







1.在一个文件夹划分train、val
本来只有一个flower_photos文件夹
经过处理后,出现了train、val文件夹
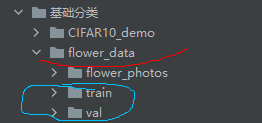
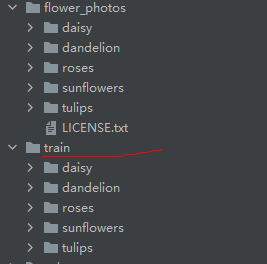
并且train和val文件夹如下
对目录下的文件名随机采样,生成列表 eval_index = random.sample(images, k=int(num*split_rate))
得到路径名后,copy
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
下面的assert多次使用了,要注意用法
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd()
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
assert os.path.exists(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()
2. 目标检测中,都是划分后放在txt文件下
最终的效果图
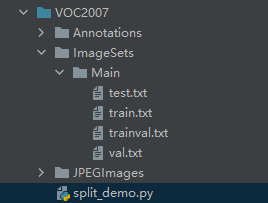
一个是对所有路径名进行random.sample,
一个则是对 range() 后的数字,进行sample
import os
import random
"""
训练集+验证集: 0.9 。其中训练集 0.9*0.9 = 0.81 验证集 0.9*0.1 = 0.09
测试集 :0.1
"""
# 保证结果可以复现
random.seed(0)
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml) # num : 17125
num_list = range(num) # num_list, 就是由range(17125)构成的多个数(应该不是list,就是索引而已), 0、1、2....17124
"""
print(rang(10)) : >>> range(0,10)
for i in range(10):
print(i) >>> 0 1 2 3 4 ... 9
"""
# tr是从tv中的0.9
# tv = int(17124*0.9) = 15412
# tr = int(15412 *0.9) = 13870
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
"""
random.sample:多用于截取列表中指定长度的随机数字,构成新list,但是不会改变原列表本身的排序:
list = [0,1,2,3,4]
rs = random.sample(list, 2)
print(rs)
print(list)
》》》[2, 4] #此数组随着不同的执行,里面的元素随机,但都是两个
》》》[0, 1, 2, 3, 4]
"""
# trainval得到的是很多个数字,应该用于后面充当索引
trainval = random.sample(num_list, tv)
train = random.sample(trainval, tr)
# 下面四行,应该是用于创建新的txt文件
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in num_list:
# total_xml中存入了所有xml的文件名
# 这一句话是把200700027.xml中的200700027取出来,不用.xml;
# 因为,这是一个大的for循环,将文件名存入对应的txt中,需要每次都换行
name = total_xml[i][:-4] + '\n'
"""
file_name,file_extend=os.path.splitext(total_xml[i])
分成了一个元组,由两部分组成
>>> ('D:\\pycharm\\pytorch相关\\labelImg-master\\ori_image\\2021_000008', '.jpg')
"""
# i只是一个索引 0~17124中的单个数字
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









