






原文链接:https://ai.google/research/pubs/pub45384
作者介绍
Úlfar Erlingsson在数据隐私领域具备20年经验,目前任职谷歌大脑的研究科学家 负责领导 Google安全与隐私团队的研究工作。此前他曾担任微软研究院的研究员做软件安全控制方面的理论分析工作,后来创业的安全公司GreenBorder被Google收购用做Chrome的沙盒技术。在隐私安全方面于14年做出了RAPPOR,本篇论文发表于2016年六月第29届IEEE计算机安全基础研讨会(CSF'16)。这项数据驱动技术的工程化使用方面请参考:https://juejin.im/entry/596db0156fb9a06bb0195b36。作者最新比较有趣的论文是差分隐私方面的《用半监督知识迁移解决深度学习中训练隐私数据的问题》https://openreview.net/forum?id=HkwoSDPgg¬eId=HkwoSDPgg。以下是正文:
摘要
在计算机软件方面我们的设置的安全模型、策略,机制和保护措施主要是于上世纪70年代之前构思和开发实现的。然而今非昔比,软件已发生了根本性的变化:它的规模庞大了成千上万倍,囊括了无数的库,分层接口和服务,并且以更复杂的方式用于更多场景实现。我们的计算机核心安全概念需要重新审视。例如,当软件太复杂而无法让开发人员或其用户解释其预期行为时,不清楚最小特权原则还是有用的安全策略。
一种可能性是对现代软件采用基于经验值的,由数据驱动的方法,并通过全面的在线监测并确定其具体行为。这种方法可以成为一种实用,有效的安全原则 - 正如其在垃圾邮件和滥用行为中的成功所证明的那样- 但将它用于限制软件行为引发了许多问题。特别是这三个问题似乎很关键。首先,我们在大规模场景下能否有效地监控软件行为的细节?第二,是否可以在不侵犯用户隐私的情况下学习这些细节信息?第三,这些细节信息是否真的可以作为对制定软件应该如何表现的安全策略的基础条件?
本文概述了数据驱动的软件安全模型,并描述了如何正确回答上述三个问题。具体而言,本文简要介绍了高效,详细的软件监控方法,以及学习详细软件统计数据的方法,同时为用户提供差异化的隐私服务,最后,机器学习方法如何帮助发现用户对预期软件行为的期望,从而有助于制定安全政策。即使在非常大的范围内这些方法也可以在实践中应用起来,并证明数据驱动的软件安全模型可以提供真实的好处。
一.介绍
自从计算机安全的核心概念经过在1970年代和1960年代后期开发和阐述后,大部分一直保持不变,例如在Lampson和Saltzer和Schroeder的关于软件保护开创性论文[1],[2]。然而,从那时起令人惊讶的是在增加计算机用户的实际安全性方面几乎没有取得进展,特别是与同期计算机方向其他方面的指数级改进相比。实际上,在一些统计维度上计算机安全问题在这几十年中逐渐恶化,尽管已经开发和部署了大量的计算机安全机制,并且诸如高级别加密之类的技术的使用已经变得无处不在。
今朝的计算机用户每年因计算机安全问题而遭受到一些困扰或损害,比如他们的个人信息被从个人设备或易受攻击的数据库所窃取,或者因为他们的计算机感染了未知的软件或被收集到僵尸网络中,或者只是因为他们的信用卡或汽车由于安全缺陷或漏洞而被召回。因此,基于新的理念发力于计算机安全值得思考- 尽管任何此类努力都必须承认安全性本身很复杂和普遍认为决定没有任何灵丹妙药可以一劳永逸。
这篇简短的文件提出了一种由数据驱动的软件安全模型,它建立在基于经验处理程序的抽象层面,它将软件与执行跟踪中所有安全相关事件的数据进行配对。
例如,实施这种数据驱动的模型将自动禁止通过Microsoft Windows Solitaire游戏[3]进行网络访问,并且还禁止触发Heartbleed类漏洞的消息[4]。在该模型中,安全策略自动从历史证据中获得,并且Solitaire游戏不使用Windows网络库,即使它包含它们,也不存在具有大量有效载荷的自然发生的TLS心跳消息。
本文进一步调用和描述了这种数据驱动的软件安全模型,并给出了软件实践有效的例子。
A.安全模型和制定策略的难点
长期以来我们在计算机安全方面只取得了令人失望的微小的进展。在千禧年之际的一系列会谈和论文中,计算机安全领域的创始人之一Butler Lampson对该领域的愿景和承诺及其在实践中的失败做了很好的概述[5]。
在这项工作中,Lampson令人信服地解释了计算机安全的困难,例如,它如何比传统安全更难,因为互联互通网络创造了无限的潜在攻击者,并且因为计算机精确、可靠的去执行任务意味着只有充分解决了全部漏洞,才能保证攻击可以被阻止。
最重要的是,Lampson绘制了安全策略,机制和保证之间的对应关系,如图1所示, 以及对程序正确性的一致性要求(即确定软件正确实现了规范)。在该列表中,图1添加了安全模型之间的对应关系,例如访问控制列表,功能或信息流跟踪,以及不同的编程方法,例如命令式或函数式编程,逻辑或声明式形式或响应式式软件模块。与编程范式一样,安全模型可以最好地看作是朝向同一流向的替代方法(至少,如果我们遵循Lampson并忽略一般的非干扰因素等[6])。在一个图灵完备性的语言中的很容易实现任务和方法,而在另一个语言中则很难实现,安全模型也是如此,通常安全模型只能将执行限制在同一组可执行的安全策略中[7]。
以及对程序正确性的一致性要求(即确定软件正确实现了规范)。在该列表中,图1添加了安全模型之间的对应关系,例如访问控制列表,功能或信息流跟踪,以及不同的编程方法,例如命令式或函数式编程,逻辑或声明式形式或响应式式软件模块。与编程范式一样,安全模型可以最好地看作是朝向同一流向的替代方法(至少,如果我们遵循Lampson并忽略一般的非干扰因素等[6])。在一个图灵完备性的语言中的很容易实现任务和方法,而在另一个语言中则很难实现,安全模型也是如此,通常安全模型只能将执行限制在同一组可执行的安全策略中[7]。
Lampson的文章强调了如何定义正确的安全策略 - 由通过所选定的机制保证实施 - 是创建安全软件的主要障碍。软件开发人员不愿意完全指定安全策略的预期功能,并且当被迫创建它们时,可能又会出现这样那样的错误;而且直到最后才能确保简易程序的程序正确性变得切实可行[8]。图1将安全策略视为一种规范形式,尽管这一策略特别重要且难以正确实现。我们要求软件开发人员,管理员或用户定义安全策略并选择执行机制只是一厢情愿,通过基础且易用的配置去创建预期正确执行的软件已被证明是这样的一个不可逾越的挑战。
根据面临的任务和所需的保证,某些安全模型和机制可能特别适合提供保障性,类似于最好通过某种特定方面的规定实现某类软件功能。就像其他形式的软件规范一样,安全策略的意图和粒度可以宽泛些,并且可以出于某些考虑很容易地推行和设置预期的策略。例如,简单禁止所允许的信息流可以全面保护机密信息,就像在Datalog中声明的实现功能就可以完全确保可判定性一样。为大类软件实现简单,有用的安全策略的安全模型显然是有利的,即使它们的简易型将不能使得这些模型足以解决许多现实情况下的安全问题。
一个特别重要的安全模型所容许的简易策略是其足以包含阻止低级别软件漏洞利用机制。
B.针对软件底层自动创建策略

在过去的几十年中基于堆栈的缓冲区溢出和内存损坏漏洞已成为主要的攻击手段和关键的软件安全问题。
在防御此类攻击时,图2中概述的安全模型在定义成功防止漏洞利用的简单、有用的安全策略方面特别有效。在这个被称为“编程软件安全”的安全模型中,安全策略是根据编程语言抽象和语义以及编程人员的明确意图,通过识别明显真实的简单程序属性,自动从软件源代码(或二进制文件)派生出来的。
这个安全模型已经被多次实际使用,例如通过在执行堆栈上放置canary mitigation 或cookie来保持程序员预期的函数返回地址值的完整性,或者通过引入人为的异构性和随机性来捕获程序对的具体表示不敏感像指针这样的意图[9]。这些实例化遵循了图2的最优解,并且必须明确地只允许少数特殊情况,例如动态加载、库和信号传递。不幸的是,许多实例将策略和机制紧密和错综复杂地联系在一起,使底层模型清晰地可识别。
这种安全模型最明显不过的例子是强制执行开发人员预期的控制和数据流,这通常被称为控制流完整性(cfi)和数据流完整性(dfi)[10]、[11]、[12]、[13]、[14]、[15]。在这项工作中,很明显可以从软件本身自动导出不同粒度的不同安全策略,以及这些策略如何(极大地)限制攻击者利用低级别漏洞。这些策略可以在不同的抽象级别上运行,目的是以完全精确的方式强制实施程序的详细抽象模型,或者在代码或数据之间进行二进制、粗粒度的区分,甚至使某些活动完全不受约束。例如,一些CFI机制只适用于C++ VTABLE,但确实如此,而另一些则以非常粗糙的方式应用于所有间接控制流;类似地,数据流完整性机制在它们的抽象方式中有所不同,其中一些基于数据分配,而另一些则基于读/写模式等。
数据流安全机制是它们的策略由已经编写的软件程序决定。在任何情况下,用户都不需要指定策略详细信息:他们必须简单地在具有不同强制机制的安全策略和不同的保证级别之间进行选择。当然,这种选择可能仍然具有挑战性,因为存在各种各样的机制,从二进制翻译仿真器到高度优化的编译器插入的、软件工程和性能特征大不相同的内联保护。此外,每个机构的参数可能是可调整的,例如,改变精度水平或进行其他权衡。最后,只有这些机制中的一些会试图提供高度的保证,例如那些验证最终二进制文件的静态CFI属性的机制[16]。然而,与编写由Lampson确定的安全策略或程序规范的主要障碍相比,这些都是容易实现的、常见的工程权衡。
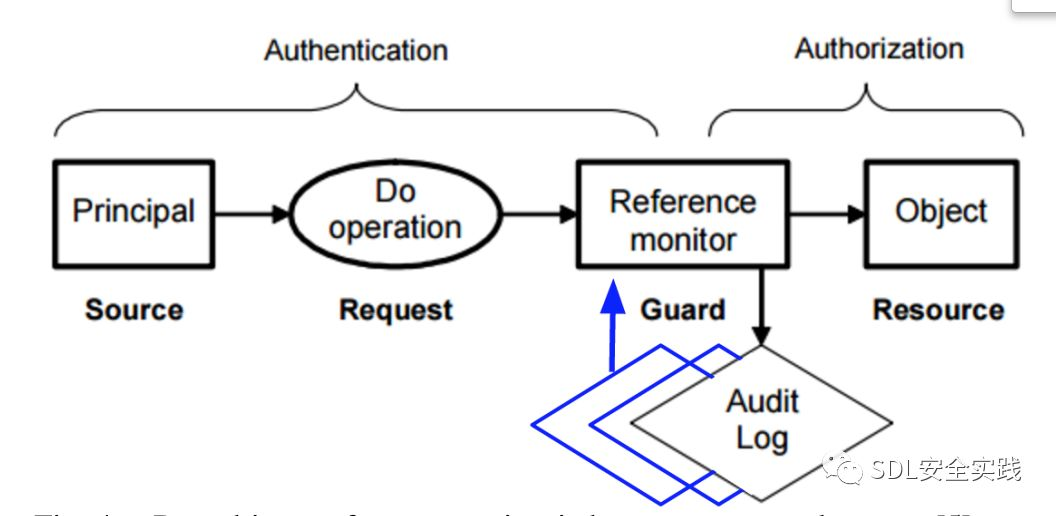
体现这种程序员意图的安全模型的机制现在以某种形式被广泛地使用,毫无疑问,由于缺乏用户指定的安全策略。然而,这个模型的应用最多只能消除一组漏洞,大约是由严格的类型安全编程语言消除的漏洞,并且留下未修复的其他漏洞,例如由程序员造成的实际逻辑错误。值得考虑的是,在没有用户规范的情况下,可以采用其他方式来定义实际有用的安全策略,例如,通过将这些策略自动建立在所有软件程序执行过程中收集的经验基础上。
二.基于数据的软件安全模型
让我们假设软件可以附带对该程序所有执行情况的全面总结, 可以详细说明该程序在每个实例中的历史行为。实际上,让我们将一个经验程序的新抽象定义为静态软件程序(例如,它的源代码或可执行文本),与它所有执行跟踪的多集将结合。这些跟踪将在一定的粒度级别被捕获,为了安全起见,可能只包括与安全相关的执行事件。
由于现代软件通常是在线进行安全更新的,如果没有其他情况的话,这种经验程序抽象的实际实现不是一个牵强的想法。
这种抽象自然会支持图3中概述的安全模型,除非特别允许,否则它只会禁止所有新出现的、与安全相关的行为。默认情况下,此模型可以防止许多软件攻击,例如在复杂的操作系统服务中经常发现的权限提升类漏洞。最近,通过历史证据表明该软件从未使用过keyctl或kernel-keyring,因此该模型的实施将禁止在常用应用程序中使用Linux keyctl系统调用来阻止对CVE-2016-0728漏洞的利用。
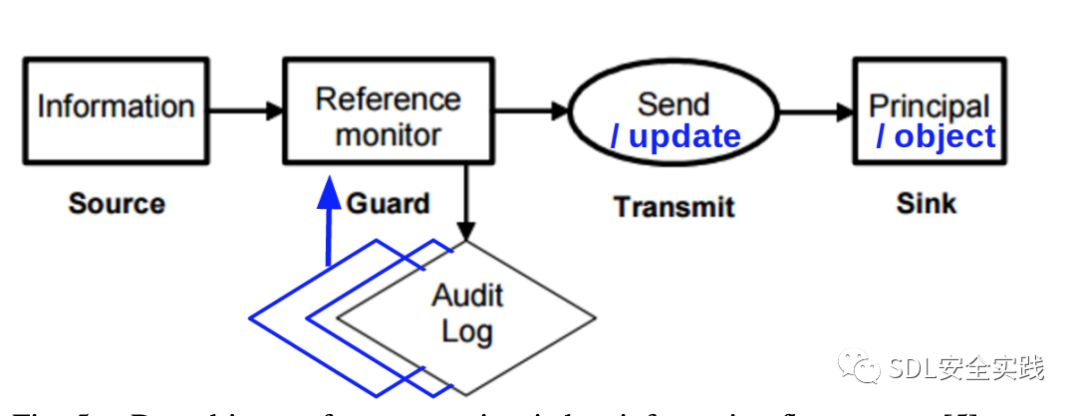
当然,要将这种模式应用到实际的安全执行机制中,存在着许多障碍和随着而来产生的问题。例如,在第一次执行程序时应该强制执行什么安全策略?但是,不管障碍是什么,图3中的数据驱动安全模型非常有吸引力。特别是软件安全实施似乎是个自然而然的基础,可以考虑软件过去的整体行为(参见基于状态的安全实施,仅考虑当前的执行[17]。此外,如图4和图5所示,该模型可以自然地与现有的安全模型相结合,只需确保按照历史审计日志进行操作和信息流(从而将审计的重要性提高到与Lampson’s黄金标准[5]的其他方面相当)。
至关重要的是这种数据驱动的安全性与编程安全性共享一个巨大的优势,即策略主要由已经编写(和执行)的经验类程序决定。因此,策略可以简单且易于指定。
数据驱动安全策略的主要参数是执行跟踪中使用的事件抽象-例如,网络服务请求、API或系统调用、函数调用或简单的安全权限, 以及在安全相关的历史频率必须看到过相关事件,才能在当前执行中被允许。尽管历史证据可以用多种方式解释(例如,使用复杂的机器学习),但效率和稳健性问题可能更倾向于使用更简单的方法(例如,使用一组观察到的事件,而不是它们的序列)。
为了清晰起见,本文只考虑安全相关的事件,例如系统调用,这些事件可以使用集合理论操作轻松地进行汇总和组合。如果一个事件在执行跟踪中至少发生过一次(对于某些固定的低阈值k,则为k次),则认为该事件受历史数据支持;否则,安全策略将禁止该事件发生。这些允许的操作集减少软件攻击面的安全策略已被证明具有很大的实用价值,例如,在网络防火墙和操作系统沙盒中[18]。
简单的、数据驱动的软件安全策略可以特别非常适合大规模、流行的软件应用程序,这些应用程序通常规模庞大,由无数的平台、模块和库组成,并且充满神秘或未使用的功能。在这种常用的软件中,存在许多隐藏漏洞的老旧的地方,以及嵌入式解释程序、动态库加载程序和反射API,攻击者可以利用这些API执行任意行为。简单地不允许以前看不到的安全相关事件可以有效地阻止此类攻击,对于广泛使用的软件来说,这些软件可以成为大量执行跟踪的历史证据的有力基础。
当然,数据驱动的安全不是万能药,必须仔细考虑其局限性、障碍和开放性问题。但是,如上所述,数据驱动的安全实施可以提供显著的好处,至少对于最影响用户的常用软件是如此。
A.异常和入侵检测的区别
过去从执行跟踪自动构建安全策略的最突出尝试集中在异常检测和软件入侵检测技术上。尽管细节不同,但这项工作的共同理念是使用从良性训练运行(或试运行)中收集的一组跟踪信息来确定什么是“正常”执行,并在随后的操作阶段强制遵循此安全策略[19]、[20]。由于软件往往对可能的行为有长尾效应,并且这些技术只使用一组部分的训练跟踪(例如来自一个特殊的训练阶段),因此在实际部署时,它们总是会遇到大量的错误报告。因此,它们的除了对手动操作人员发出大量但有用的警告通知外实际用途很有限。
全面性:本文的数据驱动软件安全模型依赖于经验的程序抽象来避免此类错误报告的安全违规行为。根据定义,经验项目包括所有执行痕迹,而不仅仅是训练运行的痕迹。这些跟踪还应包括软件开发和测试期间执行的所有操作,这应确保任何潜在的、实际的软件功能都将被表示出来,即使是首次使用不受欢迎的软件。常用软件的长尾行为应该特别透明,因为它们的策略可以总结出数十亿个执行痕迹。
抽象级别:为了使上述内容正确,必须仔细选择用于数据驱动安全策略的抽象和方法。尤其是,它们不能是如此细粒度的,以至于它们包含了与软件语义正交的用户特定行为。例如,基于用户输入到文本编辑软件的内容或Web浏览器的URL栏的安全策略很可能在将来触发错误。因此,数据驱动的安全性最好基于更简单、更粗略的抽象,例如本文中使用的系统调用集,可能会在参数值及其大小上增加不变量。造成这种抽象的技术可以在推断收敛软件不变量[21 ]、[22 ]的基础上建立。
开发流程集成:此外,数据驱动的安全技术必须至少部分集成到工程流程中,最好在整个软件开发周期中使用。例如,可以使用测试覆盖率分析来确定安全策略是否全面且具有足够的许可性,以允许广泛的软件部署。可以使用模糊测试,有形的执行或其他自动测试技术来增加覆盖范围(如[23]中所述)。但是必须小心,否则可能会发现带有嵌入式解释器或其他通用模块的软件显示所有可能的行为。
这种软件工程集成在维护安全策略方面也将是无价的,因为软件是为了安全性,稳定性或行为而更新的(在现代软件中很常见),或者偶尔进行重大升级。(当然,对软件更新进行适当的计算需要重新定义经验程序抽象,以解决版本随时间的差异。)最重要的是,数据驱动安全策略的维护必须集成到软件开发中,新的、总结的安全策略被视为软件安全更新的一种形式。
实际的执行跟踪:无论软件开发是如何执行的,在数据驱动的安全策略的制定过程中,都没有替代来自实际执行跟踪的证据。测试充其量只是部分的,软件通常用于意外配置中的意外目的;没有任何测试框架可以希望复制所有最终用户活动和可能影响软件执行的环境。在实际执行过程中,不可避免地会首先看到一些执行路径(例如,不难想象这可能适用于软件模拟的非正规浮点计算)。此外,安全策略可能不允许在软件开发过程中常见的某些行为,例如调试器或自动化驱动的输入,这一点可能很重要;否则,数据驱动的安全策略可能在默认情况下为常见的sendmail调试脚本漏洞CVE-1999-0095打开大门。
上下文特异性:为了提高安全策略的精度,执行跟踪可以包括有关环境因素的信息,例如时间、区域设置、用户首选项等,这些因素可能以多种方式影响软件行为。例如,软件的执行可能高度依赖于时间:考虑到2000年千年虫虫及其影响,一些商业软件的关于年的判断处理也是如此。在这种情况下,人们可能希望在功能或集成测试期间在执行跟踪中捕获到这种行为。更麻烦的是,有些软件可能包含一些功能性的“复活节彩蛋”,这些功能甚至在软件开发过程中都是隐藏的。在后一种情况下,我们可以问询以前从未见过的软件行为,即使是在测试期间,是否不应该简单地算作一个bug从而导致程序终止;当然,软件崩溃往往没有好的理由,这里至少有一个好的理由。
补救措施:更一般地说,在违反数据驱动的安全策略时,可能会采取一系列补救措施。在许多情况下,基于错误的情况去停止执行是有必要的,例如,对于可以由用户重启的非关键软件,如果不担心数据丢失,只要软件可以重启已避免死循环。此外,有时简单地询问用户是否继续执行,并总结他们的决定以制定未来的政策是切实可行的;这种方法的一种变通情况是用于某些移动电话和Web平台上的安全相关权限。最后,即使静默地允许继续执行,系统管理员和软件开发人员都可以充分利用软件漏洞的高精度报告,例如设置防火墙规则或开发安全更新。通过静默警报进行修复模糊同传统异常检测的区别,但数据驱动的安全措施应该触发更少的警报。
部署引导:即使在使用静默警报时,在通过对足够的实际执行跟踪进行汇总之前,应该不会强制实施数据驱动的安全策略,直到这些策略收敛和稳定为止。这是数据驱动软件安全模型与传统异常检测的关键区别。这是数据驱动的软件安全模型和传统的异常检测之间的关键区别。通过与软件开发生命周期(包括软件的初始实际使用)集成,可以监控收敛到稳定安全策略的过程,并且在某些时候,在使用领域知识仔细考虑之后,必须翻转开关以开始实施这些策略。
因此,数据驱动的实施不太可能在软件开发,测试和早期部署期间带来任何安全性好处;它的好处将主要在软件经常使用之后产生,幸运的是,这也是其改进的安全性将对大多数用户产生影响的时候。
B.开放性问题和正式的模型
关于这种数据驱动的软件安全模型仍然存在悬而未决的问题,这里无法解答。
例如,如果安全策略是由实际执行跟踪驱动的,则不难想象攻击者可能试图将恶意行为分类为良性行为,例如,通过使用Sybil攻击来促进模拟攻击[24],[25]。在其他情况下,例如团购餐厅的评论,这些攻击在很大程度上是通过注册用户帐户的风控来防止的。然而在软件环境中,这些攻击可能是毁灭性的,特别是在没有明确定义、负责的用户注册的情况下。即便如此,在某些领域,如数据中心计算领域,这一障碍显然可以克服,例如,通过消除Sybil或管理它们的数量。
关于这个模型还有更多的正式问题,特别是关于它的经验程序抽象。从形式语言的角度来看,程序可以看作是语言识别器,从这个角度来看,现代软件的不安全部分源于它识别了过多的输入。经验程序通过在某些抽象级别禁止执行跟踪中的某些事件来限制已识别输入的集合,而软件本身的静态文本隐式地定义允许事件的子集。显然,如果有关于经验程序的正式推理的合理基础,那么应用数据驱动的软件安全模型会有所帮助。
但是,首先必须确定可以在实践中足够有效地完成全面的软件执行跟踪,并用于推导提供有用安全性益处的数据驱动策略。
三、数据驱动软件安全方法
尽管其相对简单和其他吸引人的品质,但在大多数领域中,数据驱动的软件安全模型不太可能直接应用。例如,与软件工程过程的关键集成以及用于构建和维护安全策略的机制的部署本身可能就是主要挑战。此外,选择经验程序的抽象、粒度和阈值,以及确定跟踪数据何时收敛到有用的安全策略(需要安全工程师的具备稀缺领域内的专家技能)仍然是一门艺术,而不仅仅是科学。
尽管如此,在过去的几年里,我们在谷歌已经构建了几个数据驱动的安全机制,并以各种方式利用它们,作为软件产品和生产基础设施的一部分。这些机制中的许多都是实验性的,但也有一些已经得到了显著的应用。
本节描述了其中三种机制,它们确定可以以足够低的开销以保护最终用户隐私的方式收集执行跟踪,并且可以以新颖的方式使用这些跟踪来保护用户的安全和隐私。
A.有效监控软件执行细节
在由Michael Vrable领导的工作中,我们对谷歌的软件执行细节进行了有效的监控,我们已经考虑了数据驱动的安全策略,这些策略是关于在我们的数据中心运行的生产软件的系统调用行为。对于此类软件,通过与Google的测试驱动开发相结合,并从数千个流程实例中收集执行跟踪摘要,可以相对容易地实现经验程序抽象。此外,故障停止强制可以特别适用于容错软件,该软件旨在优雅地容忍进程故障并自动丢弃触发此类故障的请求。
我们的经验表明,使用标准技术(如Linux上的ptrace和seccomp-bpf)可以有效地收集、总结和实施基于系统调用跟踪的安全策略,这两种技术都不会产生任何显著的单次系统调用成本,即使是像使用系统范围的探查器那样整体应用的话[26]。
我们已经开发了进一步的技术,根据可执行二进制代码(包括消息封送处理代码)的重新排序,在函数、库例程或网络消息级别进行有效跟踪,以便可以使用操作系统内存保护来阻止执行可能未使用的代码。最后,我们创建了一些机制来可靠地处理软件行为中突然的、意外的变化,以及由此产生的事件风暴和其他中断。因此,实际上,至少对于涉及多组系统调用或一组其他支持例程和服务的策略,可以有效地实现数据驱动的安全模型。
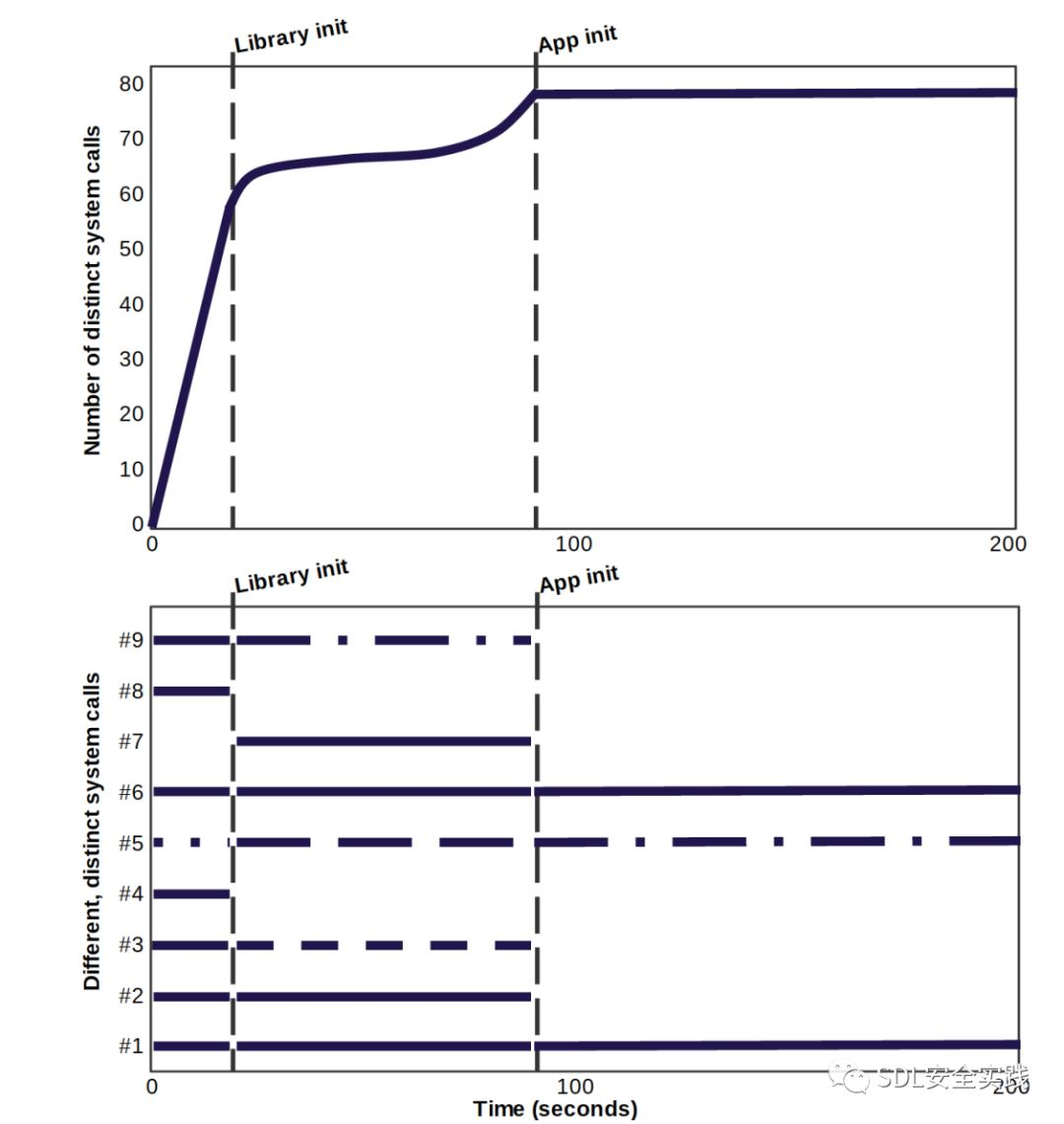
此外,我们的工作已经证明,执行此类策略可以显著减少暴露于潜在易受攻击软件的攻击面。当被视为一个经验程序时,即使是功能最丰富的软件也相对较少地使用底层系统服务——尽管软件可能包括所有可能功能的代码、模块和库,以及网络消息。
例如,图6的上半部分展示了一个这样的程序如何使用少于三分之一的Linux系统调用。图6的下半部分还示出了这样的软件如何能够表现出可用于提高安全性的特定于阶段的行为,例如,在初始化后进一步约束策略,就像chrome web浏览器所做的那样[18]。值得注意的是,在这种情况下,软件不使用keyctl调用,因此自动派生的安全策略可以阻断对第3页讨论的CVE-2016-0728漏洞的攻击。
B.对软件执行数据的隐私保护
软件监控可能会对用户产生隐私影响,即使数据对隐私的敏感程度不是很明显。简单地知道一个软件功能已经被激活,可能会产生重大的后果,正如电视法律剧中有效地证明的那样,根据出于良性目的捕获的日志记录中的证据,犯罪者经常被判有罪。
有许多可能的方法可以保护参与收集经验程序执行跟踪的软件用户的隐私和匿名性。例如,可以使用复杂的加密方法(例如部分同态的paillier加密)来收集和组合数据,或者用户在提供跟踪数据时可以简单地依赖类似tor的网络匿名。
在谷歌,我们已经开发并部署了一些特别有吸引力的隐私保护技术,根据随机响应的思想来监控客户数据[27]。这些技术可以在开源Rappor项目中找到,可以在https://github.com/google/rapper[27]上找到。Rappor已经被广泛地用于收集客户端值的统计信息,例如chromeWeb浏览器中用户提供的URL域。
Rappor可以很容易地应用于收集执行跟踪数据,同时保留用户的隐私和匿名性。特别是,对于有关经验程序使用的系统调用频率的报告,充分利用“基本Rappor”——一种简单的、二进制形式的随机响应。这些报告在计算和大小方面开销都很低,并且可以很容易地聚合到数据驱动的安全策略中。
C.匹配用户要求和软件权限
在谷歌我们在过去几年中开发了评估用户期望软件在不同方面表现的技术。这项工作是在在线软件市场的背景下进行的,例如移动电话和网络平台的市场。其目标是通过创建类似软件的“对等组”,改进thosse市场中软件对安全相关权限的使用[28]。
我们的前提是用户期望他们认为提供类似功能的软件具有类似的行为。
最近,在Martin Pelikan领导的工作中,我们已经取得了很好的结果,特别是通过使用现代机器学习技术发现了明显相似的软件,在不同软件的可用数据上使用word2vec skip-gram模型,例如其描述以及用户如何与在线市场上的软件交互。因此,我们能够制作出具有类似功能的相当精确的软件对等组,从而建立了一个很好的比较基础,从中评估用户的期望。
为了安全起见,我们发现了解用户期望软件如何运行(或对其进行很好的估计)可以提供许多好处。特别是,它允许实际的、具体的软件行为,例如由经验程序提供的行为,与用户的期望进行比较。如果存在(大)差异,可以采取多种补救方法。最值得注意的是,可以通知软件开发人员,并要求他们纠正这种情况;其他替代方案包括对软件进行进一步的自动或手动审查,对市场上的软件进行不同的处理,甚至询问用户的意见。一些补救方法被认为适合实际应用,当测量证明它们对用户有明显的好处时。四.结论
在决定是否允许软件执行与安全相关的操作时,最好考虑软件过去执行过哪些操作的历史证据。对于流行的、广泛使用的软件,实际上有数十亿次的执行,从中提取历史证据,从而允许建立一个非常准确的“正常”软件执行构成的观点。此外,在大多数情况下,该相同的软件已经联网,并且可以向聚合这些证据的在线服务提供执行跟踪数据。
基于上述原因,可以建立一个独特的数据驱动软件安全模型。这种数据驱动模型不同于传统的异常和入侵检测方法,例如,它的全面性和与软件开发过程的集成。这个模型立即引起了对效率、隐私和实用性的关注,但是这些关注可以通过现有的技术和机制得到积极的解决。
尽管该模型的一般适用性和部署仍存在许多问题,但它的实施已经通过减少其攻击面为在某些重要领域运行的软件提供了实质性的安全效益,从而以防火墙非常成功地保护网络的方式保护软件。承认本文中的观点,得益于许多人的思想和工作。按字母顺序排列,感谢Mart n Abadi、Blake Bassett、Ludovico Cavedon、Andy Chu、Giulia Fanti、Iulia Ion、Suman Jana、Noah Johnson、Aleksandra Korolova、Karen Lees、Ilya Mironov、Martin Pelikan、Vasyl Pihur、Ananth Raghunathan、Sooel Son、Dawn Song、Michael Vrable、Moti Yung和Yinqian Zhang。还感谢Alessandra Gorla、Florian Gross和Andreas Zeller根据他们在[29]中的相关工作以及他们最近关于沙盒的工作的讨论进行合作[23]。
参考
[1] B. W. Lampson, “Protection,” SIGOPS Oper. Syst. Rev., vol. 8, no. 1,
pp. 18–24, Jan. 1974.
[2] J. H. Saltzer and M. D. Schroeder, “The protection of information in
computer systems,” Proceedings of the IEEE, vol. 63, no. 9, pp. 1278–
1308, Sept 1975.
[3] D. Wagner, “Object capabilities for security,” in Proceedings of the 2006
Workshop on Programming Languages and Analysis for Security, ser.
PLAS ’06. ACM, 2006, pp. 1–2.
[4] Z. Durumeric, J. Kasten, D. Adrian, J. A. Halderman, M. Bailey, F. Li,
N. Weaver, J. Amann, J. Beekman, M. Payer, and V. Paxson, “The
matter of Heartbleed,” in Proceedings of the 2014 Conference on Internet
Measurement Conference, ser. IMC ’14. ACM, 2014, pp. 475–488.
[5] B. W. Lampson, “Computer security in the real world,” Computer,
vol. 37, no. 6, pp. 37–46, June 2004.
[6] M. R. Clarkson and F. B. Schneider, “Hyperproperties,” in 2008 21st
IEEE Computer Security Foundations Symposium, June 2008, pp. 51–65.
[7] F. B. Schneider, “Enforceable security policies,” ACM Trans. Inf. Syst.
Secur., vol. 3, no. 1, pp. 30–50, Feb. 2000.
[8] G. Klein, K. Elphinstone, G. Heiser, J. Andronick, D. Cock, P. Derrin,
D. Elkaduwe, K. Engelhardt, R. Kolanski, M. Norrish, T. Sewell,
H. Tuch, and S. Winwood, “seL4: Formal verification of an OS kernel,”
in Proceedings of the ACM SIGOPS 22Nd Symposium on Operating
Systems Principles, ser. SOSP ’09. ACM, 2009, pp. 207–220.
[9] U. Erlingsson, “Low-level software security: Attacks and defenses,” ´
in Proceedings of Foundations of Security Analysis and Design IV,
A. Aldini and R. Gorrieri, Eds. Springer-Verlag, 2007, pp. 92–134.
[10] V. Kiriansky, D. Bruening, and S. P. Amarasinghe, “Secure execution
via program shepherding,” in Proceedings of the 11th USENIX Security
Symposium. USENIX Association, 2002, pp. 191–206.
[11] M. Abadi, M. Budiu, U. Erlingsson, and J. Ligatti, “Control-flow ´
integrity: Principles, implementations, and applications,” ACM Trans.
Inf. Syst. Secur., vol. 13, no. 1, pp. 4:1–4:40, Nov. 2009.
[12] D. Dhurjati, S. Kowshik, and V. Adve, “SAFECode: Enforcing alias
analysis for weakly typed languages,” in Proceedings of the 27th
ACM SIGPLAN Conference on Programming Language Design and
Implementation, ser. PLDI ’06. ACM, 2006, pp. 144–157.
[13] M. Castro, M. Costa, and T. Harris, “Securing software by enforcing
data-flow integrity,” in Proceedings of the 7th Symposium on Operating
Systems Design and Implementation, ser. OSDI ’06. USENIX Association, 2006, pp. 147–160.
[14] P. Akritidis, C. Cadar, C. Raiciu, M. Costa, and M. Castro, “Preventing
memory error exploits with WIT,” in 2008 IEEE Symposium on Security
and Privacy (sp 2008), May 2008, pp. 263–277.
[15] C. Tice, T. Roeder, P. Collingbourne, S. Checkoway, U. Erlingsson, ´
L. Lozano, and G. Pike, “Enforcing forward-edge control-flow integrity
in GCC & LLVM,” in Proceedings of the 23rd USENIX Conference
on Security Symposium, ser. SEC’14. USENIX Association, 2014, pp.
941–955.
[16] B. Zeng, G. Tan, and U. Erlingsson, “Strato: A retargetable framework ´
for low-level inlined-reference monitors,” in Proceedings of the 22Nd
USENIX Conference on Security, ser. SEC’13. USENIX Association,
2013, pp. 369–382.
[17] M. Abadi and C. Fournet, “Access control based on execution history,”
in In Proceedings of the 10th Annual Network and Distributed System
Security Symposium, 2003, pp. 107–121.
[18] C. Reis and S. D. Gribble, “Isolating web programs in modern browser
architectures,” in Proceedings of the 4th ACM European Conference on
Computer Systems, ser. EuroSys ’09. ACM, 2009, pp. 219–232.
[19] D. E. Denning, “An intrusion-detection model,” IEEE Transactions on
Software Engineering, vol. SE-13, no. 2, pp. 222–232, Feb 1987.
[20] V. Chandola, A. Banerjee, and V. Kumar, “Anomaly detection: A
survey,” ACM Comput. Surv., vol. 41, no. 3, pp. 15:1–15:58, Jul. 2009.
[Online]. Available: http://doi.acm.org/10.1145/1541880.1541882
[21] M. D. Ernst, J. Cockrell, W. G. Griswold, and D. Notkin, “Dynamically
discovering likely program invariants to support program evolution,” in
Proceedings of the 21st International Conference on Software Engineering, ser. ICSE ’99. ACM, 1999, pp. 213–224.
[22] S. Hangal and M. S. Lam, “Tracking down software bugs using
automatic anomaly detection,” in Proceedings of the 24th International
Conference on Software Engineering, ser. ICSE ’02. ACM, 2002, pp.
291–301.
[23] K. Jamrozik, P. von Styp-Rekowsky, and A. Zeller, “Mining sandboxes,”
in Proceedings of the 38th International Conference on Software Engineering, ser. ICSE 2016. ACM, 2016, p. (to appear).
[24] J. R. Douceur, “The Sybil attack,” in Revised Papers from the First International Workshop on Peer-to-Peer Systems, ser. IPTPS ’01. SpringerVerlag, 2002, pp. 251–260.
[25] D. Wagner and P. Soto, “Mimicry attacks on host-based intrusion
detection systems,” in Proceedings of the 9th ACM Conference on
Computer and Communications Security, ser. CCS ’02. ACM, 2002,
pp. 255–264.
[26] J. M. Anderson, L. M. Berc, J. Dean, S. Ghemawat, M. R. Henzinger,
S.-T. A. Leung, R. L. Sites, M. T. Vandevoorde, C. A. Waldspurger, and
W. E. Weihl, “Continuous profiling: Where have all the cycles gone?”
in Proceedings of the Sixteenth ACM Symposium on Operating Systems
Principles, ser. SOSP ’97. ACM, 1997, pp. 1–14.
[27] U. Erlingsson, V. Pihur, and A. Korolova, “RAPPOR: Randomized ´
aggregatable privacy-preserving ordinal response,” in Proceedings of
the 2014 ACM SIGSAC Conference on Computer and Communications
Security, ser. CCS ’14. ACM, 2014, pp. 1054–1067.
[28] S. Jana, U. Erlingsson, and I. Ion, “Apples and oranges: Detecting ´
least-privilege violators with peer group analysis,” CoRR, vol.
abs/1510.07308, 2015. [Online]. Available: http://arxiv.org/abs/1510.
07308
[29] A. Gorla, I. Tavecchia, F. Gross, and A. Zeller, “Checking app behavior
against app descriptions,” in Proceedings of the 36th International
Conference on Software Engineering, ser. ICSE 2014. ACM, 2014,
pp. 1025–1035.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









