





-
技术介绍
Intel Extension for Transformers 使用了多种优化技术来提升深度学习模型的性能。主要包括:- 量化(Quantization):通过减少模型参数的位数来减小模型大小并加速推理过程。提供了包括AWQ,SmoothQuant在内的先进量化技术;
- 混合精度(Mixed Precision):使用不同的数据类型(如bfloat16、int8)来平衡计算速度和精度;
- 与Intel CPU的SIMD指令结合加速推理;
- FP8数据类型:使用8位浮点数来进一步压缩模型;
- 自动量化(AutoQuant):自动化量化过程,以找到最佳的量化策略;
- FlashAttention:一种优化注意力机制的方法,用于加速长序列的处理;
-
实验过程
利用ModelScope提供的免费CPU算力尝试ITREX的性能。步骤如下:- 在ModelScope上注册账号并绑定阿里云账号后,点击左侧创建Notebook,可以选择我们的计算环境;
- 选择CPU环境,启动Notebook后点击查看Notebook,就可以进入工作空间。
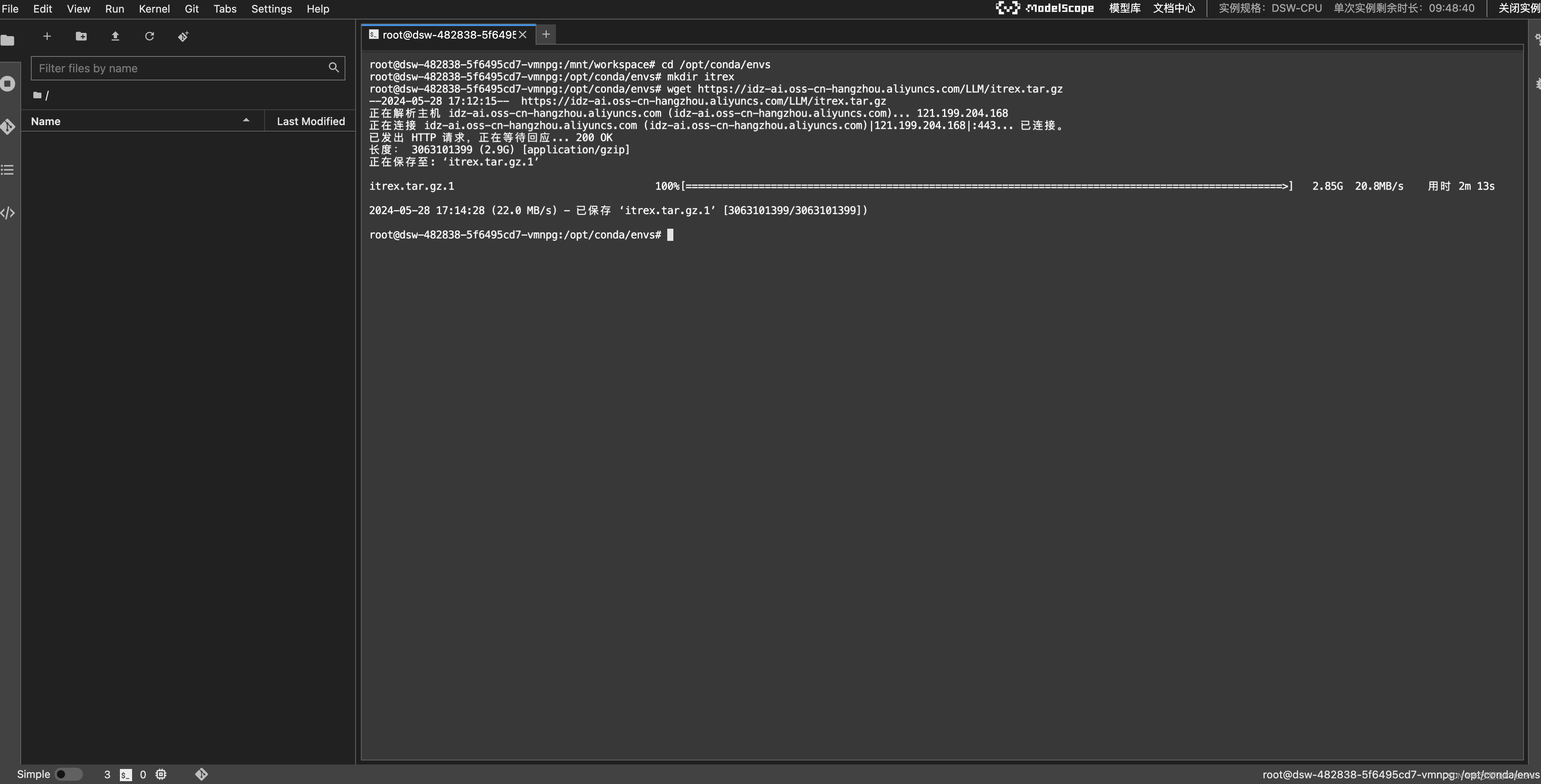
- 启动一个终端,在终端中输入下面的命令来下载ITREX所需的conda环境
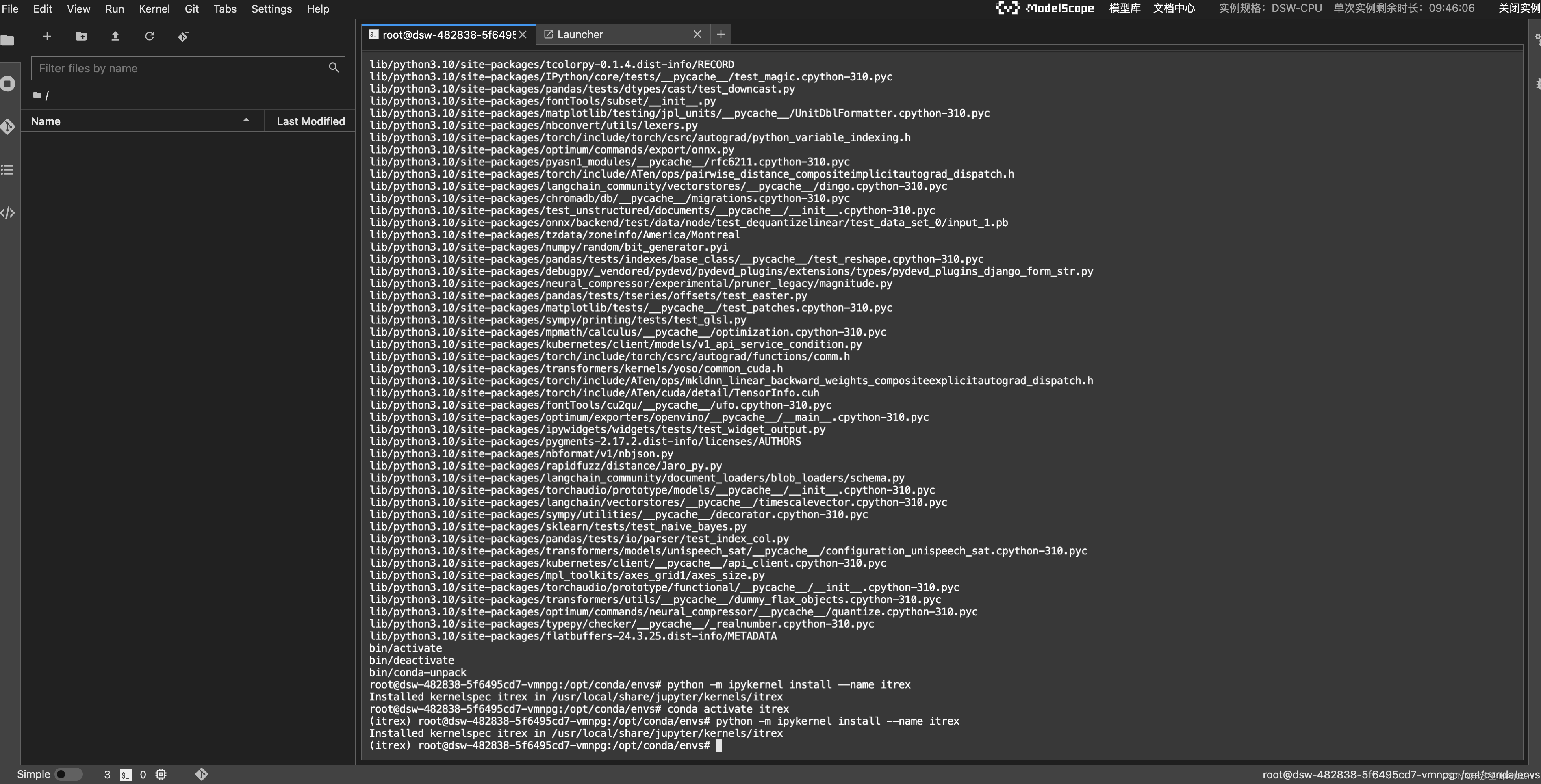
- 再输入下面的命令安装环境和对应的ipykernel。
- 环境准备完毕,下面开始下载模型,我们选择的是zhipuAI的ChatGLM3模型和一个embedding模型
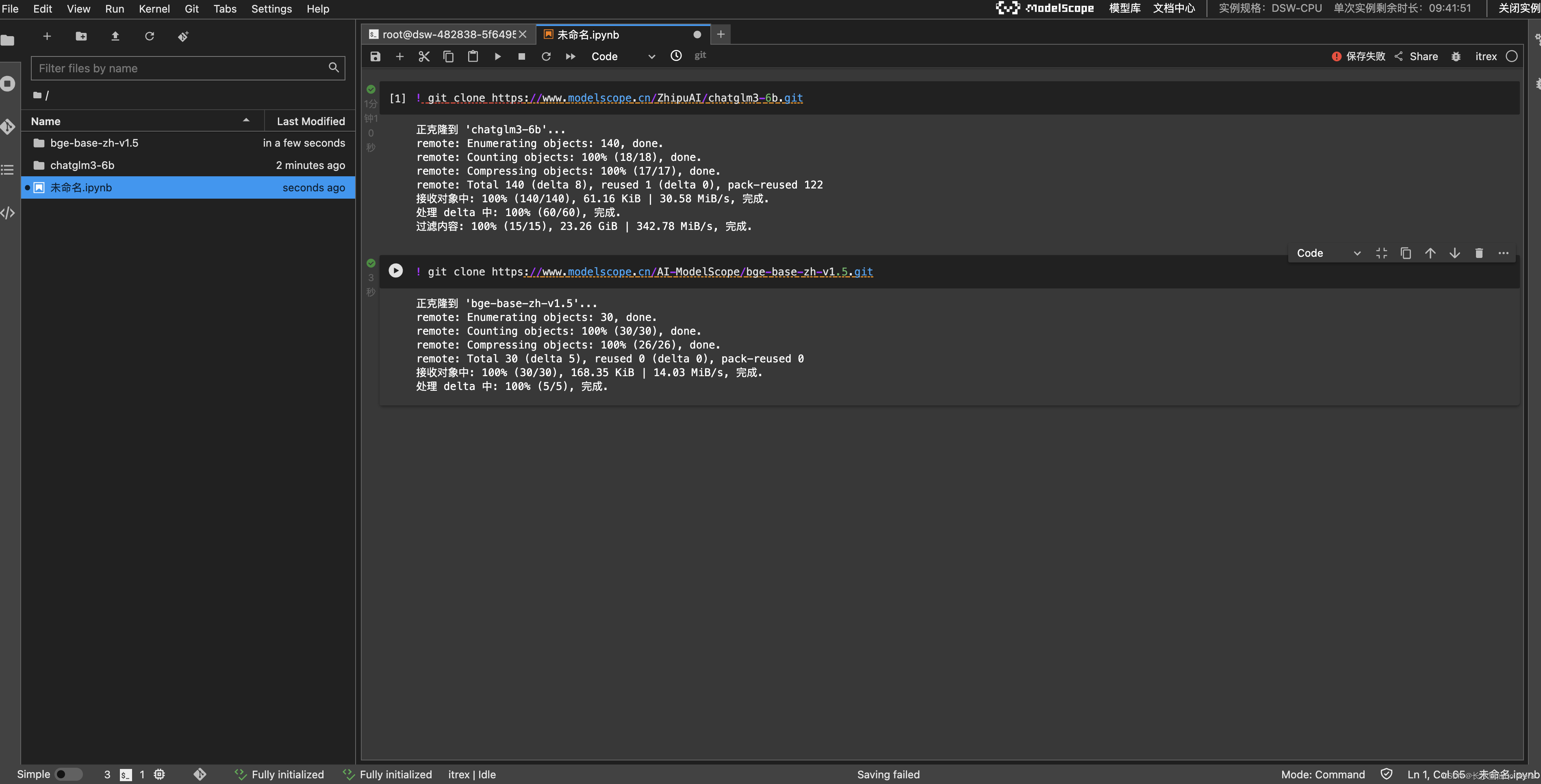
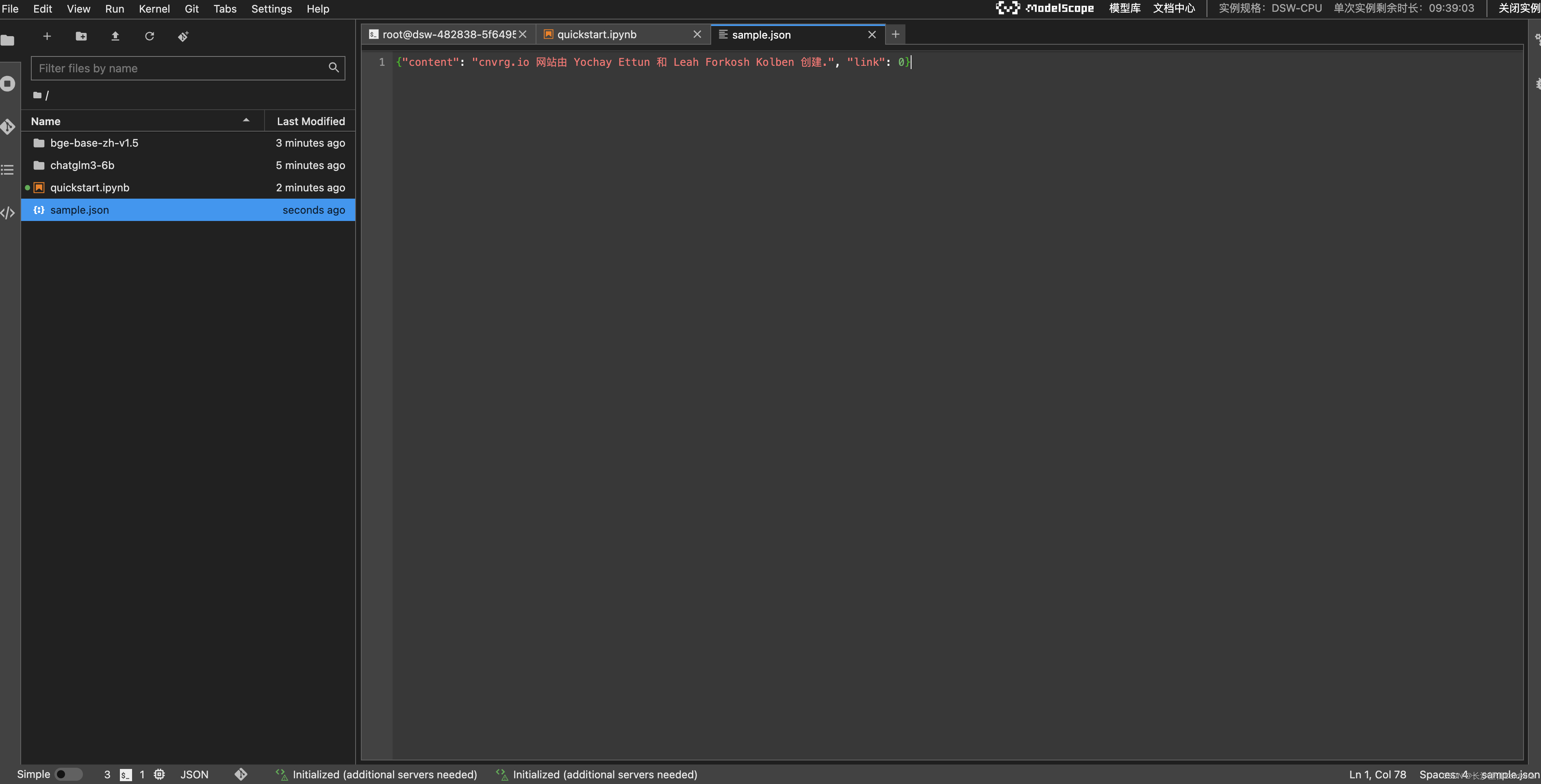
- 这次试验我们计划试一下RAG插件。首先准备一条简短的知识,格式为json,保存为文件sample.json
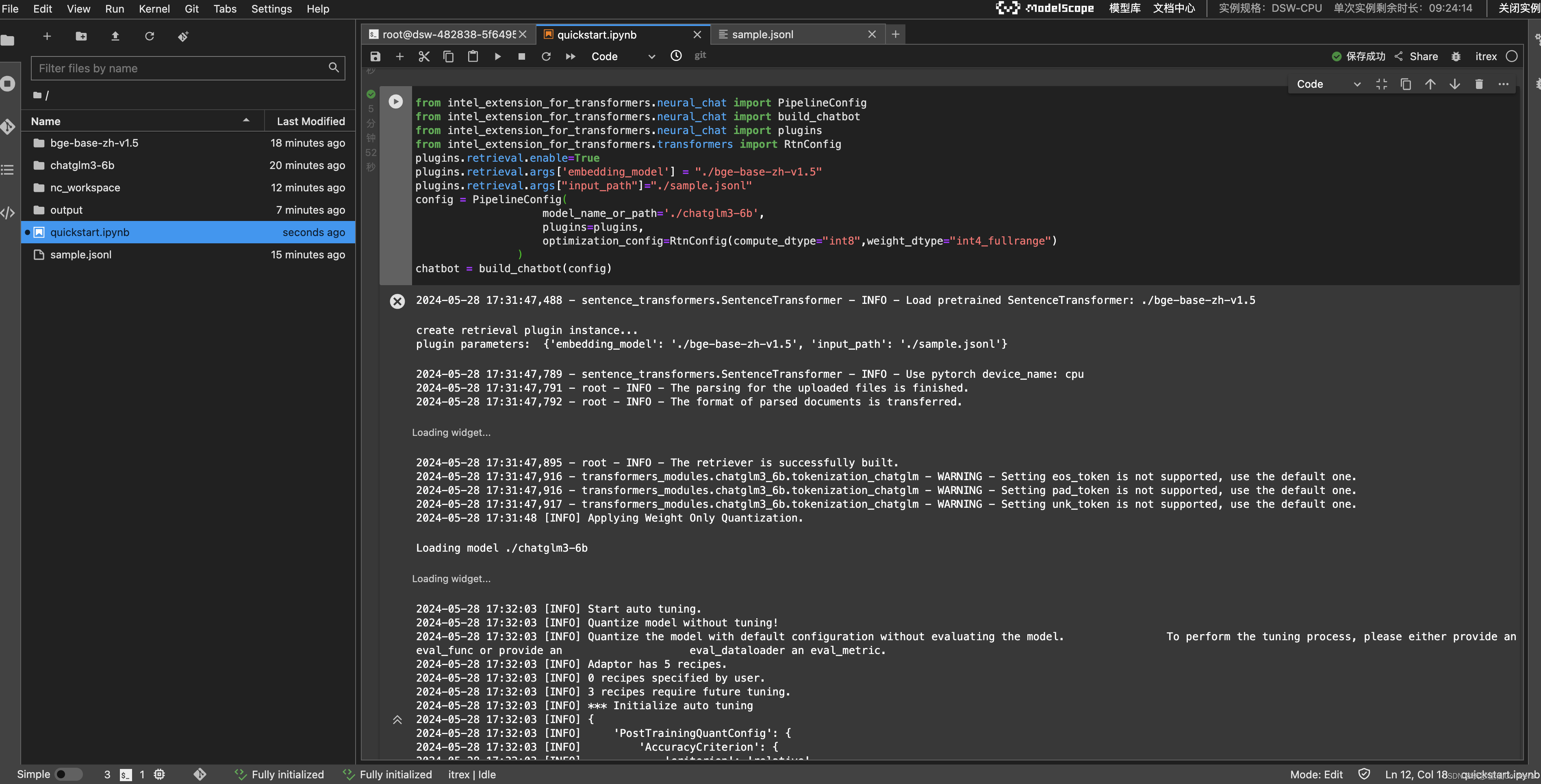
- 执行下面的代码加载模型和插件
- 在ModelScope上注册账号并绑定阿里云账号后,点击左侧创建Notebook,可以选择我们的计算环境;
-
推理结果
可以看到,关闭retrieval插件时模型的回答是错误的,打开后模型输出了正确答案。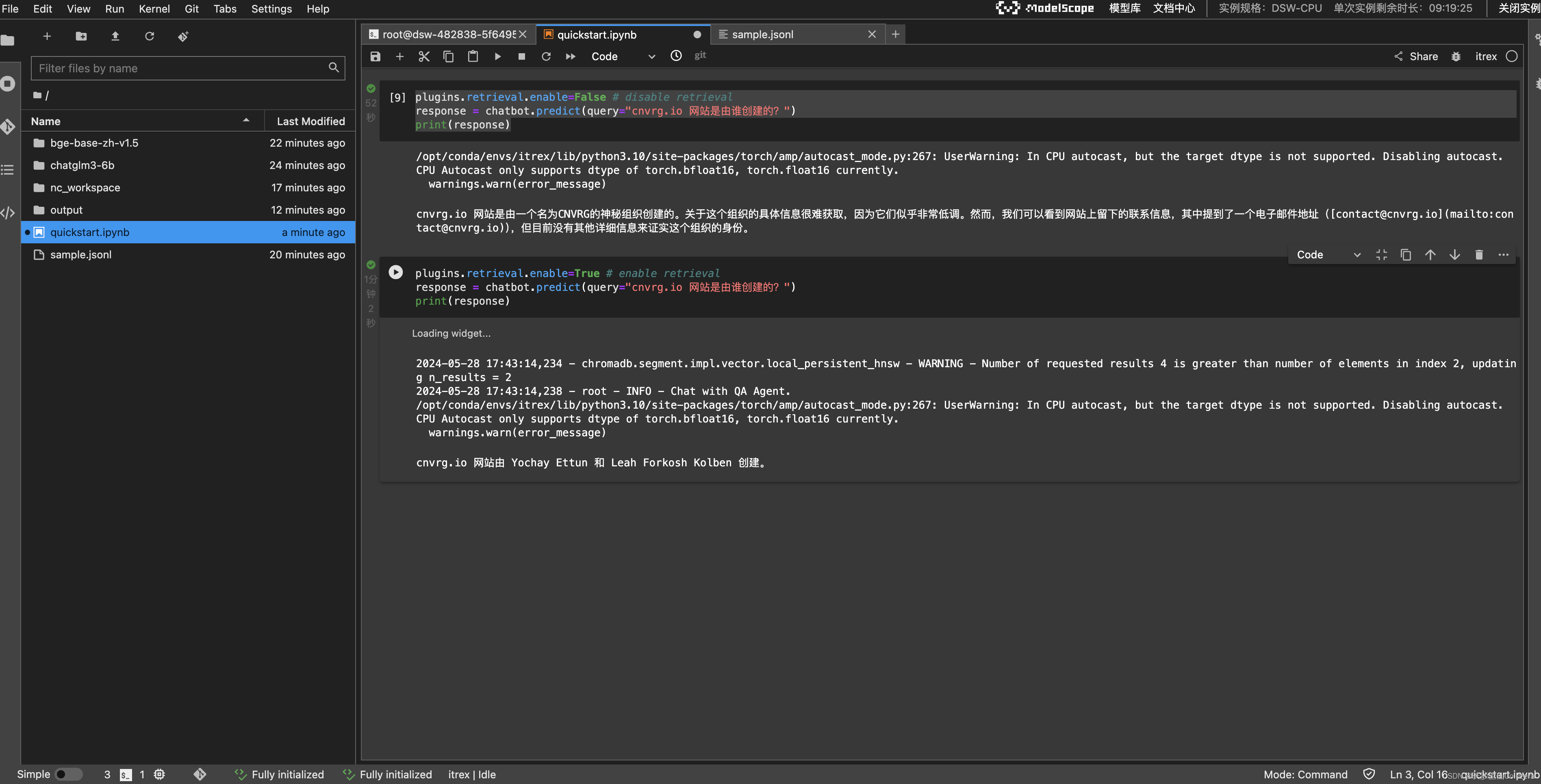
-
总结
ITREX提供了一个在Intel CPU上进行高效推理的方案,不仅支持多种前沿的Efficient inference技术,并且与Intel硬件结合地很好。
利用Intel transformers拓展包加速CPU大模型推理
最新推荐文章于 2024-05-30 00:09:42 发布
















 4076
4076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









