







目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(ground-truth bounding box)。
不同的模型使用的区域采样方法可能不同。 这里我们介绍其中的一种方法:以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框。 这些边界框被称为锚框(anchor box)。
首先,让我们修改输出精度,以获得更简洁的输出。
%matplotlib inline
import torch
from d2l import torch as d2l
torch.set_printoptions(2) # 精简输出精度
1. 生成多个锚框
ps:锚框的宽度和高度分别是ws根号r和hs/根号r,下面图片有错误。

r是指锚框的宽高比与图像的宽高比之比即w’/h’ = w/h*r,s是图像尺寸缩放因子即w’h’=whs^2,联立求解即可得文中的锚框宽高即w’=ws×sqrt( r ),h’=hs/sqrt( r )。
上述生成锚框的方法在下面的multibox_prior函数中实现。 我们指定输入图像、尺寸列表和宽高比列表,然后此函数将返回所有的锚框。
#@save
def multibox_prior(data, sizes, ratios):
"""生成以每个像素为中心具有不同形状的锚框"""
in_height, in_width = data.shape[-2:] # 从倒数第二维道最后一维,也就是这里的高和宽
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# 为了将锚点移动到像素的中心,需要设置偏移量。
# 因为一个像素的高为1且宽为1,我们选择偏移我们的中心0.5
offset_h, offset_w = 0.5, 0.5
steps_h = 1.0 / in_height # 在y轴上缩放步长
steps_w = 1.0 / in_width # 在x轴上缩放步长
# 生成锚框的所有中心点
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w, indexing='ij')
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# 生成“boxes_per_pixel”个高和宽,
# 之后用于创建锚框的四角坐标(xmin,xmax,ymin,ymax)
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # 处理矩形输入
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# 除以2来获得半高和半宽
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(
in_height * in_width, 1) / 2
# 每个中心点都将有“boxes_per_pixel”个锚框,
# 所以生成含所有锚框中心的网格,重复了“boxes_per_pixel”次
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output.unsqueeze(0)
可以看到返回的锚框变量Y的形状是(批量大小,锚框的数量,4),4表明:每个锚框的位置用4个数字来表示。
img = d2l.plt.imread('drive/MyDrive/chapter13/img/catdog.jpg')
h, w = img.shape[:2]
print(h, w)
X = torch.rand(size=(1, 3, h, w)) # 批量大小为1,通道为3
# size[0]=0.75表示的是生成的锚框是图片的75%的大小
Y = multibox_prior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
Y.shape
运行结果:

将锚框变量Y的形状更改为(图像高度,图像宽度,以同一像素为中心的锚框的数量,4)后,我们可以获得以指定像素的位置为中心的所有锚框。 在接下来的内容中,我们访问以(250,250)为中心的第一个锚框。 它有四个元素:锚框左上角的 (𝑥,𝑦) 轴坐标和右下角的 (𝑥,𝑦) 轴坐标。 输出中两个轴的坐标各分别除以了图像的宽度和高度。
boxes = Y.reshape(h, w, 5, 4)
boxes[250, 250, 0, :]
运行结果如下,因为除以了高宽,所以变成了0-1之间的实数:

为了显示以图像中以某个像素为中心的所有锚框,定义下面的show_bboxes函数来在图像上绘制多个边界框。
def show_bboxes(axes, bboxes, labels=None, colors=None):
"""显示所有边界框"""
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.detach().numpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i],
va='center', ha='center', fontsize=9, color=text_color,
bbox=dict(facecolor=color, lw=0))
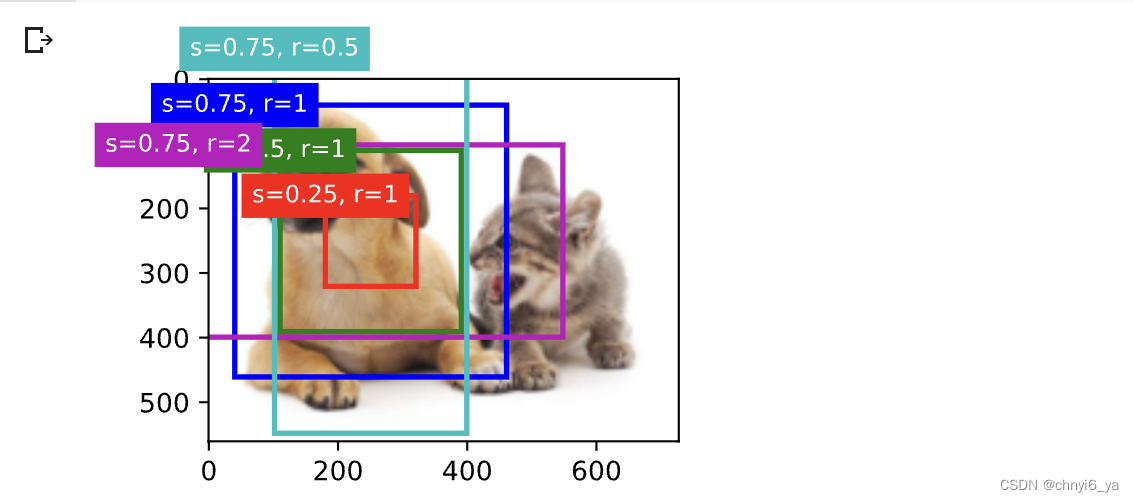
正如从上面代码中所看到的,变量boxes中 𝑥 轴和 𝑦 轴的坐标值已分别除以图像的宽度和高度。 绘制锚框时,我们需要恢复它们原始的坐标值。 因此,在下面定义了变量bbox_scale。 现在可以绘制出图像中所有以(250,250)为中心的锚框了。 如下所示,缩放比为0.75且宽高比为1的蓝色锚框很好地围绕着图像中的狗。
d2l.set_figsize()
bbox_scale = torch.tensor((w, h, w, h))
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, boxes[250, 250, :, :] * bbox_scale,
['s=0.75, r=1', 's=0.5, r=1', 's=0.25, r=1', 's=0.75, r=2',
's=0.75, r=0.5']) # 生成了5个锚框
运行结果如下:
2. 交并比(IoU)
接下来部分将使用交并比来衡量锚框和真实边界框之间、以及不同锚框之间的相似度。 给定两个锚框或边界框的列表,以下box_iou函数将在这两个列表中计算它们成对的交并比。
def box_iou(boxes1, boxes2):
"""计算两个锚框或边界框列表中成对的交并比"""
box_area = lambda boxes: ((boxes[:, 2] - boxes[:, 0]) *
(boxes[:, 3] - boxes[:, 1]))
# boxes1,boxes2,areas1,areas2的形状:
# boxes1:(boxes1的数量,4),
# boxes2:(boxes2的数量,4),
# areas1:(boxes1的数量,),
# areas2:(boxes2的数量,)
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
# inter_upperlefts,inter_lowerrights,inters的形状:
# (boxes1的数量,boxes2的数量,2)
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# inter_areasandunion_areas的形状:(boxes1的数量,boxes2的数量)
inter_areas = inters[:, :, 0] * inters[:, :, 1]
union_areas = areas1[:, None] + areas2 - inter_areas
return inter_areas / union_areas
3. 在训练数据中标注锚框
将真实边界框分配给锚框,此算法在下面的assign_anchor_to_bbox函数中实现。
def assign_anchor_to_bbox(ground_truth, anchors, device, iou_threshold=0.5):
"""将最接近的真实边界框分配给锚框"""
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
# 位于第i行和第j列的元素x_ij是锚框i和真实边界框j的IoU
jaccard = box_iou(anchors, ground_truth)
# 对于每个锚框,分配的真实边界框的张量
anchors_bbox_map = torch.full((num_anchors,), -1, dtype=torch.long,
device=device)
# 根据阈值,决定是否分配真实边界框
max_ious, indices = torch.max(jaccard, dim=1)
anc_i = torch.nonzero(max_ious >= iou_threshold).reshape(-1)
box_j = indices[max_ious >= iou_threshold]
anchors_bbox_map[anc_i] = box_j
col_discard = torch.full((num_anchors,), -1)
row_discard = torch.full((num_gt_boxes,), -1)
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard)
box_idx = (max_idx % num_gt_boxes).long()
anc_idx = (max_idx / num_gt_boxes).long()
anchors_bbox_map[anc_idx] = box_idx
jaccard[:, box_idx] = col_discard
jaccard[anc_idx, :] = row_discard
return anchors_bbox_map
4. 标记类别和偏移量
现在我们可以为每个锚框标记类别和偏移量了。
假设一个锚框 𝐴 被分配了一个真实边界框 𝐵 。 一方面,锚框 𝐴 的类别将被标记为与 𝐵 相同。 另一方面,锚框 𝐴 的偏移量将根据 𝐵 和 𝐴 中心坐标的相对位置以及这两个框的相对大小进行标记。 鉴于数据集内不同的框的位置和大小不同,我们可以对那些相对位置和大小应用变换,使其获得分布更均匀且易于拟合的偏移量。 这里介绍一种常见的变换。
给定框 𝐴 和 𝐵 ,中心坐标分别为 (𝑥𝑎,𝑦𝑎) 和 (𝑥𝑏,𝑦𝑏) ,宽度分别为 𝑤𝑎 和 𝑤𝑏 ,高度分别为 ℎ𝑎 和 ℎ𝑏 ,可以将 𝐴 的偏移量标记为:
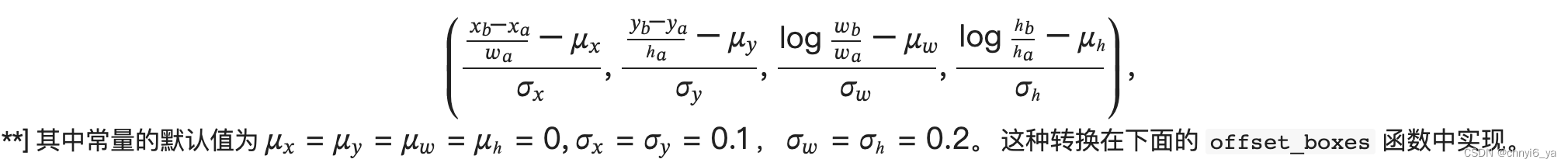
def offset_boxes(anchors, assigned_bb, eps=1e-6):
"""对锚框偏移量的转换"""
c_anc = d2l.box_corner_to_center(anchors)
c_assigned_bb = d2l.box_corner_to_center(assigned_bb)
offset_xy = 10 * (c_assigned_bb[:, :2] - c_anc[:, :2]) / c_anc[:, 2:]
offset_wh = 5 * torch.log(eps + c_assigned_bb[:, 2:] / c_anc[:, 2:])
offset = torch.cat([offset_xy, offset_wh], axis=1)
return offset
如果一个锚框没有被分配真实边界框,我们只需将锚框的类别标记为背景(background)。 背景类别的锚框通常被称为负类锚框,其余的被称为正类锚框。 我们使用真实边界框(labels参数)实现以下multibox_target函数,来标记锚框的类别和偏移量(anchors参数)。 此函数将背景类别的索引设置为零,然后将新类别的整数索引递增一。
def multibox_target(anchors, labels):
"""使用真实边界框标记锚框"""
batch_size, anchors = labels.shape[0], anchors.squeeze(0)
batch_offset, batch_mask, batch_class_labels = [], [], []
device, num_anchors = anchors.device, anchors.shape[0]
for i in range(batch_size):
label = labels[i, :, :]
anchors_bbox_map = assign_anchor_to_bbox(
label[:, 1:], anchors, device)
bbox_mask = ((anchors_bbox_map >= 0).float().unsqueeze(-1)).repeat(
1, 4)
# 将类标签和分配的边界框坐标初始化为零
class_labels = torch.zeros(num_anchors, dtype=torch.long,
device=device)
assigned_bb = torch.zeros((num_anchors, 4), dtype=torch.float32,
device=device)
# 使用真实边界框来标记锚框的类别。
# 如果一个锚框没有被分配,标记其为背景(值为零)
indices_true = torch.nonzero(anchors_bbox_map >= 0)
bb_idx = anchors_bbox_map[indices_true]
class_labels[indices_true] = label[bb_idx, 0].long() + 1
assigned_bb[indices_true] = label[bb_idx, 1:]
# 偏移量转换
offset = offset_boxes(anchors, assigned_bb) * bbox_mask
batch_offset.append(offset.reshape(-1))
batch_mask.append(bbox_mask.reshape(-1))
batch_class_labels.append(class_labels)
bbox_offset = torch.stack(batch_offset)
bbox_mask = torch.stack(batch_mask)
class_labels = torch.stack(batch_class_labels)
return (bbox_offset, bbox_mask, class_labels)
5. 一个例子
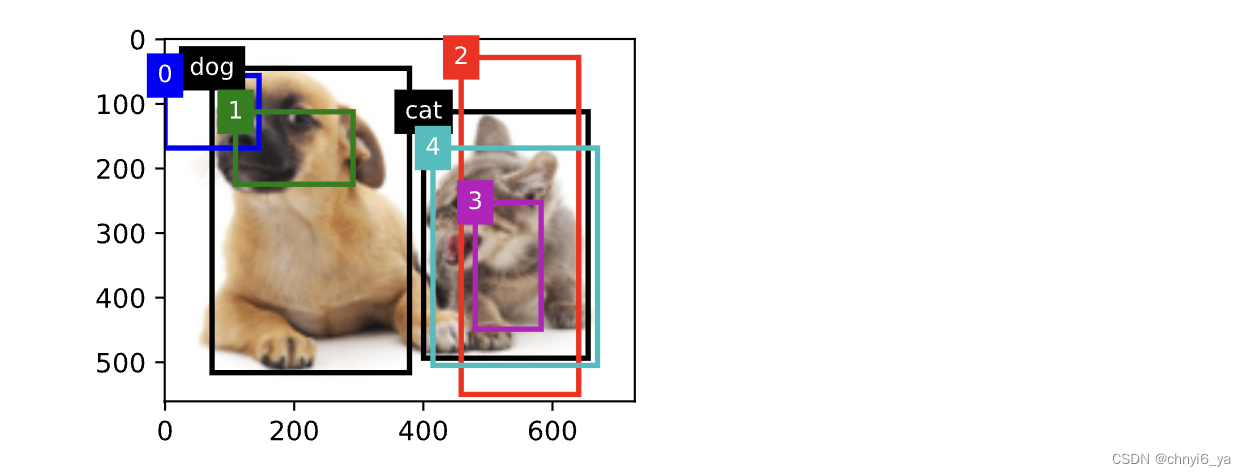
下面通过一个具体的例子来说明锚框标签。 我们已经为加载图像中的狗和猫定义了真实边界框,其中第一个元素是类别(0代表狗,1代表猫),其余四个元素是左上角和右下角的 (𝑥,𝑦) 轴坐标(范围介于0和1之间)。 我们还构建了五个锚框,用左上角和右下角的坐标进行标记: 𝐴0,…,𝐴4 (索引从0开始)。 然后我们在图像中绘制这些真实边界框和锚框。
ground_truth = torch.tensor([[0, 0.1, 0.08, 0.52, 0.92],
[1, 0.55, 0.2, 0.9, 0.88]])
anchors = torch.tensor([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],
[0.57, 0.3, 0.92, 0.9]])
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, ground_truth[:, 1:] * bbox_scale, ['dog', 'cat'], 'k')
show_bboxes(fig.axes, anchors * bbox_scale, ['0', '1', '2', '3', '4']);
运行结果:
使用上面定义的multibox_target函数,我们可以根据狗和猫的真实边界框,标注这些锚框的分类和偏移量。 在这个例子中,背景、狗和猫的类索引分别为0、1和2。 下面我们为锚框和真实边界框样本添加一个维度。
labels = multibox_target(anchors.unsqueeze(dim=0),
ground_truth.unsqueeze(dim=0))
返回的结果中有三个元素,都是张量格式。第三个元素包含标记的输入锚框的类别。
让我们根据图像中的锚框和真实边界框的位置来分析下面返回的类别标签。 首先,在所有的锚框和真实边界框配对中,锚框 𝐴4 与猫的真实边界框的IoU是最大的。 因此, 𝐴4 的类别被标记为猫。 去除包含 𝐴4 或猫的真实边界框的配对,在剩下的配对中,锚框 𝐴1 和狗的真实边界框有最大的IoU。 因此, 𝐴1 的类别被标记为狗。 接下来,我们需要遍历剩下的三个未标记的锚框: 𝐴0 、 𝐴2 和 𝐴3 。 对于 𝐴0 ,与其拥有最大IoU的真实边界框的类别是狗,但IoU低于预定义的阈值(0.5),因此该类别被标记为背景; 对于 𝐴2 ,与其拥有最大IoU的真实边界框的类别是猫,IoU超过阈值,所以类别被标记为猫; 对于 𝐴3 ,与其拥有最大IoU的真实边界框的类别是猫,但值低于阈值,因此该类别被标记为背景。
labels[2]
运行结果:

返回的第二个元素是掩码(mask)变量,形状为(批量大小,锚框数的四倍)。 掩码变量中的元素与每个锚框的4个偏移量一一对应。 由于我们不关心对背景的检测,负类的偏移量不应影响目标函数。 通过元素乘法,掩码变量中的零将在计算目标函数之前过滤掉负类偏移量。
labels[1]
运行结果:

labels[0]
运行结果:

6. 使用非极大值抑制预测边界框
在预测时,我们先为图像生成多个锚框,再为这些锚框一一预测类别和偏移量。 一个预测好的边界框则根据其中某个带有预测偏移量的锚框而生成。 下面我们实现了offset_inverse函数,该函数将锚框和偏移量预测作为输入,并应用逆偏移变换来返回预测的边界框坐标。
def offset_inverse(anchors, offset_preds):
"""根据带有预测偏移量的锚框来预测边界框"""
anc = d2l.box_corner_to_center(anchors)
pred_bbox_xy = (offset_preds[:, :2] * anc[:, 2:] / 10) + anc[:, :2]
pred_bbox_wh = torch.exp(offset_preds[:, 2:] / 5) * anc[:, 2:]
pred_bbox = torch.cat((pred_bbox_xy, pred_bbox_wh), axis=1)
predicted_bbox = d2l.box_center_to_corner(pred_bbox)
return predicted_bbox
当有许多锚框时,可能会输出许多相似的具有明显重叠的预测边界框,都围绕着同一目标。 为了简化输出,我们可以使用非极大值抑制(non-maximum suppression,NMS)合并属于同一目标的类似的预测边界框。
以下是非极大值抑制的工作原理。 对于一个预测边界框 𝐵 ,目标检测模型会计算每个类别的预测概率。 假设最大的预测概率为 𝑝 ,则该概率所对应的类别 𝐵 即为预测的类别。 具体来说,我们将 𝑝 称为预测边界框 𝐵 的置信度(confidence)。 在同一张图像中,所有预测的非背景边界框都按置信度降序排序,以生成列表 𝐿 。然后我们通过以下步骤操作排序列表 𝐿 。
- 从 𝐿 中选取置信度最高的预测边界框 𝐵1 作为基准,然后将所有与 𝐵1 的IoU超过预定阈值 𝜖 的非基准预测边界框从 𝐿 中移除。这时, 𝐿 保留了置信度最高的预测边界框,去除了与其太过相似的其他预测边界框。简而言之,那些具有非极大值置信度的边界框被抑制了。
- 从 𝐿 中选取置信度第二高的预测边界框 𝐵2 作为又一个基准,然后将所有与 𝐵2 的IoU大于 𝜖 的非基准预测边界框从 𝐿 中移除。
- 重复上述过程,直到 𝐿 中的所有预测边界框都曾被用作基准。此时, 𝐿 中任意一对预测边界框的IoU都小于阈值 𝜖 ;因此,没有一对边界框过于相似。
- 输出列表 𝐿 中的所有预测边界框。
以下nms函数按降序对置信度进行排序并返回其索引。
def nms(boxes, scores, iou_threshold):
"""对预测边界框的置信度进行排序"""
B = torch.argsort(scores, dim=-1, descending=True)
keep = [] # 保留预测边界框的指标
while B.numel() > 0:
i = B[0]
keep.append(i)
if B.numel() == 1: break
iou = box_iou(boxes[i, :].reshape(-1, 4),
boxes[B[1:], :].reshape(-1, 4)).reshape(-1)
inds = torch.nonzero(iou <= iou_threshold).reshape(-1)
B = B[inds + 1]
return torch.tensor(keep, device=boxes.device)
我们定义以下multibox_detection函数来将非极大值抑制应用于预测边界框。 这里的实现有点复杂,请不要担心。我们将在实现之后,马上用一个具体的例子来展示它是如何工作的。
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,
pos_threshold=0.009999999):
"""使用非极大值抑制来预测边界框"""
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
out = []
for i in range(batch_size):
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)
conf, class_id = torch.max(cls_prob[1:], 0)
predicted_bb = offset_inverse(anchors, offset_pred)
keep = nms(predicted_bb, conf, nms_threshold)
# 找到所有的non_keep索引,并将类设置为背景
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
combined = torch.cat((keep, all_idx))
uniques, counts = combined.unique(return_counts=True)
non_keep = uniques[counts == 1]
all_id_sorted = torch.cat((keep, non_keep))
class_id[non_keep] = -1
class_id = class_id[all_id_sorted]
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
# pos_threshold是一个用于非背景预测的阈值
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1 - conf[below_min_idx]
pred_info = torch.cat((class_id.unsqueeze(1),
conf.unsqueeze(1),
predicted_bb), dim=1)
out.append(pred_info)
return torch.stack(out)
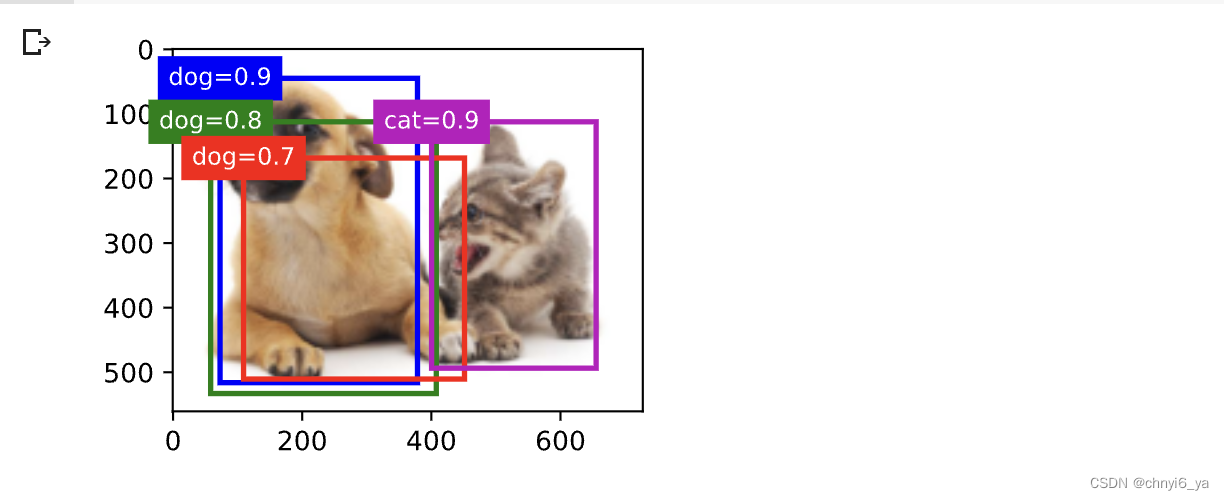
现在让我们将上述算法应用到一个带有四个锚框的具体示例中。 为简单起见,我们假设预测的偏移量都是零,这意味着预测的边界框即是锚框。 对于背景、狗和猫其中的每个类,我们还定义了它的预测概率。
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0] * anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
我们可以在图像上绘制这些预测边界框和置信度。
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, anchors * bbox_scale,
['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9'])
运行结果:
现在我们可以调用multibox_detection函数来执行非极大值抑制,其中阈值设置为0.5。 请注意,我们在示例的张量输入中添加了维度。
我们可以看到返回结果的形状是(批量大小,锚框的数量,6)。最内层维度中的六个元素提供了同一预测边界框的输出信息。 第一个元素是预测的类索引,从0开始(0代表狗,1代表猫),值-1表示背景或在非极大值抑制中被移除了。 第二个元素是预测的边界框的置信度。 其余四个元素分别是预测边界框左上角和右下角的 (𝑥,𝑦) 轴坐标(范围介于0和1之间)。
output = multibox_detection(cls_probs.unsqueeze(dim=0),
offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0),
nms_threshold=0.5)
output
运行结果:

删除-1类别(背景)的预测边界框后,我们可以输出由非极大值抑制保存的最终预测边界框。
fig = d2l.plt.imshow(img)
for i in output[0].detach().numpy():
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)
运行结果:
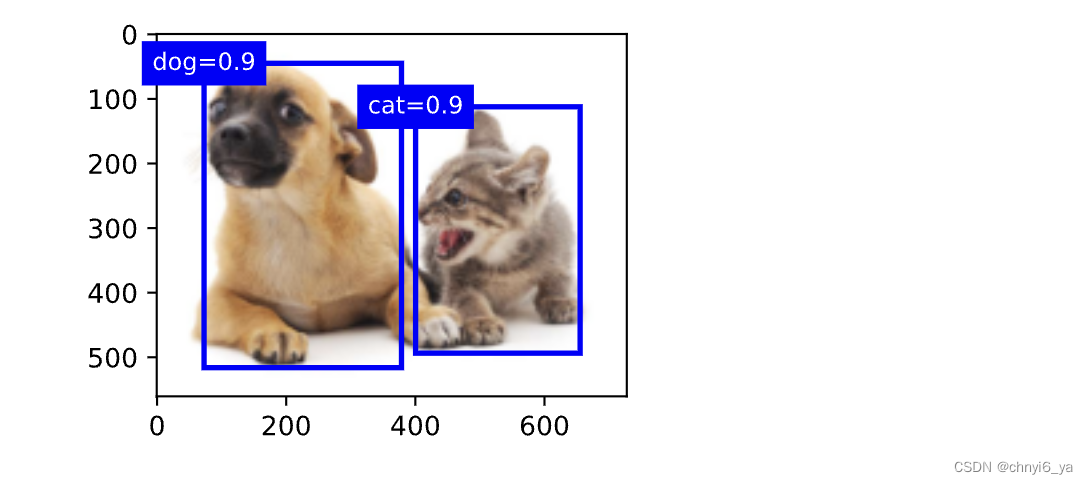
实践中,在执行非极大值抑制前,我们甚至可以将置信度较低的预测边界框移除,从而减少此算法中的计算量。 我们也可以对非极大值抑制的输出结果进行后处理。例如,只保留置信度更高的结果作为最终输出。
7. Q&A
- 真实边缘框从哪里得来的?
答:真实边缘框是从文件中读出来的,那里的真实边缘框是手标出来的。训练的时候有真实边缘框,是因为训练的时候去读数据(数据里面已经有人为标好的真实边缘框)。锚框是算法生成出来的,用来预测真实边缘框。对每个图片去生成一堆锚框,生成锚框的时候不能去看真实边缘框,是因为在做预测的时候,你没有真实边缘框。所以生成锚框去做预测,然后用nms去除相似的,然后在训练的时候,要对每个锚框算标号,也就是去看真实边缘框来给标号。















 1788
1788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









