






今日,阿里巴巴团队推出了其最新研究成果——EMO(Emote Portrait Alive)音频驱动的肖像视频生成框架,相关研究已经在arXiv发表。该技术能够仅通过一张静态图像和相关声音音频,创造出表情丰富且头部姿态多变的动态声音肖像视频。这标志着阿里巴巴在Animateanyone项目之后,再次在动态肖像视频生成领域取得了重要进展。
项目官网:EMO (humanaigc.github.io)
GitHub:GitHub - HumanAIGC/EMO
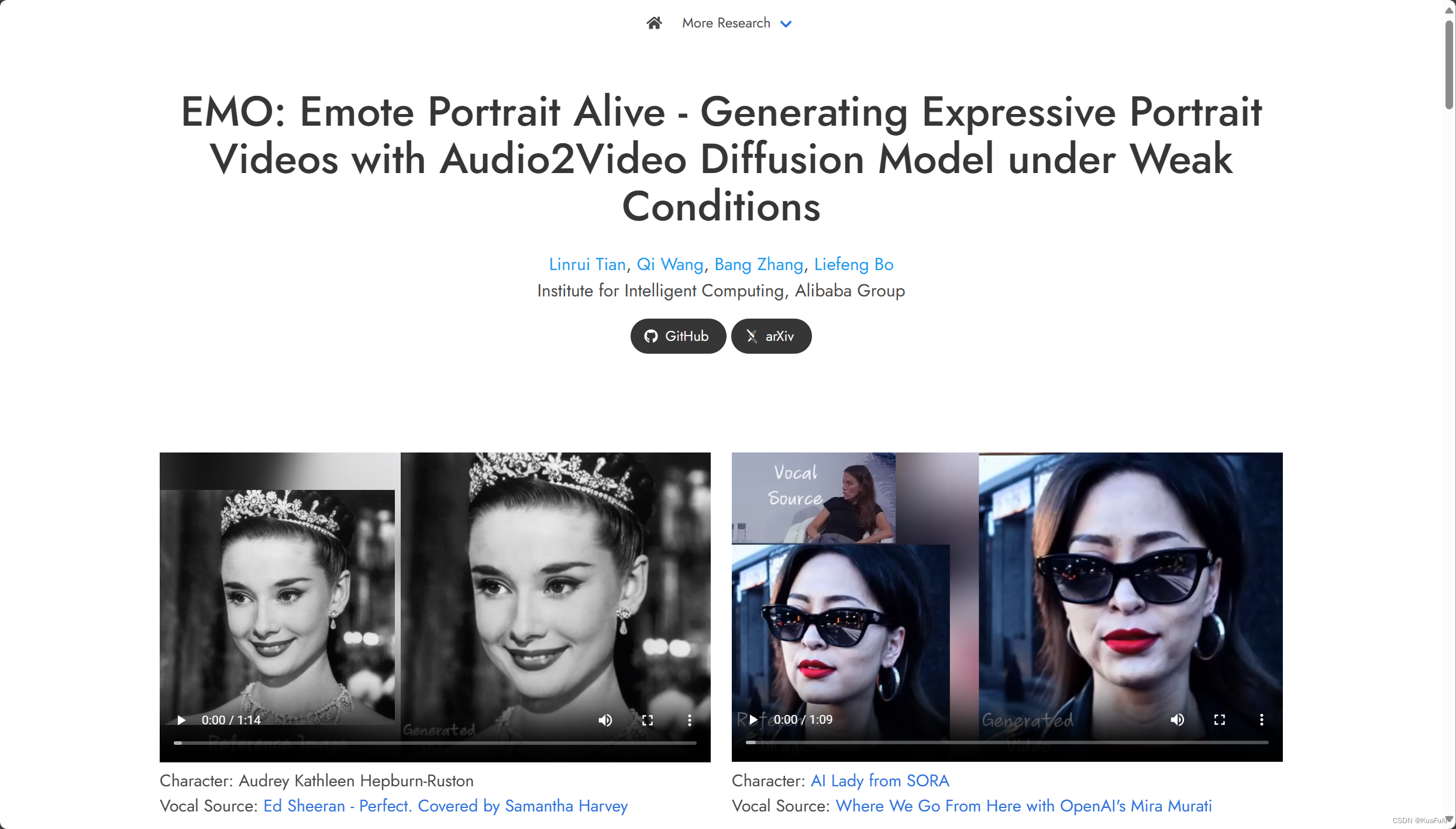
效果展示:
话不多说,直接上视频
技术原理:
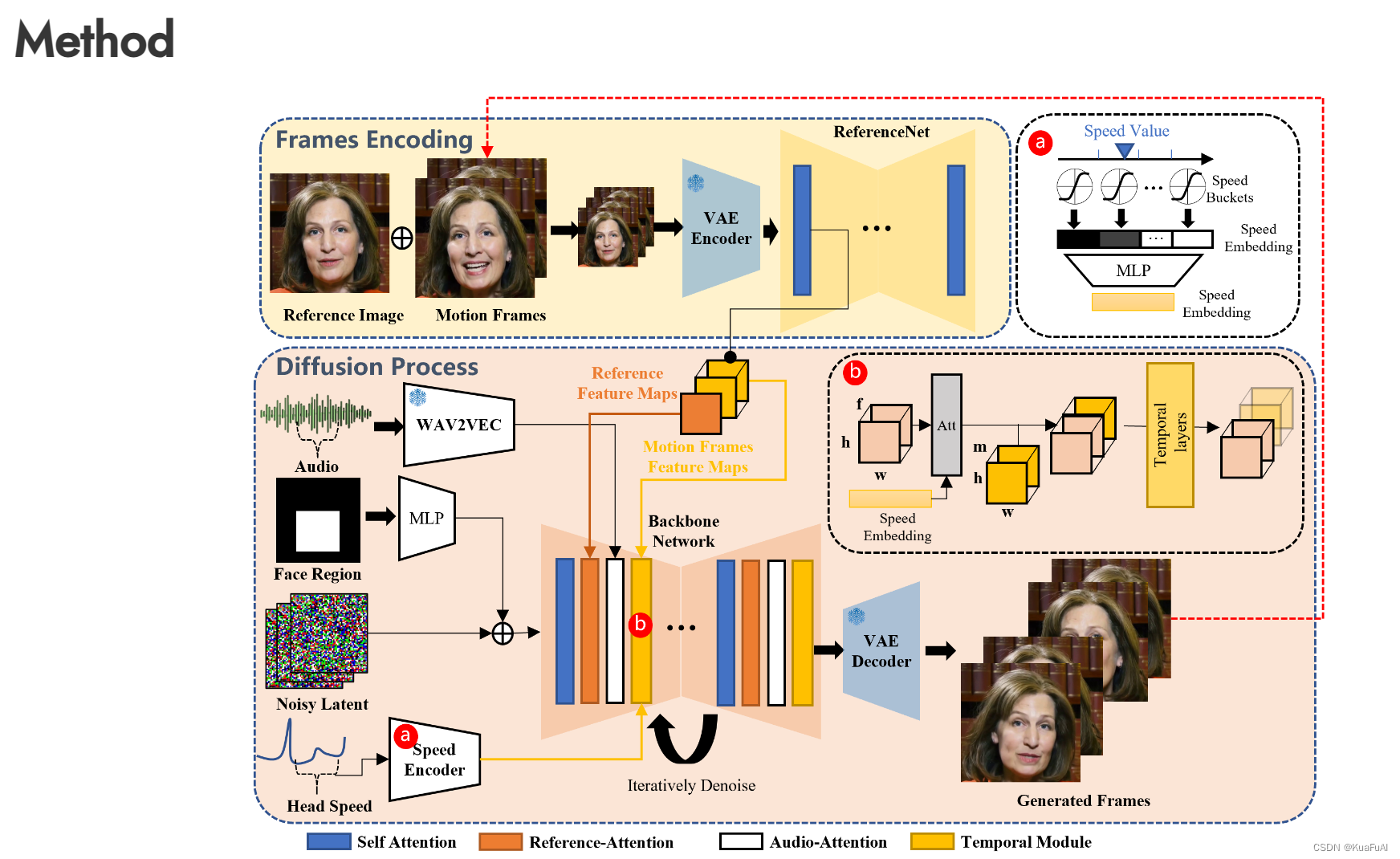
在其官网中公开的技术原理:
Overview of the proposed method. Our framework is mainly constituted with two stages. In the initial stage, termed Frames Encoding, the ReferenceNet is deployed to extract features from the reference image and motion frames. Subsequently, during the Diffusion Process stage, a pretrained audio encoder processes the audio embedding. The facial region mask is integrated with multi-frame noise to govern the generation of facial imagery. This is followed by the employment of the Backbone Network to facilitate the denoising operation. Within the Backbone Network, two forms of attention mechanisms are applied: Reference-Attention and Audio-Attention. These mechanisms are essential for preserving the character's identity and modulating the character's movements, respectively. Additionally, Temporal Modules are utilized to manipulate the temporal dimension, and adjust the velocity of motion.
整理出来大概就是以下五个步骤
①帧编码阶段:在整个框架的初步阶段利用ReferenceNet提取参考图像和运动帧中的特征。为后续的图像生成奠定基础。
②扩散过程阶段:在这一阶段,预先训练好的音频编码器处理音频嵌入,同时将面部区域掩码与多帧噪声结合,用以指导面部图像的生成。这一步骤是实现声音到视觉表现转换的关键。
③去噪操作:接下来,通过Backbone Network来进行去噪操作,以清晰地重现面部图像。这一网络是整个生成过程中的核心,确保生成图像的质量和准确性。
④注意力机制:在Backbone Network内部,应用了两种形式的注意力机制:Reference-Attention和Audio-Attention。前者主要用于保持角色的身份特征,后者则用于调节角色的动作和表情,确保音频和视觉表现的一致性。
⑤时间模块的使用:为了操纵时间维度,调整运动的速度,框架中还加入了时间模块。这一设计使得生成的视频不仅在视觉上吸引人,而且在动态展示上也更加自然流畅。
通过这些技术步骤,EMO框架能够根据静态图像和声音音频,生成具有丰富表情和头部姿势的动态声音肖像视频。
主要特点:
①高度自然与逼真的视频生成能力:EMO仅需音频输入(比如对话或唱歌)就能生成视频的先进能力,无需依赖于任何预录视频或3D面部模型。它以其卓越的细腻表现和高度逼真的输出,精确地复现了人类的面部动作和表情,甚至是细微的微表情和音频同步的头部动作。确保了视频帧的平滑过渡,有效避免了面部变形或帧抖动,极大提升了视频的整体质感。
②身份一致性与视频生成的稳定性:EMO能够在整个视频生成过程中维持人物的视觉一致性,使人物外观与初始参考图像紧密相连(依托FrameEncoding模块)。通过引入速度控制器和面部区域控制器等稳定性控制机制,显著提高视频生成的稳定性,减少视频崩溃的风险。
③灵活性与多样性:EMO还支持生成与输入音频长度相匹配的任意长度视频,它的训练数据集横跨多种语言和风格,涵盖了从中文、英文到现实主义等,展现了其对不同文化和艺术风格的广泛适应性。
个人观点
EMO不需要在预先录制视频片段或依赖3D面部模型的情况下,能够根据音频输入直接生成具有高表现力和逼真度的视频。具有较高的表现力和逼真度,并且能够补助到面部细微表情的差别,无论是在娱乐、教育、或者是直播等领域都具有一定的应用价值。
但是EMO在生成极其复杂或快速变化的表情和动作时,对于保持视频质量和稳定性仍旧存在一定的问题。并且在个人隐私和伦理问题上也需要进一步的考究。

















 123
123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









