







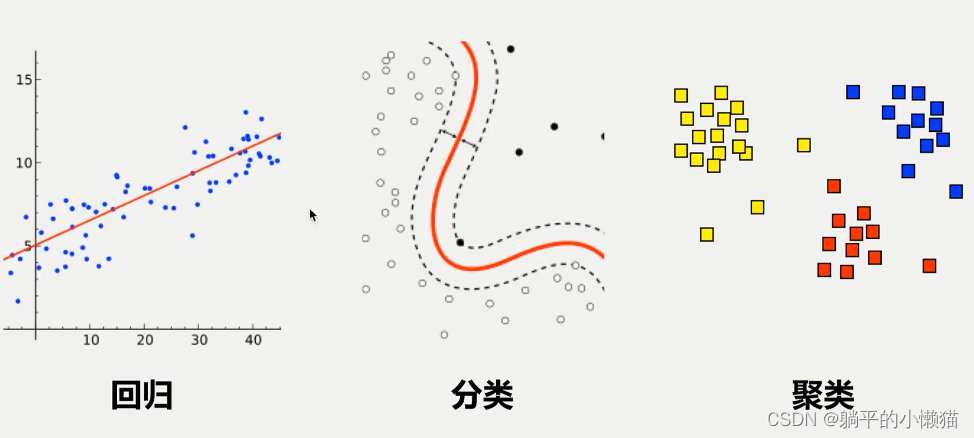
数据结构与算法之回归算法
回归算法是一类用于建立变量之间关系的统计模型,主要用于预测和分类。在数据科学和机器学习领域,回归算法是非常重要的一种算法。
回归算法有很多种,比如线性回归、岭回归、Lasso回归、逻辑回归等等。这些算法的原理都是基于经验风险最小化(ERM)和结构风险最小化(SRM)的思想。
经验风险最小化是指通过最小化训练数据上的损失函数来寻找最优的模型参数。损失函数是衡量模型预测值和实际值之间差异的函数。常用的损失函数有均方误差(MSE)、平均绝对误差(MAE)等。
结构风险最小化是指在最小化经验风险的同时,也要考虑模型的复杂度,以避免过拟合。过拟合是指模型过于复杂,导致在训练数据上表现良好,但在测试数据上表现不好的现象。结构风险最小化的代表算法是岭回归和Lasso回归。
除了经验风险最小化和结构风险最小化外,回归算法还涉及到梯度下降、正则化、交叉验证等概念。这些都是算法原理的重要组成部分。
总之,回归算法是一种强大的统计工具,对数据科学和机器学习都有着重要的意义。理解回归算法的原理是深入掌握数据科学和机器学习的必要前提之一。
一、C 实现回归算法及代码详解
回归算法是一种机器学习算法,用于预测数值型变量的值。它可以帮助我们理解变量之间的关系,并预测任何给定的输入值的输出值。其中常见的回归算法有线性回归、多项式回归、岭回归、Lasso回归等。
以下是使用 C 语言实现线性回归算法的示例代码。
#include <stdio.h>
#define MAX_ITER 10000 // 最大迭代次数
#define ALPHA 0.01 // 学习率
double h(double x[], double w[], int n) {
double result = 0.0;
for (int i = 0; i < n; i++) {
result += x[i] * w[i];
}
return result;
}
int main() {
int m = 5; // 样本数量
int n = 2; // 特征数量
double x[][2] = { // 样本特征
{1.0, 2.0},
{2.0, 4.0},
{3.0, 6.0},
{4.0, 8.0},
{5.0, 10.0}
};
double y[] = { // 样本标签
2.0,
4.0,
6.0,
8.0,
10.0
};
double w[] = {0.0, 0.0}; // 初始化权重
double cost = 0.0;
int iter = 0;
while (iter < MAX_ITER) {
for (int i = 0; i < m; i++) {
double y_hat = h(x[i], w, n);
double error = y_hat - y[i];
for (int j = 0; j < n; j++) {
w[j] = w[j] - ALPHA * error * x[i][j];
}
cost += error * error / (2 * m);
}
printf("Iter: %d\t Cost: %lf\n", iter, cost);
iter++;
cost = 0.0;
}
printf("Final Weights: w0 = %lf, w1 = %lf\n", w[0], w[1]);
return 0;
}
在上述代码中,我们先定义了样本数量和特征数量。然后定义了样本特征和标签。接着初始化了权重(假设我们的模型只有两个特征,所以权重也只有两个)。在训练过程中,我们根据样本特征和当前权重计算预测值,计算误差,然后更新权重,最后计算损失函数并输出。迭代达到最大次数或者损失函数已经收敛时,输出最终权重。
需要注意的是,在实际应用中,我们通常需要对样本特征进行归一化处理,以避免不同特征的权重差异过大。此外,在实际应用中,我们还可能需要使用更复杂的模型(如多项式回归、岭回归、Lasso回归等),并进行模型选择和调参处理。

二、C++ 实现回归算法及代码详解
回归算法是一种统计学习方法,目的是预测一个或多个数值型的目标变量。它通过对已有数据的学习,建立一个预测模型,预测新数据的输出。
在本文中,我们将讨论C++中的三个回归算法:线性回归、逻辑回归和决策树回归,并提供相应的代码示例。
- 线性回归
线性回归是最简单的回归算法之一,它建立一个线性方程来预测数值型目标变量。这个方程由输入特征和对应的权值组成,通过调整权值来最小化预测值和真实值之间的误差。
代码示例:
#include <iostream>
#include <vector>
#include <cmath>
using namespace std;
const double learning_rate = 0.01;
double predict(vector<double>& features, vector<double>& weights) {
double result = 0.0;
for (int i = 0; i < features.size(); ++i) {
result += features[i] * weights[i];
}
return result;
}
void train(vector<vector<double>>& features, vector<double>& targets, vector<double>& weights, int num_epochs) {
for (int epoch = 0; epoch < num_epochs; ++epoch) {
double sum_error = 0.0;
for (int i = 0; i < features.size(); ++i) {
double error = targets[i] - predict(features[i], weights);
sum_error += pow(error, 2);
for (int j = 0; j < weights.size(); ++j) {
weights[j] += learning_rate * error * features[i][j];
}
}
cout << "epoch " << epoch << ", error " << sqrt(sum_error / targets.size()) << endl;
}
}
int main() {
vector<vector<double>> features {{1.0, 2.0}, {2.0, 3.0}, {3.0, 4.0}, {4.0, 5.0}, {5.0, 6.0}};
vector<double> targets {3.0, 4.0, 5.0, 6.0, 7.0};
vector<double> weights {0.0, 0.0};
int num_epochs = 500;
train(features, targets, weights, num_epochs);
cout << "final weights: " << weights[0] << ", " << weights[1] << endl;
return 0;
}
以上代码实现了线性回归算法,包括预测和训练两个函数。在训练期间,我们计算误差并通过梯度下降算法更新权值。在最后,我们输出了学习到的权值,表示训练结果。
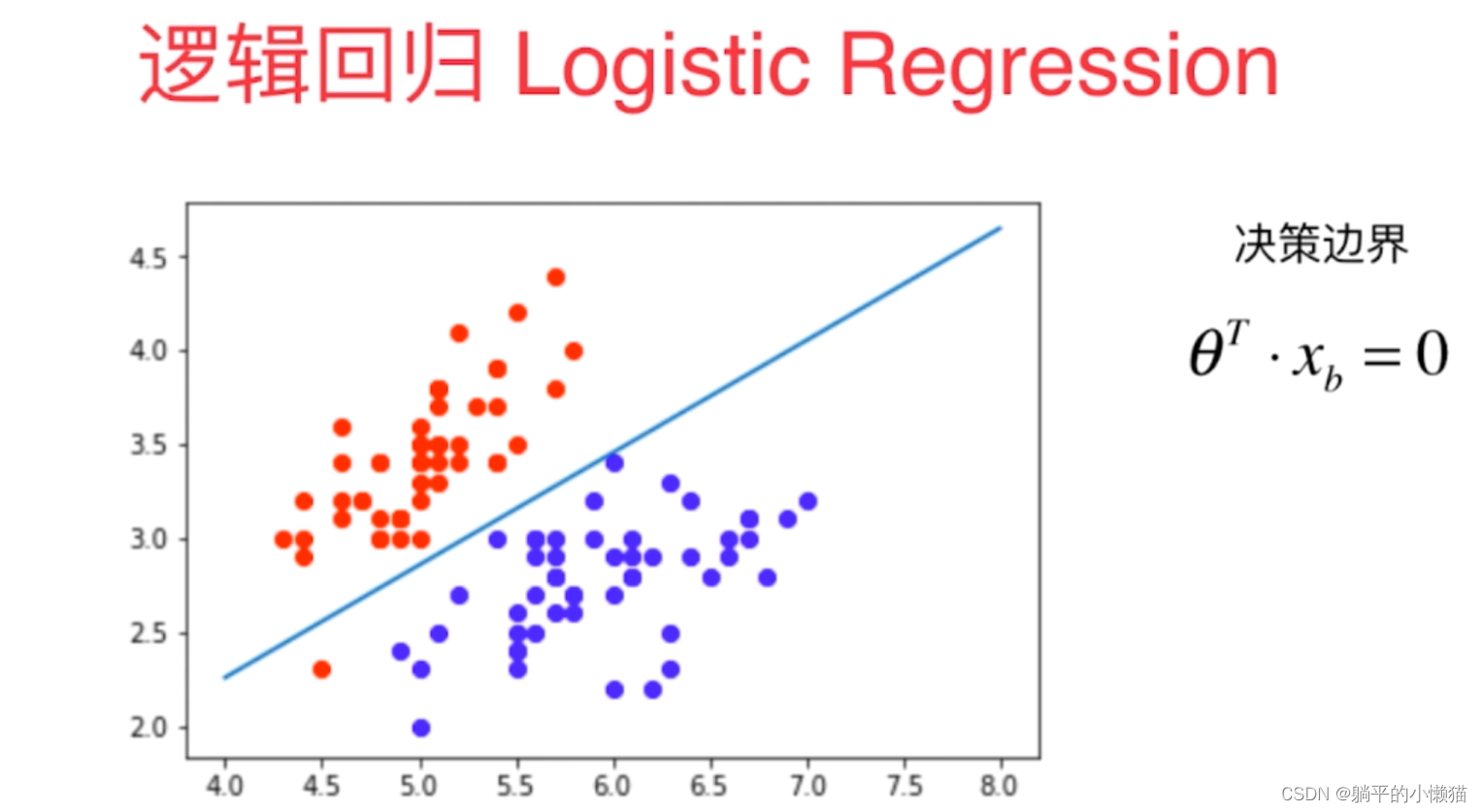
- 逻辑回归
逻辑回归是一种广泛使用的分类算法,它将输入特征与一个sigmoid函数组合,产生的输出是一个介于0和1之间的概率值。通过比较预测概率和阈值,可以将样本划分为正类或负类。
代码示例:
#include <iostream>
#include <vector>
#include <cmath>
using namespace std;
const double learning_rate = 0.01;
double sigmoid(double x) {
return 1.0 / (1.0 + exp(-x));
}
double predict(vector<double>& features, vector<double>& weights) {
double result = 0.0;
for (int i = 0; i < features.size(); ++i) {
result += features[i] * weights[i];
}
return sigmoid(result);
}
void train(vector<vector<double>>& features, vector<double>& targets, vector<double>& weights, int num_epochs) {
for (int epoch = 0; epoch < num_epochs; ++epoch) {
double sum_error = 0.0;
for (int i = 0; i < features.size(); ++i) {
double error = targets[i] - predict(features[i], weights);
sum_error += pow(error, 2);
for (int j = 0; j < weights.size(); ++j) {
weights[j] += learning_rate * error * features[i][j] * predict(features[i], weights) * (1 - predict(features[i], weights));
}
}
cout << "epoch " << epoch << ", error " << sqrt(sum_error / targets.size()) << endl;
}
}
int main() {
vector<vector<double>> features {{1.0, 2.0}, {2.0, 3.0}, {3.0, 4.0}, {4.0, 5.0}, {5.0, 6.0}};
vector<double> targets {0.0, 0.0, 1.0, 1.0, 1.0};
vector<double> weights {0.0, 0.0};
int num_epochs = 500;
train(features, targets, weights, num_epochs);
cout << "final weights: " << weights[0] << ", " << weights[1] << endl;
return 0;
}
以上代码实现了逻辑回归算法,包括sigmoid函数、预测和训练两个函数。在训练期间,我们计算误差并通过梯度下降算法更新权值。在最后,我们输出了学习到的权值,表示训练结果。
- 决策树回归
决策树回归是一种基于决策树的回归算法,它将输入特征与对应的输出目标分成多个小区间,然后逐步逼近真实目标值。在预测时,从根节点开始,沿着特征的取值不断向下走,最终到达叶节点,将叶节点的输出值作为预测结果。
代码示例:
#include <iostream>
#include <vector>
#include <cmath>
using namespace std;
const int max_depth = 10;
const int min_leaf_samples = 5;
class DecisionTree {
public:
DecisionTree(int max_depth, int min_leaf_samples) :
max_depth_(max_depth), min_leaf_samples_(min_leaf_samples),
feature_index_(-1), threshold_(0.0), left_(nullptr), right_(nullptr),
is_leaf_(false), leaf_value_(0.0) {}
void fit(vector<vector<double>>& features, vector<double>& targets) {
fit_recur(features, targets, 0);
}
double predict(vector<double>& features) {
if (is_leaf_) {
return leaf_value_;
}
if (features[feature_index_] < threshold_) {
return left_->predict(features);
} else {
return right_->predict(features);
}
}
private:
void fit_recur(vector<vector<double>>& features, vector<double>& targets, int depth) {
if (targets.size() < min_leaf_samples_ || depth >= max_depth_) {
is_leaf_ = true;
leaf_value_ = mean(targets);
return;
}
int num_features = features[0].size();
double best_error = INFINITY;
for (int i = 0; i < num_features; ++i) {
for (int j = 0; j < features.size(); ++j) {
double threshold = features[j][i];
vector<vector<double>> left_features, right_features;
vector<double> left_targets, right_targets;
for (int k = 0; k < features.size(); ++k) {
if (features[k][i] < threshold) {
left_features.push_back(features[k]);
left_targets.push_back(targets[k]);
} else {
right_features.push_back(features[k]);
right_targets.push_back(targets[k]);
}
}
if (left_targets.size() < min_leaf_samples_ || right_targets.size() < min_leaf_samples_) {
continue;
}
double error = mse(left_targets) + mse(right_targets);
if (error < best_error) {
feature_index_ = i;
threshold_ = threshold;
best_error = error;
left_ = new DecisionTree(max_depth_, min_leaf_samples_);
left_->fit_recur(left_features, left_targets, depth + 1);
right_ = new DecisionTree(max_depth_, min_leaf_samples_);
right_->fit_recur(right_features, right_targets, depth + 1);
}
}
}
}
double mean(vector<double>& targets) {
double sum = 0.0;
for (int i = 0; i < targets.size(); ++i) {
sum += targets[i];
}
return sum / targets.size();
}
double mse(vector<double>& targets) {
double sum =
三、Java 实现回归算法及代码详解
回归算法是机器学习中常用的算法之一,用于预测连续值的输出。常见的回归算法有线性回归、多项式回归、岭回归、Lasso回归等等。在本文中,我们将介绍如何使用Java语言实现线性回归和多项式回归算法,并提供相应的代码。
- 线性回归
线性回归是最简单的回归算法之一,其思路是找到一条直线,使得该直线能够最好地拟合数据集。这条直线的形式可以表示为y = b0 + b1*x,其中b0和b1是待求的参数,x为特征,y为标签。
实现线性回归的过程如下:
1)初始化参数b0和b1为0或者随机值。
2)通过最小化误差平方和来求解参数b0和b1,误差平方和的计算公式为:Sum of (y - predicted_y)^2,其中y为实际值,predicted_y为预测值。
3)通过优化算法(如梯度下降)不断调整参数b0和b1,直至找到最优值。
Java代码实现:
public class LinearRegression {
private double b0; //参数 b0
private double b1; //参数 b1
public void train(double[] x, double[] y, double alpha, int epochs) {
int n = x.length;
for (int i = 0; i < epochs; i++) {
double b0_gradient = 0;
double b1_gradient = 0;
for (int j = 0; j < n; j++) {
double y_pred = predict(x[j]);
b0_gradient += (y_pred - y[j]);
b1_gradient += (y_pred - y[j]) * x[j];
}
b0_gradient *= 2.0 / n;
b1_gradient *= 2.0 / n;
b0 -= alpha * b0_gradient;
b1 -= alpha * b1_gradient;
}
}
public double predict(double x) {
return b0 + b1 * x;
}
}
上述代码中,train()方法用于训练模型,alpha是学习率,epochs是迭代次数;predict()方法用于给出预测值。
- 多项式回归
多项式回归是通过使用多项式函数来拟合数据集,其中每个数据点都表示为(x, y),其中x是一个特征,y是一个标签。多项式回归的目标是找到一个具有最佳拟合度的多项式函数。
实现多项式回归的过程如下:
1)初始化参数w为0或者随机值。
2)将输入数据x转化为多项式特征,如将一元二次方程y = a*x^2 + b*x + c转化为y = w1*x^2 + w2*x + w3,其中w1、w2和w3为待求的参数。
3)通过最小化误差平方和来求解参数w,误差平方和的计算公式同线性回归。
4)通过优化算法(如梯度下降)不断调整参数w,直至找到最优值。
Java代码实现:
public class PolynomialRegression {
private double[] w; //参数 w
public void train(double[] x, double[] y, double alpha, int epochs, int degree) {
int n = x.length;
double[][] X = new double[n][degree + 1];
for (int i = 0; i < n; i++) {
for (int j = 0; j < degree + 1; j++) {
X[i][j] = Math.pow(x[i], j);
}
}
w = new double[degree + 1];
for (int i = 0; i < epochs; i++) {
double[] error = new double[n];
for (int j = 0; j < n; j++) {
double y_pred = predict(x[j]);
error[j] = y_pred - y[j];
}
for (int j = 0; j < degree + 1; j++) {
double w_gradient = 0;
for (int k = 0; k < n; k++) {
w_gradient += error[k] * X[k][j];
}
w_gradient *= 2.0 / n;
w[j] -= alpha * w_gradient;
}
}
}
public double predict(double x) {
double y_pred = 0;
for (int i = 0; i < w.length; i++) {
y_pred += w[i] * Math.pow(x, i);
}
return y_pred;
}
}
上述代码中,train()方法用于训练模型,alpha是学习率,epochs是迭代次数,degree是多项式的阶数;predict()方法用于给出预测值。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









