








这篇文章发表在2022年的AAAI,研究的是多元时间序列的多步预测问题。作者提出了一个CATN模型,该模型第一次使用树结构来捕捉多个时间序列间的交叉特征,然后使用包含全局、局部学习、交叉注意力机制的多级学习机制来捕捉序列内部的时间特征。
1.问题定义
1.1 什么是多元时间序列?
论文中的多元时间序列就是包含不同不同变量的时间序列,这些变量是相互关联的,它们可以来自同一系统或过程的不同方面。多元时间序列可以用于分析现实世界中的各种现象,例如金融市场、气象、交通流量等。
举一个具体的例子,假设正在研究某个城市的交通流量。我们可以收集到许多不同的变量,例如每小时通过某个路段的车辆数量、平均车速、车辆类型等等。这些变量可以组成一个多元时间序列数据集,其中每个时间点都有多个变量值。通过分析这些数据,我们可以了解交通流量的趋势和模式,并预测未来的交通情况。
1.2 多元时间序列预测
单元时间序列:
x
i
=
{
x
1
i
,
x
2
i
,
.
.
.
x
T
i
}
\mathrm{x}^i=\{x^i_1,x^i_2,...x^i_T\}
xi={x1i,x2i,...xTi}.
多元时间序列:
X
=
{
x
1
,
x
2
,
.
.
.
x
d
x
∣
x
T
x
∈
R
d
x
,
x
d
x
∈
R
T
x
}
\mathcal{X}=\{\mathrm{x}^1,\mathrm{x}^2,...\mathrm{x}^{d_x}|x_{T_x}\in \mathbb{R}^{d_x},\mathrm{x}^{d_x}\in \mathbb{R}^{T_x}\}
X={x1,x2,...xdx∣xTx∈Rdx,xdx∈RTx}
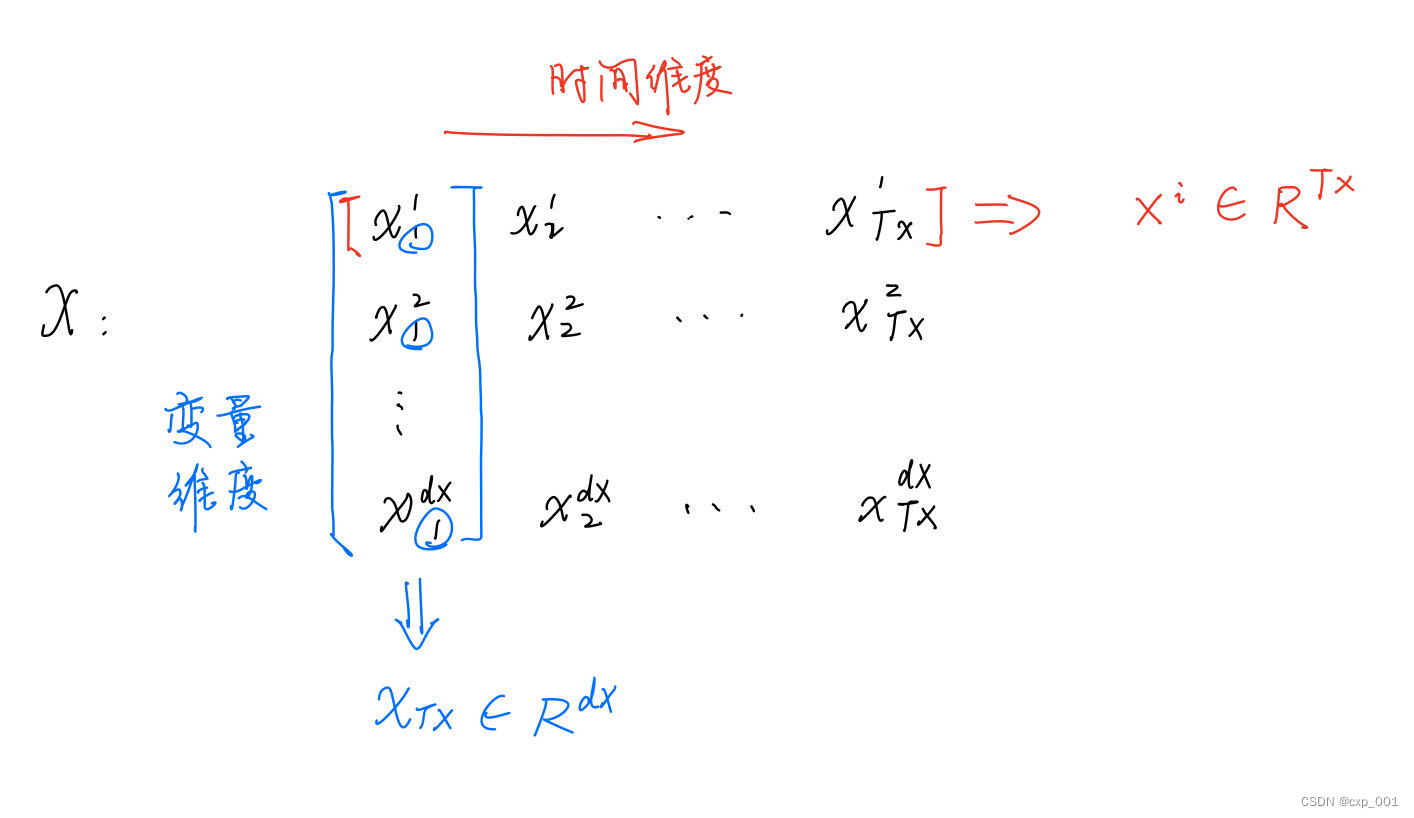 多元时间序列预测:
多元时间序列预测:
给定
X
\mathcal{X}
X,输出是
Y
=
{
y
1
,
y
2
,
y
3
,
.
.
.
y
d
y
∣
y
d
y
∈
R
T
y
,
y
T
y
∈
R
d
y
}
\mathcal{Y}=\{\mathrm{y}^1,\mathrm{y}^2,\mathrm{y}^3,...\mathrm{y}^{d_y}|\mathrm{y}^{dy}\in \mathbb{R}^{T_y},y_{T_y}\in \mathbb{R}^{d_y}\}
Y={y1,y2,y3,...ydy∣ydy∈RTy,yTy∈Rdy}.
2. 模型
模型的总体结构如图所示,
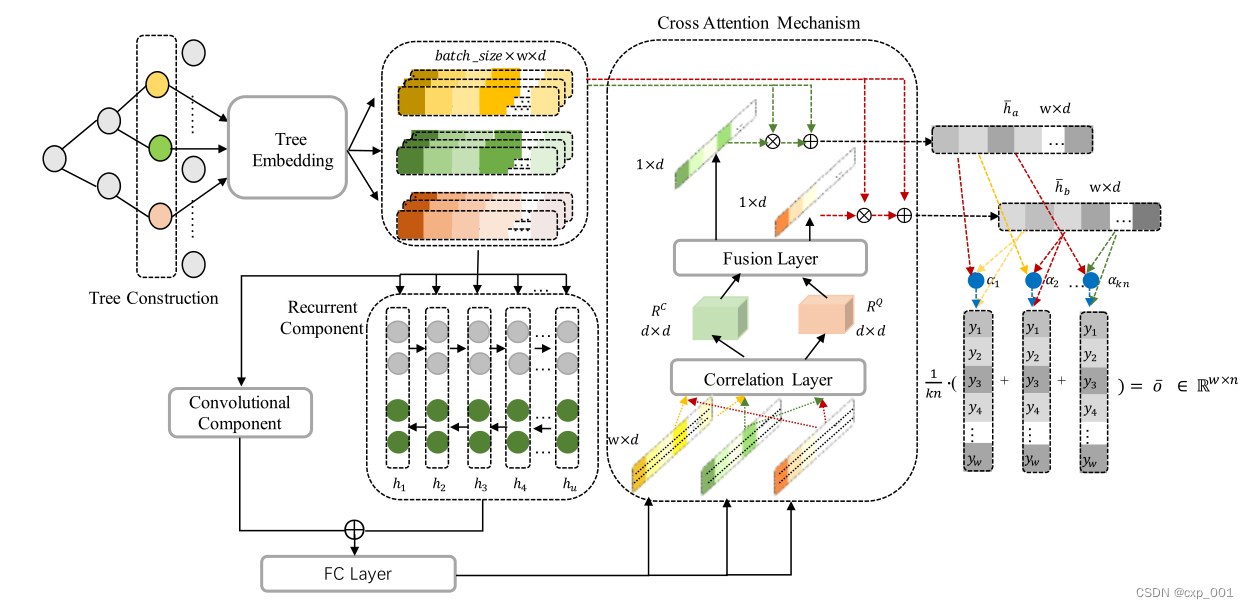
2.1 构建树
作者通过层次聚类的方法,由下到上构建一个树的结构。
其中,对于多元时间序列
X
=
{
x
1
,
x
2
,
.
.
.
x
d
x
∣
x
T
x
∈
R
d
x
,
x
d
x
∈
R
T
x
}
\mathcal{X}=\{\mathrm{x}^1,\mathrm{x}^2,...\mathrm{x}^{d_x}|x_{T_x}\in \mathbb{R}^{d_x},\mathrm{x}^{d_x}\in \mathbb{R}^{T_x}\}
X={x1,x2,...xdx∣xTx∈Rdx,xdx∈RTx},
作者从时间维度将
X
\mathcal{X}
X看作为向量形式的时间序列,即
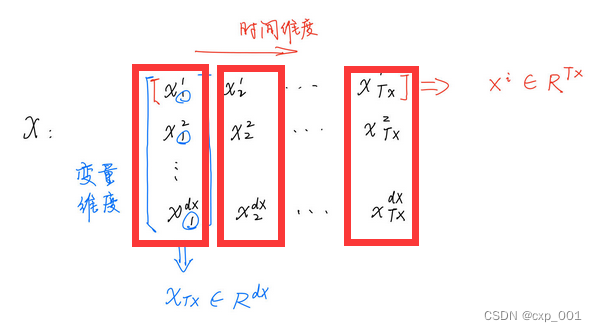
将当中的每一个向量视为树的叶子节点,然后通过层次聚类,构建一棵二叉树。
层次聚类常用的方法有(1)单链接(single-linkage)聚类法,类间距离等于两类对象之间的最小距离。(2)完全链接(complete-linkage )聚类法,组间距离等于两组对象之间的最大距离。(3)平均链接(average-linkage)聚类法,组间距离等于两组对象之间的平均距离。
但是,作者认为最远和最近的距离准则不能代表整个簇,平均链接时间复杂度较高,于是使用了中值链接准则来计算类间距离:
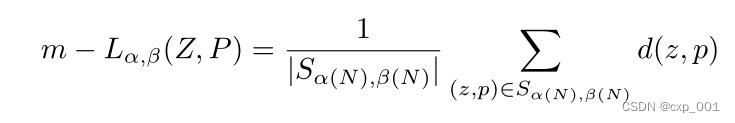
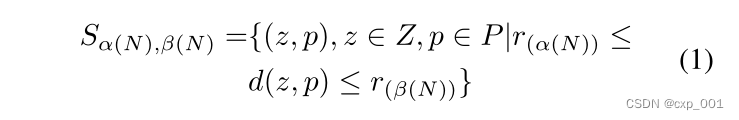
2.2 Tree embedding
作者将树定义为边和点的集合: T { V , E } \mathcal{T}\{V,E\} T{V,E}。将 V V V划分为叶子节点 V L V_L VL和非叶子节点 V I V_I VI。将边 E E E划分为左向边 E L E_L EL和右向边 E R E_R ER。
(1)节点嵌入
将每个叶子节点
v
l
∈
V
L
v_l\in V_L
vl∈VL嵌入到一个可更新的稠密向量
u
∈
R
d
u\in \mathbb{R}^d
u∈Rd。
(2)时间嵌入
选择t步的时间信息
E
t
∈
R
r
×
t
E_t \in \mathbb{R}^{r\times t}
Et∈Rr×t,r为时间戳分层的总数。然后将
E
t
E_t
Et映射到稠密向量
R
r
×
t
\mathbb{R}^{r\times t}
Rr×t。
最终,将节点嵌入向量和时间嵌入向量拼接作为叶子节点最终的表示,叶子节点可以表示为
[
u
:
E
t
]
[u:E_t]
[u:Et]。
(3)边嵌入
分别将左向边和右向边嵌入到稠密向量
e
l
,
e
r
e_l,e_r
el,er。
非叶子节点
v
i
∈
V
I
v_i\in V_I
vi∈VI的表示:
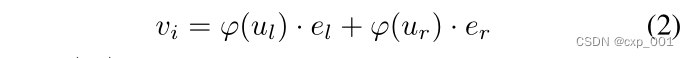
其中,
φ
\varphi
φ是填充缺失值的操作。
然后对节点进行归一化:
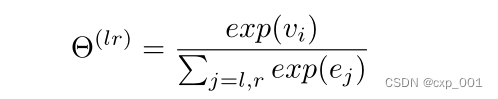
2.3 全局和局部学习
(1)卷积操作
使用卷积来挖掘局部信息,使用循环分量来挖掘全局信息。
使用
n
c
nc
nc个滤波器对每个节点的
E
d
E_d
Ed进行卷积操作。
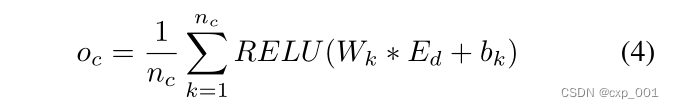
最后,输出的大小为
w
×
1
w\times 1
w×1。
(2)循环操作
对于每个节点,我们得到
E
d
∈
R
w
×
d
E_d\in \mathbb{R}^{w\times d}
Ed∈Rw×d,然后kn个节点的嵌入输入到kn个LSTMs当中。作者采用双向LSTM。对于每个LSTM,其循环次数为
u
=
d
2
u=\frac{d}{2}
u=2d,然后我们可以得到两个隐含向量序列:


然后进行拼接,
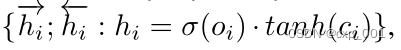
最后,和卷积模块的输出
o
c
o_c
oc拼接,然后馈入交叉注意模块。
2.4 交叉注意机制
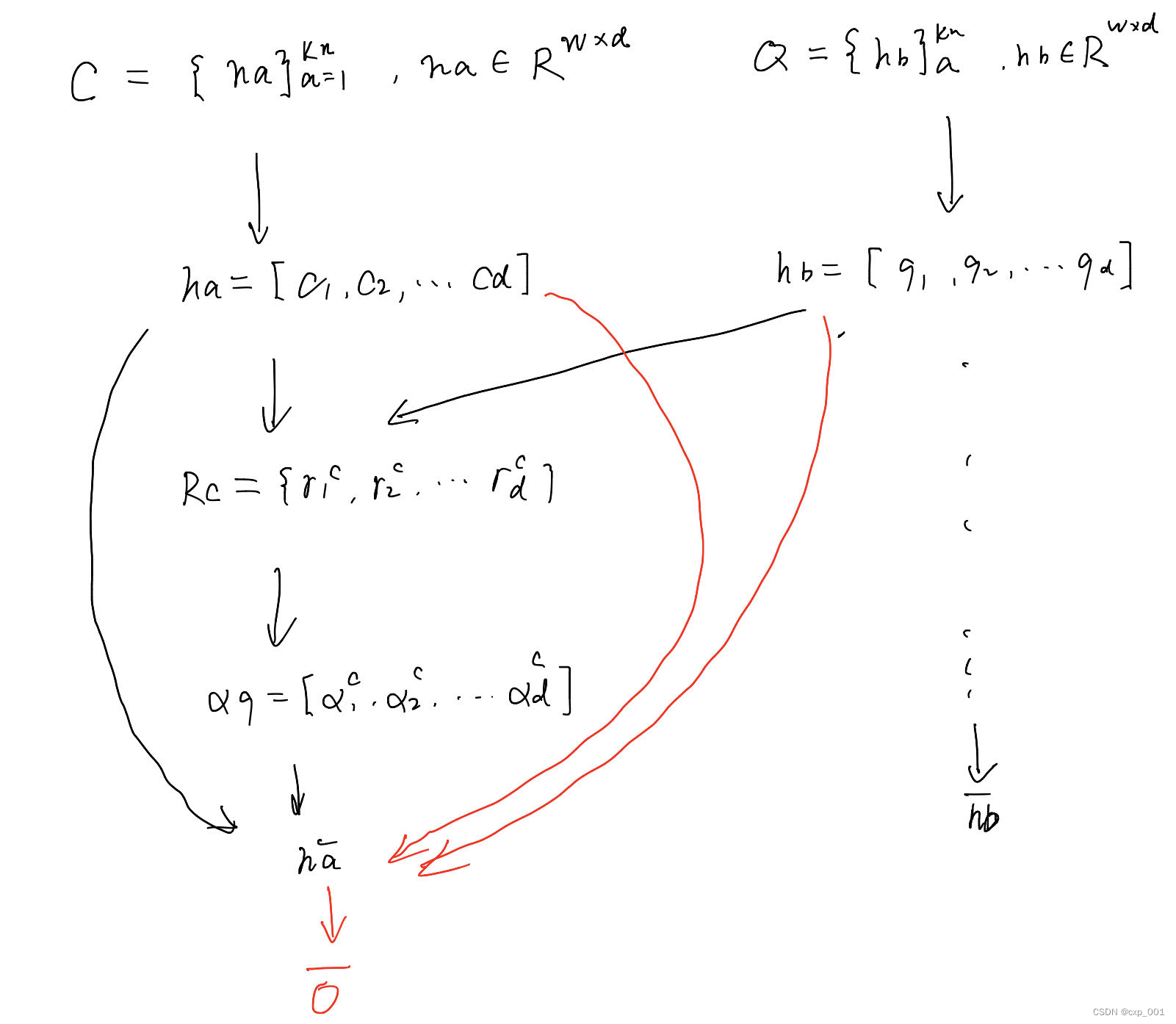
树的第k层的节点输入到局部和全局输出模块,最终得到kn个隐藏状态。对于这些隐藏状态,作者将其划分为两个集合, C = { h a } a = 1 k n \mathcal{C}=\{h_a\}^{kn}_{a=1} C={ha}a=1kn由kn个节点的隐藏状态构成和 Q = { h b } b = a + 1 k n \mathcal{Q}=\{h_b\}^{kn}_{b=a+1} Q={hb}b=a+1kn由kn-a个隐藏状态构成。然后构造集合 S = { ( h a , h b ) ∣ a ∈ [ 1 , k n ] , b ∈ ( a , k n ] } \mathcal{S}=\{(h_a,h_b)|a\in [1,kn],b\in (a,kn]\} S={(ha,hb)∣a∈[1,kn],b∈(a,kn]}。交叉注意通过ha和hb之间的关联度来衡量注意的程度,有助于重读目标的重要信息,提高特征的可分辩性。
对于 h a = [ c 1 , c 2 , . . . c d ] h_a=[c_1,c_2,...c_d] ha=[c1,c2,...cd]和 h b = [ q 1 , q 2 , . . . q d ] h_b=[q_1,q_2,...q_d] hb=[q1,q2,...qd]。我们可以计算 c i c_i ci和 c j c_j cj之间的相似度矩阵: R R R,使用余弦相似度计算。我们可以得到基于 h a h_a ha和基于 h b h_b hb的相关图 R c R^c Rc和 R q R^q Rq(我感觉他俩是一样的)。
然后,在融合层,对于对比注意力图
R
c
=
{
r
1
c
,
r
2
c
,
.
.
.
r
d
c
}
∈
R
d
×
d
R_c=\{r_1^c,r_2^c,...r_d^c\}\in \mathbb{R}^{d\times d}
Rc={r1c,r2c,...rdc}∈Rd×d,我们计算第i个位置的注意力值,是一个标量
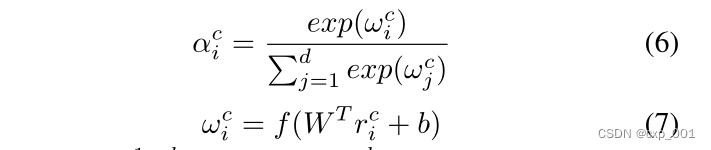
对于
R
c
R_c
Rc,w吗可以得到对应每个位置的注意力值向量
α
c
∈
R
1
×
d
\alpha_c\in \mathbb{R}^{1\times d}
αc∈R1×d。
同样,对于
R
q
R_q
Rq,我们可以得到注意力值向量
α
q
∈
R
1
×
d
\alpha_q\in \mathbb{R}^{1\times d}
αq∈R1×d。
然后我们使用注意力值向量对 h a , h b h_a,h_b ha,hb进行加权求和,同时使用残差注意机制,得到 h a ‾ ∈ R w × 1 , h b ‾ ∈ R w × 1 \overline{h_a} \in \mathbb{R}^{w\times 1} ,\overline{h_b}\in\mathbb{R}^{w\times 1} ha∈Rw×1,hb∈Rw×1。
然后,可以得到新的集合 S ‾ = ( h a ‾ , h b ‾ ) \overline{\mathcal{S}}={(\overline{h_a},\overline{h_b})} S=(ha,hb)。
然后,再次根据注意力计算最终输出:
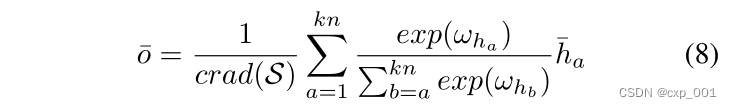
总体流程:
2.5 学习目标
最小化多步预测误差
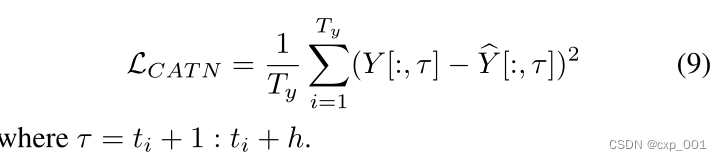
3.实验
3.1 实验设置
使用了四个真实世界的数据集,包括(1)交通数据集。(2)电力数据集。(3)加州高速公路系统数据集。(4)洛杉矶县高速公路数据集。
使用了五个典型的指标,即平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)、对称平均绝对百分比误差(SMAPE)和加权绝对百分比误差(W APE)来进行时间序列预测评估。
另外选择了八种时间序列预测方法作为基线。
3.2 实验结果
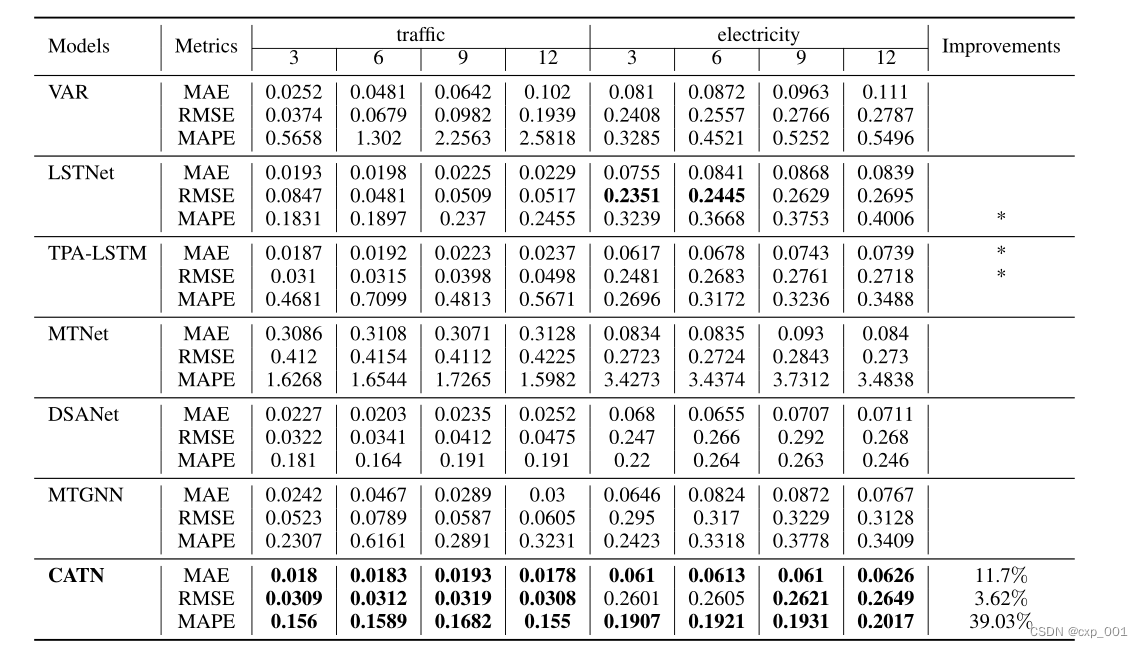
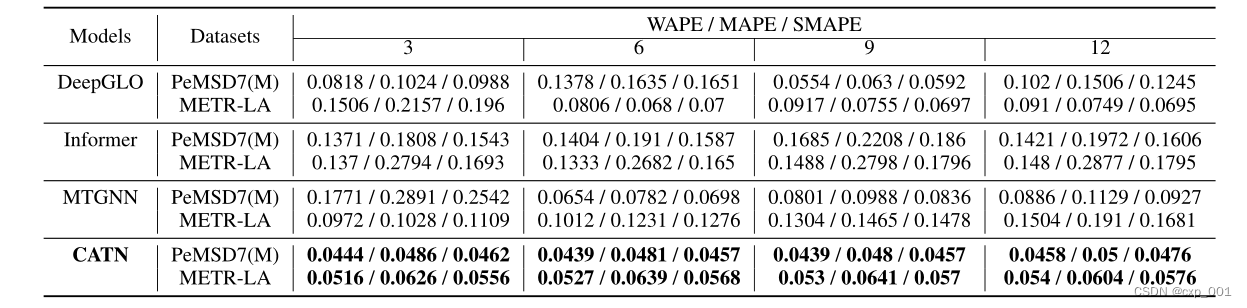
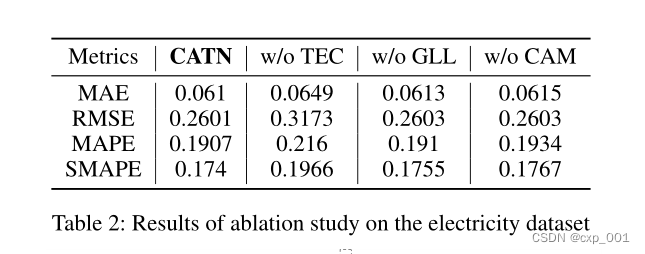
3.3消融实验
本文研究了多变量时间序列数据的分层和分组相关挖掘问题,提出了基于CATN的多步预测方法。是第一个通过基于树的深度学习方法来学习序列间分层和分组相关性的工作,设计了一种多层次学习机制来捕捉序列内数据的长、短和跨时间模式。















 1777
1777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











