






来源:新智元
OpenAI每次宣布大事之际,总有人要走。
这不,canvas刚发布,Sora项目却再传出坏消息——负责人Tim Brooks在推特官宣离职,加入谷歌DeepMind。
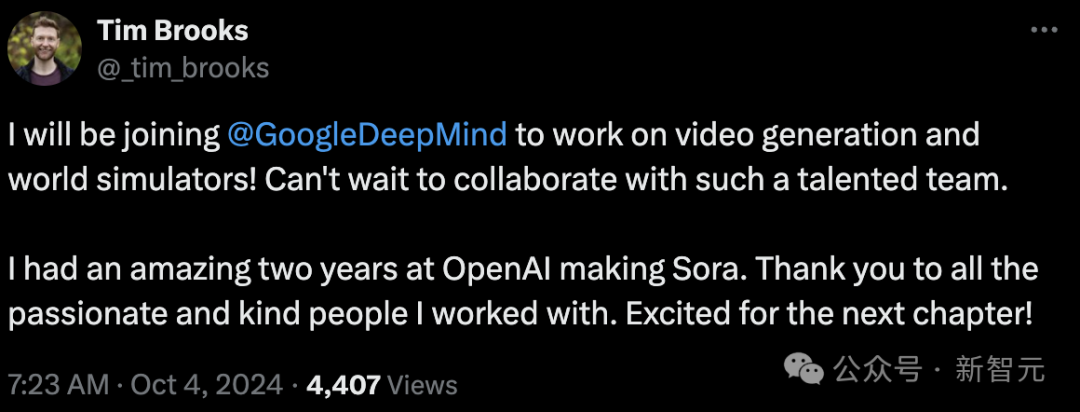
我将加入谷歌DeepMind致力于视频生成和世界模拟器!迫不及待地想与这样一个才华横溢的团队合作。
我在OpenAI创建Sora的两年里度过了一段美妙的时光。感谢所有与我一起工作的充满热情和善良的人。对下一个阶段感到兴奋!
按下葫芦起来瓢,看来发布日官宣离职可以成为OpenAI的传统了。
谷歌大佬纷纷在评论区弹冠相庆,包括DeepMind和谷歌研究院首席科学家Jeff Dean,以及谷歌AI Studio的产品负责人Logan Kilpatrick。
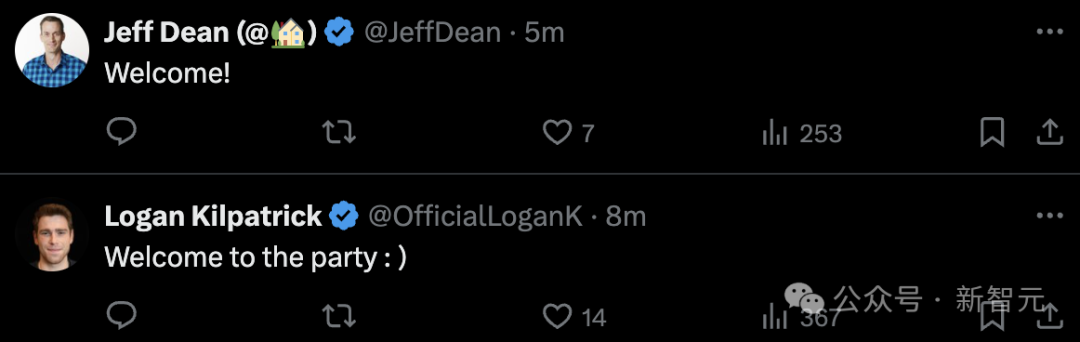
DeepMind推理团队的创始人和领导人Denny Zhou——

GPT-4o全量发布前就已辞职的「Her」项目负责人Alexis Conneau虽然没有加入谷歌,但也开始在线玩梗——欢迎成为OpenAI前员工的一员。

看来,谷歌自家的视频生成模型Veo有望超越Sora了。
目前,Sora的另一位共同负责人Bill Peebles仍在OpenAI任职。
虽然今年2月就已经发布,但Sora仍然是一个「期货模型」,只对一小部分红队测试人员和艺术家开放。
究竟什么时候上线,OpenAI也没给出过明确期限,不像「Her」项目好歹有个「今年秋天」的flag。
陷入研究泥潭,又遭遇CTO和负责人相继出走,Sora的未来再一次前途未卜。
个人经历

Tim Brooks在OpenAI共同领导了Sora项目,他的研究重点是开发能模拟现实世界的大型生成模型。
这位小哥在伯克利AI研究中心获得博士学位,博士导师是Alyosha Efros。读博期间,他提出了名为InstructPix2Pix的技术。

在加入OpenAI之前,他曾在谷歌参与开发Pixel手机相机的AI技术,还在英伟达研究过视频生成模型。
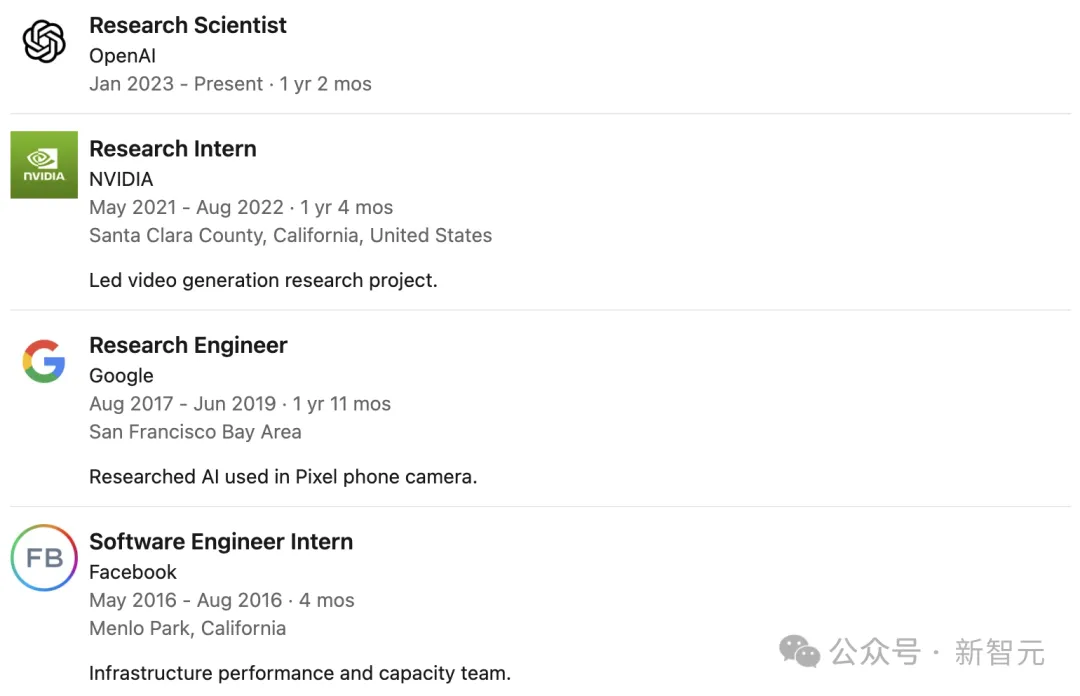
同时,他还是DALL·E 3的主要研究员。

而他的另一部分履历,就实在令人大呼精彩了——摄影作品获得了「国家地理」、「Nature's Best Photography」和「National Wildlife Federation」的大奖。

他拍摄的动物照片:

他还曾经在纽约百老汇的Beacon Theatre表演,还在国际无伴奏口技比赛中获奖。
网友们纷纷表示,羡慕他拥有这种自由。
而且,Tim Brooks还在简历中颇为「凡尔赛」地表示:「我对AI充满热情,幸运的是,这种热情与我对摄影、电影和音乐的爱好完美融合。」
加入DeepMind后,小哥表示,依旧会从事视频生成和世界模拟器相关的工作,继续融合自己对AI的热情和对摄影、电影的爱好。
从视频生成,到模拟世界
今年4月,Sora模型刚刚发布两个月时,共同负责人Tim Brooks和Bill Peebles参与了由AGI House组织的一场主题演讲,表达了自己对视频生成技术的看法——「将通过模拟一切来实现AGI」。

文生视频模型,如Sora所展示的复杂场景生成能力,逐渐显现出对人类互动和身体接触的详细理解,这是AGI的重要一步。
要生成内容真实、画面逼真的视频,就需要一个内部模型理解所有物体和人类在环境中如何运动、交互,因此,他们认为Sora将为通用人工智能的发展做出贡献。
在方法论方面,Tim Brooks和Bill Peebles都特别强调了模型的扩展性,他们认为语言模型之所以如此成功,是源于具有扩展能力,并引用了《The Bitter Lesson》中的观点:
长远来看,那些随着规模增长而性能提升的方法,随着计算能力的增加将最终胜出。
通过创建基于Transformer的框架,并对不同的Sora模型进行比较,他们展示了模型训练中计算量增加对性能提升的影响。
从基础模型到增加了32倍计算量的模型,可以看到对场景和物体的理解逐步提升。
我们一直致力于保持方法的简单性,尽管有时候实际情况比说起来更具挑战性。
我们的主要关注点是做出尽可能简单的事情,然后在此基础上进行大规模的扩展。
参考资料:
https://x.com/_tim_brooks/status/1841982327431561528
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!
















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









