









| 索引类型 | 特性 | 原理 | 距离计算方式 |
|---|---|---|---|
| FLAT |
| 并非真正的索引,索引与向量原始数据一致,无需独立创建索引文件,检索时将向量原始数据加载至内存生成索引,属于暴力检索 |
|
| IVF_FLAT |
| 倒排索引,通过聚类的方式将向量添加到不同的分桶,数据不压缩,查询速度与召回率之间的权衡由参数 nprobe 来控制。nprobe 越大,召回率越高,但查询时间越长。 |
|
| IVF_SQ8 |
| 基于IVF_FLAT的一种向量数据压缩算法,将向量进行标量量化(原始向量中每个 FLOAT(4字节)转为 UINT8(1字节)),磁盘和内存占用比原来降至1/4。 |
|
| IVF_SQ8H |
| 对IVF_SQ8做了深度优化,把找出向量最近的nprobe个分桶的运算(Coarse Quantizer)单独拷贝到 GPU运算,大大的节省了Coarse Quantizer时间,每个分桶中的查询受配置参数 gpu_search_threshold 控制,当 nq >= gpu_search_threshold 时,查询在 GPU 上进行;反之在 CPU 上进行。 |
|
| IVF_PQ |
| 基于IVF_FLAT的一种向量数据有损压缩算法(PQ乘积量化),首先,PQ先将D维空间切分成M份:类似于将128维空间切分成M个D/M维的子空间,每个子向量进行k-means聚类。
|
|
| RNSG |
| NSG是通过建立导航点 (Navigation Point) ,特殊的选边策略, 深度遍历收回离散节点 (Deep Traversal) 等方法将导航点与子图相连接,获得良好的搜索性能。
|
|
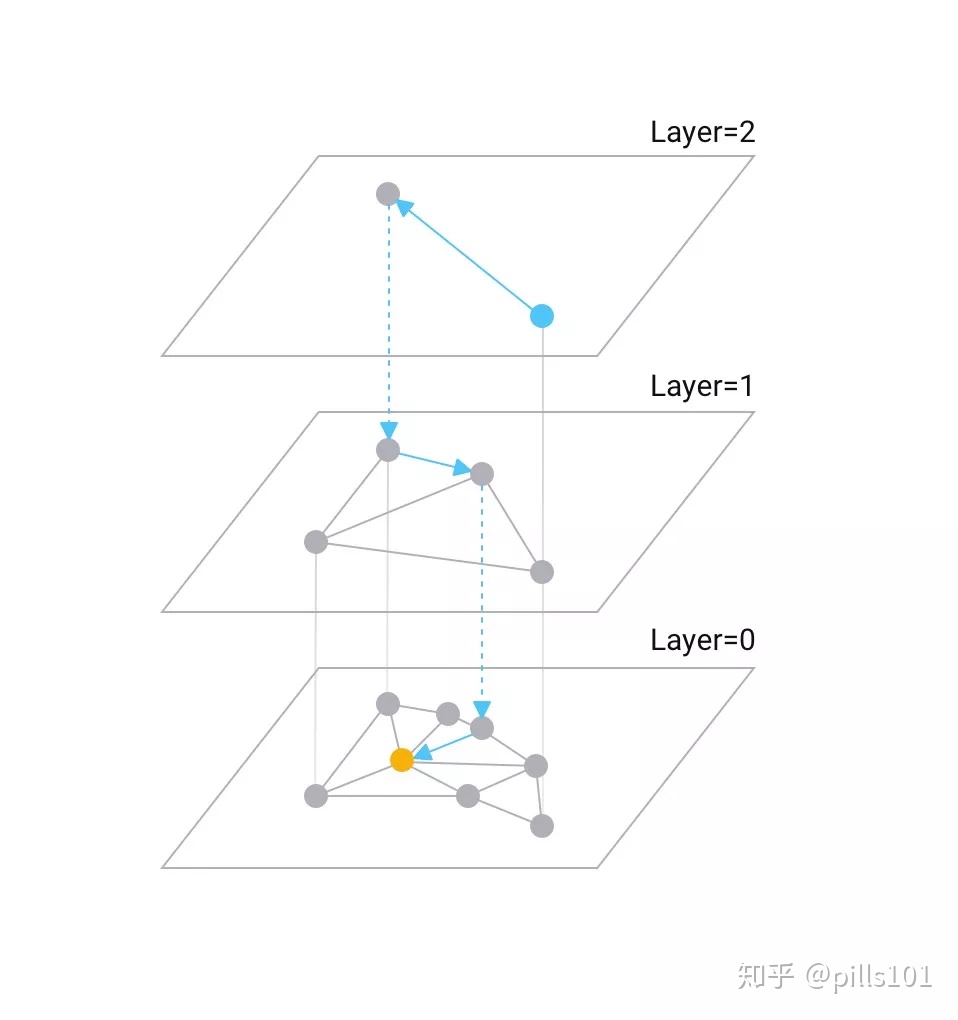
| HNSW |
| 前身是NSW,Milvus借鉴了 SkipList 的思想,提升了其整体性能,按照一定的规则把一张的图分成多张,越接近上层的图,平均度数越低,节点之间的距离越远;越接近下层的图平均度数越高,节点之间的距离也就越近。
|
|
| Annoy |
| 基于树的索引(1/n棵二叉树),建树时每次选择空间中的两个质心作为分割点,相当于kmeans过程,以使得两棵子树分割的尽量均匀以保证logn的检索复杂度。以垂直于过两点的直线的超平面来分割整个空间,然后在两个子空间内递归分割直到子空间最多只有k个点。如下图
|
|


 查找性能及准确度受treenum、searchnum控制
查找性能及准确度受treenum、searchnum控制关于rt的数据说明:基于1000000条 * 512维 整形向量计算,索引分桶数为512*16,每次检索np=1,topK=2,检索时nprobe=1024。















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









