






 搜狗创始人王小川的百川智能融资超35亿美元,其大模型Baichuan3在医疗问题上表现出色,与GPT-4竞争激烈。文章详细分析了Baichuan3在不同测试中的性能,特别是在医疗领域的能力得到了认可。
搜狗创始人王小川的百川智能融资超35亿美元,其大模型Baichuan3在医疗问题上表现出色,与GPT-4竞争激烈。文章详细分析了Baichuan3在不同测试中的性能,特别是在医疗领域的能力得到了认可。
前言:
在上一篇大模型五虎的文章中,我们介绍了国内估值最高的大模型企业——智谱AI,它们拥有自研的 GLM(General Language Model)算法框架,从最初追逐OpenAI的脚步,到“不愿做国内的OpenAI”,智谱AI毅然决然的走出了自己的道路。那么同为清华系创业团队的搜狗创始人,王小川的“百川智能”又有什么亮眼的表现呢,敬请看下文。
基本介绍

截至目前,百川智能的融资金额已达 3.5 亿美元,如今估值超18 亿美金
在国产五虎中,位列第四。
百川智能成立于2023年4月,由前搜狗公司CEO王小川创立。
其核心骨干成员由前搜狗员工组成
团队成员包括Google、腾讯、微软等科技公司的顶尖AI人才。
百川智能在成立后的100天内就陆续开源了其研发的 Baichuan 2-7B、Baichuan 2-13B
在成立的半年时间内以月为速度单位发布一款大模型。
在2024年1月29日发布了最新大语言模型Baichuan3,在多个权威测试中都展现出了不俗的能力。
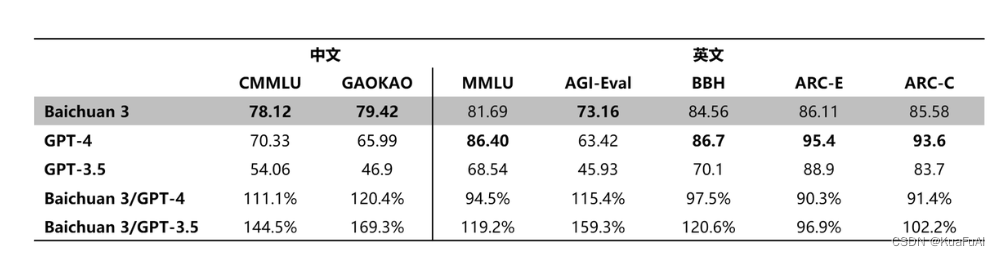
在GMMLU GAOKAO等测试中,Baichuan3执行中文指令的能力已经全面超过GPT-4的水平。
在处理英文任务(MMLU AGI-Eval)上的水平也接近GPT-4。
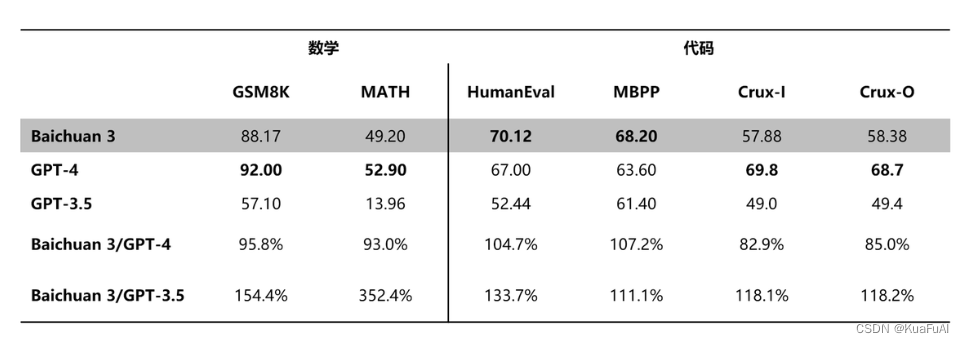
在数学计算和推理能力测试(GSM8K,MATH)中的表现也很不错,全面超过了GPT3.5,略低于GPT-4。
在代码测试(HumanEval,MBPP等)中与GPT-4的表现各有优略,值得一提的是Baichuan3在HumanEval上的表现比较亮眼。

在多轮对话和遵循指令测试(MT-Bench,IFEval)中的表现超过了GPT-3.5,尽管在数值上和GPT-4没有相差多少,但是在这种维度上的测试,相差1%,可能就会影响到实际的体验。
基准测试看完了,我们再来看一组百川智能官网上公布的数据
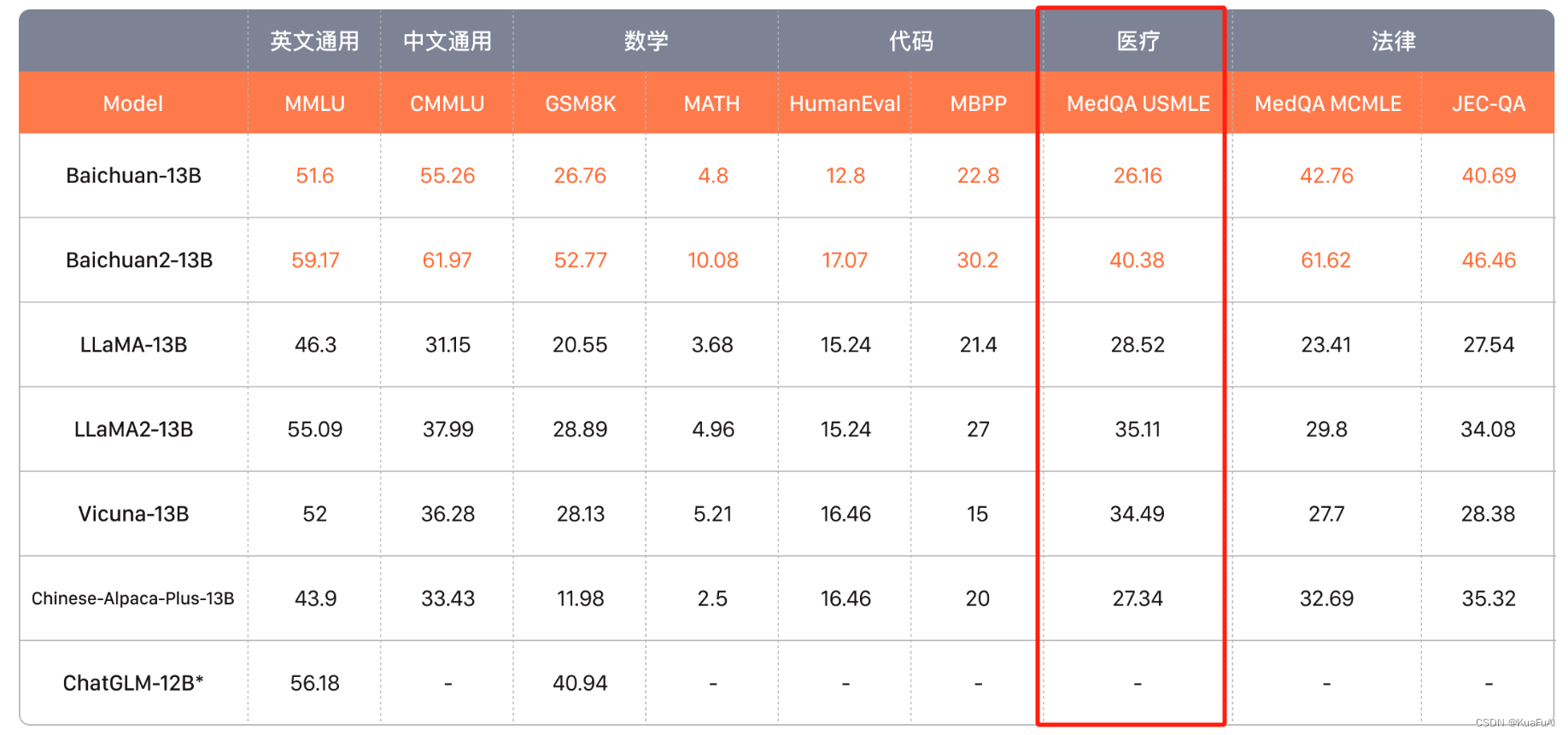
常规的基准测试我们不再赘述,表现都很不错。
这里需要特别指出的是,早在Baichuan2的时候就已经在为医疗的训练数据上进行了资源倾斜,在Baichuan3上的表现更甚,在模型预训练阶段构建了超过千亿Token的医疗数据集,针对医疗的问题,还对prompt进行了调优,这种针对具体领域的拓展延伸,我觉得是当前大模型可塑造和深究的一个方向。
其实最早搜狗输入法在做的东西和产品的形态就已经和ChatGPT相似了,输入法猜你想说什么,搜索猜你想要什么,而ChatGPT则是将这些能力集成提升到了一个全新的高度。
产品体验
既然Baichuan3耗费了大量的精力在医疗问题上,那我们今天就来探究一下,它的水平到底咋样
这里我准备了3个在医疗方面的问题,来看一下它的效果
问题1:mRNA疫苗技术是什么?解读一下它的技术内涵


我将这个问题同时抛给了Baichuan3和GPT-4,从字数上来看,GPT-4好像略胜一筹,但是二者的内容都具有一定的专业性,似乎相差不大?
问题2:生物3D打印技术的在临床如何应用?


在这个问题上,GPT-4回答的似乎更加精确,但是Baichuan3给出了一个空军军医大学的具体案例,这是国外的模型所不具备的能力。
问题3:我相信以你的能力,肯定能帮我解决阿尔兹海默症的难题
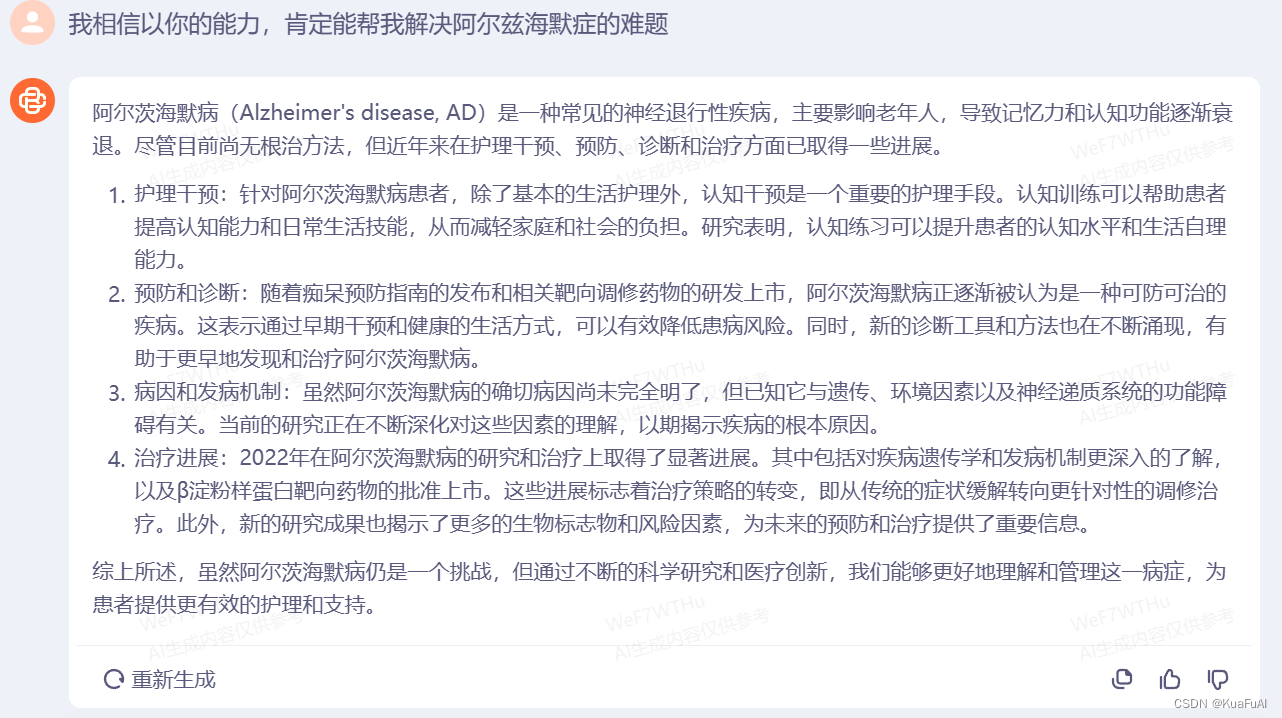

二者在技术性上的回答大差不大,但是GPT-4更具逻辑性,表现的更像是在与一个“人”进行对话
综合来看,Baichuan3在回答医疗问题上的能力,却非浪得虚名,似乎在该领域已经能和GPT-4掰手腕了?当然这几个简单的问题,并不足以展示Baichuan3的全部能力,本文中的测试也仅供参考,感兴趣的话,还是要自己体验一下较好。
总结
与其纠结谁才是国内OpenAI的问题,倒不如探讨一下,在这样一个大浪淘沙的环境下,大模型企业如何发展,身为普通人的我们又该如何面对这波机遇。互联网革命尚且没有谢幕,通用人工智能时代又席卷而来......

















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









