可靠的!即使flume被杀死或重启,依然不丢数据!但是为了保证这个特性,付出的代价是,一旦flume发现以下两种情况,flume就会报错,停止:
①一个文件已经被放入目录,在采集文件时,不能被修改
②文件的名在放入目录后又被重新使用(出现了重名的文件)
要求:
必须已经封闭的文件才能放入到SpoolingDirSource,在同一个SpoolingDirSource中都不能出现重名的文件!
TailDirSource(监控多个文件目录中的多个文本文件)
- TailDirSource采集的文件,不能随意重命名!如果日志在正在写入时,名称为 xxxx.tmp,写入完成后,滚动,改名为xxx.log,此时一旦匹配规则可以匹配上述名称,就会发生数据的重复采集!
- Taildir Source 可以读取多个文件最新追加写入的内容!
- Taildir Source是可靠的,即使flume出现了故障或挂掉
- Taildir Source在工作时,会将读取文件的最后的位置记录在一个json文件中,一旦agent重启,会从之前已经记录的位置,继续执行tail操作
很重要!!!!
在taildirsource中 如果已经上传到hdfs的文件修改了文件名 会重新上传 换个场景 如果是监听hive.log 在凌晨会修改名称 flume就会重新上传这个文件 导致hdfs上的数据重复 因此要去修改源码中的updatepoi 和 reliabletaildireventreader 中判断inode和 absolute路径的条件修改为只判断inode的位置就可以 结果会变成修改文件名不会重新上传文件 修改文件内容不会将之前的数据重新追加上传 而是只更新最新增加的数据
事务
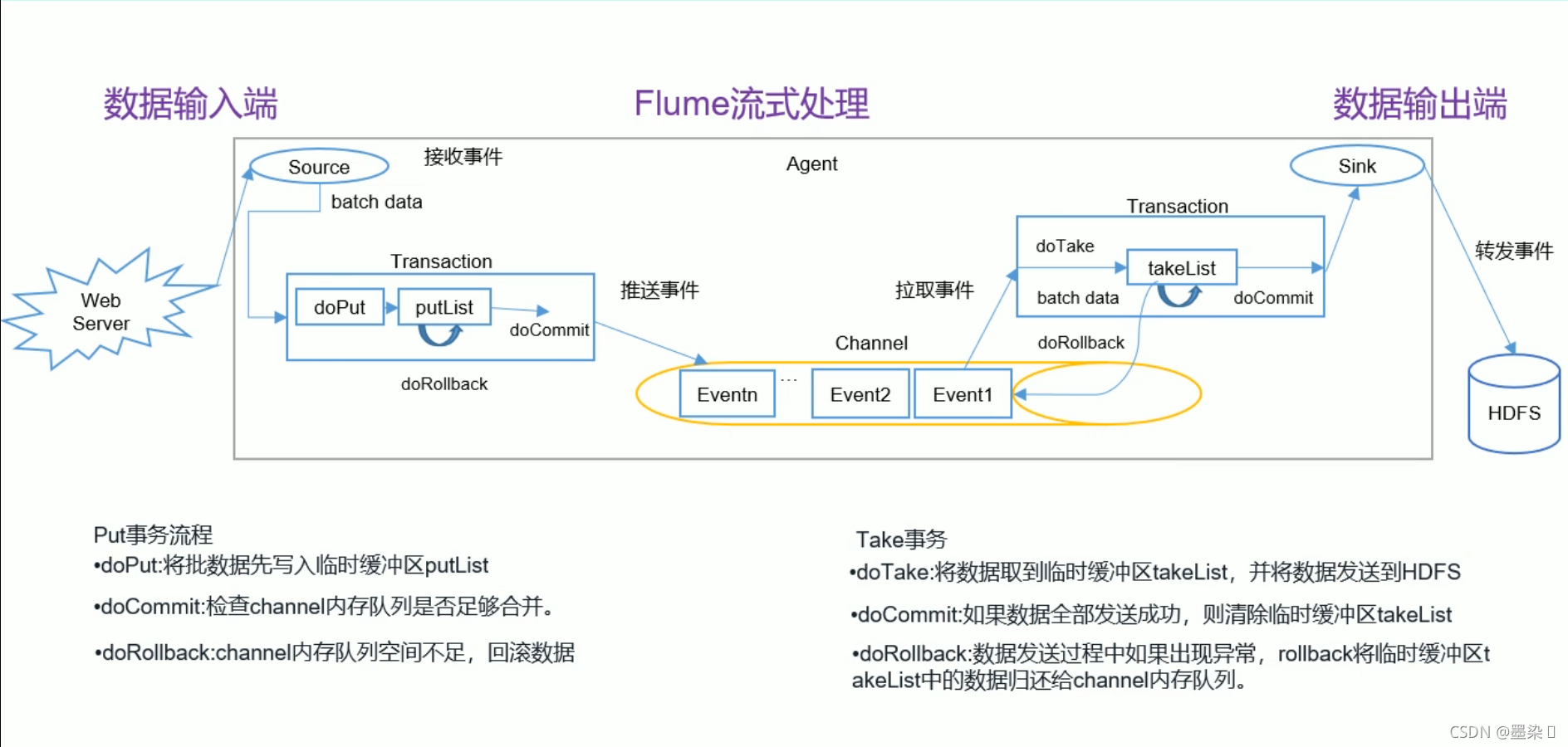
分为两个事务:Put和Take
source接收到数据后,doput会这一批数据暂存到缓冲区putlist中,docommit会检查channel内存队列中是否能够合并数据,如果不能的话,dorollback会将数据回滚到putlist中
因为sink是主动去拉去数据的,dotake会将数据从channel中拉取到takelist中,如果数据能够完整拉取,那么docommit会将takelist中的数据清除,如果拉取过程发生异常,那么dorollback会将takelist中的数据回滚到channel内存队列中















 3784
3784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









