







1. 自注意力
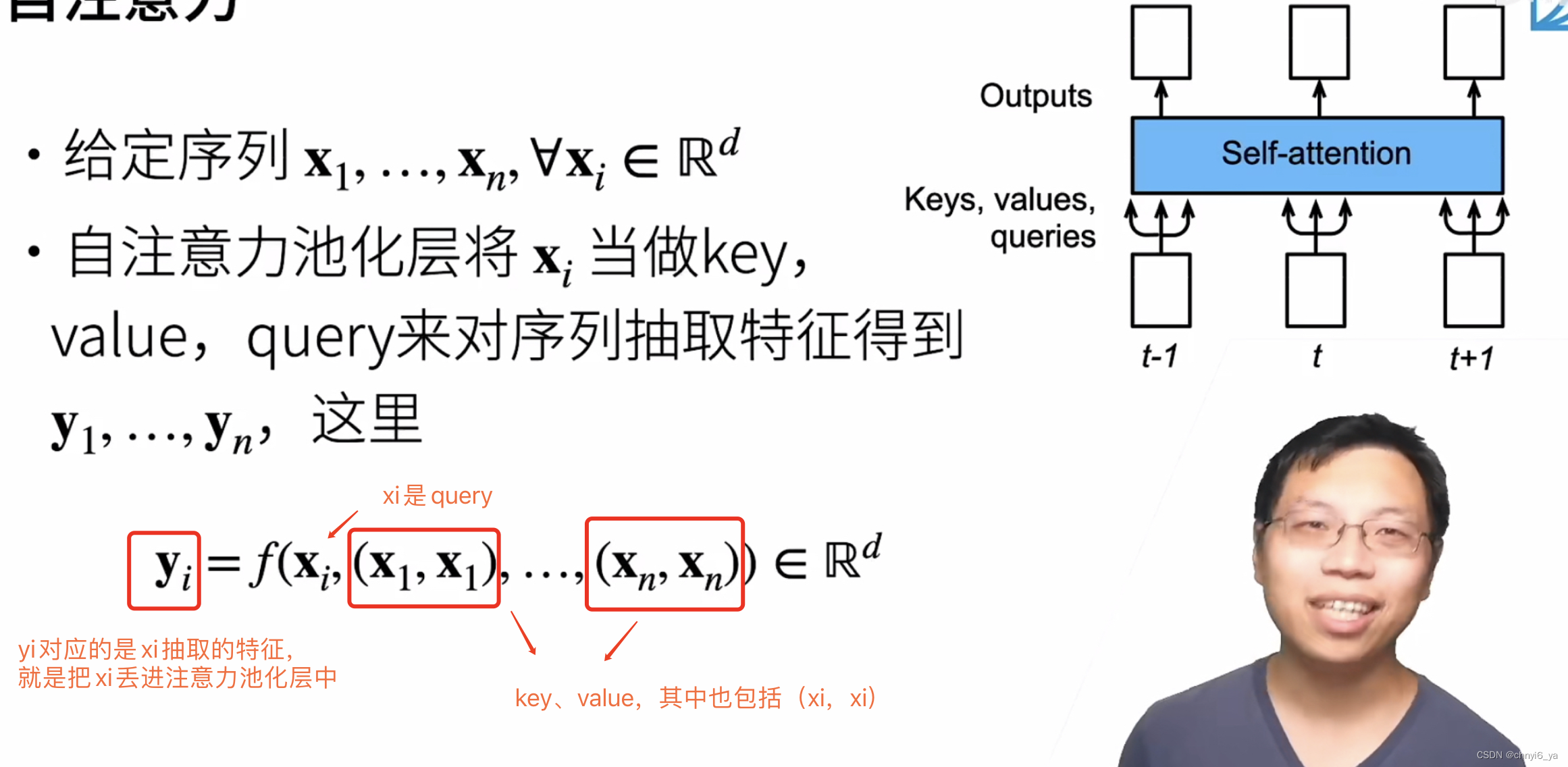
- 一个长为n的序列,每个xi是一个长为d的向量
- key、value都来自于自己
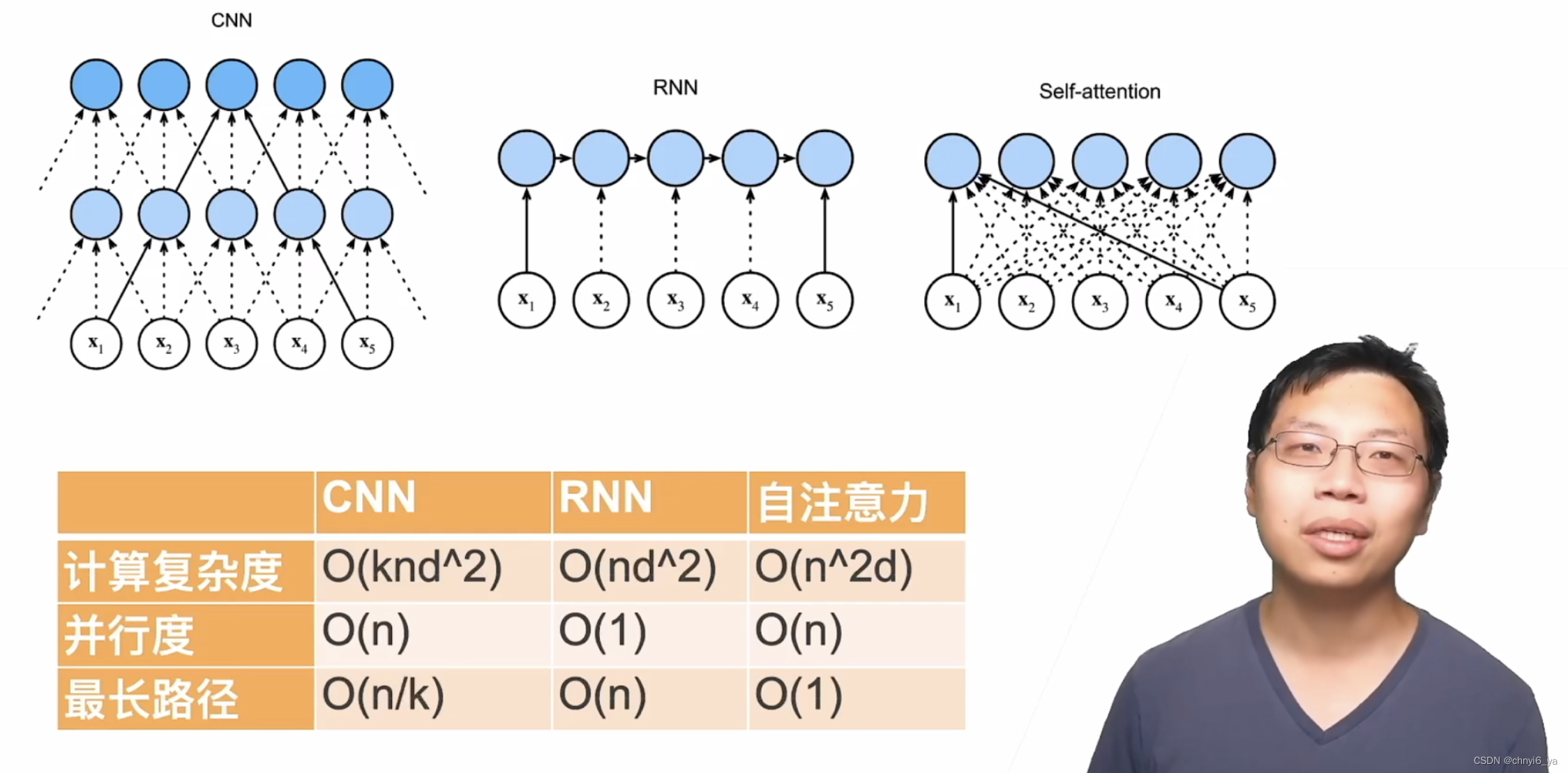
2. 跟CNN、RNN对比
3. 位置编码

4. 位置编码矩阵
5. 绝对信息位置
6. 相对位置信息

7. 总结

8. 代码实现
import math
import torch
from torch import nn
from d2l import torch as d2l
8.1 自注意力
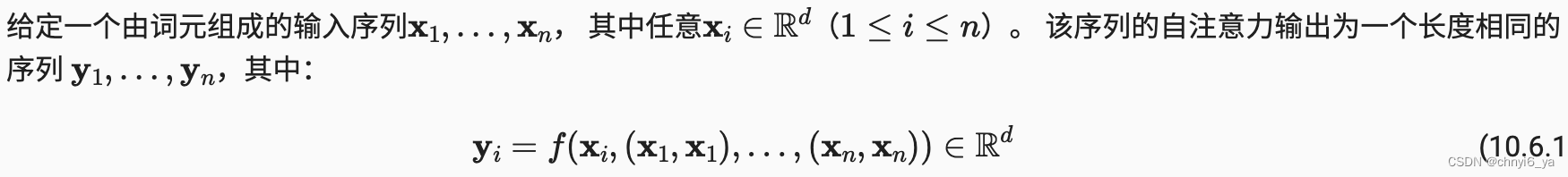
下面的代码片段是基于多头注意力对一个张量完成自注意力的计算, 张量的形状为(批量大小,时间步的数目或词元序列的长度, 𝑑 )。 输出与输入的张量形状相同。
num_hiddens, num_heads = 100, 5
attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
运行结果:

batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
attention(X, X, X, valid_lens).shape
运行结果:

8.2 位置编码

class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P
# max_len就是n,num_hiddens就是d
# 因为p是一个n x d的矩阵
# 不看第0维的batch_size,就可以理解为每一行是一个样本,每一列是样本对应的特征
self.P = torch.zeros((1, max_len, num_hiddens))
# 表示矩阵从0到999行每一行中,第2j列和2j+1列的:i/1000^2j/d,i是行数
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(10000, torch.arange(
0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
def forward(self, X):
# 注意:这里的X是输入单个字符的embedding,和上面的X不一样
X = X + self.P[:, :X.shape[1], :].to(X.device)
# 使用dropout来避免这个模型对P太过于敏感
return self.dropout(X)
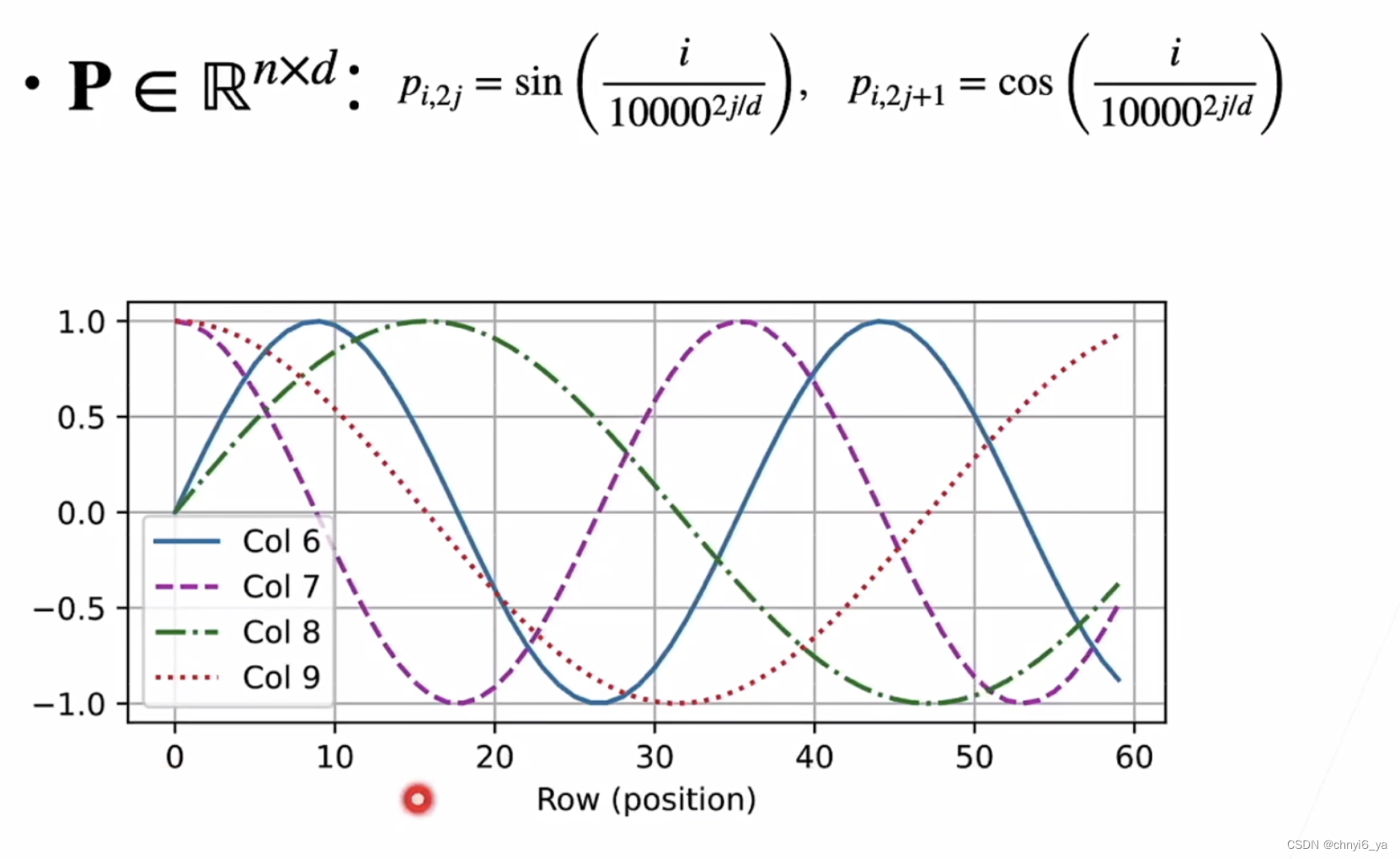
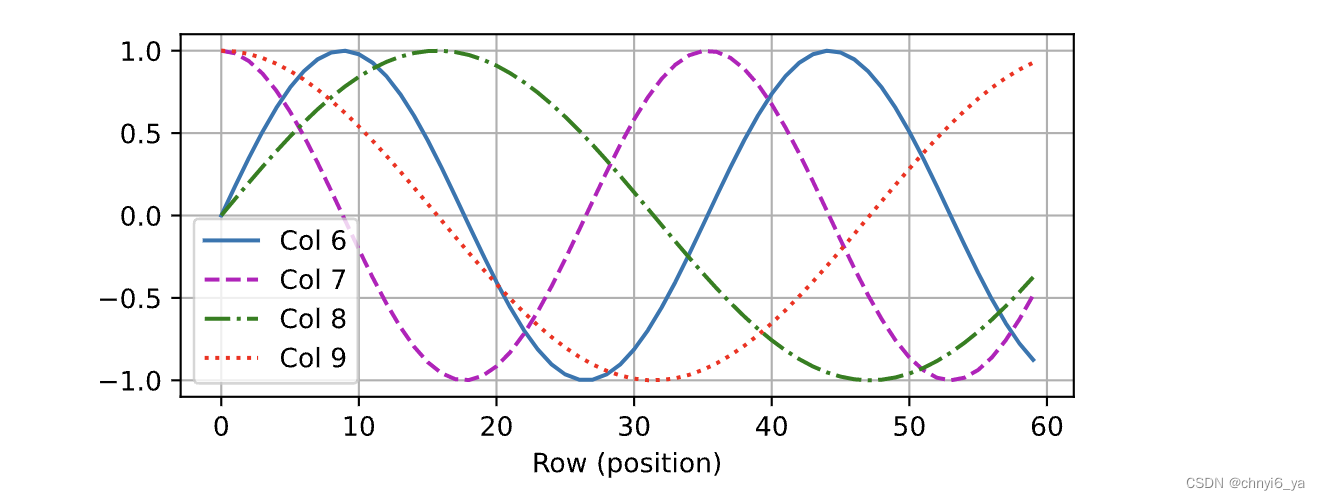
在位置嵌入矩阵 𝐏 中, 行代表词元在序列中的位置,列代表位置编码的不同维度。 从下面的例子中可以看到位置嵌入矩阵的第 6 列和第 7 列的频率高于第 8 列和第 9 列。 第 6 列和第 7 列之间的偏移量(第 8 列和第 9 列相同)是由于正弦函数和余弦函数的交替。
encoding_dim, num_steps = 32, 60
pos_encoding = PositionalEncoding(encoding_dim, 0)
pos_encoding.eval()
X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))
P = pos_encoding.P[:, :X.shape[1], :]
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)',
figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])
运行结果:
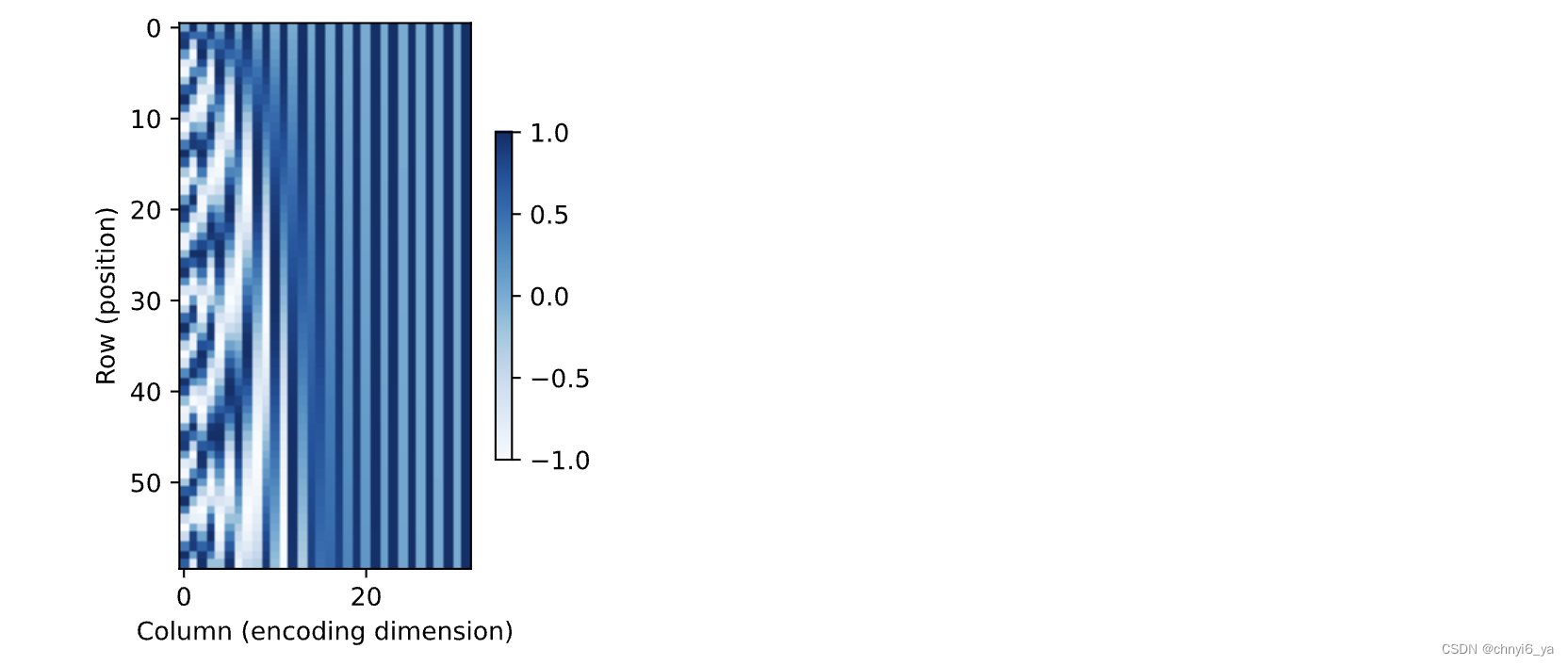
8.3 绝对位置信息
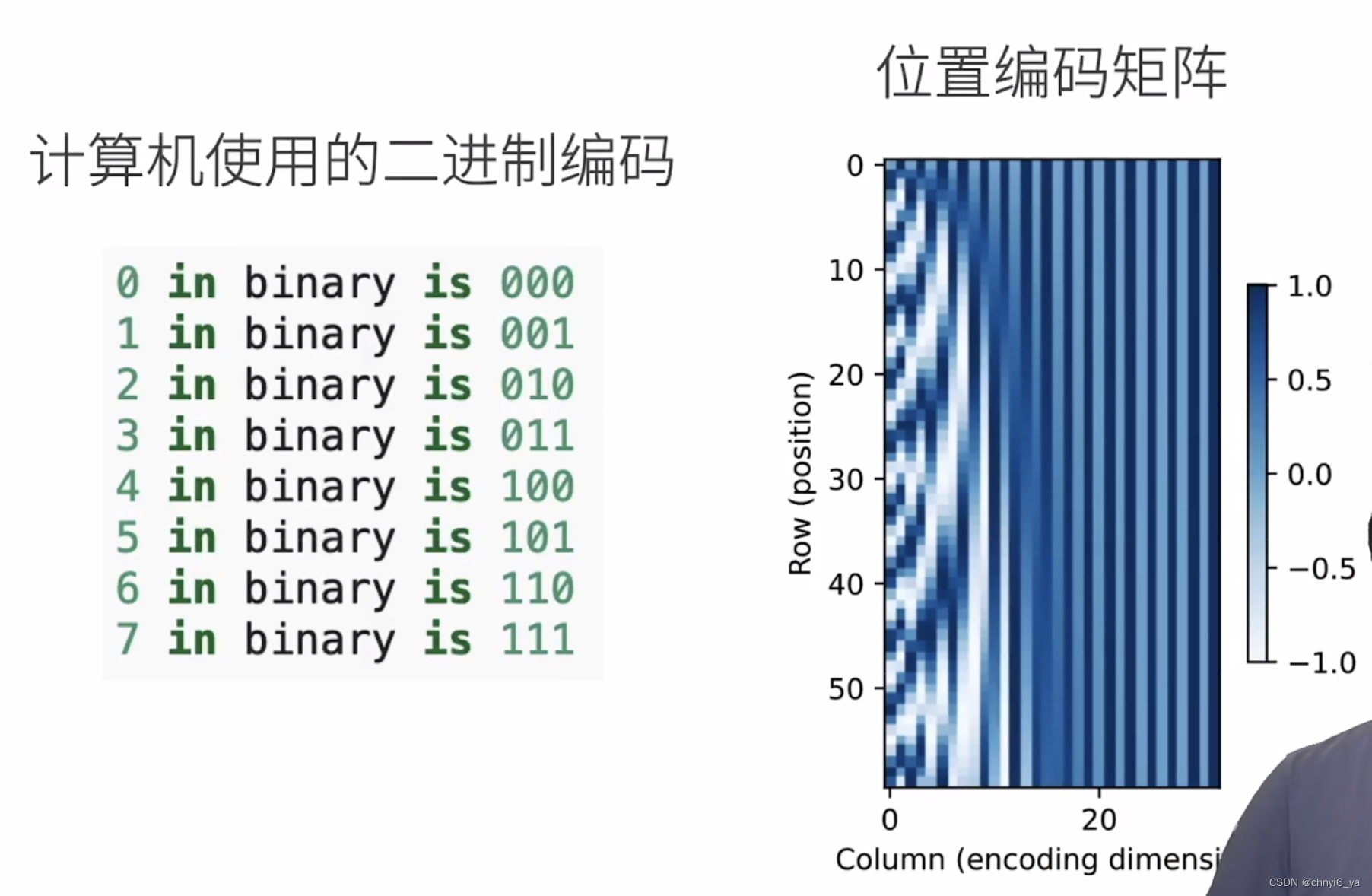
为了明白沿着编码维度单调降低的频率与绝对位置信息的关系, 让我们打印出 0,1,…,7 的二进制表示形式。 正如所看到的,每个数字、每两个数字和每四个数字上的比特值 在第一个最低位、第二个最低位和第三个最低位上分别交替。
for i in range(8):
print(f'{i}的二进制是:{i:>03b}')

在二进制表示中,较高比特位的交替频率低于较低比特位, 与下面的热图所示相似,只是位置编码通过使用三角函数[在编码维度上降低频率]。 由于输出是浮点数,因此此类连续表示比二进制表示法更节省空间。
P = P[0, :, :].unsqueeze(0).unsqueeze(0)
d2l.show_heatmaps(P, xlabel='Column (encoding dimension)',
ylabel='Row (position)', figsize=(3.5, 4), cmap='Blues')
运行结果:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









