







创建简单的长短期记忆 (LSTM) 分类网络。
目录
写在前面
- 示例背景:此示例使用 [1] 和 [2] 中所述的日语元音数据集。此示例训练一个 LSTM 网络,旨在根据表示连续说出的两个日语元音的时序数据来识别说话者。训练数据包含九个说话者的时序数据。每个序列有 12 个特征,且长度不同。该数据集包含 270 个训练观测值和 370 个测试观测值。
- 本文初衷在于帮助初学者创建LSTM网络,网络上很多介绍停留理论层面,反复地说LSTM网络的特点而忽略matlab创建的实际过程,或者以收费的形式贩卖mathwork里的实例,对学生党不友好。
- LSTM网络简介:LSTM 网络常用于对序列数据进行分类 。LSTM 网络是一种循环神经网络 (RNN),可学习序列数据的时间步之间的长期依存关系。
- 输入输出模式:LSTM网络按输入输出模式可分sequence to sequence网络与sequence to last(label)网络,前者多输入多输出,后者多输入单输出,本实例为sequence to last输入输出模式,例子来源mathwork。
- 输入输出详细情况:该实例输入类型为cell型,每个元胞内为12*X的矩阵,12个特征*X个时间步(每个元胞内X可以不同)。输出类型为catagorical类型,其中是对每一个cell元胞包含内容标注的类别。(sequence to last)
- 小建议:如果你想训练自己的LSTM网络,你首先就要想下自己的输入输出关系是否与LSTM网络相符,这是你起码能得到一个结果的基础;然后就是想想改网络特点是否满足你的要求。
- 重点:对于LSTM网络的两种工作模式,
- 1、输入 特征数*时间步 矩阵,输出对每个时间步的模式分类(sequence to sequence)。 2、输入 特征数*时间步 矩阵,输出对整体(最后一个时间步)的模式分类(sequence to last)。
- 这两种工作模式输入相同输出不同,前者输出为cell类型,每个cell内矩阵大小为:1*X(它对每一个时间步作分类)。后者为categorical类型分类列向量,大小为X*1(它对输入中每个元胞包含序列的整体作分类)
网络上有很多对LSTM网络的实际意义、作用的概述,这篇文章不包括该内容。
该示例演示如何:
-
加载序列数据。
-
构造网络架构。
-
指定训练选项。
-
训练网络。
-
预测新数据的标签并计算分类准确度。
加载数据
加载日语元音数据集。预测变量是包含不同长度序列的元胞数组,特征维度为 12。标签是由标签 1、2、...、9 组成的分类向量。matlab中sequence to last输出目前只能为categorical分类列向量,每一行是一个数字标签,这个数字标签你可以用数字1到9,没有特殊含义只起分类作用。
%matlab自带该数据,直接输入就能得到
[XTrain,YTrain] = japaneseVowelsTrainData;
[XValidation,YValidation] = japaneseVowelsTestData;查看前几个训练序列的大小。序列是具有 12 行(每个特征一行)和不同列数(每个时间步一列)的矩阵。
XTrain(1:5)
ans=5×1 cell array
{12×20 double}
{12×26 double}
{12×22 double}
{12×20 double}
{12×21 double}
定义网络架构
定义网络架构可以通过深度网络设计器(deep learning toolbox),这样你能做到优秀的可视化效果。也可以自己在代码里设置layer参数和training option参数来改变。想快速搭建的直接方法二,不影响最终效果而且快捷。
方法一:
1.打开深度网络设计器。
deepNetworkDesigner在序列到标签上暂停,然后点击打开。这会打开一个适合序列分类问题的预置网络。
深度网络设计器显示该预置网络。

选择 sequenceInputLayer,检查并确认 InputSize 设置为 12,与特征维度匹配。

选择 lstmLayer 并将 NumHiddenUnits 设置为 100。

选择 fullyConnectedLayer,检查并确认 OutputSize 设置为 9,即类的数目。

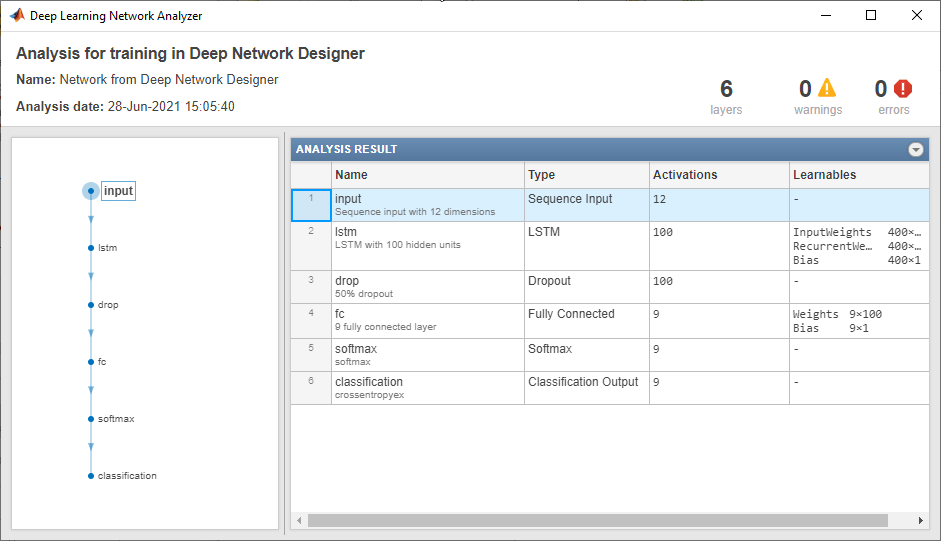
2.检查网络架构
要检查网络并查看层的详细信息,请点击分析。
3.导出网络架构
要将网络架构导出到工作区,请在设计器选项卡上,点击导出。深度网络设计器将网络保存为变量 layers_1。
您还可以通过选择导出 > 生成代码来生成用于构造网络架构的代码。
方法二:
1、手动设置参数
曾经学到这里时,我以为别人代码里的layer与training options参数只能是matlab工具包自动生成的。因为matlab有一个pattern recognition工具包就是直接生成function代码,那个就很难修改。但是这两个参数是可以人工设置的。
% 定义 LSTM 网络架构
% 定义 LSTM 网络架构。将输入指定为大小为 12(输入数据的特征数量)的序列。指定包含 100 个隐含单元的 LSTM 层。
% 最后,在网络中包含一个大小为 9 的全连接层,后跟 softmax 层和分类层,以此来指定九个类。
numFeatures = 12;
numHiddenUnits = 100;
numClasses = 9;
layers_1 = [ ...
sequenceInputLayer(numFeatures)
bilstmLayer(numHiddenUnits,'OutputMode','last')
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer];%指定训练选项。将求解器设置为 'adam'。要防止梯度爆炸,请将梯度阈值设置为 2。
maxEpochs = 100;
miniBatchSize = 27;
%% 指定训练选项
options = trainingOptions('adam', ...
'ExecutionEnvironment','cpu', ...
'GradientThreshold',2, ...
'MaxEpochs',maxEpochs, ...
'MiniBatchSize',miniBatchSize, ...
'SequenceLength','longest', ...
'Shuffle','never', ...
'Verbose',0, ...
'Plots','training-progress');训练网络
net = trainNetwork(XTrain,YTrain,layers_1,options);
测试网络
对测试数据进行分类,并计算分类准确度。指定与训练相同的小批量大小。
YPred = classify(net,XValidation,'MiniBatchSize',miniBatchSize);
acc = mean(YPred == YValidation)acc = 0.9405
源代码
clear
clc
close all
%% 加载序列数据
% 加载日语元音训练数据。XTrain 是包含 270 个不同长度的 12 维序列的元胞数组。
% Y 是对应于九个说话者的标签 "1"、"2"、...、"9" 的分类向量。
% XTrain 中的条目是具有 12 行(每个特征一行)和不同列数(每个时间步一列)的矩阵。
[XTrain,YTrain] = japaneseVowelsTrainData;
XTrain(1:5)
%% 在绘图中可视化第一个时序。每行对应一个特征。
figure
plot(XTrain{1}')
xlabel("Time Step")
title("Training Observation 1")
legend("Feature " + string(1:12),'Location','northeastoutside')
%% 准备要填充的数据
numObservations = numel(XTrain);
for i=1:numObservations
sequence = XTrain{i};
sequenceLengths(i) = size(sequence,2);
end
%% 按序列长度对数据进行排序。
[sequenceLengths,idx] = sort(sequenceLengths);
XTrain = XTrain(idx);
YTrain = YTrain(idx);
%% 在条形图中查看排序的序列长度。
figure
bar(sequenceLengths)
ylim([0 30])
xlabel("Sequence")
ylabel("Length")
title("Sorted Data")
miniBatchSize = 27;
%% 定义 LSTM 网络架构
numFeatures = 12;
numHiddenUnits = 100;
numClasses = 9;
layers = [ ...
sequenceInputLayer(numFeatures)
bilstmLayer(numHiddenUnits,'OutputMode','last')
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer]
maxEpochs = 100;
miniBatchSize = 27;
%% 指定训练选项
options = trainingOptions('adam', ...
'ExecutionEnvironment','cpu', ...
'GradientThreshold',1, ...
'MaxEpochs',maxEpochs, ...
'MiniBatchSize',miniBatchSize, ...
'SequenceLength','longest', ...
'Shuffle','never', ...
'Verbose',0, ...
'Plots','training-progress');
%% 训练 LSTM 网络
net = trainNetwork(XTrain,YTrain,layers,options);
%% 测试 LSTM 网络
[XTest,YTest] = japaneseVowelsTestData;
XTest(1:3)
%% LSTM 网络 net 已使用相似长度的小批量序列进行训练
numObservationsTest = numel(XTest);
for i=1:numObservationsTest
sequence = XTest{i};
sequenceLengthsTest(i) = size(sequence,2);
end
[sequenceLengthsTest,idx] = sort(sequenceLengthsTest);
XTest = XTest(idx);
YTest = YTest(idx);
%% 对测试数据进行分类
miniBatchSize = 27;
YPred = classify(net,XTest, ...
'MiniBatchSize',miniBatchSize, ...
'SequenceLength','longest');
%% 计算预测值的分类准确度。
acc = sum(YPred == YTest)./numel(YTest)参考资料
[1] Kudo, Mineichi, Jun Toyama, and Masaru Shimbo.“Multidimensional Curve Classification Using Passing-through Regions.”Pattern Recognition Letters 20, no. 11–13 (November 1999):1103–11. https://doi.org/10.1016/S0167-8655(99)00077-X.
[2] Kudo, Mineichi, Jun Toyama, and Masaru Shimbo.Japanese Vowels Data Set.Distributed by UCI Machine Learning Repository.
[3] Mathwork:Sequence Classification Using Deep Learning















 3183
3183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









