






 本文详细介绍了PyTorch中的张量创建、索引、维度变换和广播操作,重点讲解了自动求导机制,包括雅可比矩阵和反向传播过程,并探讨了如何利用CUDA进行并行计算。通过实例展示了张量的构造、梯度计算及内存管理,同时提到了在多GPU环境下的数据并行计算策略。
本文详细介绍了PyTorch中的张量创建、索引、维度变换和广播操作,重点讲解了自动求导机制,包括雅可比矩阵和反向传播过程,并探讨了如何利用CUDA进行并行计算。通过实例展示了张量的构造、梯度计算及内存管理,同时提到了在多GPU环境下的数据并行计算策略。
第二章
2.1张量
创建
x = x.new_ones(4, 3, dtype=torch.double)
# 创建一个新的全1矩阵tensor,返回的tensor默认具有相同的torch.dtype和torch.device
# 也可以像之前的写法 x = torch.ones(4, 3, dtype=torch.double)
print(x)
x = torch.randn_like(x, dtype=torch.float)
# 重置数据类型
print(x)
# 结果会有一样的size
# 获取它的维度信息
print(x.size())
print(x.shape)
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
tensor([[ 2.7311, -0.0720, 0.2497],
[-2.3141, 0.0666, -0.5934],
[ 1.5253, 1.0336, 1.3859],
[ 1.3806, -0.6965, -1.2255]])
torch.Size([4, 3])
torch.Size([4, 3])
- 一维张量是向量
- 并非是pytorch特有的,是pytorch运算的基本单元,在pytorch中支持GPU运算与自动求导
常见的构造Tensor的方法:
| 函数 | 功能 |
|---|---|
| Tensor(sizes) | 基础构造函数 |
| tensor(data) | 类似于np.array |
| ones(sizes) | 全1 |
| zeros(sizes) | 全0 |
| eye(sizes) | 对角为1,其余为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀分成step份 |
| rand/randn(sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| randperm(m) | 随机排列 |
索引
需要注意的是:索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用copy()等方法
import torch
x = torch.rand(4,3)
y = x[0,:]
y += 1
print(y)
print(x[0, :]) # 源tensor也被改了了
tensor([3.7311, 0.9280, 1.2497])
tensor([3.7311, 0.9280, 1.2497])
维度变换
torch.view()和torch.reshape()
注: torch.view() 返回的新tensor与源tensor共享内存(其实是同一个tensor),更改其中的一个,另外一个也会跟着改变。(顾名思义,view()仅仅是改变了对这个张量的观察角度)
x += 1
print(x)
print(y) # 也加了了1
tensor([[ 1.3019, 0.3762, 1.2397, 1.3998],
[ 0.6891, 1.3651, 1.1891, -0.6744],
[ 0.3490, 1.8377, 1.6456, 0.8403],
[-0.8259, 2.5454, 1.2474, 0.7884]])
tensor([ 1.3019, 0.3762, 1.2397, 1.3998, 0.6891, 1.3651, 1.1891, -0.6744,
0.3490, 1.8377, 1.6456, 0.8403, -0.8259, 2.5454, 1.2474, 0.7884])
- 希望原始张量和变换后的张量互相不影响,即不共享内存,我们需要使用第二种方法torch.reshape(),同样可以改变张量的形状
- 但是此函数并不能保证返回的是其拷贝值,所以官方不推荐使用
- 推荐的方法是我们先用clone()创造一个张量副本然后再使用 torch.view()进行函数维度变换,还有一个好处是会被记录在计算图中,即梯度回传到副本时也会传到源 Tensor
广播

2.2自动求导
autograd
数学上,若有向量函数
y
⃗
=
f
(
x
⃗
)
\vec{y}=f(\vec{x})
y=f(x)(有m个因变量y和n个自变量x),那么
y
⃗
\vec{y}
y 关于
x
⃗
\vec{x}
x 的梯度就是一个雅可比矩阵:
$
J=\left(\begin{array}{ccc}\frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \ \vdots & \ddots & \vdots \ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}}\end{array}\right)
$
还有复合函数的链式求导法则
而 torch.autograd 这个包就是用来计算一些雅可比矩阵的乘积的。例如,如果
v
v
v 是一个标量函数
l
=
g
(
y
⃗
)
l = g(\vec{y})
l=g(y) 的梯度 (损失函数
l
l
l对输出
y
y
y的导数):
$
v=\left(\begin{array}{lll}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right)
$
由链式法则,我们可以得到 (把
y
y
y往
x
x
x传即为雅格比矩阵,即损失函数
l
l
l对输入
x
x
x的导数):
$
v J=\left(\begin{array}{lll}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right)\left(\begin{array}{ccc}\frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \ \vdots & \ddots & \vdots \ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}}\end{array}\right)=\left(\begin{array}{lll}\frac{\partial l}{\partial x_{1}} & \cdots & \frac{\partial l}{\partial x_{n}}\end{array}\right)
$
注意:grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
1. 神经网络反向传播是复合函数求导的过程。每一层都是一个函数,从后往前传。后一层m个节点,前一层n个节点,即每一层都有一个雅格比矩阵。pytorch自动求导实际上提供了计算雅格比乘积的工具
2. 动态计算图DCG:张量和运算结合起来创建的
1. is_leaf,是
1. 首先requires_grad这个是看用户需求进行设定,如果为false则把你视为叶子节点
2. requires_grad=False and is_leaf=True,则不计算该张量的grad。,也就是到了最开始的那一层
3. requires_grad=True and is_leaf=True,则计算该张量的grad,并且把计算得到的grad放到该张量的grad属性里面
4. requires_grad=True and is_leaf=False, 不保留grad
5. requires_grad=True and is_leaf=False,即非叶子节点,可以通过retain_grad()来得到grad
2. 只有由其他张量运算得到的张量才有梯度,即requires_grad=True
3. 静态图与动态图的区别:不需要预先定义计算图结构
3. 如果定义x时定义requires_grad=True,则仅反向传播以后,即z.backward(),才有梯度,即x.grad.data
4. 如果定义x时定义requires_grad=False,则仅正向传播即z有值,反向传播z.backward()会出错
torch.Tensor是这个包的核心类。如果设置它的属性.requires_grad为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用.backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性- 在
y.backward()时,如果 y 是标量,则不需要为 backward() 传入任何参数;否则,需要传入一个与 y 同形的Tensor - 要阻止一个张量被跟踪历史,可以调用
.detach()方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch.no_grad():中。在评估模型时特别有用,因为模型可能具有requires_grad = True的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算,一劳永逸
- 在
- Tensor和Function 互相连接生成了一个无环图,它编码了完整的计算历史。每个张量都有一个
.grad_fn属性,该属性引用了创建 Tensor自身的Function- 当这个张量是用户手动创建时,这个张量的grad_fn是 None
- 如果需要计算导数,可以在
Tensor上调用.backward()。如果Tensor是一个标量(即它包含一个元素的数据),则不需要为backward()指定任何参数,但是如果它有更多的元素,则需要指定一个gradient参数,该参数是形状匹配的张量
创建一个张量并设置requires_grad=True用来追踪其计算历史
x = torch.ones(2, 2, requires_grad=True)
print(x)
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
对这个张量做一次运算:
y = x**2
print(y)
tensor([[1., 1.],
[1., 1.]], grad_fn=<PowBackward0>)
y是计算的结果,所以它有grad_fn属性。
print(y.grad_fn)
<PowBackward0 object at 0x000001CB45988C70>
对 y 进行更多操作
z = y * y * 3
out = z.mean()
print(z, out)
tensor([[3., 3.],
[3., 3.]], grad_fn=<MulBackward0>) tensor(3., grad_fn=<MeanBackward0>)
.requires_grad_(...) 原地改变了现有张量的requires_grad标志。如果没有指定的话,默认输入的这个标志是 False(下方)
a = torch.randn(2, 2) # 缺失情况下默认 requires_grad = False
a = ((a * 3) / (a - 1))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b.grad_fn)
False
True
<SumBackward0 object at 0x000001CB4A19FB50>
梯度
现在开始进行反向传播,因为 out 是一个标量(x,out见上述),因此out.backward()和 out.backward(torch.tensor(1.)) 等价
out.backward()
输出导数 d(out)/dx
print(x.grad)
tensor([[3., 3.],
[3., 3.]])
- grad在反向传播过程中是累加的,这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。下面的例子解释了清0与不清0的区别
# 再来反向传播⼀次,注意grad是累加的
out2 = x.sum()
out2.backward()
print(x.grad)
tensor([[4., 4.],
[4., 4.]])
out3 = x.sum()
x.grad.data.zero_()
out3.backward()
print(x.grad)
tensor([[1., 1.],
[1., 1.]])
- 现在我们来看一个雅可比向量积的例子:
x = torch.randn(3, requires_grad=True)
print(x)
y = x * 2
i = 0
while y.data.norm() < 1000: #首先,它对张量y每个元素进行平方,然后对它们求和,最后取平方根。 这些操作计算就是所谓的L2或欧几里德或p范数
y = y * 2
i = i + 1
print(y)
print(i)
tensor([-0.9332, 1.9616, 0.1739], requires_grad=True)
tensor([-477.7843, 1004.3264, 89.0424], grad_fn=<MulBackward0>)
8
- 在这种情况下,
y不再是标量。torch.autograd不能直接计算完整的雅可比矩阵,但是如果我们只想要雅可比向量积,只需将这个向量作为参数传给backward:
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v) #因为y不是标量,所以要指定backward梯度图的形状。v的数据可以随意,但形式要是和x的梯度维度相同
print(x.grad)
tensor([5.1200e+01, 5.1200e+02, 5.1200e-02])
- 也可以通过将代码块包装在
with torch.no_grad():中,来阻止 autograd 跟踪设置了.requires_grad=True的张量的历史记录
print(x.requires_grad)
print((x ** 2).requires_grad)
with torch.no_grad():
print((x ** 2).requires_grad)
True
True
False
- 如果我们想要修改 tensor 的数值,但是又不希望被 autograd 记录(即不会影响反向传播), 那么我们可以对 tensor.data 进行操作
x = torch.ones(1,requires_grad=True)
print(x.data) # 还是一个tensor
print(x.data.requires_grad) # 但是已经是独立于计算图之外
y = 2 * x
x.data *= 100 # 只改变了值,不会记录在计算图,所以不会影响梯度传播
y.backward()
print(x) # 更改data的值也会影响tensor的值
print(x.grad)
tensor([1.])
False
tensor([100.], requires_grad=True)
tensor([2.])
2.3并行计算
数据量较大无法在单块GPU上完成,或者需要提升计算速度的场景,且大batch能提升训练效果,这时就需要用到并行计算(使用cuda)
cuda
- 在编写程序中,当我们使用了 .cuda() 时,其功能是让我们的模型或者数据从CPU迁移到GPU(0)当中,通过GPU开始计算
- 数据在GPU和CPU之间进行传递时会比较耗时,我们应当尽量避免数据的切换
- GPU运算很快,但是在使用简单的操作时,我们应该尽量使用CPU去完成
- 当我们的服务器上有多个GPU,我们应该指明我们使用的GPU是哪一块,如果我们不设置的话,tensor.cuda()方法会默认将tensor保存到第一块GPU上,等价于tensor.cuda(0),这将会导致爆出
out of memory的错误。我们可以通过以下两种方式继续设置。
#设置在文件最开始部分 import os os.environ["CUDA_VISIBLE_DEVICE"] = "2" # 设置默认的显卡``` CUDA_VISBLE_DEVICE=0,1 python train.py # 使用0,1两块GPU ``` - 主流方式是数据并行的方式(Data parallelism)
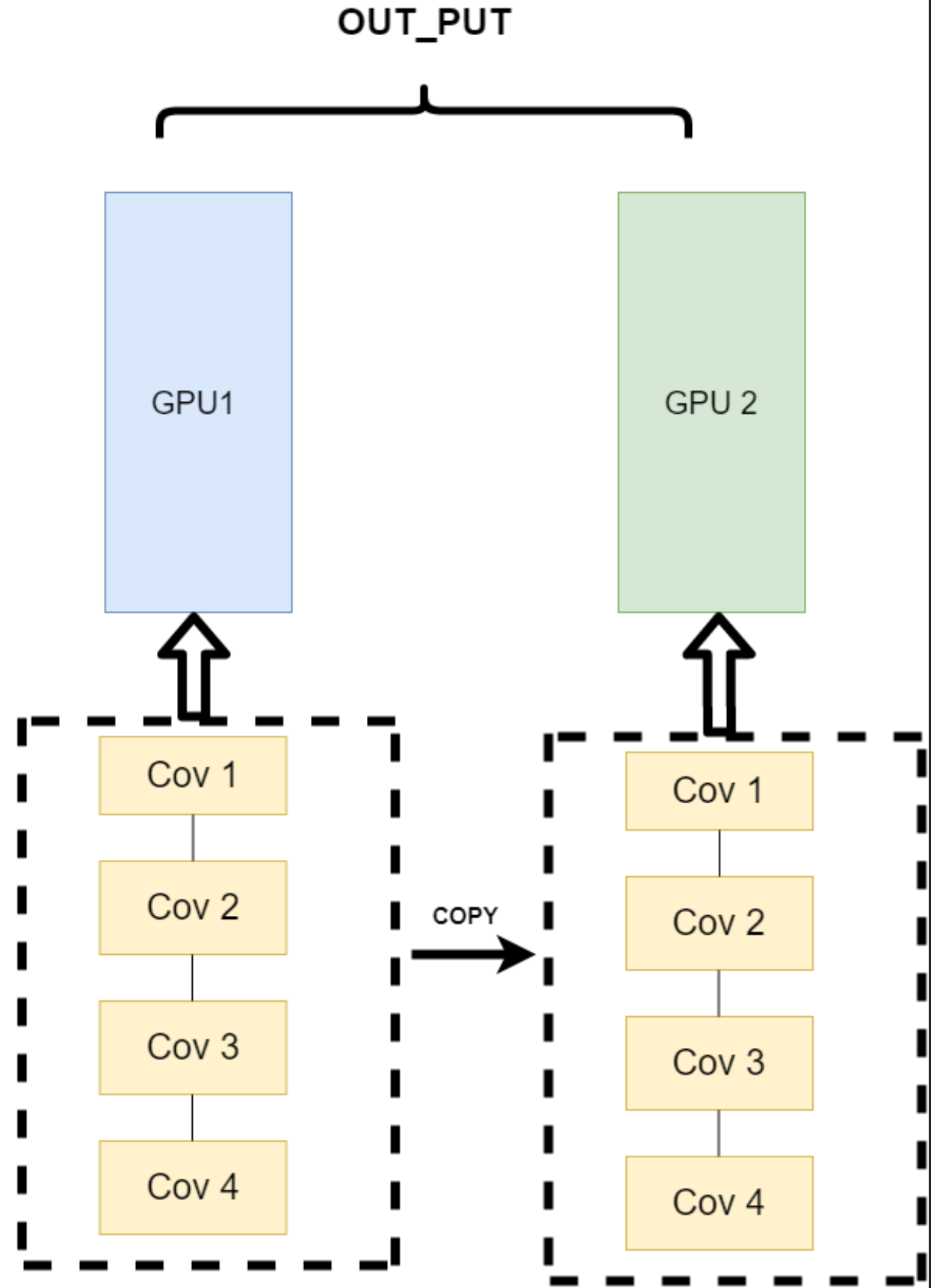
我不再拆分模型,我训练的时候模型都是一整个模型。但是我将输入的数据拆分。所谓的拆分数据就是,同一个模型在不同GPU中训练一部分数据,然后再分别计算一部分数据之后,只需要将输出的数据做一个汇总,然后再反转。其架构如下:















 7471
7471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









