









目录
一、创建网络模型
在学习网络模型的创建前,简单回顾下模型创建大致是一个什么过程。在前几节中,总结了机器模型学习的五大模块,分别是下图所示的数据,模型,损失函数,优化器,迭代训练:

正如前两节学习的数据模块一样,这节要说到的网络模型的创建只是模型模块的一个分支,具体的关系如下图所示:
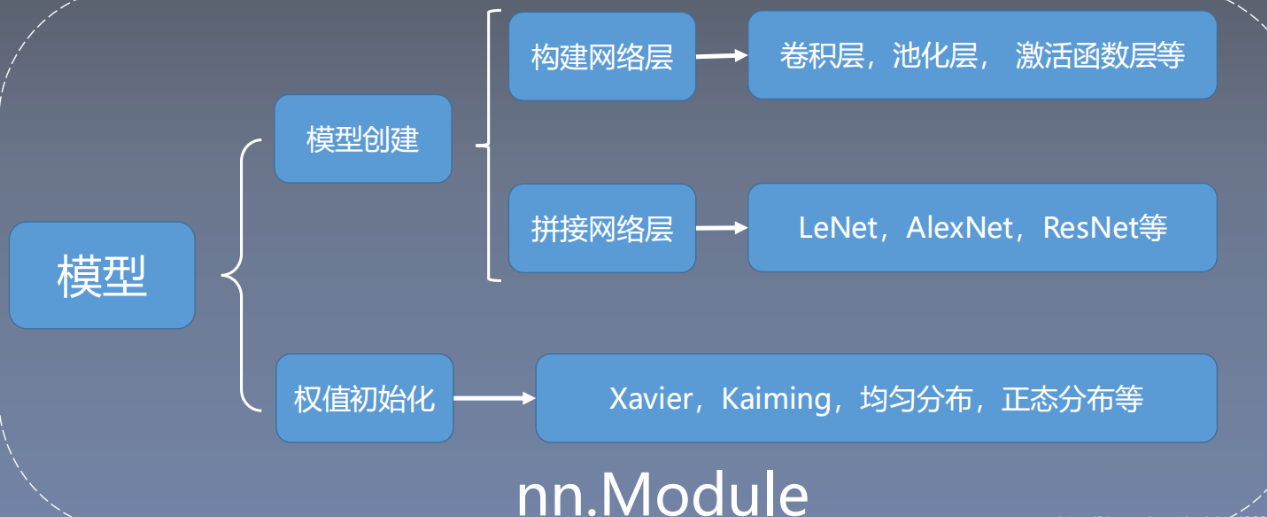
创建模型的步骤
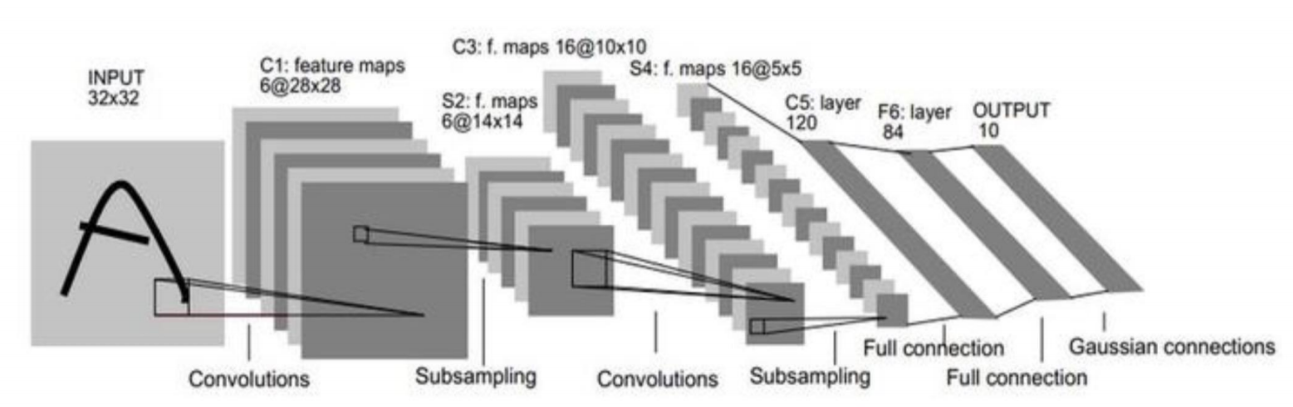
LeNet网络模型的大致结构可以如下图所示:
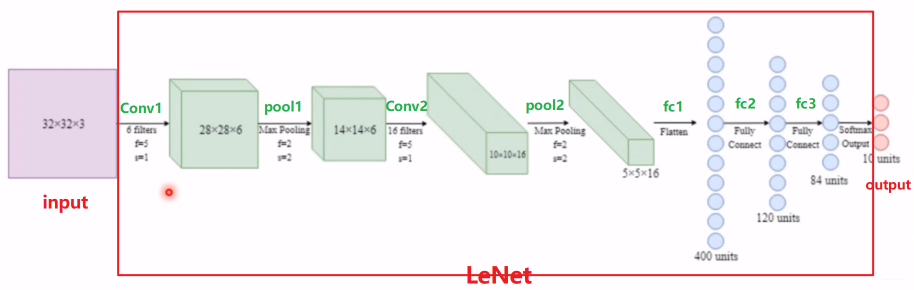
上面是LeNet的模型计算图,LeNet的内部通过一系列卷积层、池化层、全连接层的组合实现期望的运算。
构建模型要素:
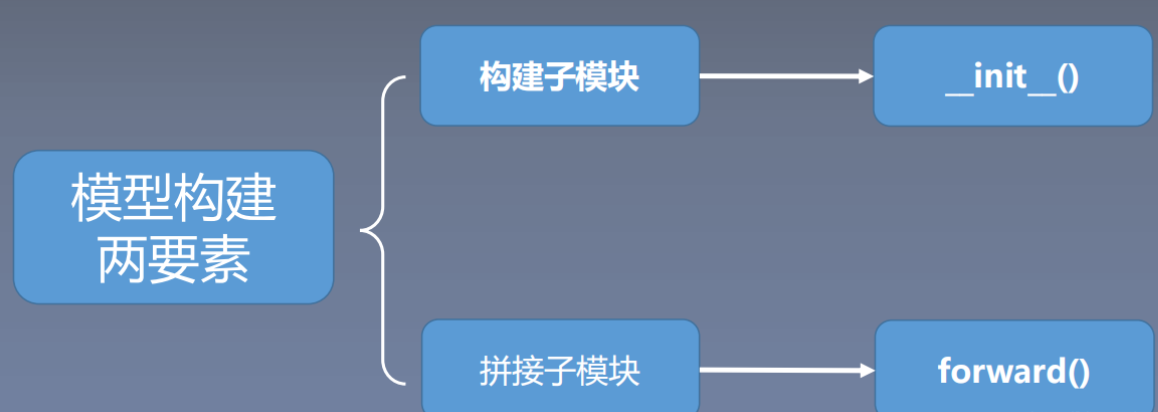
由上图可以概括出模型构建的两个要素:
- 构建子模块:构建子模块(比如LeNet里面的卷积层,池化层,全连接层)
- 拼接子模块:拼接子模块(有了子模块,需要把子模块按照一定的顺序,逻辑进行拼接起来得到最终的LeNet模型,比如子模块间的输出和输入维度要对齐等)
为了方便仍以上一节中的人民币二分类任务为例,依然是利用断点调试功能,了解一下LeNet构建的过程。
首先在如下图所示的地方打上断点,然后运行Debug,在断点处停下后,
执行step into(F7)进入lenet.py以查看执行情况,

首先看到的是定义的LeNet类通过 __super __方法继承了父类nn.Module的初始化函数 __ init __,并且可以发现在它的 __ init __方法里面定义了两个卷积层和三个全连接层,这便实现了各个子模块的构建。所以构建模型的第一个要素(子模块的构建)就是在 __ init __中完成的。
第一个要素完成后,还有第二个要素(子模块的拼接)需要解决,由于子模块的拼接涉及具体的计算(计算过程在我们定义类中的forward()方法中完成),为此我们需要把目光聚焦于训练过程中,如下图所示,打上断点后Debug:
在断点处停下后,执行step into(F7)便能够进入module.py.py中__call__函数,这并不奇怪,在上一节的调试中也是如此,因为定义的LeNet类是继承了Module类的。此后再执行几次step into(F7)便能够进入LeNet的forward方法。
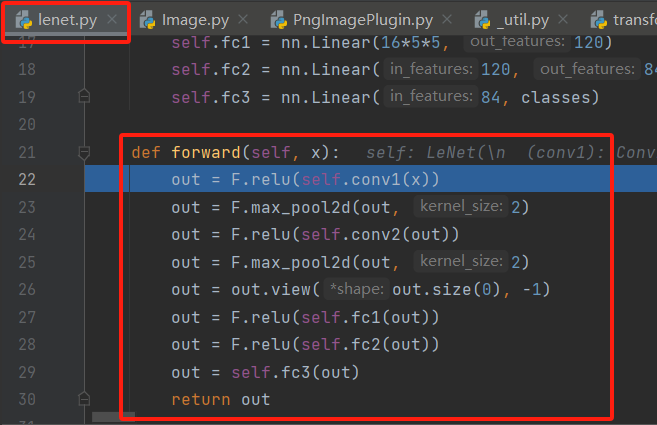
如上图中的forward()方法,完成了每个子模块间的连接(通过ReLu激活函数以及最大池化层等方式)。
至此,基于LeNet这个例子,就大致了解了上面构建模型的两个要素:
- 构建子模块, 是在自定义的模型(继承nn.Module)的
__ init__方法中完成 - 拼接子模块, 在自定义模型的
forward()方法中完成
前文中提到所有自定义网络层都是继承自nn.Module的,为此灰常有必要了解一下这个类。
二、nn.Module的属性
首先看看Pytorch中神经网络模块有哪些组成部分:

可以发现Pytorch的神经网络模块torch.nn包括了若干个子模块,而Module就是它的子模块之一,这些子模块负责不同的内容以完成神经网络的搭建。
nn.Module有8个重要的属性, 用于管理整个模型,他们都是以有序字典的形式存在着:

• _parameters: 存储管理属于nn.Parameter类的属性,例如权值,偏置这些参数
• _modules: 存储管理nn.Module类, 比如LeNet中,会构建子模块,卷积层,池化层,就会存储在_modules中
• _buffers:存储管理缓冲属性, 如BN层中的running_mean, std等都会存在这里面
• ***_hook:存储管理钩子函数(5个与hooks有关的字典,这个先不用管)
2.1 nn.Parameter
首先是nn.Parameter, 在Pytorch中,优化器训练的是模型的可学习参数,训练过程需要计算梯度,因此是参数为 requires_grad = True 的张量Tensor。此外,一个模型往往不止一个参数,Pytorch一般将参数用nn.Parameter来表示,并且用nn.Module(中的 _parameters属性)来管理其结构下的所有参数。测试代码如下:
import torch
from torch import nn
## nn.Parameter ,默认具有 requires_grad = True 属性
w = nn.Parameter(torch.randn(2, 2))# 初始化参数
print(w)
print(w.requires_grad) # True
## nn.ParameterList 可以将多个nn.Parameter组成一个列表
params_list = nn.ParameterList([nn.Parameter(torch.rand(8, i)) for i in range(1, 3)])# 列表推导式
print(params_list)
print(params_list[0].requires_grad)# 打印paras_list中第一个参数的requires_grad属性
## nn.ParameterDict 可以将多个nn.Parameter组成一个字典
params_dict = nn.ParameterDict({"a": nn.Parameter(torch.rand(2, 2)),
"b": nn.Parameter(torch.zeros(2))})
print(params_dict)
print(params_dict["a"].requires_grad)# 打印paras_dict中"a"的requires_grad属性
可以使用nn.Module的parameters属性把这些参数管理起来,测试代码接续nn.Parameter的测试代码:
# 创建module
module = nn.Module()
# 赋值
module.w = w
module.params_list = params_list
module.params_dict = params_dict
num_param = 0 # 计数器
for param in module.parameters():
print(param,"\n")
num_param = num_param + 1
print("number of Parameters =",num_param)
一般通过继承nn.Module来构建模块类,并将所有含有需要学习的参数的部分放在构造函数中。
# 以下范例为Pytorch中nn.Linear的源码的简化版本
# 可学习的参数放在了__init__构造函数中,并在forward中调用F.linear(F是nn.functional的别名)函数来实现计算逻辑。
from torch import functional as F
class Linear(nn.Module):
__constants__ = ['in_features', 'out_features']
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
# 通过Paraneter管理可学习参数
self.weight = nn.Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = nn.Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
def forward(self, input):
return F.linear(input, self.weight, self.bias)
2.2 nn.functional
nn.functional(一般引入后改名为F)有各种功能组件的函数实现。 比如:
- 激活函数系列(F.relu, F.sigmoid, F.tanh, F.softmax)
- 模型层系列(F.linear, F.conv2d, F.max_pool2d, F.dropout2d, F.embedding)
- 损失函数系列(F.binary_cross_entropy, F.mse_loss, F.cross_entropy)
一般我们都是直接使用nn.**函数来调用nn.functional的各种功能函数,实际上是通过继承nn.Module转换为类的实现形式, 并直接封装在nn模块下:
- 激活函数变成(nn.ReLu, nn.Sigmoid, nn.Tanh, nn.Softmax)
- 模型层(nn.Linear, nn.Conv2d, nn.MaxPool2d, nn.Embedding)
- 损失函数(nn.BCELoss, nn.MSELoss, nn.CrossEntorpyLoss)
有了如上两个模块之后,便可以重点学习nn.Module了
2.3 nn.Module
在nn.Module中,有8个重要的属性, 用于管理整个模型,他们都是以有序字典的形式存在着:

其中主要参数的功能如下表示:
| 属性 | 作用 |
|---|---|
| _parameters | 存储管理属于nn.Parameter类的属性,例如权值,偏置这些参数 |
| _modules | 存储管理nn.Module类, 比如LeNet中,会构建子模块,卷积层,池化层,就会存储在_modules中 |
| _buffers | 存储管理缓冲属性, 如BN层(标准归一化)中的running_mean, std等都会存在这里面 |
| _hooks | 存储管理钩子函数 |
下面是nn.Module的一个实现机制的大致了解(友情提醒,由于不是特别熟悉,读者可以参考原博客的作者哦~)。仍以人民币二分类模型为例,以断点调试作为工具:
首先在模型初始化处打上断点,如下图所示:
然后Debug在断点停下后,执行step into(F7)进入lenet.py,
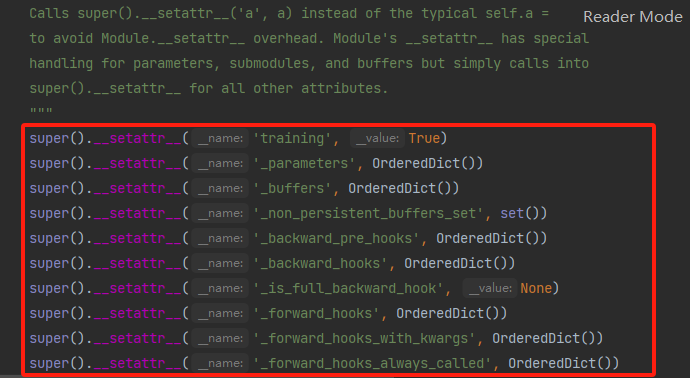
LeNet是继承于nn.Module的,,并在__ init__方法中__ super__方法中实现了对父类nn.Module初始化函数的调用。执行step into(F7)进入父类的__ init__方法,在__ init__中通过下图方式对8个属性完成了赋值。
 再次执行几次
再次执行几次step into(F7)便能够回到自定义LeNet的第二行代码,建立第一个子模块卷积层,在第二行代码处执行step into(F7)便能够查看卷积层的具体实现:
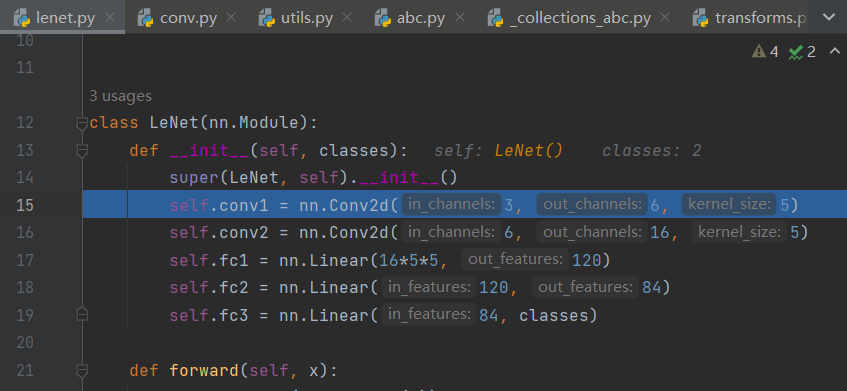
进入到nn.Conv2d后,会发现Conv2d是继承于_ConvNd的,
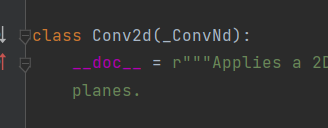
在Conv2d的初始化方法中,依然是先调用父类的初始化方法, 执行step over(F8)到下图所示处后step into(F7)进入父类_ConvNd的初始化函数

如下图所示,可以发现ConvNd也是继承自Module这个类的,并且初始化方法中也是用了super调用了父类的初始化方法。 于是Conv2d这个子模块也是一个Module,并且也有那8个有序字典的属性。
然后再跳Lenet的第三行代码,在此之前先查看一下变量区的情况。
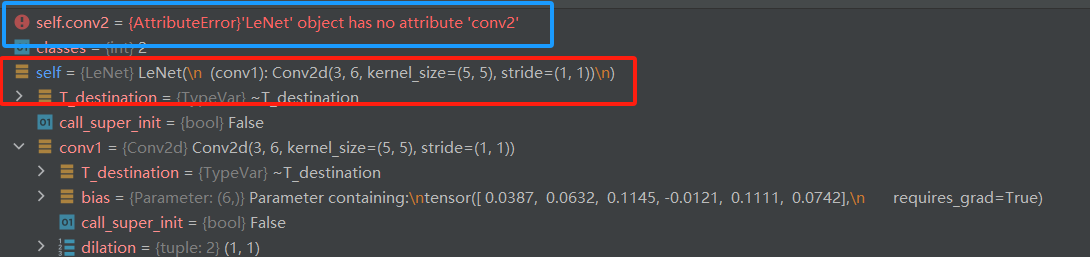
由于第三行代码还没有开始运行,于是conv2还没有被初始化。 但是由于第二行代码已经执行完成,,于是LeNet中已经保存了conv1的信息。因为Conv2d也是一个Module,所以它也有8个有序字典。可以发现conv1(是一个Conv2d类)下的_modules是空的了,这是因为它没有子模块。但是可以发现它的_parameters这个字典里面不是空的,因为它已经在LeNet第二行代码执行后完成了初始化,所以是有参数的。parameters这个字典会记录权重和偏置的参数信息,因此是非空的。
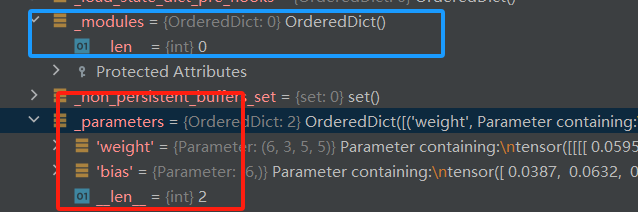
通过上面的调试,便大概了解了LeNet是如何使用这个Module实现了一个子网络层的构建,并且把它存储到了_modules这个字典中进行管理的。但目前只是知道了LeNet是将这个子模块Conv2d存储到这个_modules字典里面,但是不清楚是存进去的具体方式,为了一探究竟那就继续在LeNet的第三行代码处执行step in(F7)吧。
这次step in(shift + F8)进来后不执行任何调试操作,直接step out(F9)跳回LeNet的第三行代码。
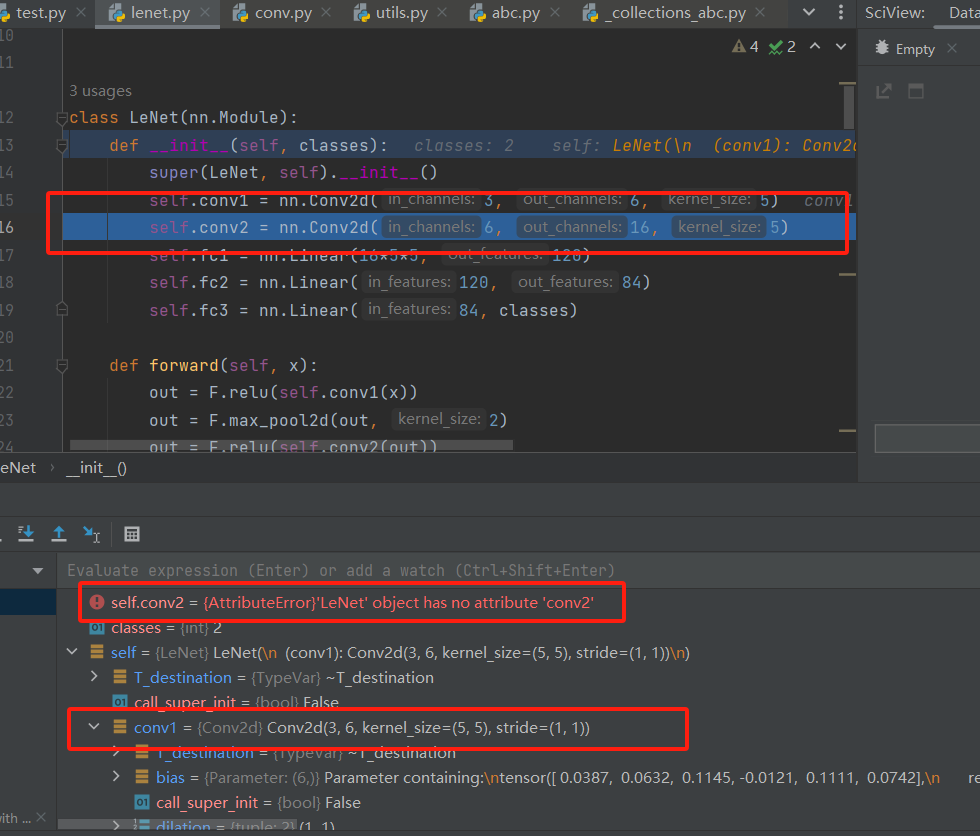
如上图所示,这时候我们会发现LeNet这个Module的_modules字典中依然只有conv1,没有出现conv2, 这是因为目前只是通过初始化函数实现了一个Conv2d的一个实例化,还没有赋值到我们的conv2中,只是构建了这么一个网络层,下一步才是赋值到conv2这个上面,所以一个子模块的初始化和赋值是两步走的,第一步初始化完了之后,会被一个函数进行拦截,然后再进行第二步赋值, 那么这个函数是啥呢? 它又想干啥呢? 我们可以再次stepinto一下,进入这个函数,这次就直接到了这个函数里面(注意我们上面的第一次stepinto是跳到了__init__里面去初始化)
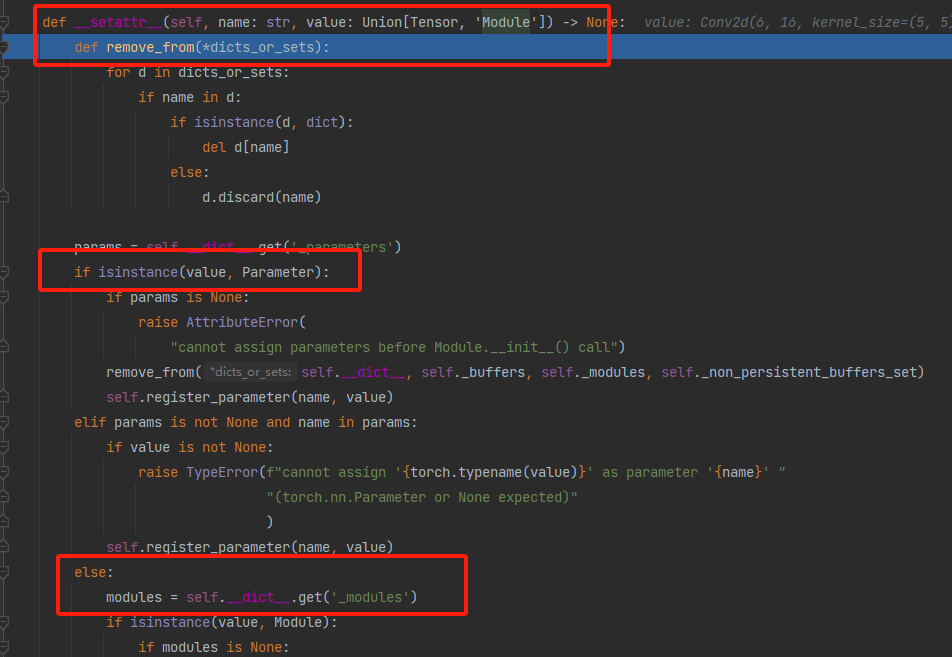
如上图所示,这次到了 setattr__,这便是用于赋值的函数。该方法接以value为参数, 首先会判断value的数据类型:如果是模型的参数,就会将该模型参数保存到Conv2d的有序字典_parameters中;如果是Module类型,就会保存到LeNet的有序字典_modules中。 而conv2d是一个Module,于是存入到_modules字典中, name就是conv2。所以再次执行step out(shift + F8)跳回LeNet第三行代码后就会发现_modules字典中有了conv2了。
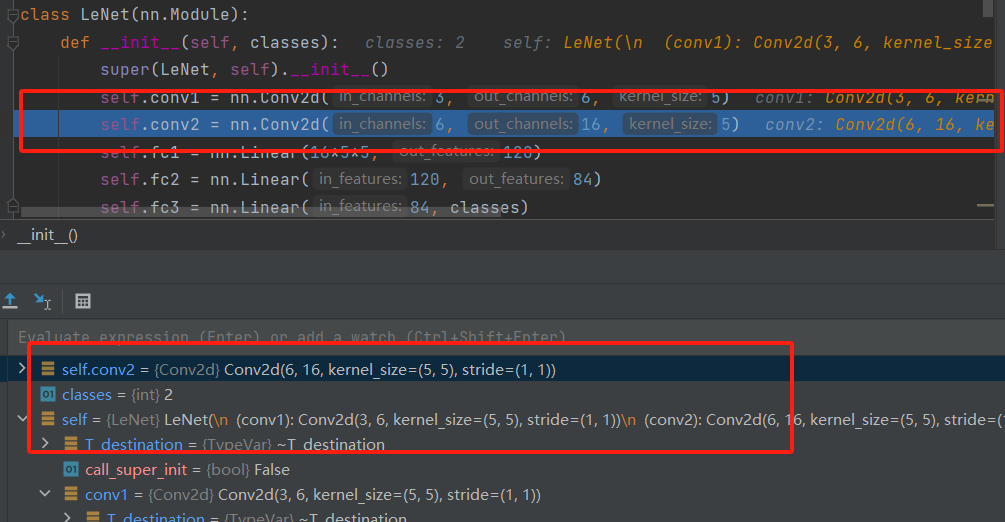
一直这样运行下去直至整个网络的完成便是nn.Module构建属性的一个机制。整个流程简要叙述一下呢就是:首先有一个大的Module(比如说自定义的LeNet)继承nn.Module这个父类,然后这个自定义的Module内部可以同时定义很多的小Module,这些小Module也是继承于nn.Module的, 在这些小Module的__init__方法中,会先通过调用父类nn.Module的初始化方法进行8个属性的一个初始化。 然后在构建每个小模块的时候其实分为两步,第一步是小Module
的初始化,初始化完成后用__ setattr__这个方法通过判断value的类型将其保存到相应的属性字典里面去,然后再进行赋值给相应的成员(如果是模型参数就保存到用于储存模型参数的有序字典_ paramaters中;如果是Module类型的话就保存到储存module的有序字典_ modules中去)。 这样一个个的构建小Module,直到把整个大Module构建完毕。
下面是对nn.Module进行简单地总结:
- 一个大module(自定义Module,比如demo中的LeNet)可以包含多个小module(LeNet包含卷积层,池化层,全连接层,每个层都是一个小module)
- 一个module相当于一个运算(比如激活函数,池化,标准归一化等), 必须实现forward()函数(从计算图的角度去理解)
- 每个module都有8个字典管理它的属性(最常用的就是_parameters,_modules(前者储存用于模型训练的参数,后者用于输出子module))
一般情况下很少直接使用 nn.Parameter来定义参数构建模型,而是通过拼装一些常用的模型层来构造模型。这些模型层也是继承自nn.Module的对象,本身也包括参数,属于要定义的模块的子模块。
nn.Module提供了一些方法可以管理这些子模块,详情可以参见官方文档。
三、 模型容器Containers
在搭建模型中,模型容器Containers也是一个灰常重要的概念,整体框架如下:
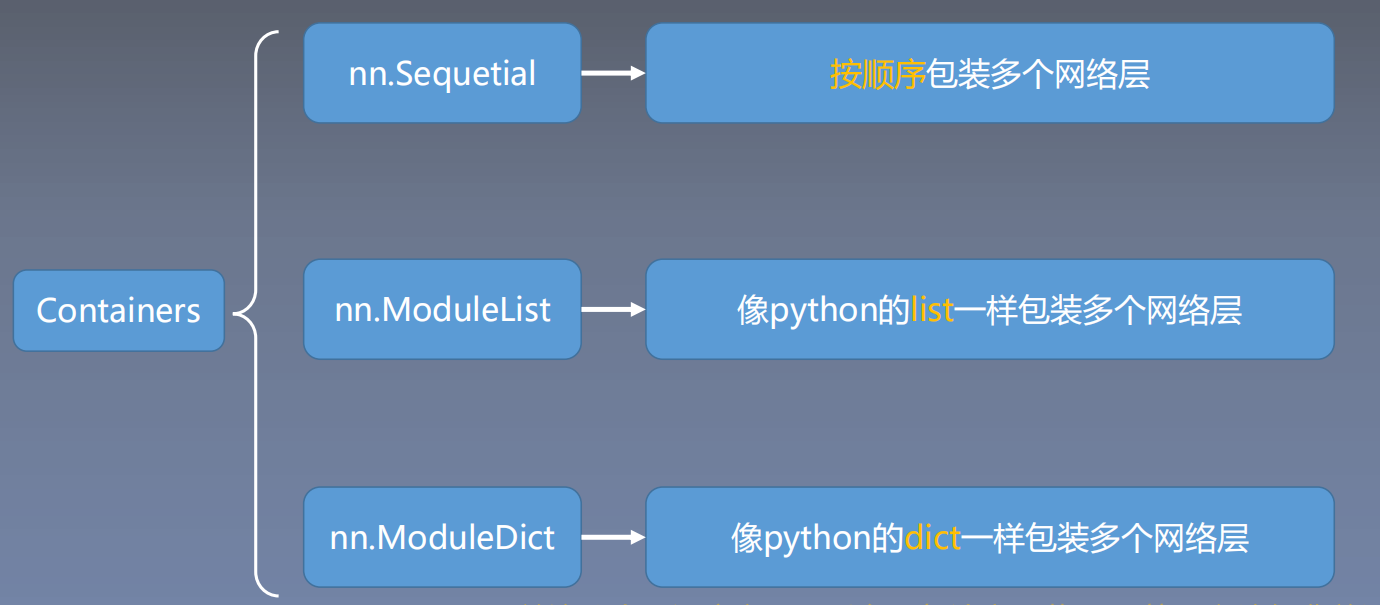
3.1 nn.Sequential
这是nn.module的容器,用于按顺序 包装一组网络层,下图是Sequential一个实例:
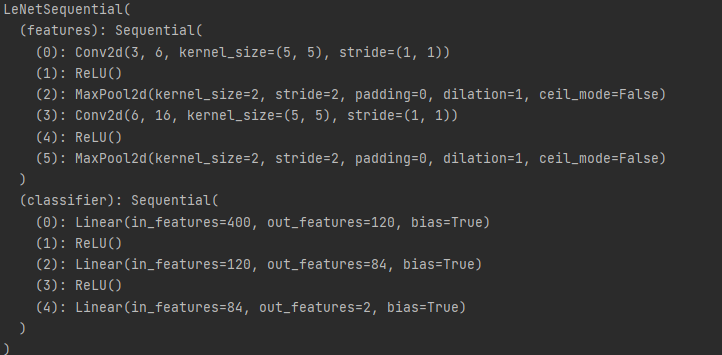
下面以LeNet模型为例,前面的那部分划分为特征提取部分,后面的全连接层为模型部分。测试代码如下:
import torch
from torch import nn
from torch import functional as F
class LeNetSequential(nn.Module):
# 特征提取部分
def __init__(self, classes):
super(LeNetSequential, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), )
# 模型分类部分
self.classifier = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes), )
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
如上的代码所示,LeNet被分成了两大部分,第一部分用于特征提取, 第二部分用于分类。 利用Sequential将各网络进行了简单地堆叠,forward只需要对特征提出部分做flatten拉伸变换,然后丢进classifer部分就完成。
(1)输入数据类型非字典
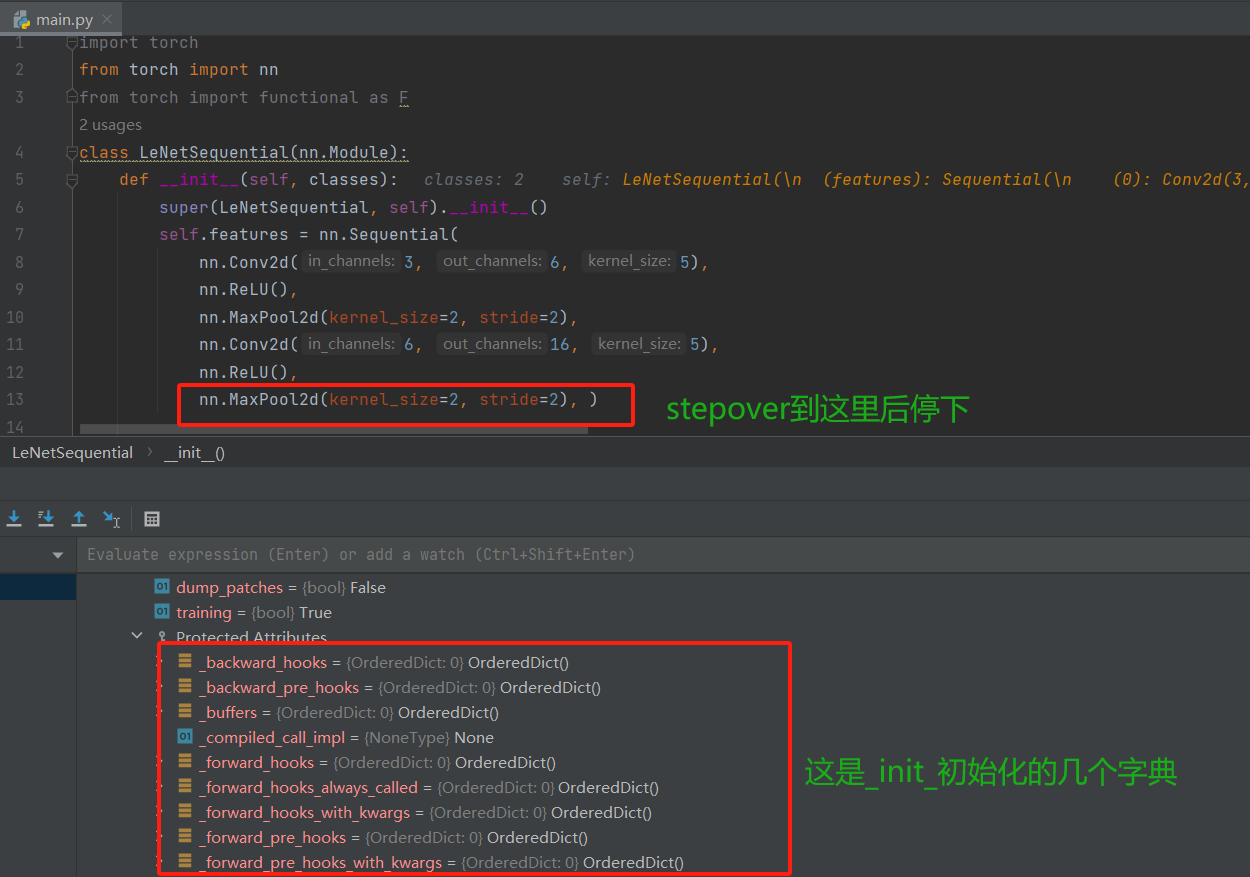
下面仍然以代码调试为工具,看看Sequential的运行机制(每个子module没有对应的“键”)。在如下的代码行处打断点,Debug在断点停下后执行step into(F7) 步入即可,这样就能够进入LeNetSequential类里。

因为这个类继承的也是nn.Module,所以初始化和上文提到的一样就直接略过不再赘述了。执行step over(F7) 一步步的往下,到一个Sequential完成的位置停下来(这个类中是在feature特征提取那停下)
然后,step into->step out->step into 进入container.py的Sequential这个类。会发现class Sequential(Module), 即Sequential也是继承与nn.Module这个类的。
之后便可一直step over(这里我是直接完成了第一个Sequential的构建后才演示的,所以图上有1,2,3,4,5),把第一个Sequential构建完毕。构建完第一个Sequential后如下图所示。
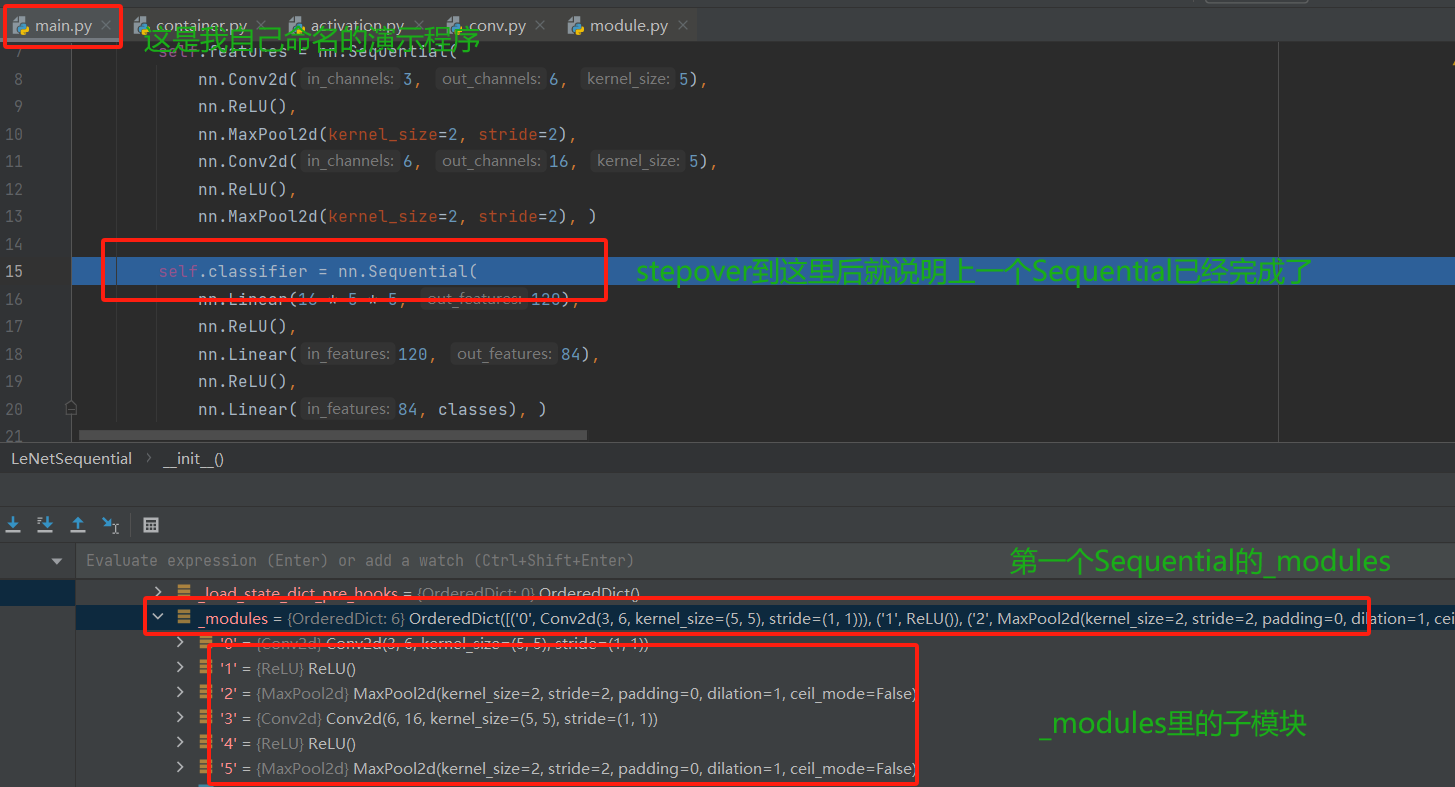
下面的那个Sequential构建其实原理和第一个的一样了,所以不再进行调试查看,简单梳理一下Sequential的构建机制, 这个依然是继承Module类,所以也是在__init__方法中先调用父类去初始化8个有序字典,然后再__init__里面完成各个子模块的参数存储。 这样,子模块构建完成,还记得我们模型搭建的第一步吗?
接下来,就是拼接子模块, 这个是通过前向传播函数完成的,所以下面我们看看Sequential是怎么进行拼接子模块的,依然是调试查看(这部分调试居多,因为这些内部机制,光靠文字写是没法写的,与其写一大推迷迷糊糊,还不如截个图来的痛快), 我们看前向传播:
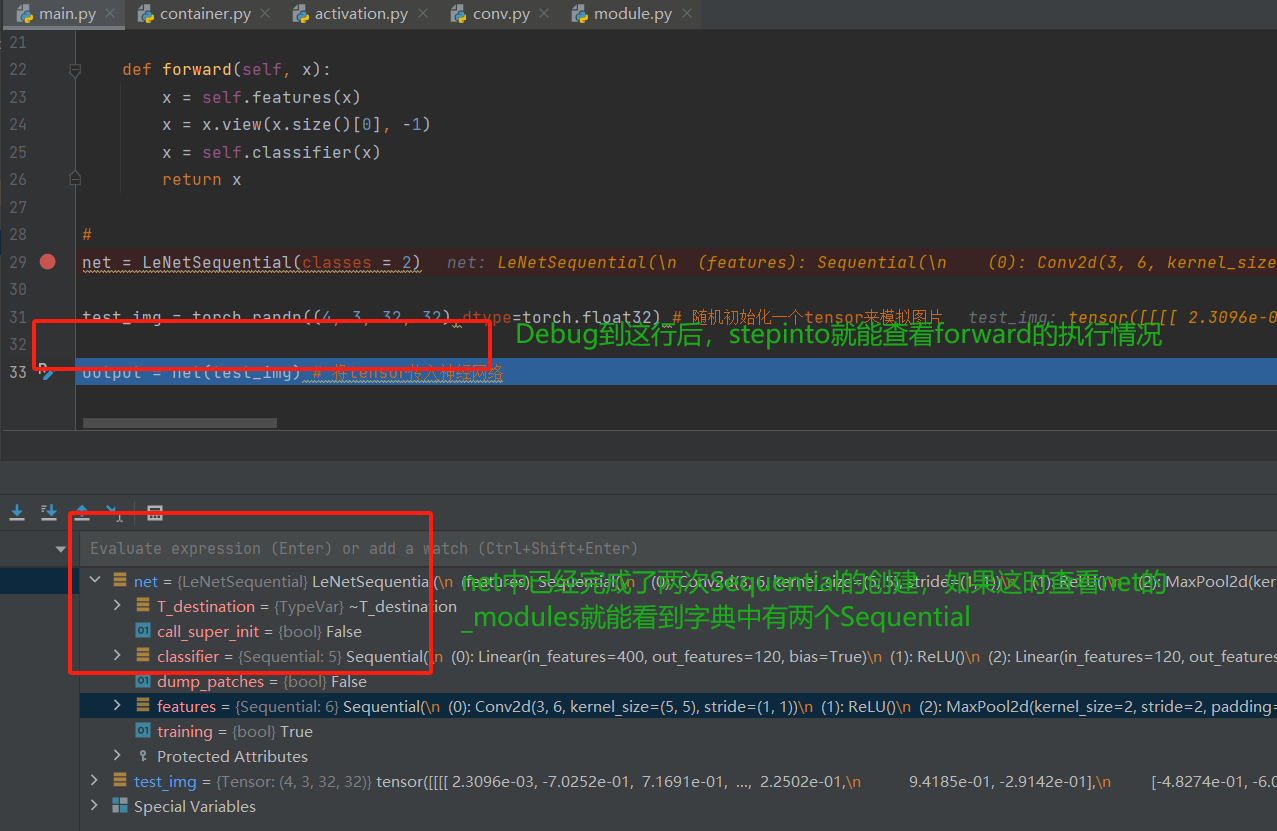
在上述的代码行output = net(test_img)处重复执行step into,直到进入到container.py中, 就是在这里面调用前向传播的。
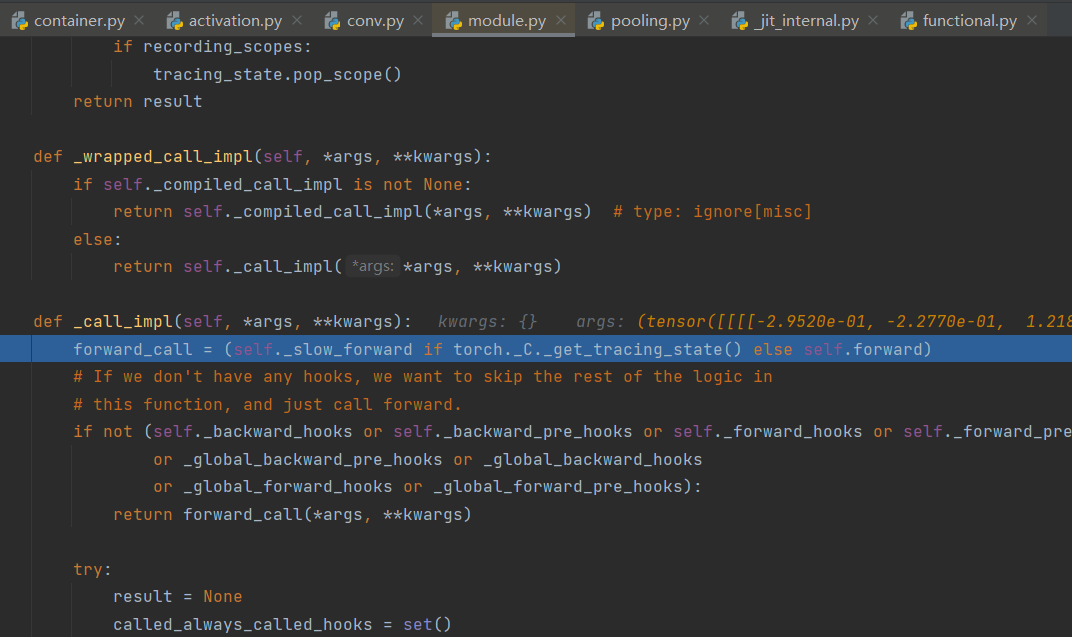
重复执行step into后会跳回到如下代码行处,而这是这一行代码便完成了特征提取这部分内容,要Sequential是怎样了实现的特征提取的话只需要执行step into后进入查看。

由于self.features是一个Sequential, 而Sequential也是继承于Module,所以执行几次step into后,我们还是stepout到前向传播的那一行,然后便能看到已经步入了Sequential的前向传播。
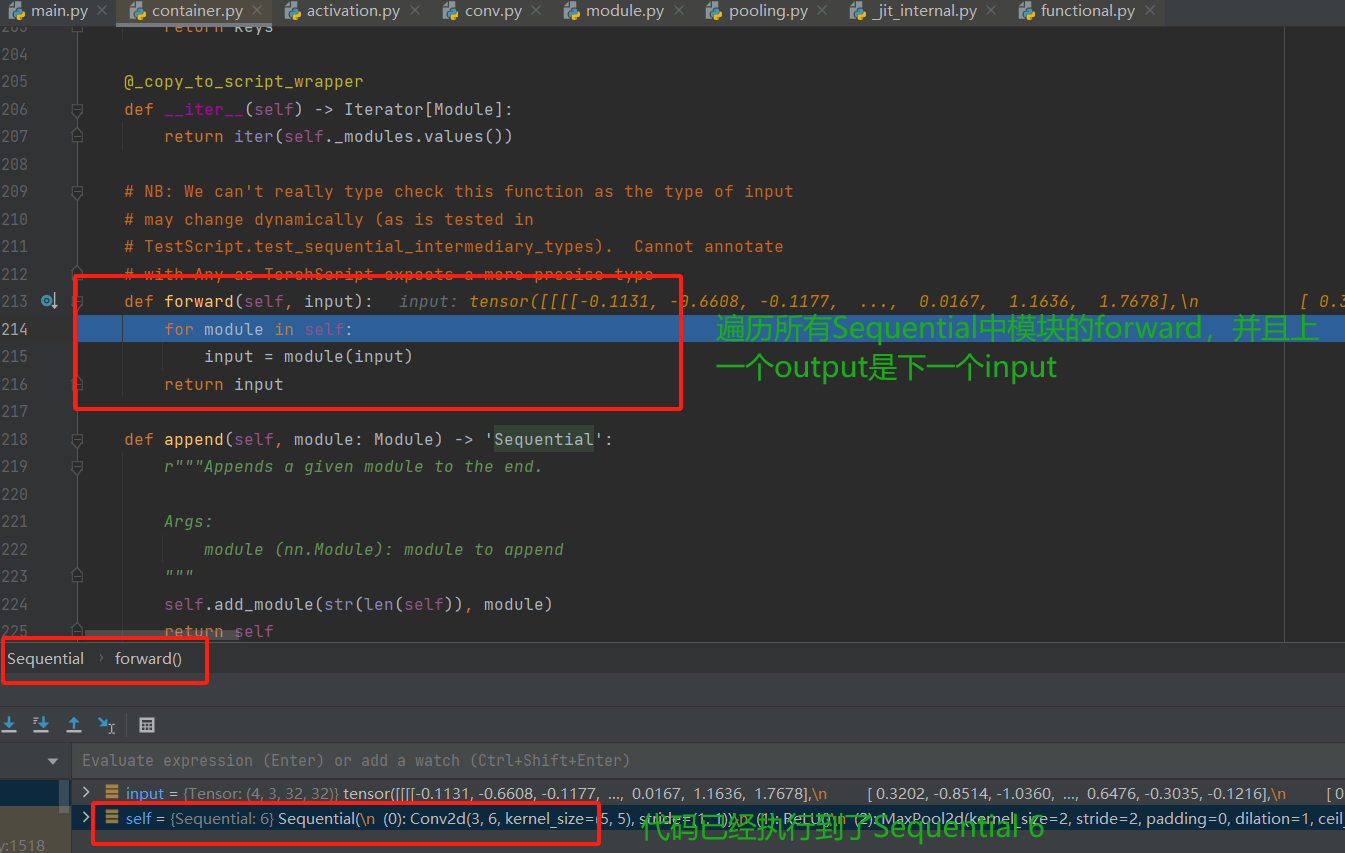
从上面可以看出,在Sequential的前向传播里面,会根据之前定义时候的那个_module那个有序的参数字典(储存了每个层的子Module信息), 前向传播的时候遍历这个字典, 得到每个子模块进行处理。这就是Sequential的前向传播运行的步骤了,下面的self.classifier的前向传播也是如此,于是不再赘述。
最后呢,模型的拼接这块也简单梳理一下,在Sequential定义的时候,会把每一层的子模块的信息存入到它的_modules这个有序字典中,然后前向传播的时候会遍历这个字典,把每一层拿出来然后处理数据,并且要注意上一层的输出正好是下一层的输入。通过上述迭代就可以完成前向传播过程。
执行完成全部代码后自定义LeNet信息如下所示:
(2)输入数据类型为字典
在前文的Debug中其实我们已经发现网络层是有名字的,比如1,2,这样便可以通过序号去索引网络层。如果网络层成千上百的话,很难通过序号去索引网络层,这时候变突发奇想:能不能自己给每一个网络层命名然后通过名字来索引对应的网络层呢?答案当然是肯定的,这边是下面要提到的构建Sequential第二种方法。
首先先给出测试代码:
import torch
from torch import nn
from torch import functional as F
from collections import OrderedDict
class LeNetSequentialOrderDict(nn.Module):
def __init__(self, classes):
super(LeNetSequentialOrderDict, self).__init__()
self.features = nn.Sequential(OrderedDict({
'conv1': nn.Conv2d(3, 6, 5),
'relu1': nn.ReLU(inplace=True),
'pool1': nn.MaxPool2d(kernel_size=2, stride=2),
'conv2': nn.Conv2d(6, 16, 5),
'relu2': nn.ReLU(inplace=True),
'pool2': nn.MaxPool2d(kernel_size=2, stride=2),
}))
self.classifier = nn.Sequential(OrderedDict({
'fc1': nn.Linear(16 * 5 * 5, 120),
'relu3': nn.ReLU(),
'fc2': nn.Linear(120, 84),
'relu4': nn.ReLU(inplace=True),
'fc3': nn.Linear(84, classes),
}))
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
#
net = LeNetSequentialOrderDict(classes = 2)
test_img = torch.randn((4, 3, 32, 32),dtype=torch.float32) # 随机初始化一个tensor来模拟图片
output = net(test_img) # 将tensor传入神经网络
print(net)
print(output)
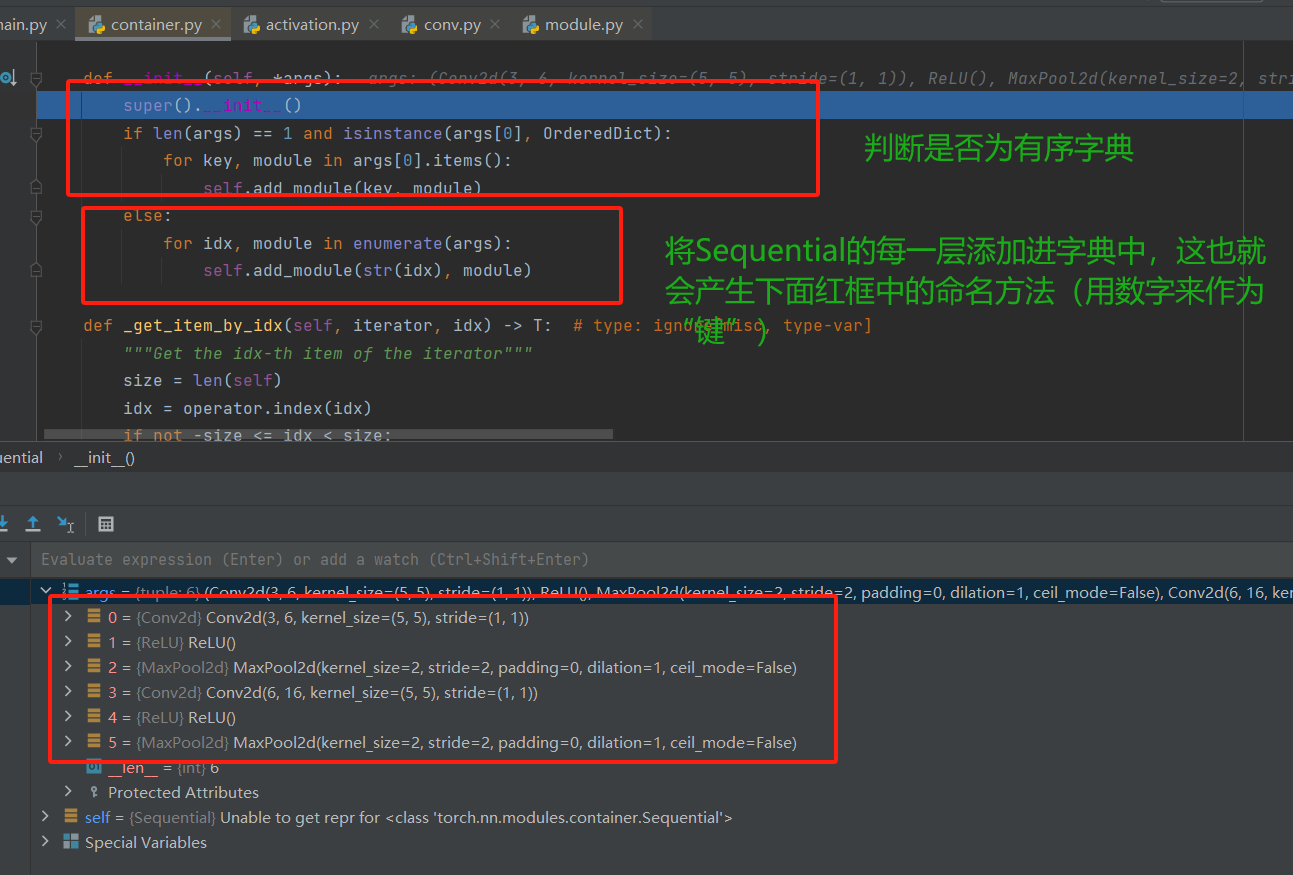
上述代码中Sequential包装的就是一个有序的字典(利用Orderdict来完成), 字典中是网络名:网络层的形式。通过这个有序的字典可以对每一层网络进行命名, 那它是什么时候进行初始化的呢? 当然还是在定义(也就是初始化类)的时候,上面Debug中的某张图片里面已经提到过了,下面在贴上那张图片:
如上图所示,Sequential在完成初始化的时候里面有个判断传入的参数是否为有序字典的判断语句,如果我们利用Sequential直接各个层(也就是输出的网络层类型不是字典类型),于是不满足if的条件,就跳到了下面的else。如果我们对比if和else的代码可以发现,self.add_module()的第一个参数就能告诉我们,如果传入的有序字典类型的网络层,就会以键名(也就是key)来命名,然后把key(网络名):value(网络层)存入到_module有序参数字典;否则就用str类型的数字来命名Sequential每个子模块,然后加入到_module有序参数字典中。
最后是对Sequential进行一个总结:nn.Sequential是nn.module的容器, 用于按顺序包装一组网络层,有如下的两个特点:
顺序性: 各网络层之间严格按照顺序构建,这时候一定要注意前后层数据的关系自带forward(): 在自定义的forward里,通过for循环依次执行前向传播运算
3.2 nn.ModuleList
nn.ModuleList是nn.module的容器,用于包装一组网络层,以迭代方式调用网络层
| 方法 | 作用 |
|---|---|
| append() | 在ModuleList后面添加网络层 |
| extend() | 拼接两个ModuleList |
| insert() | 指定在ModuleList中位置插入网络层 |
举个栗子~,使用ModuleList来循环迭代的实现一个20个全连接层的网络的构建。测试代码如下:
import torch
from torch import nn
from torch import functional as F
import torch
from torch import nn
from torch import functional as F
class ModuleList(nn.Module):
def __init__(self):
super(ModuleList, self).__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)])
def forward(self, x):
for i, linear in enumerate(self.linears):
x = linear(x)
return x
#
net = ModuleList()
test_img = torch.randn((4, 3, 10, 10),dtype=torch.float32) # 随机初始化一个tensor来模拟图片
output = net(test_img) # 将tensor传入神经网络
在上代码块的自定义ModuleList类的__ init__方法中,self.linears是通过列表推导式[nn.Linear(10, 10) for i in range(20)]定义的,这条代码就是迭代20次,每次连接一个全连接层,然后前向传播的时候也是遍历每一层。下面仍然以调试为工具简要看看ModuleList的初始化是怎么进行的。
在如下的断点处step into,
然后step over到如下的代码处后step over直到i=20也执行完毕后,再step into,

如下图所示,modules是一个列表,里面有20个全连接层。 前向传播就是用for循环获取到每个网络层然后计算。
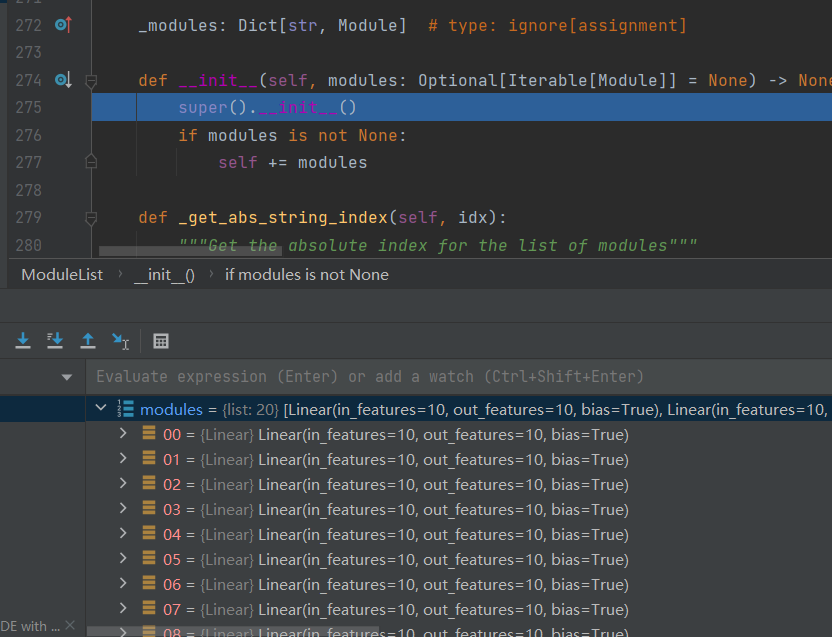
这样就完成了一个20层的全连接层的网络的实现。借助nn.ModuleList只需要一行代码就可以搞定。这就是nn.ModuleList的使用了,最重要的就是可以迭代模型,索引模型。
3.3 nn.ModuleDict
nn.ModuleDict是nn.module的容器, 用于包装一组网络层, 以索引方式调用网络层, 主要方法:
| 方法 | 作用 |
|---|---|
| clear() | 清空ModuleDict |
| items() | 返回可迭代的键值对(key-value pairs) |
| keys() | 返回字典的键(key) |
| values() | 返回字典的值(value) |
| pop() | 返回一对键值对, 并从字典中删除 |
测试代码如下:
import torch
from torch import nn
from torch import functional as F
class ModuleDict(nn.Module):
def __init__(self):
super(ModuleDict, self).__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(10, 10, 3),
'pool': nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict({
'relu': nn.ReLU(),
'prelu': nn.PReLU()
})
def forward(self, x, choice, act):
x = self.choices[choice](x)
x = self.activations[act](x)
return x
net = ModuleDict()
test_img = torch.randn((4, 10, 32, 32)) # 随机初始化一个tensor来模拟图片
output = net(test_img, 'conv', 'relu') # 将tensor传入神经网络,选择层进行组合
print(output) # 打印网络层
上面通过self.choices这个ModuleDict可以选择卷积或者池化,下面通过self.activations这个ModuleDict可以选取是用哪个激活函数
这在选择网络层的时候挺实用,比如要做时间序列预测的时候往往会用到GRU或LSTM, 这样便可以对比哪种网络的效果好。 而具体选择哪一层是前向传播那完成,会看到多了两个参数。
总结

四、AlexNet构建
在LeNet提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气。但卷积神经网络并没有主导这些领域。这是因为虽然LeNet在小数据集上取得了很好的效果,但是在更大、更真实的数据集上训练卷积神经网络的性能和可行性还有待研究。事实上,在上世纪90年代初到2012年之间的大部分时间里,神经网络往往被其他机器学习方法超越,如支持向量机(support vector machines)。
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。 AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
AlexNet的特点如下:
- 采用ReLu: 替换饱和激活函数, 减轻梯度消失
- 采用LRN(Local Response Normalization): 对数据归一化,减轻梯度消失(后面被Batch归一化取代了)
- Dropout: 提高全连接层的鲁棒性,增加网络的泛化能力
- Data Augmentation: TenCrop, 色彩修改
AlexNet和LeNet的架构非常相似,下面看看AlexNet的架构:

测试代码如下(其实也可以直接调用torchvision.models.AlexNet()):
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(# 特征层
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) # 平均池化
self.classifier = nn.Sequential(# 分类层
nn.Dropout(),# 用于正则化
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
容易发现Alex是用Sequential进行搭建的: 第一部分使用一个Sequential来装下卷积池化模块,目的是提取图像的特征,第二部分是一个全局的池化层把特征进行整合,第三层是使用一个Sequential来装全连接层组成的,用于模型的分类。forward函数就不再详细赘述。
虽然上述只是简单的介绍了Alex的架构和实现,但是聪明的读者在了解了本节内容后再去查看 VGG, ResNet等神经网络的经典架构后也许会惊讶的发现:不管这些模型多么复杂, 都可以使用nn.Module, Sequential, ModuleList, ModuleDict构建,所以依然可以看懂这些网络的逻辑,但具体的实现比如forward函数会随应用的不同而发生变化~
五、总结
这次的内容有点多,并且还去开会去了,还不容易才复习完以及码完字,但是这块内容非常的重要,所以还是得多回顾回顾。下面大致将本节内容做一个总结。
本节的内容主要是分为3大块, 第一块就是Pytorch模型的构建步骤有两个子模块的构建和拼接, 然后就是学习了非常重要的一个类叫做nn.Module(自定义的类都是继承了这个类,可以说是所有类的爸爸了)。nn.Module里面有8个重要的参数字典,其中_parameters和_modules是重点(读到这忘记了二者作用的话,还请往上翻翻再去记记呢),并且以LeNet为例通过代码调试的工具了解了一下LeNet的构建过程。
第二块是模型容器Containers,这里面先学习了nn.Sequential, 这个是顺序搭建每个子模块, 常用于block构建,依然以LeNet为例并通过代码调试了解了初始化和前向传播机制。 然后是nn.ModuleList, 这个类似于列表可迭代,常用于搭建结构相同的网络子模块(可以用列表推导式快速搭建)。 最后呢就是nn.ModuleDict,类似于字典,常用于可选择的网络层(比如GRU或者LSTM)。
第三块就是简要看了看经典卷积神经网络AlexNet的架构。
下面依然是贴上参考博客作者附上的一张思维导图~:
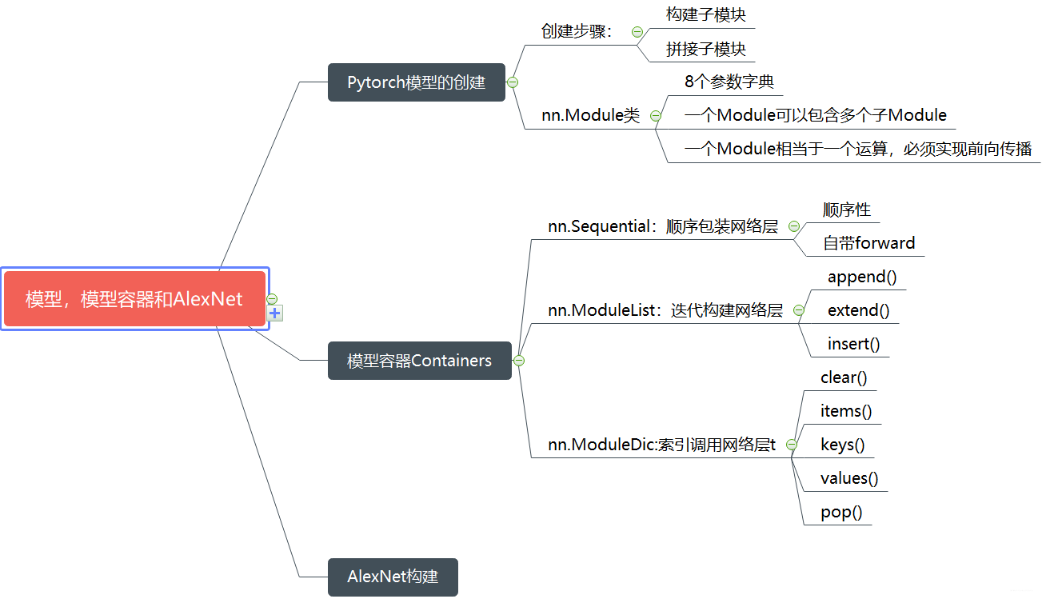
好哒,本次的内容总算回顾忘了,再次单方面地感谢参考博客的作者的图呢。















 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









