







 本文探讨了语义分割的历史发展,特别是深度学习特别是Transformer模型如何显著提升任务性能。通过实例展示了如何使用HuggingFaceTransformers库中的DETR、Segformer、BEiT、MaskFormer和DPT模型进行图像语义分割,包括预训练模型的加载、图像处理和可视化,强调了Transformer在捕捉复杂语义信息和生成直观可视化上的关键作用。
本文探讨了语义分割的历史发展,特别是深度学习特别是Transformer模型如何显著提升任务性能。通过实例展示了如何使用HuggingFaceTransformers库中的DETR、Segformer、BEiT、MaskFormer和DPT模型进行图像语义分割,包括预训练模型的加载、图像处理和可视化,强调了Transformer在捕捉复杂语义信息和生成直观可视化上的关键作用。
语义分割的研究历史可以追溯到早期,当时研究人员主要依赖于手动创建的特征和传统的机器学习模型。这些方法通常基于图像的纹理、颜色和形状等特征来进行分割,但面临着对复杂场景的适应性不足的挑战。随着深度学习的兴起,尤其是卷积神经网络(CNNs)的发展,语义分割取得了显著的进展。CNNs通过学习图像的高层次特征,能够更有效地进行语义分割,提高了在各种场景下的性能。深度神经网络的出现使得语义分割不再依赖于手动设计的特征,而是能够从数据中学习更复杂、更抽象的特征,从而提升了分割任务的准确性和泛化能力。
在计算机视觉中,语义分割提供了对图像内部结构的详细理解,为计算机系统对图像进行高级理解和决策提供了基础。通过对图像进行像素级别的语义分析,计算机能够准确地识别和理解图像中的各个对象和区域,为各种应用提供更精确的信息。
请看下面的实例,演示了使用Transformer实现了一个综合图像分割系统的过程,本项目实现了基于Transformer的端到端图像分割和可视化功能。通过加载预训练的Transformer模型,实现了对输入图像的准确分割。Transformer在序列数据处理方面的优越性使得模型能够捕捉图像中的复杂语义信息。在可视化阶段,Transformer进一步用于将分割结果映射为直观的图像效果,通过用户定义的词汇表和颜色映射,呈现出高质量的分割可视化。这凸显了Transformer在处理图像语义和生成直观分割可视化方面的关键作用,为用户提供了深度学习图像分割技术的强大展示和应用。
实例9-2:使用Vision Transformer进行语义分割(源码路径:daima\9\Semantic.ipynb)
实例文件Semantic.ipynb的具体实现流程如下所示。
(1)下面代码通过使用 Hugging Face 的 Transformers 库,从给定的 URL 下载一张图像,然后使用预训练的 DETR(DEtection TRansformers)模型进行图像语义分割。首先,通过 requests 模块从指定 URL 获取图像数据,然后使用 Image.open 方法将其加载为 PIL 图像对象。接着,使用 Transformers 库中的 AutoImageProcessor 创建一个图像处理器对象,并使用 DetrForSegmentation 模型进行语义分割。最后,代码通过 matplotlib.pyplot 库将原始图像和语义分割结果进行可视化。
import io
import requests
from PIL import Image
import torch
import numpy as np
import matplotlib.pyplot as plt
from transformers import AutoImageProcessor, DetrForSegmentation
from transformers.image_transforms import rgb_to_id
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)(2)使用matplotlib.pyplot库中的plt.imshow(image)命令来显示上面的图像url。
plt.imshow(image)执行效果如图9-3所示。

图9-3 显示的图像
(3)下面代码使用 Hugging Face Transformers 库加载了一个预训练的 DETR 模型(facebook/detr-resnet-50-panoptic)以及相应的图像处理器。接着,它将图像输入到模型中,获取模型的输出。最后,通过调用 image_processor.post_process_panoptic_segmentation 对模型输出进行后处理,提取出语义分割的结果 panoptic_seg 以及相关的分割信息 panoptic_segments_info。
image_processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50-panoptic")
model = DetrForSegmentation.from_pretrained("facebook/detr-resnet-50-panoptic")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
result = image_processor.post_process_panoptic_segmentation(outputs, target_sizes=[(300, 500)])
panoptic_seg = result[0]["segmentation"]
panoptic_segments_info = result[0]["segments_info"]上述代码的主要目的是使用 DETR 模型进行图像的语义分割,将图像中的不同语义区域进行标记,并提取相关的分割信息,这对于图像理解和计算机视觉任务非常有用。
(4)使用函数plt.imshow()显示分割后的图像,注意,如果 panoptic_seg 是一个分割标签的二维数组,你可能需要使用一个 colormap 来为不同的标签分配不同的颜色,以便更清晰地可视化语义分割结果。
plt.imshow(panoptic_seg)执行效果如图9-4所示。
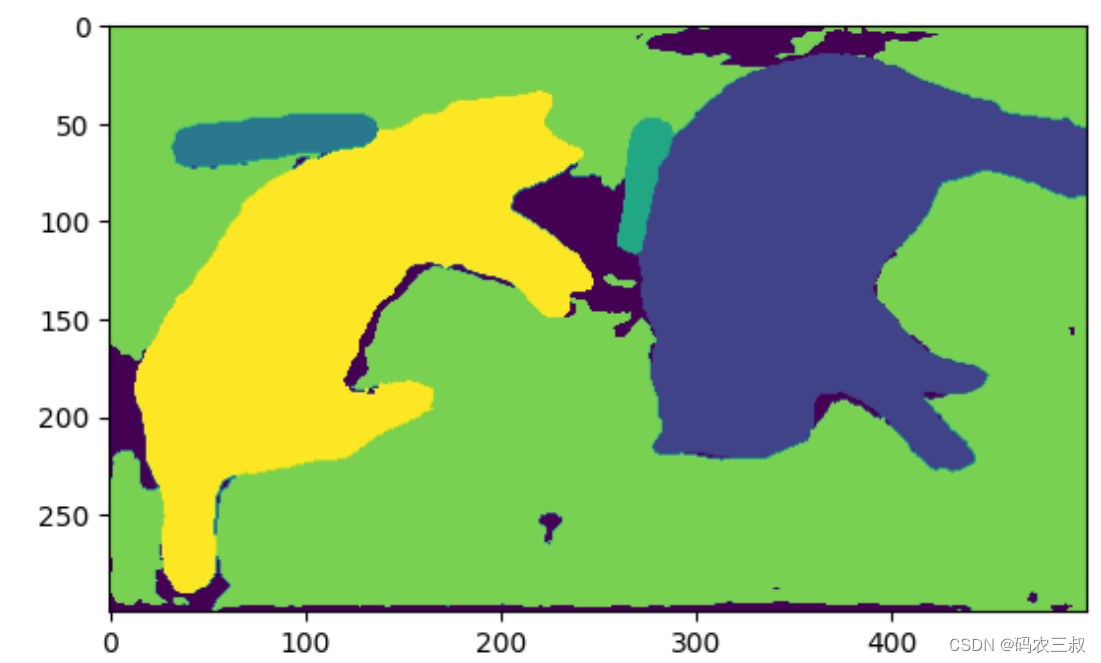
图9-4 分割后的图像
(5)下面代码使用 Hugging Face Transformers 库加载了一个预训练的 Segformer 模型(nvidia/segformer-b5-finetuned-ade-640-640)以及相应的图像处理器。接着,它将图像输入到模型中,获取模型的输出。最后,通过 outputs.logits 获取了模型的预测结果,其中 logits 是一个张量,表示每个像素对应于每个语义类别的分数。
from transformers import SegformerForSemanticSegmentation
import tensorflow as tf
image_processor = AutoImageProcessor.from_pretrained("nvidia/segformer-b5-finetuned-ade-640-640")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b5-finetuned-ade-640-640")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)上述代码的目的是使用 Segformer 模型进行语义分割,得到图像中每个像素的语义类别分数,这可以用于图像理解和语义分割任务。
(6)在下面的代码中,首先使用 logits.detach().numpy() 将 PyTorch 张量转换为 NumPy 数组,然后使用 tf.transpose() 对数组进行转置,以适应 TensorFlow 的张量格式。最后,使用 tf.math.argmax() 获取沿最后一个轴的最大值的索引,得到预测的语义分割标签。最终,使用 plt.imshow() 函数将语义分割结果进行可视化。
logits = tf.transpose(logits.detach().numpy(), [0, 2, 3, 1])
pred_seg = tf.math.argmax(logits, axis=-1)[0]
plt.imshow(pred_seg)注意:如果 pred_seg 是一个包含分割标签的二维数组,需要使用一个 colormap 来为不同的标签分配不同的颜色,以便更清晰地可视化语义分割结果。
执行效果如图9-5所示。
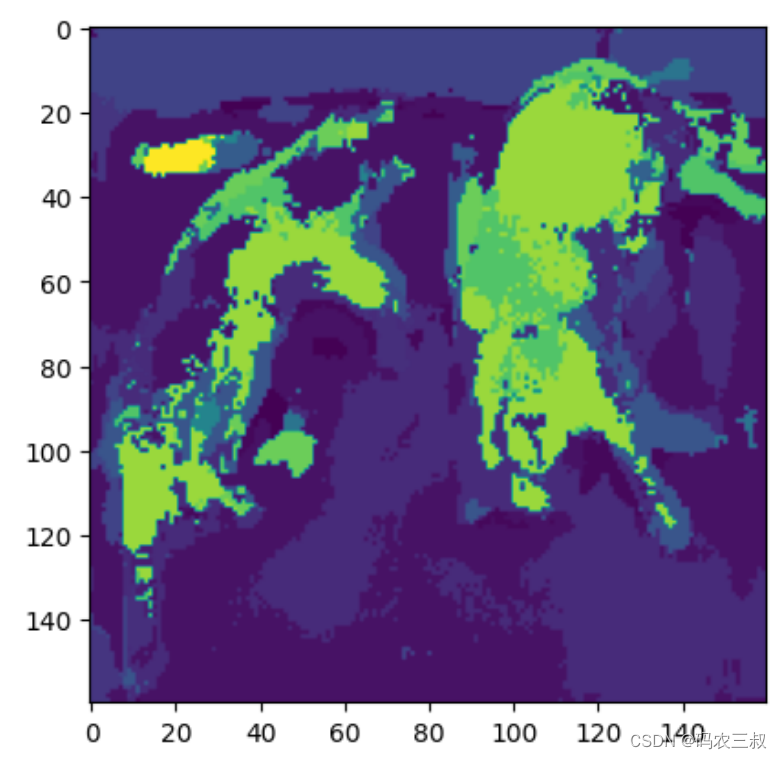
图9-5 语义分割结果的可视化
(7)使用 库Hugging Face Transformers加载了一个预训练的 BEiT(Be Vision Transformer)模型(microsoft/beit-base-finetuned-ade-640-640)以及相应的图像处理器,接着将图像输入到模型中,获取模型的输出。最后,通过 np.argmax() 获取了模型的预测结果,其中 logits 是一个包含每个像素对应于每个语义类别的分数的张量。
from transformers import AutoImageProcessor, BeitForSemanticSegmentation
image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
model = BeitForSemanticSegmentation.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
plt.imshow(np.argmax(logits.detach().numpy()[0],axis=0))上述代码使用np.argmax(logits.detach().numpy()[0],axis=0) 获取了沿着第一个轴(batch_size)的最大值的索引,以得到预测的语义分割标签。然后,使用 plt.imshow()函数将语义分割结果进行可视化。执行效果如图9-6所示。
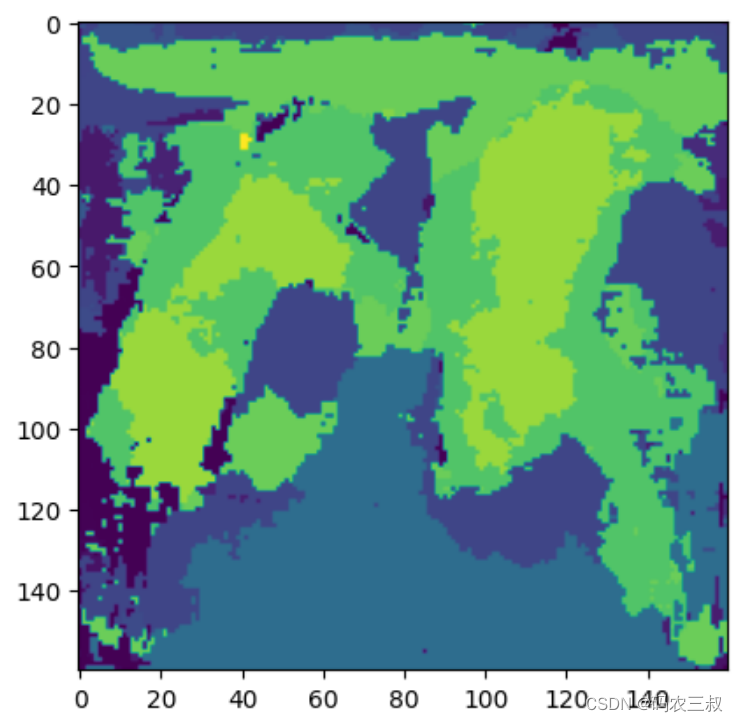
图9-6 BEiT预测结果的可视化
(8)使用库Hugging Face Transformers加载了一个预训练的 MaskFormer 模型(facebook/maskformer-swin-tiny-ade)以及相应的图像处理器,接着将图像输入到模型中,获取模型的输出。具体来说,通过 outputs.class_queries_logits 和 outputs.masks_queries_logits 获取了模型的类别查询概率和掩码查询概率。最后,使用 image_processor.post_process_semantic_segmentation 对模型输出进行后处理,得到了预测的语义分割地图(predicted_semantic_map)。该语义分割地图的形状信息通过 list(predicted_semantic_map.shape) 返回。
from transformers import AutoImageProcessor, MaskFormerForInstanceSegmentation
image_processor = AutoImageProcessor.from_pretrained("facebook/maskformer-swin-tiny-ade")
model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-tiny-ade")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
predicted_semantic_map = image_processor.post_process_semantic_segmentation(
outputs, target_sizes=[image.size[::-1]]
)[0]
list(predicted_semantic_map.shape)上述代码的目的是使用 MaskFormer 模型进行实例分割,获取图像中每个像素的类别查询概率、掩码查询概率以及最终的语义分割地图。这对于图像理解和实例分割任务非常有用。执行后输出:
[480, 640](9)可视化显示 MaskFormer 模型的预测的语义分割地图。
plt.imshow(predicted_semantic_map)执行效果如图9-7所示。
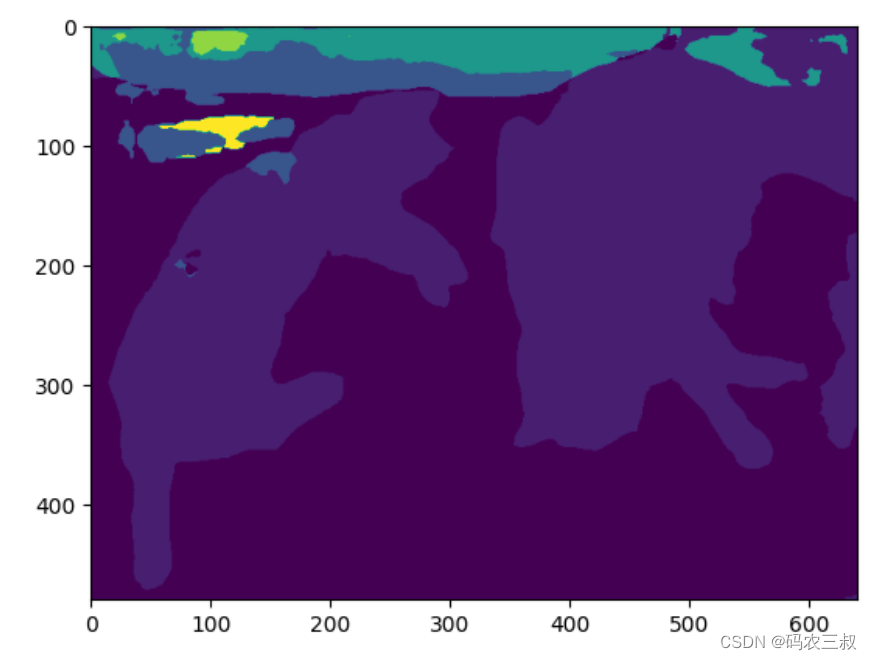
图9-7 MaskFormer 模型的预测结果的可视化
(10)下面代码使用 Hugging Face Transformers 库加载了一个预训练的 DPT(Depth Prediction Transformer)模型(Intel/dpt-large-ade)以及相应的图像处理器,接着将图像输入到模型中,获取模型的输出。通过 outputs.logits 获取了模型的预测结果,其中 logits 是一个张量,表示每个像素对应于每个语义类别的分数。最后,通过 logits.shape 返回了模型输出的张量形状信息。
from transformers import AutoImageProcessor, DPTForSemanticSegmentation
image_processor = AutoImageProcessor.from_pretrained("Intel/dpt-large-ade")
model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
logits.shape上述代码的目的是使用 DPT 模型进行语义分割,得到图像中每个像素的语义类别分数。执行后会输出:
torch.Size([1, 150, 480, 480])(11)使用 np.argmax() 获取了沿着第一个轴的最大值的索引,以得到 DPT 模型的预测的语义分割标签。然后,使用 plt.imshow() 函数将语义分割结果进行可视化。
plt.imshow(np.argmax(logits.detach().numpy()[0],axis=0))执行效果如图9-8所示。
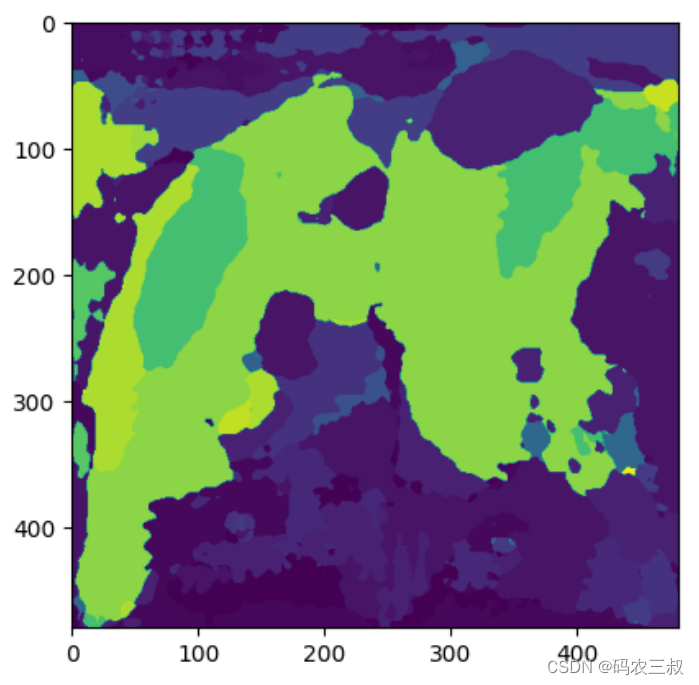
图9-8 DPT语义分割结果的可视化



















 1409
1409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











