







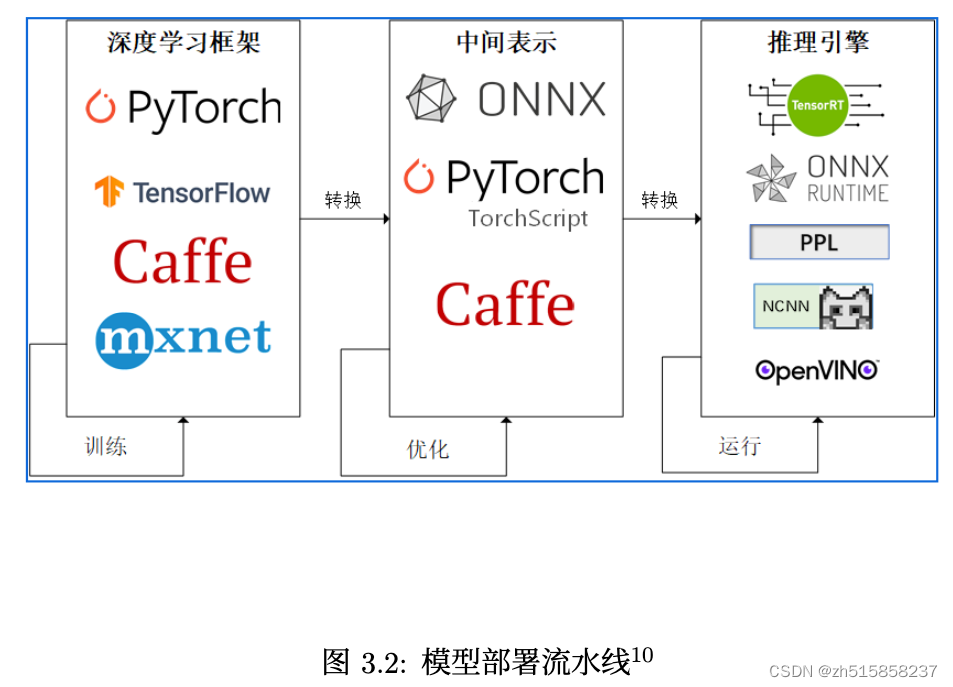
一、模型部署框架有哪些?
一些常见的部署框架和工具包括 TensorFlow Serving、ONNX Runtime、OpenVINO、TensorRT、TorchScript 等。
例如通过onnxruntime框架优化,可以在原有数据上面测试模型推理速度提升7倍。
二、模型压缩方法有哪些?
- 剪枝:剪枝是一种通过去除模型中一些不必要的连接或神经元来减小
模型大小的技术。 - 蒸馏:蒸馏是一种通过使用学生模型来模拟预训练教师模型的行为来 减小模型大小的技术。通常情况下,学生模型由更小的神经网络或线 性模型组成。
- 量化:量化是一种将预训练模型中的权重从浮点数转换为低位数的技 术。通常情况下,量化的精度是 8 位或更低。量化可以大大减少模型 的存储空间和计算量,但可能会对模型的性能产生一定的影响。
- 权重矩阵分解:使用包括 SVD 等矩阵分解方法对预训练模型的 FFN 层的权重矩阵进行分解,从而减少 Attention 层的参数量,提高模型的 效率。
- 模型参数共享:以 ALBERT 为例,模型的 Attention 层之间采用了权 重共享的方式,从而减少了模型的参数量[27] 。















 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









