







WordCount 的具体步骤可参考上一篇:Spark 第一个项目(WordCount)
本篇可作为上一篇的扩展!
上一篇程序:
WorkCount本篇程序:
WorkCountApplication
1. WordCount
1.1 修改程序
对上一篇的程序进行修改:
package wcApplication
import org.apache.spark.{SparkConf, SparkContext}
object WorkCountApplication {
def main(args: Array[String]): Unit = {
var Path = args(0)
var savePath = args(1)
// 配置文件
val conf = new SparkConf()
.setAppName("WorkCountApplication")
// SparkContext
val sc = new SparkContext(conf)
// 操作
sc.textFile(Path)
.flatMap(_.split("\\s+"))
.map(_.toLowerCase().replaceAll("\\W",""))
.map((_, 1))
.reduceByKey(_+_)
.sortBy(_._2, false)
.saveAsTextFile(savePath)
// 停止任务,关闭连接
sc.stop()
}
}
说明:
以上,并没有设置实际的参数,而是利用
main方法中的args来传递参数
args(0)、args(1)两个参数分别表示:源文件路径、保存路径这样在集群上提交任务时,可根据实际情况再传递参数。
⚠️ 注意:这里的
conf对象没有设置 Master,留到集群提交时再指定,只为避免冲突!
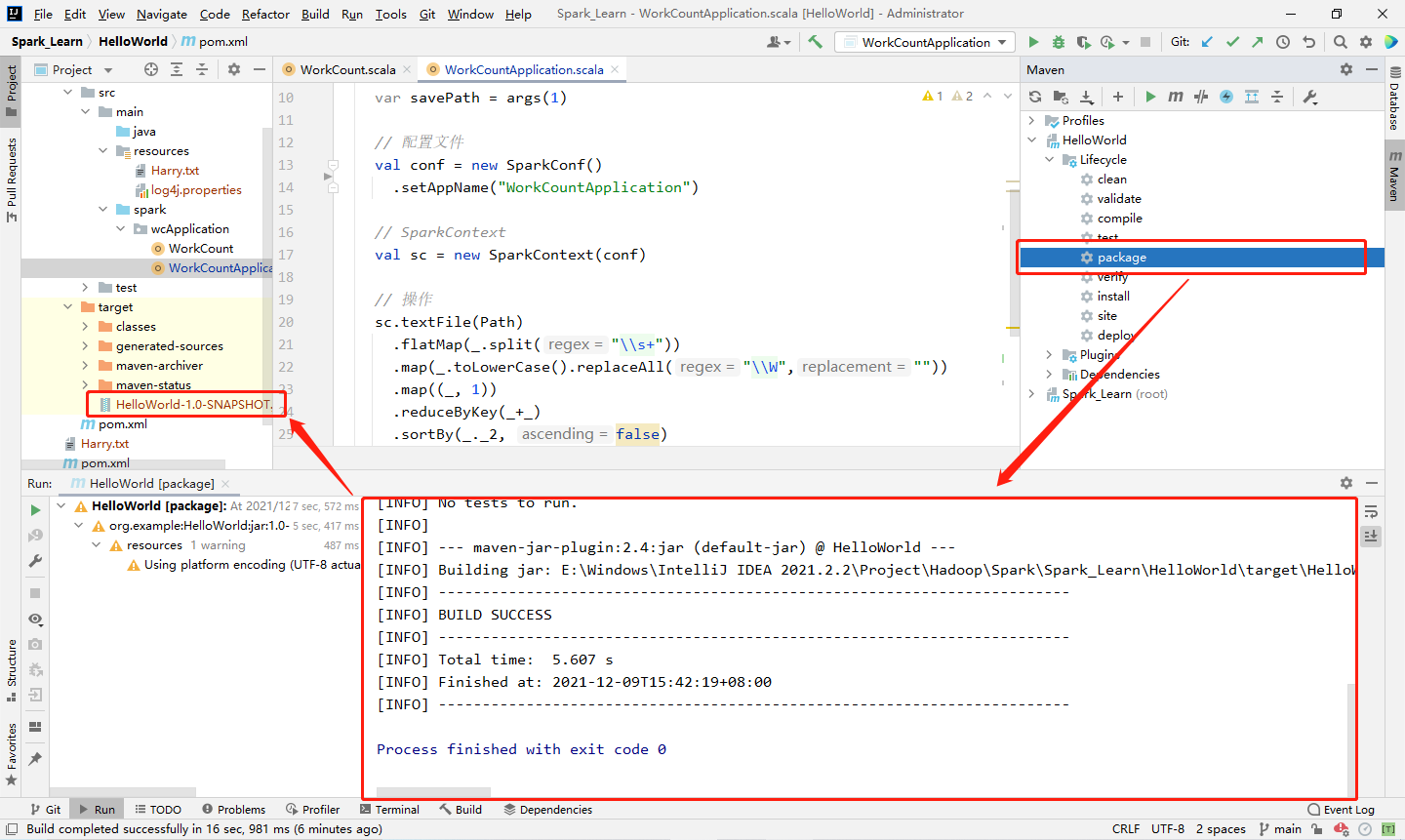
1.2 项目打包
将项目打成 jar 包,并上传至集群。
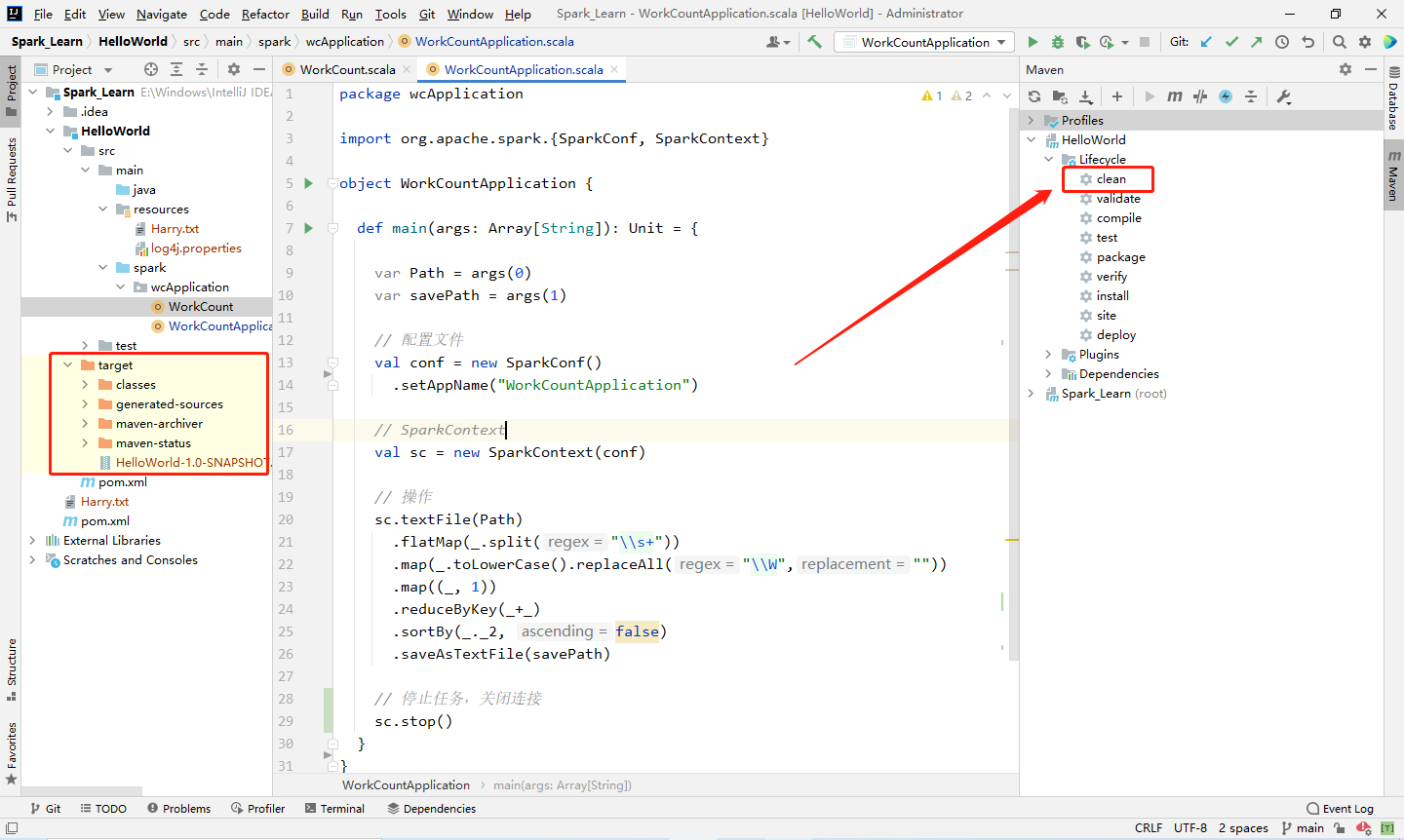
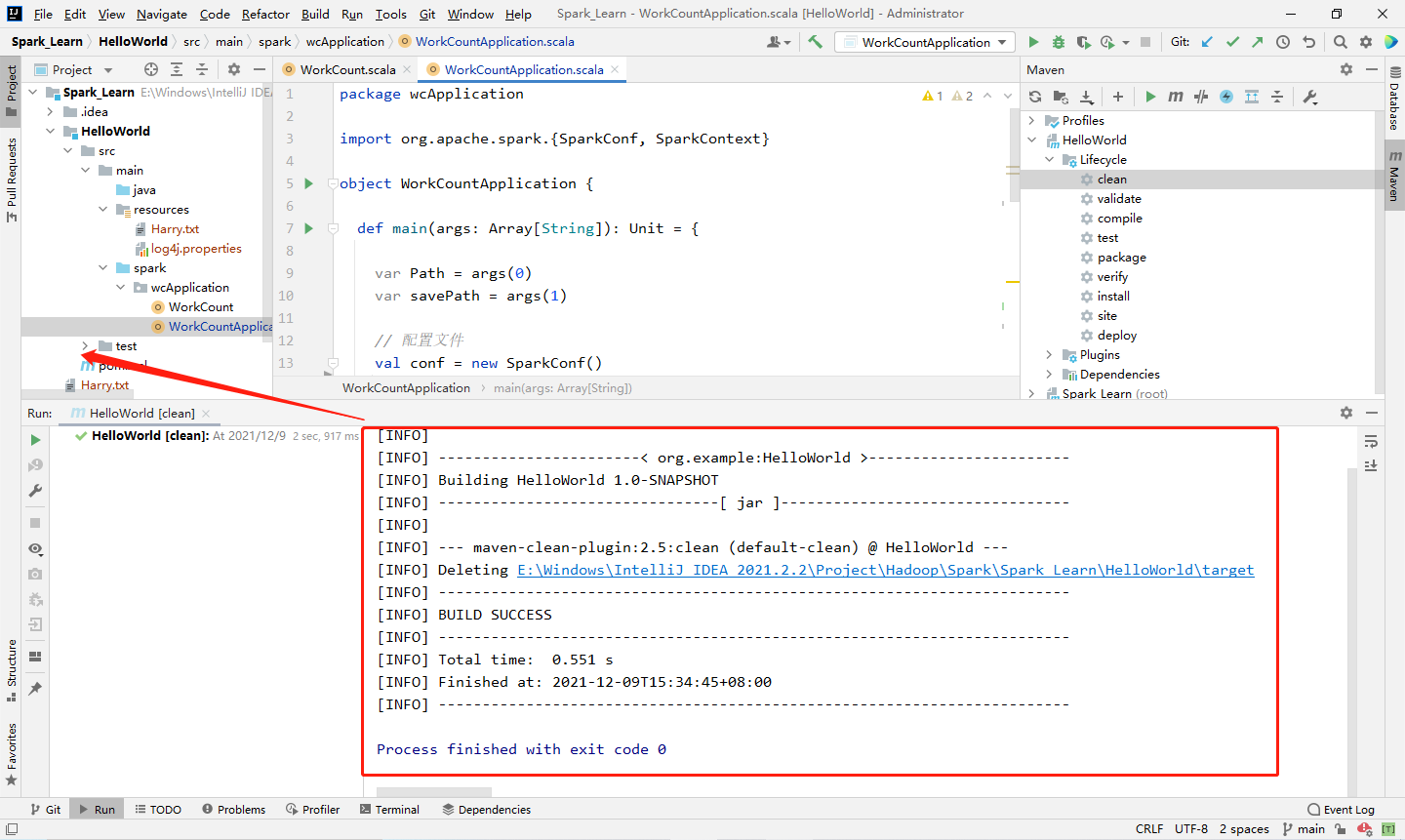
1️⃣ Step1:在 IDEA 右边栏的 Maven 中打开本项目中 Lifecycle 的 clean,清空一遍之前的编译文件,清理后左侧 target 目录中的编译文件就应该都被删除了(里面有个jar包,因为我打过一遍了,不影响,会一起被删除)。
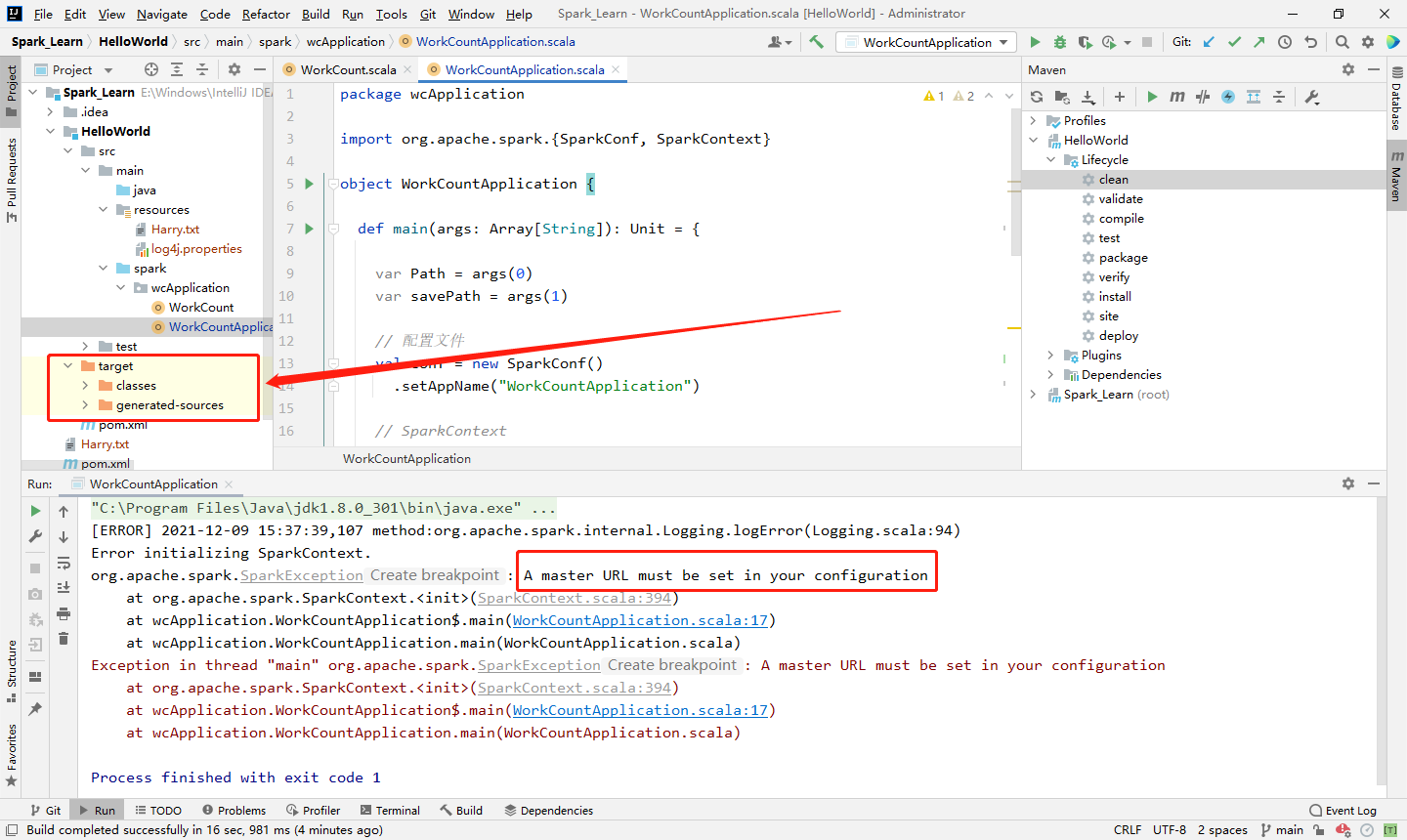
2️⃣ Step2:在当前程序下,重新编译此项目。由于main方法没有传入参数,会一个Spark的错误(没设置 master URL,因为在上文中被删了),不用管,此时编译文件已经重新生成了。
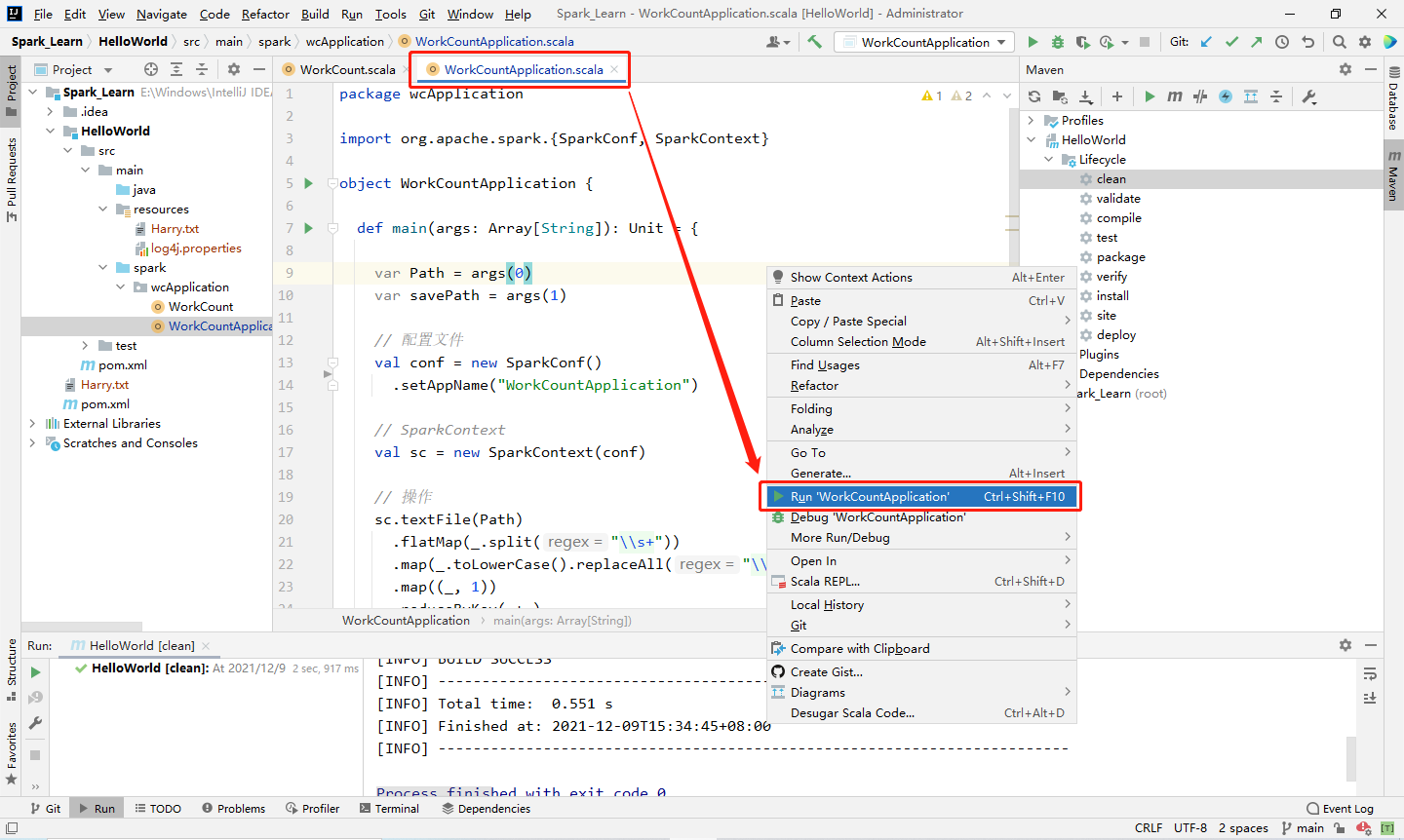
3️⃣ Step3:双击侧边栏的 package 将程序打包,生成的 jar 包在 target 目录下。
1.3 提交项目
将打包的 jar 包上传至集群(主节点),并通过命令提交该任务(应用)。
1️⃣ Step1:提交命令
提交命令如下:
spark-submit \
--class wcApplication.WorkCountApplication \
--master spark://node1:7077 \
/opt/spark-3.1.2/SparkApp/HelloWorld-1.0-SNAPSHOT.jar \
hdfs://node1:8020/SparkApp/Harry.txt \
hdfs://node1:8020/SparkApp/Succ6
来解剖下提交命令:
spark-submit用于提交应用--class代表应用(项目)的主类--master设定运行模式,这里设置为主节点的 7077 端口,表示连接到 Spark 集群/opt/spark-3.1.2/SparkApp/HelloWorld-1.0-SNAPSHOT.jar是 jar 包所在的绝对路径hdfs://node1:8020/SparkApp/Harry.txt第一个参数,即args[0],表示源文件路径hdfs://node1:8020/SparkApp/Succ6第二个参数,即args[1],表示保存的路径
修改为自己的 jar包、参数即可!
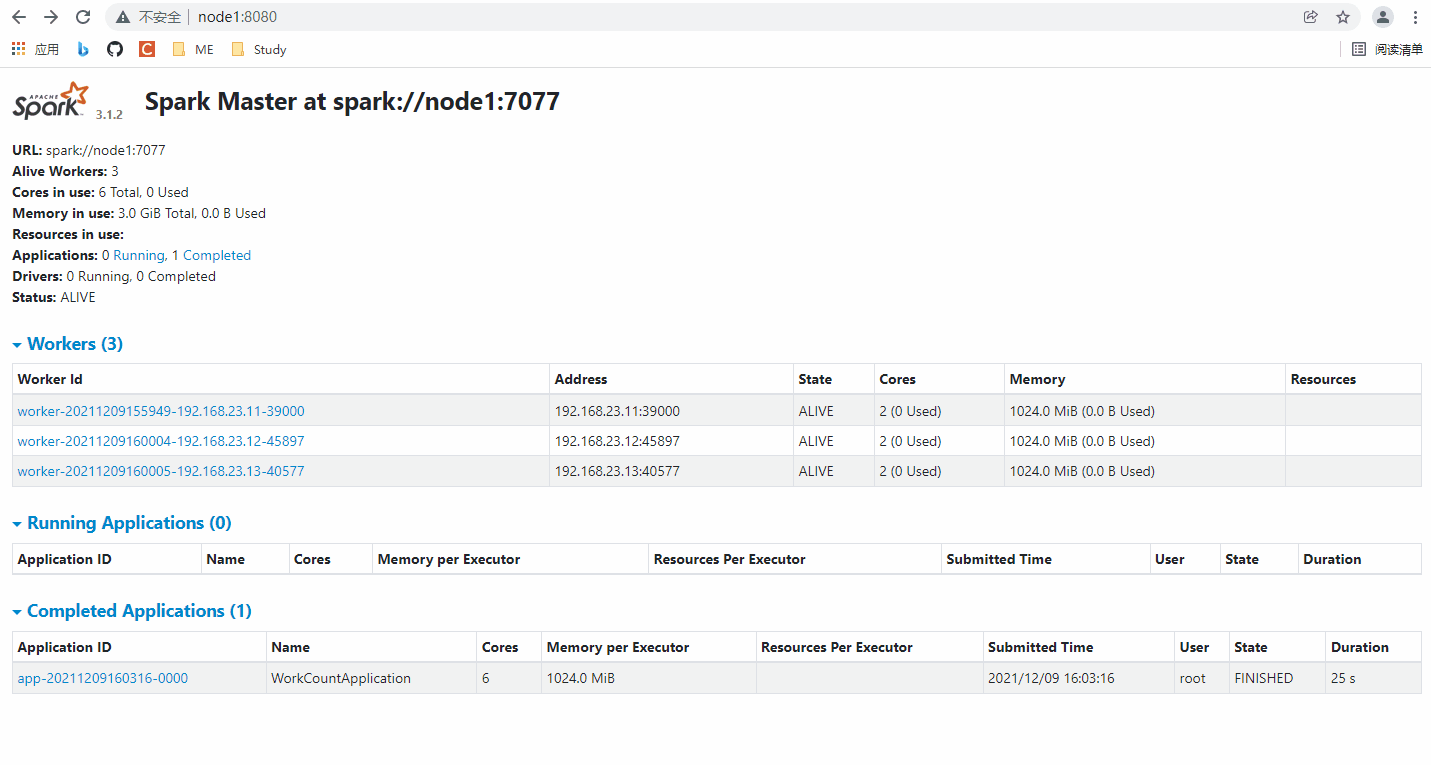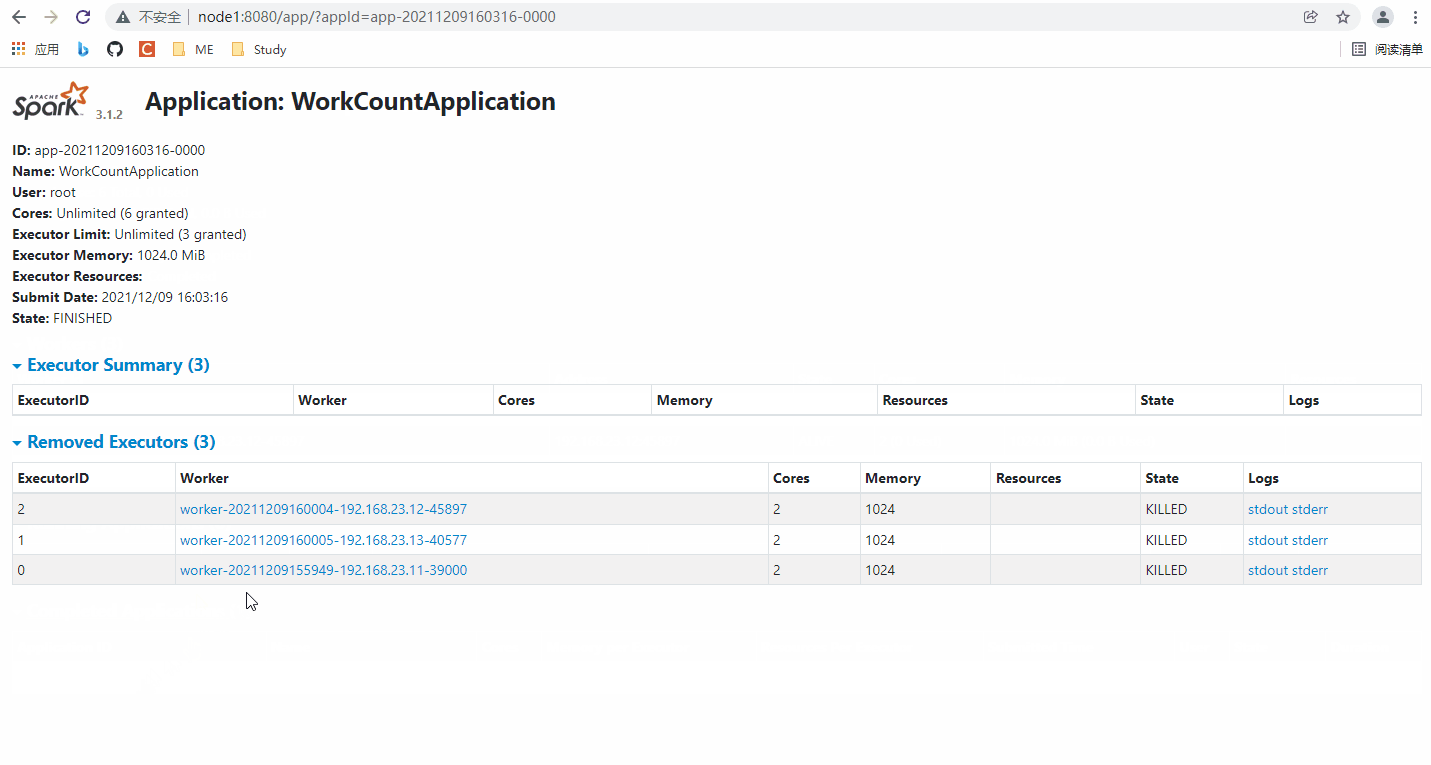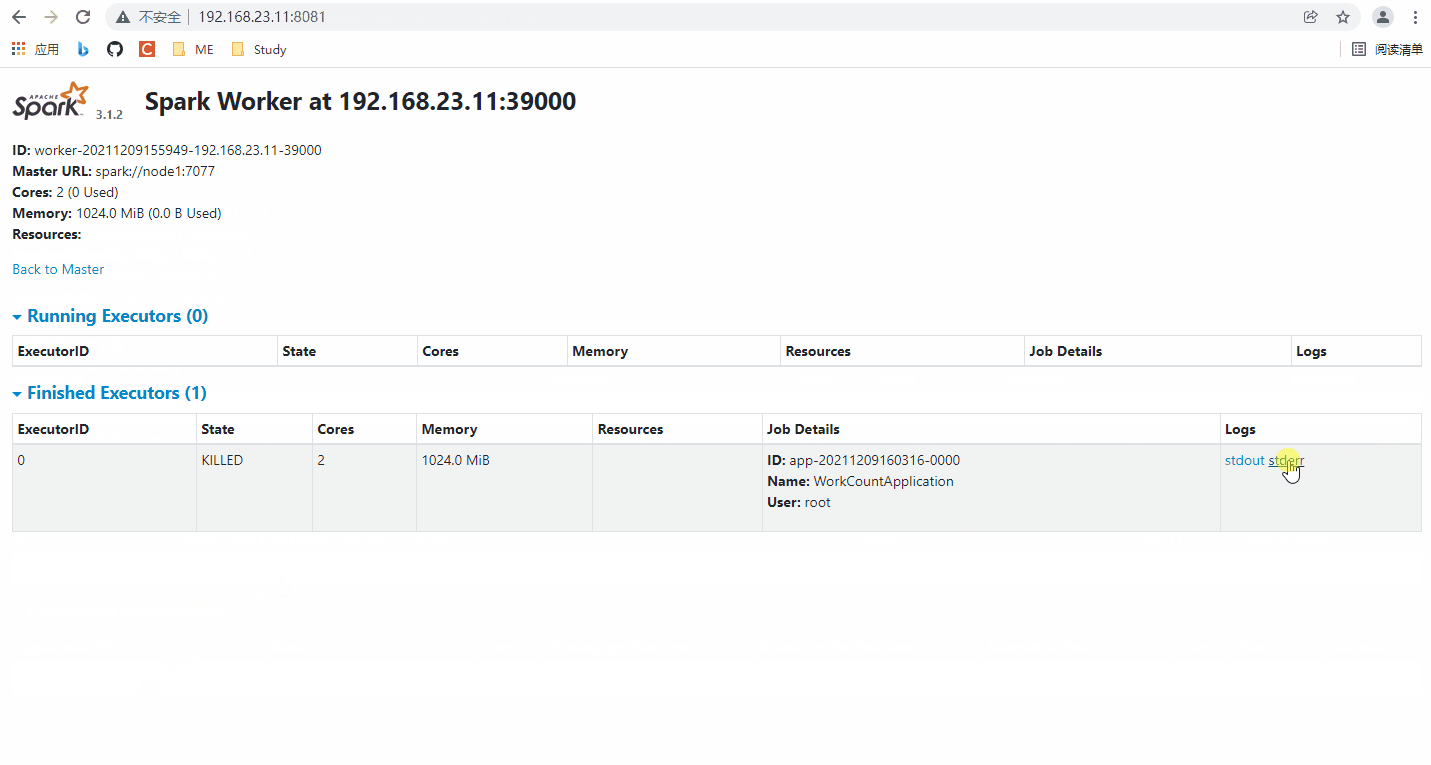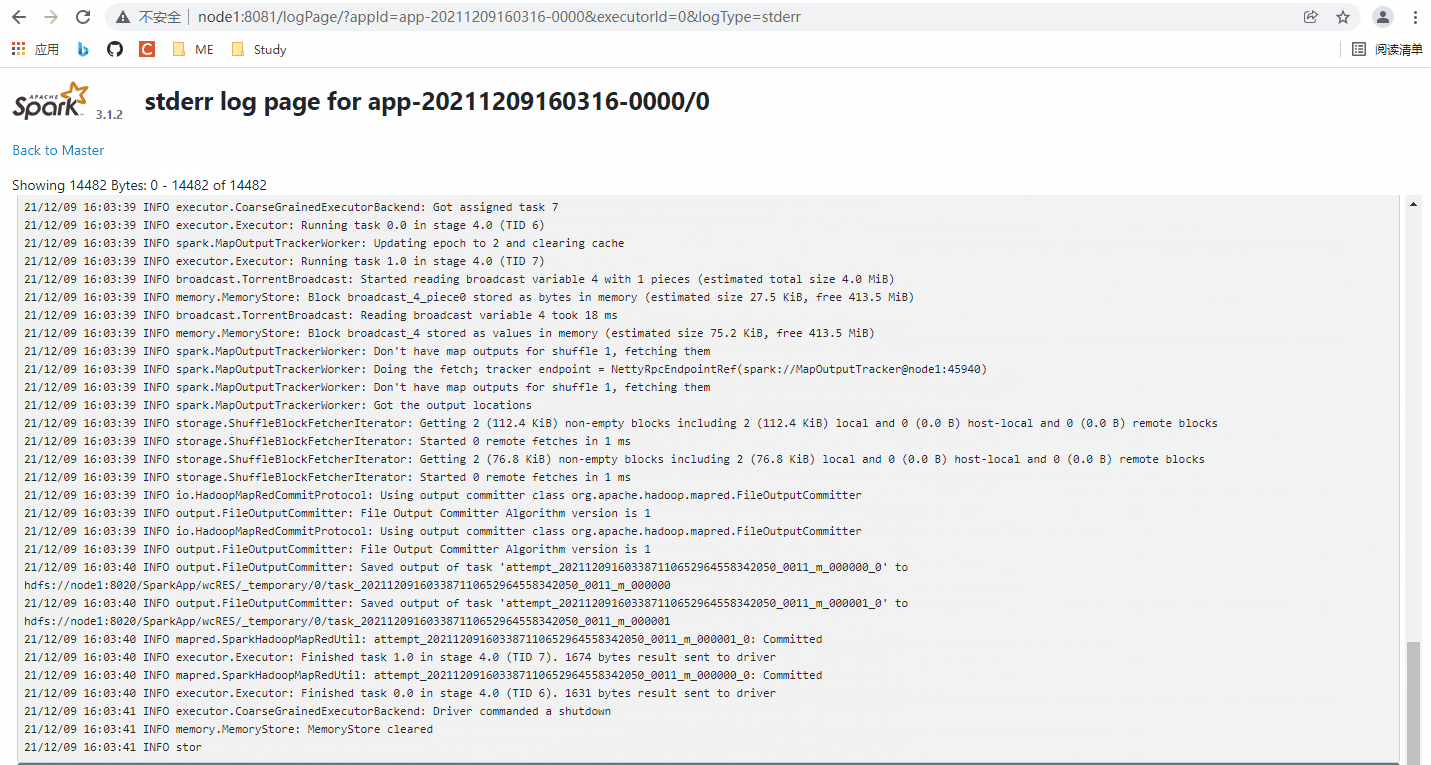
2️⃣ Step2:在HDFS、Spark 的 web 端查看该应用结果

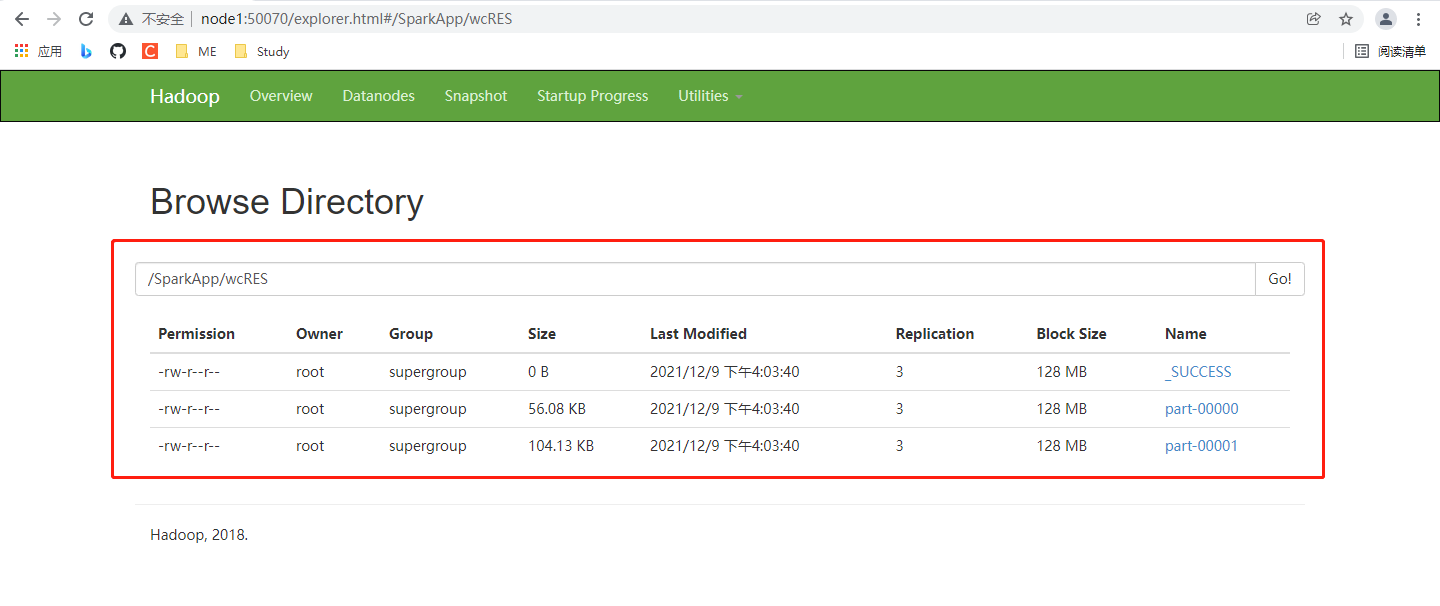
🌈 可以试着点进 Spark 应用浏览一番!
2. 扩展
2.1 查看日志
在完成的 Spark 应用中可以找到每个节点的日志,试着看一看。
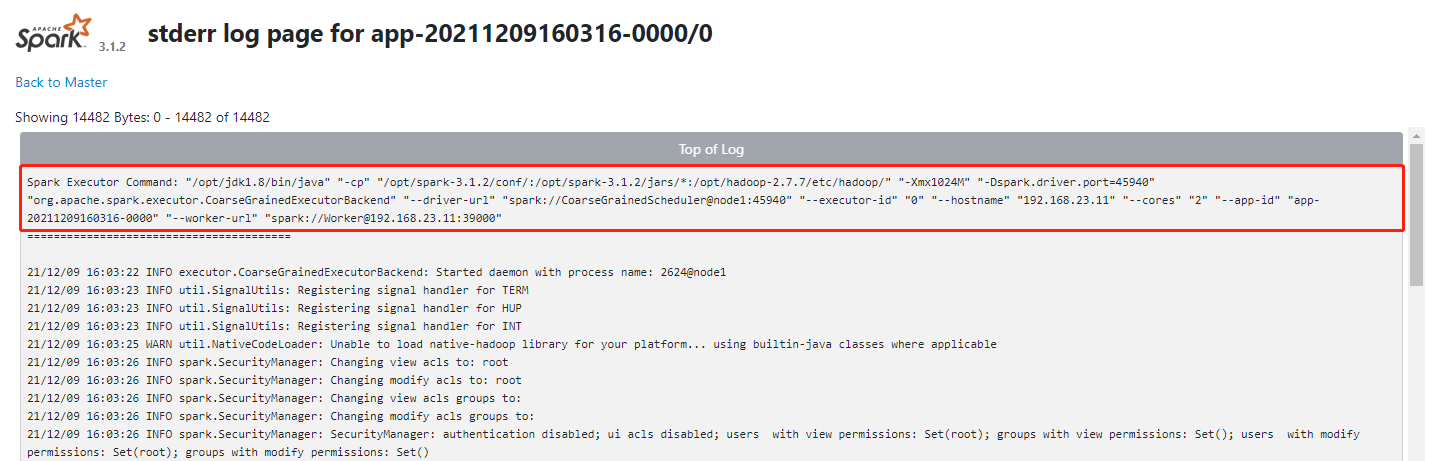
1️⃣、 日志的最上面一行包含一些提交命令的“铭牌”,其中包含路径信息、-Xmx1024M(内存大小)、主机端口、主机编号、主机IP、核心数、应用ID、Worker的Url(主节点也作为一个Worker)。
2️⃣、主机下面两条高亮的部分,可以看到用途词频统计的预料文件被分成了两份,why,我们没有设置分区数!之前本地的设置的运行模式 local[2] 才设置过两个分区,所以着应该是 Spark 默认给我们设置了。
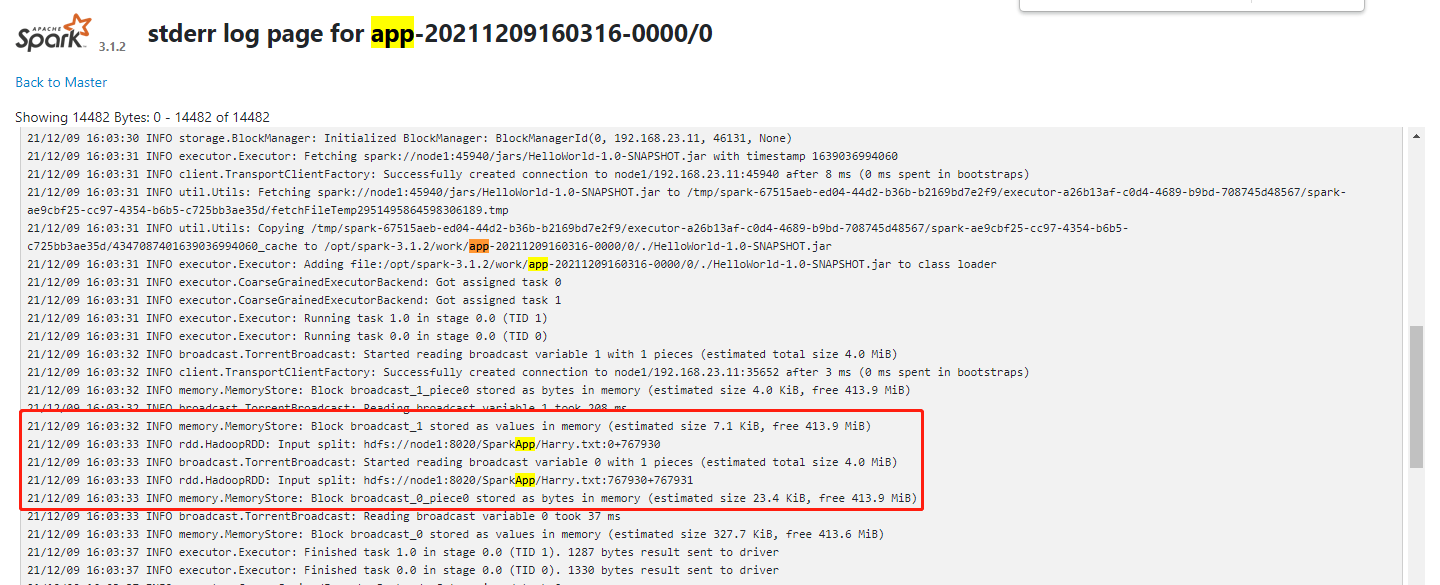
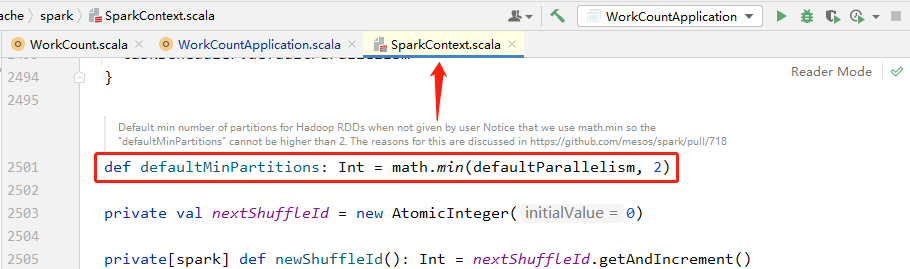
通过查看源码其实可以发现,在 SparkContext.scala 源码中,可以找到有一个默认的最小分区数,默认为 2!
2.2 提交命令
提交命令的参数可以根据实际情况修改。
--master:指定 Spark 的运行模式,可配置为local[n]、spark://HOST:PORT、mesos://HOST:PORT、yarn-client、yarn-cluster--executor-memory nG:指定每个 executor 可使用的内存为 nG--total-executor-cores n指定所有 executor 使用的 cpu 核数为 n 个--executor-coers:指定每个 executor 使用的 cpu 核数















 1254
1254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











