






转自 | 新智元
来源 | arXiv
编辑 | LQ Priscilla
Convolutional stem is all you need! Facebook AI和UC伯克利联手,探究视觉Transformer优化不稳定的本质原因,只需把patchify stem替换成convolutional stem,视觉Transformer就会性能更强,训练更稳定!
最近的研究表明,在各种图像识别人物中,相比起卷积神经网络(CNN),视觉Transformer(ViT)模型的结果更好,并且能够节省计算资源。
然而,尽管ViT的性能比CNN更好,但是论及优化器选择、特定于数据集的学习超参数的选择、训练计划长度、网络深度等,CNN更加稳健,而且优化起来更容易。
是选择ViT?还是选择CNN?
Facebook AI和UC 伯克利大学AI研究所组成的团队最近开展的一项研究则提出了一个两全其美的解决方案。
研究团队采用了标准的、轻量级的 convolutional stem的ViT模型,在不牺牲计算效率的情况下,显著提高了优化器的稳定性,并提高了峰值性能。
他们的研究结果以「Early Convolutions Help Transformer See Better」为题的论文已预发表在arXiv上。

论文主要内容
视觉Transformer (ViT) 模型为卷积神经网络 (CNN) 提供了另一种设计范式。
ViT 用multi-head self-attention的全局处理取代了卷积中固有的对局部处理的归纳偏差。希望利用这种设计以提高视觉任务的性能,类似于在NLP中观察到的趋势。
在研究这一猜想时,研究人员面临着 ViT 和 CNN 之间另一个意想不到的差异:ViT 模型表现出不合标准的「可优化性」。
ViT 对优化器的选择(AdamW vs. SGD)、特定于数据集的学习超参数的选择、训练计划长度、网络深度等,都很敏感。面对这些问题,以往的训练方法和直觉都没有用,还阻碍了研究。
相比之下,CNN的优化非常容易,优化起来也相当稳健。多年来,人们广泛使用基于 SGD、基本数据增强和标准超参数值的简单训练方法。
为什么 ViT 和 CNN 模型之间存在这种差异?
在论文中,研究人员假设问题主要是因为ViT 执行的早期视觉处理。
ViT 将输入图像「划分」为 p×p 个patch,以形成Transformer编码器的输入集。这个 patchify stem被实现为步长-p(p×p)卷积,以p=16为默认值。
这种大卷积核、大步长与 CNN 中使用的典型设计选择背道而驰,在 CNN 中,最佳效果已收敛到一小堆步长为 2 的 3×3 内核作为网络的stem。
为了验证这一假设,研究人员通过用仅包含5个以内卷积的标准convolutional stem替换其patchify stem,以「最小化」改变 ViT 的早期视觉处理。
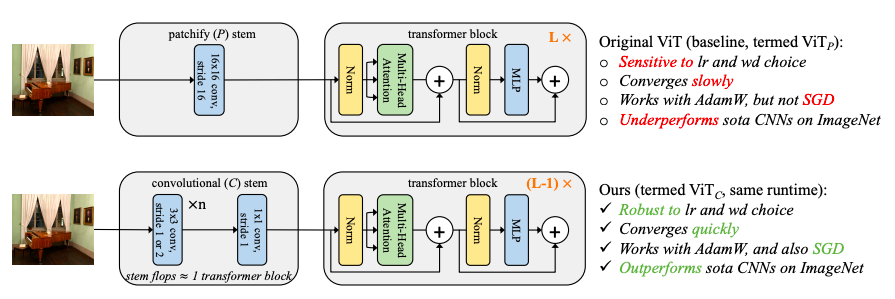
早期的卷积帮助transformer更好地看清:我们推测,与CNN相比,ViT模型的可优化性不达标,主要是由于其patchify词干的早期视觉处理,是由一个非重叠的stride-p p×p卷积来实现。默认情况下,p=16。
为了补偿flop中的少量增加,我们移除了一个Transformer块,以保持flop和运行时的奇偶校验函数(parity)。
我们观察到,尽管两种 ViT 设计中的绝大多数计算是相同的,但早期视觉处理的这种微小变化,会在对优化设置的敏感性以及最终模型精度方面产生截然不同的训练行为。
本文发现,用convoluational stem替换patchify stem后,大约使用5个convolution就可以在SGD优化器上优化,精度不会大幅度下降,并且对于learning rate和weight decay参数不敏感,训练的收敛速度更快。
另外,在模型复杂性(1G到36G)和数据集规模(ImageNet-1k到ImageNet-21k)的大范围内,ImageNet的top-1精度可以持续提升。
这些结果表明,在ViT中注入一些卷积性的感应偏差,在通常的研究环境下是有益的。通常人们会担心first layer的硬定位约束会阻碍网络的表征能力,不过我们并没有得到相关证据表明这一点。
事实上,我们观察到的情况恰恰相反,当使用convolution stem时,有更大模型和更大规模的数据时,ImageNet的结果也会得到改善。此外,在仔细控制的比较下,我们发现 ViT只有在配备convolutional stem时才能超过最先进的CNN.
我们推测,将ViT中的卷积限制在早期视觉处理中可能是一个关键的设计选择,它在(硬)归纳偏见和transformer blocks的表征学习能力之间取得了平衡。 证据来自于与「hybrid ViT」的比较。它使用了40个卷积层(ResNet-50的大部分),并没有显示出比默认的ViT有任何改进。
这一观点与一些人的研究结果产生了共鸣,他们观察到早期的transformer block比后期的transformer block更喜欢学习local attention pattern.
相比之前hybrid CNN/ViT的研究,本文的重点是探究ViT优化不稳定的本质原因,convoluational stem替换patchify stem对于ViT优化稳定性的影响。
综上所述,本文的研究结果使我们推荐使用标准的、轻量级的 convolutional stem的ViT模型,与原来的ViT模型设计相比,是一个更稳健和更高性能的架构选择。

所选ViT模型
核心实验
本文通过3个稳定性实验,一个最佳性能实验完美展现了convolutional stem相较于patchify stem的优越性。4个结论:
1. 收敛更快
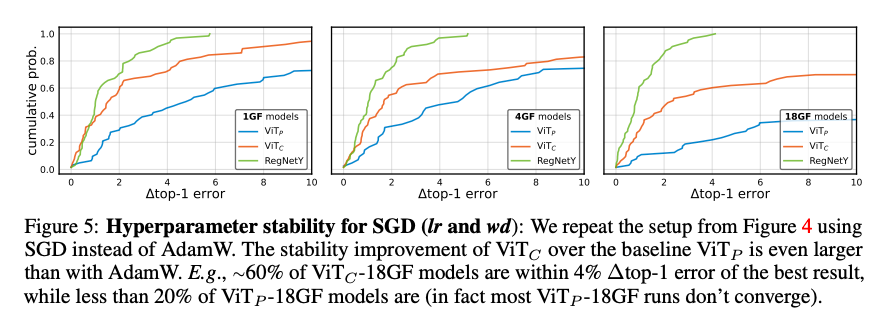
2. 可以使用SGD优化
3. 对learning rate和weight decay更稳定
4. 在ImageNet上提升了1-2个点
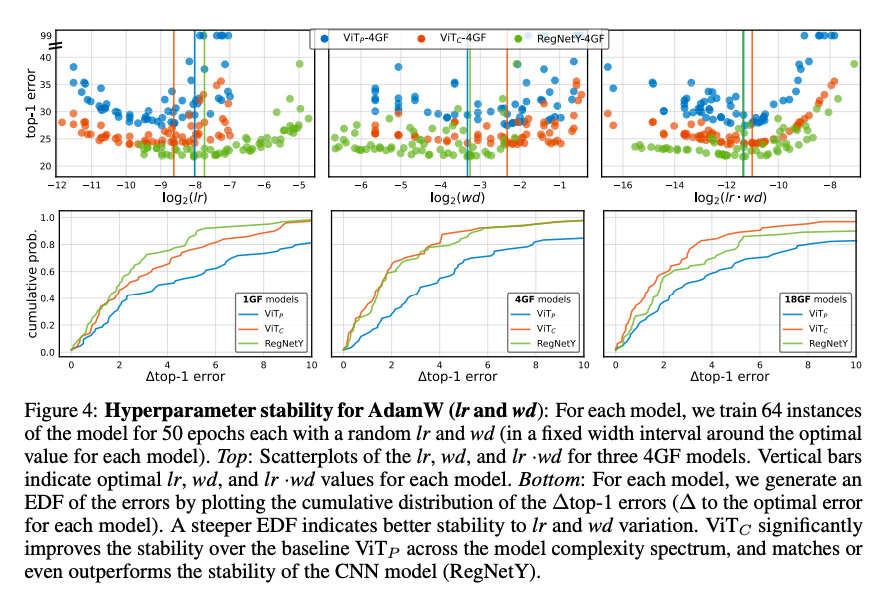
稳定性实验

AdamW和SGD优化器超参数稳定性
峰值表现
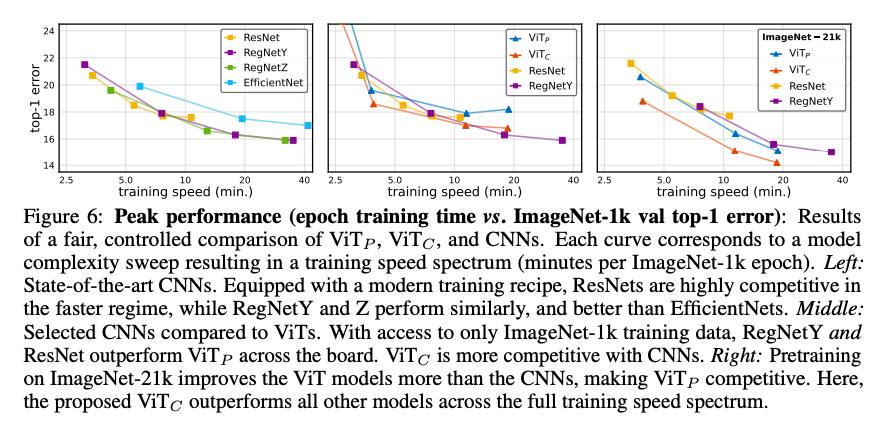

本文证明了ViT模型的优化不稳定是由于ViT的patchify stem的非常规大步长、大卷积核引起的。仅仅通过将ViT的patchify stem修改成convolutional stem,就能够提高ViT的稳定性和稳健性,非常简单实用。
但是为什么convolutional stem比patchify stem更好,还需要进一步的理论研究。最后作者还提到72GF的模型虽然精度有所改善,但是仍然会出现一种新的不稳定现象,无论使用什么stem,都会导致训练误差曲线图出现随机尖峰。
作者介绍

本论文第一作者肖特特,本科毕业于北京大学(信科学院),现为UC伯克利大学伯克利AI研究所(BAIR)的博士二年生,导师为Trevor Darrell(本论文作者之一)。肖特特同时也是Facebook AI 研究(FAIR)一员。研究兴趣包括计算机视觉和机器学习领域。
从他的简历来看,目前他已经发表了12篇顶会论文,其中两篇论文被ICLR21收录,并且肖特特在本科期间就在旷视实习,在那期间也发表了多篇顶会论文,还有5篇是在导师孙剑(旷视首席科学家)指导下完成。

参考资料:
https://syncedreview.com/2021/07/06/deepmind-podracer-tpu-based-rl-frameworks-deliver-exceptional-performance-at-low-cost-55/
https://arxiv.org/abs/2106.14881
https://tetexiao.com/
推荐阅读
重磅!DLer-计算机视觉&Transformer群已成立!
大家好,这是计算机视觉&Transformer论文分享群里,群里会第一时间发布最新的Transformer前沿论文解读及交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、视频超分、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如Transformer+上交+小明)

???? 长按识别,邀请您进群!
感谢你的分享,点赞,在看三连 















 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









