







调度策略
Linux的5种调度的策略:
- stop_sched_class
- dl_sched_class(deadline)
- rt_sched_class(realtime)
- fair_sched_class(CFS)
- idle_sched_class
5种调度的策略通过next指针连接。优先级递减。
stop_sched_class-> dl_sched_class-> rt_sched_class-> fair_sched_class->idle_sched_class
用户空间可以通过sched_setscheduler来设定用户进程的调度策略:
- SCHED_NORMAL(CFS)
- SCHED_FIFO(realtime)
- SCHED_RR(realtime)
- SCHED_BATCH(CFS)
- SCHED_IDLE(idle)
- SCHED_DEADLINE(deadline)
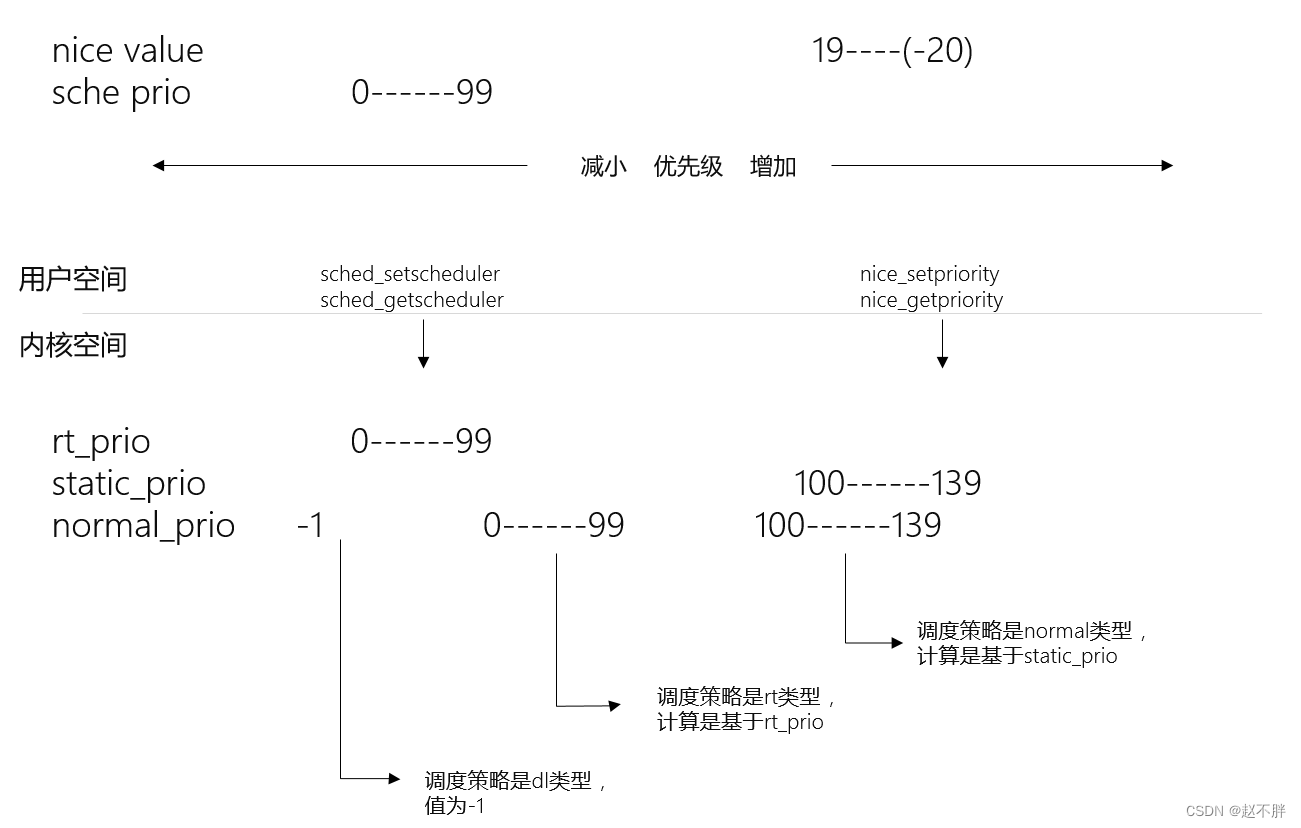
Linux 进程优先级
Struct task_struct{
……
int prio;
int static_prio; //静态优先级
int normal_prio;//动态优先级
unsigned int rt_priority; //realtime进程的优先级
……
}
优先级描述如下图
进程权重的计算
struct load_weight{
unsigned long weight;
U32 inv_weight;
}
struct sched_entity{
……
struct load_weight load;
……
}
转换公式如下:
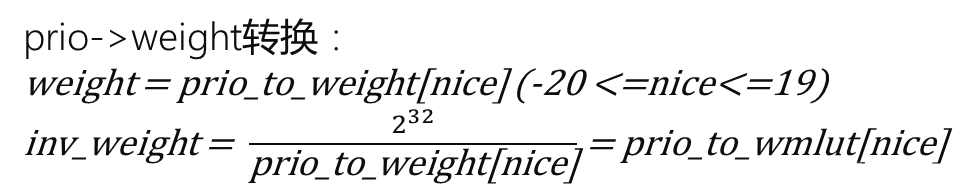
为了避免做除法,简化成为当前表格

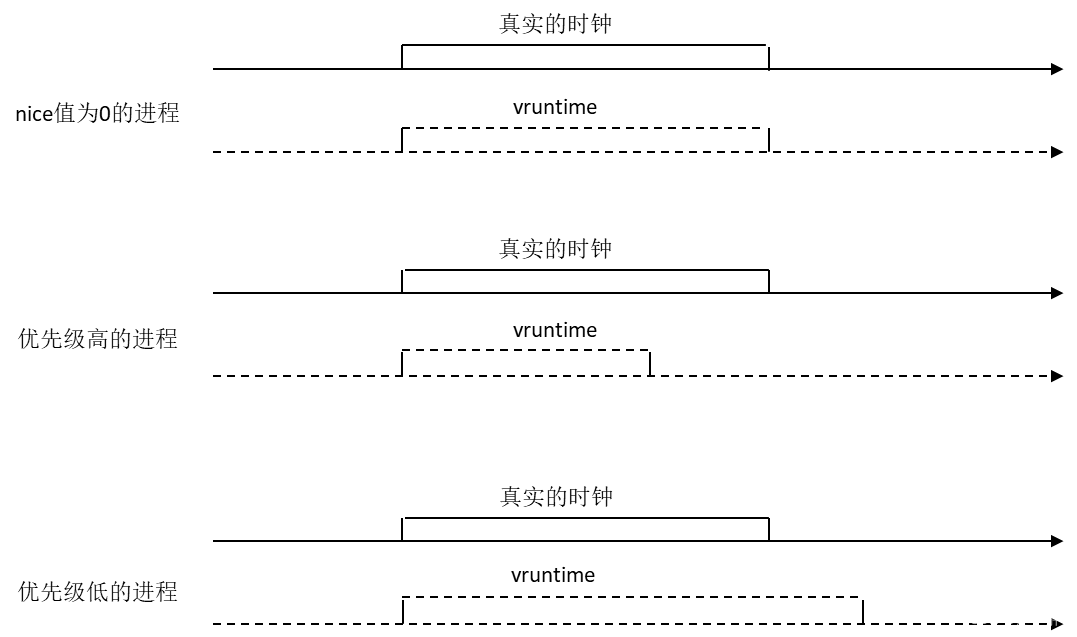
vruntime的计算:

vruntime和真实时钟的对比:
负载的计算
struct sched_avg{
u32 runnable_avg_sum; runnable_avg_period;
u64 last_runnable_update;
s64 decay_count;
unsigned long load_avg_contrib;
}
struct sched_entity{
……
struct sched_avg avg;
……
}
sched_avg用于描述进程负载,其中:
runnable_avg_sum:调度实体在就绪队列里可运行状态下的衰减累加时间。
runnable_avg_period:调度实体在系统中总的衰减累加时间。
load_avg_contrib:进程平均负载的贡献度。
另外cfs_rq数据结构中runnable_load_avg用于累加在该就绪队列上所有的调度实体的load_avg_contrib的总和。
我们把1ms—1024us当成一个周期PI,统计多个PI周期,并使用一个衰减系数来计算PI周期对负载的贡献,一个调度实体的负载总合计算公式如下:
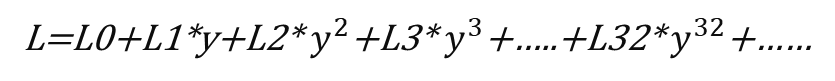
其中y代表衰减系数,Li代表在第i个周期的负载贡献。

为了方便求和计算内核又维护了个新表runnable_avg_yN_sum[]
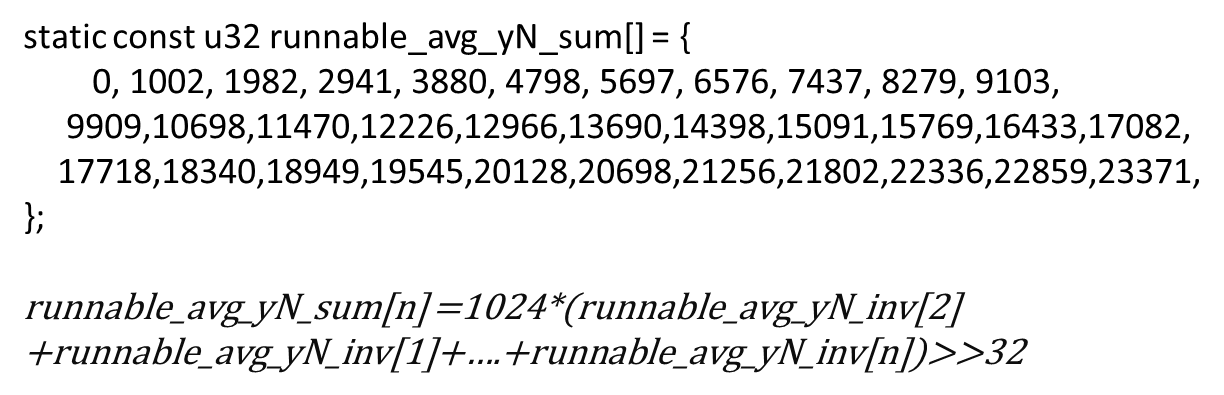
选择乘以1024的原因?
- runnable_avg_yN_inv[]不是整数,乘以1024 后取整?
- 负载计算的函数对于微秒到毫秒的计算是除1024的,为了补差?
下面来看两个函数
decay_load --计算第n个周期的衰减值。
__compute_runnablre_contrib –计算连续n个PI周期的负载累计贡献值
decay_load函数的实现
参数val为n个周期前的负载值,n表示第n个周期,计算公式如下:
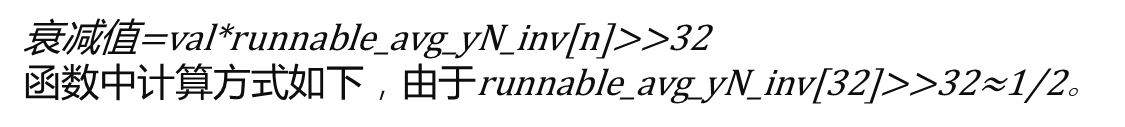
周期n<32

周期32<n<2016(32*63)
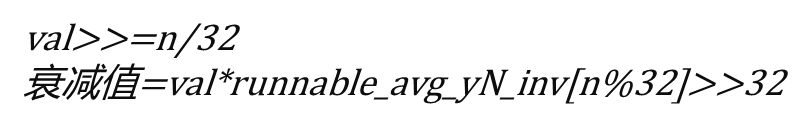
周期n>2016(32*63)
直接等于0,忽略不计
__compute_runnable_contrib 函数的实现
唯一的参数n表示连续n个周期
周期n<=32

周期32<n<345,那么n=32x+y(x,y都是整数,且y<32)
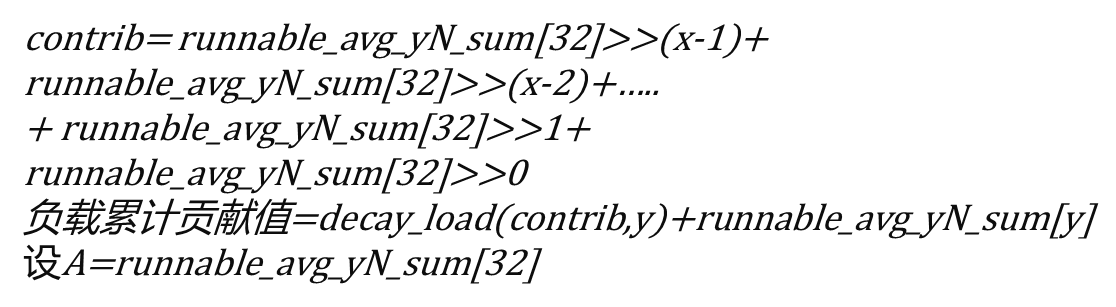
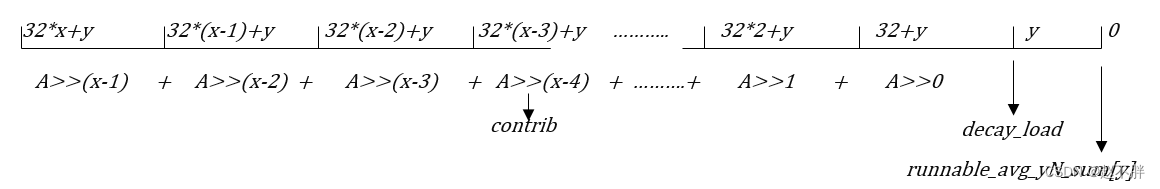
周期n>=345
负载累计贡献值为极限值LOAD_AVG_MAX(47742)
负载的计算方法
函数_update_entity_runnable_avg(),示意图如下。

首先用now-sa->last_runnable_avg并右移10位得到需要计算的时间delta(us)
sa->runnable_avg_period%1024为T0。
判断delta+T0是否大于等于1024us
大于等于(统计的时间一个周期以上) :
1024-T0得到T1,sa->runnable_avg_period +=T1,如果
se->on_rq大于0,sa->runnable_avg_sum+=T1。
(detla-T1)/1024得到周期periods。 (detla-T1)%1024得到T2
分别decay_load, sa->runnable_avg_sum和sa->runnable_avg_period
通过__compute_runnable_contrib计算得出runnable_contrib
sa->runnable_avg_period +=runnable_contrib,如果se-> on_rq大于0,sa->runnable_avg_sum+=runnable_contrib
最后sa->runnable_avg_period +=T2,如果se-> on_rq大于0,sa->runnable_avg_sum+=T2
小于(统计的时间不足一个周期):
sa->runnable_avg_period +=delta,如果se-> on_rq大于0,sa->runnable_avg_sum+= delta
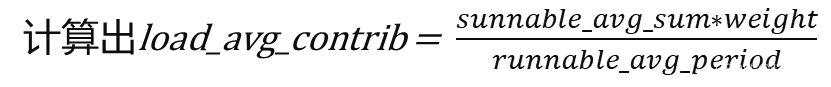
进程创建
每个调度类都定义了操作方法集
const struct sched_class fair_sched_class{
.next = &idle_sched_class ;
.enqueue = enqueue_task_fair;
.dequeue = dequeue_task_fair;
.pick_next_task = pick_next_task_fair;
……
.task_fork = task_fork_fair;
.switched_to = switch_to_fair;
.update_curr = update_curr_fair;
…..
}
do-fork->sched_fork->fair_sched_class.task_fork—task_fork_fair
1.通过update_curr更新当前进程(父进程)的vruntime,以及该CFS就绪队列min_vruntime.
-2.调用place_entity函数,计算vruntime,并且对新fork的进程vruntime做惩罚,计算调度周期的长度period,计算当前进程在CFS就绪队列中可以瓜分到的时间slice。
- period,默认值是sysctl_sched_latency(6ms)如果cfs_rq上的进程数大于nr_latency(8),周期的长度等于cfs_rq上的进程数*sysctal_sched_min_granularity(0.75ms).
- slice等于periodse->load.weightcfs_rq->load.inv_weight>>32
- 惩罚时间等于slicenice_0_weightse->load.inv_weight>>32 。新进程的se->vruntrum=max((父进程)的vruntime, vruntime做惩罚时间+cfs_rq->min_vruntime)。
do-fork->wake_up_new_task
1.首先通过select_task_rq选择调度域中最悠闲的cpu,并绑定到该task。
2.其次通过调用fair_sched_class的enqueue_task_fair
- enqueue_entity将进程添加到CFS就绪队列的红黑树中。
- update_entity_load_avg更新调度实体的负载load_avg_contirb和CFS就绪队列的负载runnable_load_avg
进程调度
__schedule是调度器的核心函数
让调度器选择切换到一个合适的进程运行,调度的时机有以下几种
1.阻塞操作
2.在中端返回前和系统调用返回用户空间时,去检查TIF_NEED_RESCHED标志位,以判断是否需要调度。
3.将要被唤醒的进程,不会马上调用schedule要求被调度,而是添加到CFS就绪队列中,并且设置TIF_NEED_RESCHED标志位。唤醒的进程什么时候被调度呢,这要根据内核是否有可抢占功能(CONFIG_PREEMPT=y)分为两种情况。
内核可抢占:
- 如果唤醒动作发生在系统调用或异常处理上下文中,在下一次调用 preempt_enable时会检查是否需要抢占调度。
- 如果唤醒动作发生在硬中断处理上下文中,硬中断处理返回前夕会检查是否需要抢占当前进程。
内核不可抢占:
- 当前进程调用cond_resched时会检查是否需要调度。
- 主动调度调用schedule。
- 系统调用或者异常处理返回用户空间时。
- 中断处理完成返回用户空间的时候
__schedule函数
pick_nest_task让调度器从就绪队列中找到下一个合适的进程。
各个调度策略优先级如下:
stop_sched_class>dl_sched_class(deadline)>rt_sched_class(realtime)>fair_sched_class(CFS)>idle_sched_class
其中如果进程中都为普通进程CFS,那么会选择就绪队列CFS中红黑树最左边的进程。
如果就绪队列上没有进程就选择idle。
通过context_switch切换到下一个进程运行。
- 根据task_struct->mm_struct判断是否是内核线程,内核线程需要借用prev线程的active_mm地址空间。用户线程要switch_mm,切换进程地址空间。
- 调用switch_to函数切换进程。
switch_mm函数的实质是把新的进程的页表地址设置到页表目录基地址寄存器中。
当一个prev进程运行时,cpu内部的TLB和cache会缓存prev进程的数据,如果进程切换到next进程时没有flush prev进程的数据,那么可能导致TLB和cache缓存了prev进程的数据,可能导致next进程访问的虚拟地址被翻译成prev缓存的数据,造成数据的不一致且系统不稳定。因此进程切换的时候,需要对TLB进行flush操作。但是这种方法很粗鲁,对整个TLB进行flush操作后,next进程面对一个空白的TLB,,因此开始执行的时候会出现很严重的TLB miss 和cache miss,导致性能下降。
如何提高TLB性能?
TLB分为gobal和process_specific
- gobal类型的TLB:内核空间 (防止内核窥探,这块方案有变化)
- process_specific类型的TLB:用户地址空间是每个进程独立的地址空间。
prev进程地址切换到next进程时,TLB中缓存的prev进程的相关数据的TLB对于next进程是无用的,因此可以flush掉,这就是所谓的process_specific。
为了支持process_specific类型的TLB,ARM体系结构提出了一种硬件的解决方案ASID。
ASID让每个TLB entry包含一个ASID号,ASID号用于每个进程分配标识进程地址空间。
TLB命令中查询条件的标准由原来的虚拟地址判断加上ASID条件,因此有ASID硬件的支持进程的切换不需要flush TLB。
- 硬件ASID:指放在CONTEXTIDR寄存器的低8位的硬件ASID号。
- 软件ASID:这个是ARM linux软件的概念,存放在进程的mm->context.id中,它包括两个域,低8位是硬件的ASID,剩余的比特位是软件的generation数。
switch_mm->check_and_switch_context.
- 读取mm->context.id中的值
- 软件generation相同,说明进程的ASID属于一个批次。直接跳转到cpu_switch_mm进行地址的切换。
- 如果generation计数不相同,说明至少发生一次ASID硬件溢出,需要通过new_context函数重新分配一个新的软件ASID,并设置到mm->context.id中。之后flush all TLB.
cpu_switch_mm(mm->pgd,mm);
会设置页表基地址TTB(Translation Table Base)寄存器之外,还会设置硬件ASID,把进程mm->context.id存储的硬件设置到CONTEXTIDR寄存器的低8位。
switch_to函数
将当前ARM寄存器信息保存在prev相应的thread_info->cpu_context_save结构体中,并将next的thread_info-> cpu_context_save信息保存在ARM寄存器中,从而完成进程的上下文切换。
Schedule_tick
check_preempt_tick
1.实际运行时间大于理论运行时间,设置该进程中的thread_info中的TIF_NEED_RESCHED标志位。
2.实际运行时间小于sysctl_sched_min_gromularity(0.75ms),也不需要调度。
3.该进程的vruntime和就绪队列红黑树最左边的调度实体的vruntime比较,如果差值大于该进程的理论运行时间会设置该进程中的thread_info中的TIF_NEED_RESCHED标志位。
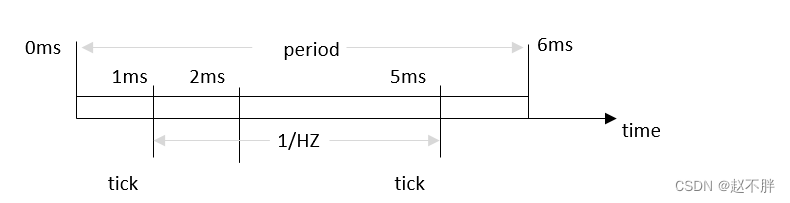
如果有三个进程A,B,C。nice值均为0,在一个调度周期内瓜分的时间为6ms/3=2ms,假设1ms的时候发生一次tick,那么下一次tick的时间为1ms +4ms=5ms,假设A进程在0ms开始运行,那么A的运行时间如图。1ms的时候第一次tick进程A分得的时间还没有用完,继续运行。2ms的时候,A分得的时间用完了,但是没有tick,继续运行。5ms的时候,第二次tick,进程A被标记成need sched。
总结
1.每个CPU有一个通用就绪队列struct rq
2.每个进程task_struct中内嵌一个调度实体struct sched_entity 结构体。
3.每个通用就绪队列数据结构中内嵌CFS就绪队列,RT就绪队列和 Deadline就绪队列结构体。
4.每个调度实体se内嵌一个权重struct load_weight结构体。
5.每个调度实体se内嵌一个平均负载struct sched_av结构体。
6.每个调度实体se有一个vruntime成员表示调度实体的虚拟时钟。
7.每个调度实体se有一个on_rq成员表示该调度实体是否在就绪队列中接受调度。
8.每个CFS就绪队列中内嵌一个权重struct load_weight结构体。
9.每个CFS就绪队列中有一个min_vruntime来跟踪该队列红黑树中最小的vruntime值。
10.每个CFS就绪队列有一个runnable_load_avg变量来跟踪队列中总平均负载。
11.task_struct数据结构中on_cpu成员表示进程是否在执行状态中,on_rq成员表示进程的调度状态。















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









