






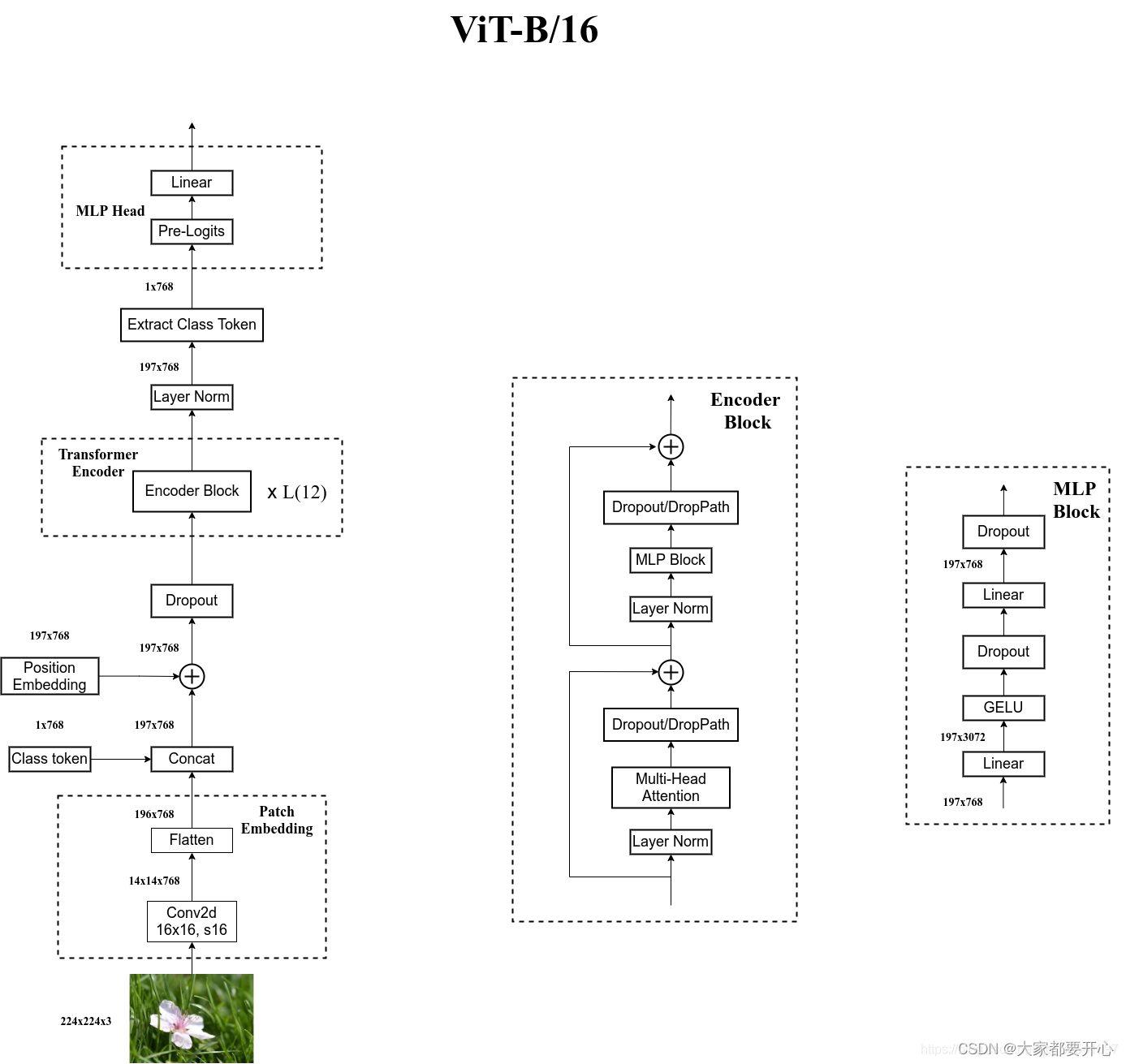
Vision Transformer(ViT)的模型框架如下图:

第一步: 使用ViT实现图片分类,首先需将图片分割成不同的块(Patches);
第二步:向量化,将各个张量拉伸成向量。假如每个Patch对应的张量的形状为(3,16,16),对应向量的形状为(1,768),对应二维矩阵[num_token, token_dim]。原图被分割为n个Patch,就能得到向量x1~xn。
第三步:在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding。
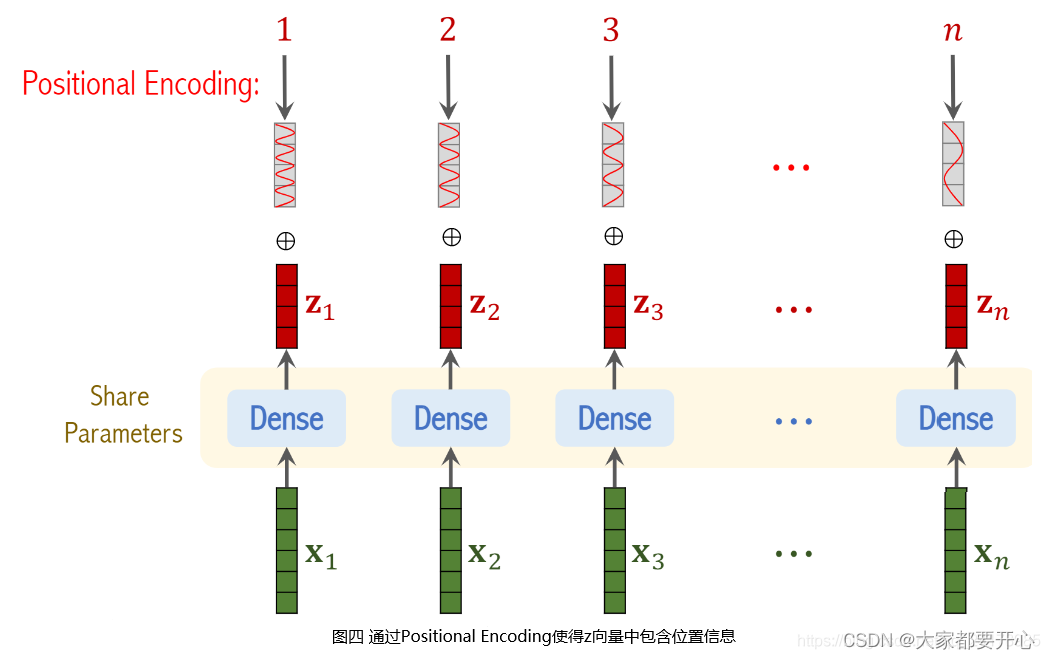
使用一个不包含激活函数的全连接层对x1~xn进行线性变换,其中n个全连接层共享参数。
因为Attention是没有学习顺序信息的能力的,对图片每一个Patch的位置做编码。其中transformer的位置编码是用三角函数直接算出来的。
在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起。
第四步:Transformer Encoder。Transformer Encoder其实就是重复堆叠Encoder Block L次。

在这里用代码来解释以下Encoder Block。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
class MultiHeadSelfAttention(layers.Layer):
def __init__(self, embed_dim, num_heads=8):
super(MultiHeadSelfAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
if embed_dim % num_heads != 0:
raise ValueError(
f"embedding dimension = {embed_dim} should be divisible by number of heads = {num_heads}"
)
self.projection_dim = embed_dim // num_heads
self.query_dense = layers.Dense(embed_dim)
self.key_dense = layers.Dense(embed_dim)
self.value_dense = layers.Dense(embed_dim)
self.combine_heads = layers.Dense(embed_dim)
def attention(self, query, key, value):
score = tf.matmul(query, key, transpose_b=True)
dim_key = tf.cast(tf.shape(key)[-1], tf.float32)
scaled_score = score / tf.math.sqrt(dim_key)
weights = tf.nn.softmax(scaled_score, axis=-1)
output = tf.matmul(weights, value)
return output, weights
def separate_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.projection_dim))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, inputs):
# x.shape = [batch_size, seq_len, embedding_dim]
batch_size = tf.shape(inputs)[0]
# 计算原始的Q,K,V矩阵
query = self.query_dense(inputs) # (batch_size, seq_len, embed_dim)
key = self.key_dense(inputs) # (batch_size, seq_len, embed_dim)
value = self.value_dense(inputs) # (batch_size, seq_len, embed_dim)
# 进行切分,得到多头
query = self.separate_heads(
query, batch_size
) # (batch_size, num_heads, seq_len, projection_dim)
key = self.separate_heads(
key, batch_size
) # (batch_size, num_heads, seq_len, projection_dim)
value = self.separate_heads(
value, batch_size
) # (batch_size, num_heads, seq_len, projection_dim)
# 注意力计算
attention, weights = self.attention(query, key, value)
attention = tf.transpose(
attention, perm=[0, 2, 1, 3]
) # (batch_size, seq_len, num_heads, projection_dim)
# 多个头进行拼接
concat_attention = tf.reshape(
attention, (batch_size, -1, self.embed_dim)
) # (batch_size, seq_len, embed_dim)
output = self.combine_heads(
concat_attention
) # (batch_size, seq_len, embed_dim)
return output
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = MultiHeadSelfAttention(embed_dim, num_heads)
self.ffn = keras.Sequential(
[layers.Dense(ff_dim, activation="relu"), layers.Dense(embed_dim),]
)
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(rate)
def call(self, inputs, training):
# 对应文章中的第2部分
attn_output = self.att(inputs)
attn_output = self.dropout1(attn_output, training=training)
# 对应文章中的第3部分
out1 = self.layernorm1(inputs + attn_output)
# 对应文章中的第4部分
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)第五步:MLP Head。需要提取出[class]token生成的对应结果 。
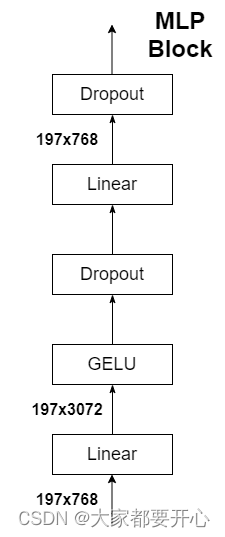
MLP Head采用普通的全连接层即可实现。
最后附上ViT-B/16的图解:














 23万+
23万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









