







为什么要写这篇文章?
自己买了带GPU机器但长期只能狂跑CPU,最近通过借鉴代码和摸索,终于让自己的GPU跑起来了。考虑到和我一样的小白,把经验分享出来供大家参考。
为了更方便的说明,我把自己参加的一个天池长期赛部分代码展示出来,并突出GPU相关的修改部分。
效果展示
之前CPU跑满100%,终于看到GPU也跑起来了。

代码示例
这是机器学习中的监督学习问题,所有标签已经打好,信号已经标准化在0-1之间,是一个典型的多分类问题(四分类)。人体信号中比较麻烦的是信号预处理和标准化等,这个属于入门赛,已经先帮助选手消化好了。但实际做项目可就没有这么幸运了,可能这就是入门赛和实际工作中项目之间的差异之一吧。
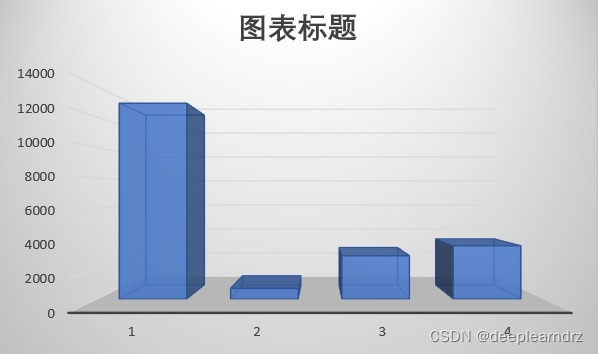
医疗数据中还有一个特点是正常样本多,病患样本少。这个问题在本赛题中也体现出来了。正常样本(分类1)超过了10000例,而某种心脏疾病的病例数才几百例。这也是分类问题中经常遇到的,最好对小样本进行数据增强,稍后验证有效的方法出来后再补充。
if torch.cuda.is_available():
device = torch.device("cuda:0")
else:
print('no gpu')
device = 'cpu'
train = pd.read_csv('train.csv')
test = pd.read_csv('testA.csv')
...
dataset = Data.TensorDataset(x_train,y_train)
train_data,eval_data =random_split(dataset,[round(0.8*x_train.shape[0]),round(0.2*y_train.shape[0])],generator=torch.Generator())
loader = Data.DataLoader(dataset = train_data, batch_size = bat_size,shuffle = True)
class MLP(nn.Module):
def __init__(self):
super(MLP,self).__init__()
self.hidden1 = nn.Linear(in_features = 205, out_features = 512)
self.hidden2 = nn.Linear(512,128)
self.hidden3 = nn.Linear(128,16)
def forward(self,x):
x = self.relu(self.bn1(self.hidden1(self.bn0(x))))
self.drop
x = self.relu(self.bn2(self.hidden2(x)))
x = self.relu(self.bn3(self.hidden3(x)))
return x
# build model
model = MLP()
model = model.to(device)
loss_function = nn.MSELoss()
optimizer = optim.Adam(model.parameters(),lr = learn_rate)
# start training
train_loss = []
val_loss = []
test_loss = []
for epoch in range(num_epochs):
for batch_idx,(x,y) in enumerate(loader):
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
out = model(x)
out = out.to(device)
loss = loss_function(out,y)
#反向传播和优化
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if epoch % 20 == 0:
val_out = model(eval_data.dataset[:][0].to(device))
v_loss = loss_function(val_out,eval_data.dataset[:][1].to(device))
torch.save(model.state_dict(),"./baseline.pth")
print('model saved')
y_test = model(x_test.to(device))
代码剖析
1.增加事前判断语句
if torch.cuda.is_available():
device = torch.device("cuda:0")
else:
print('no gpu')
device = 'cpu'
2.将模型model、训练时的输入输出x、y、计算验证集LOSS时的模型推理输出out、计算测试集时的输入后面增加to(device)
# build model
model = MLP()
model = model.to(device)
...
for epoch in range(num_epochs):
for batch_idx,(x,y) in enumerate(loader):
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
out = model(x)
out = out.to(device)
loss = loss_function(out,y)
...
if epoch % 20 == 0:
val_out = model(eval_data.dataset[:][0].to(device))
v_loss = loss_function(val_out,eval_data.dataset[:][1].to(device))
y_test = model(x_test.to(device))
注意事项
因为最终输出是在GPU,所以需要对输出进行处理时,还要传送回CPU处理。
结束语
您的支持将支付我GPU运行的电费账单,可以一直将喜欢的AI比赛进行下去。
编写过程中发现之前C友的文章很有用,列如下:
[1]https://blog.csdn.net/qq_43535213/article/details/118738323
















 4955
4955











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











