







百度飞桨部署全流程讲解以及Jetson nano部署实战案例(上)
这个是我看了反复看了四五遍BML的培训的部署课程写的一个理解,可能有理解不到位的地方可以看下原B站视频,讲的也很好。
https://www.bilibili.com/video/BV1YQ4y127rB?from=search&seid=4040677619604070442&spm_id_from=333.337.0.0
这里是由于内容体系太复杂太多了,所以分为上下两个,第一部分写下整个飞桨的部署推理理论的核心架构,第二部分在我自己的Jetson nano上跑下视频中的实例。
首先什么是部署,在飞桨中简单来说就是我没有GPU或者一些好的硬件设备。但是我可以先在平台上进行训练,然后把这个模型放到像服务器或者我自己的硬件设备你可以看作是一个小服务器上面去。
那这两个有什么区别呢?服务器肯定是好的,性能够强,迭代够快。适合互联网呀、大公司这种情况。那边缘端其实工业上都会经常考虑的,一些小任务量的反复的工作其实也不需要那么高的性能和迭代,所以智能硬件发挥了很大的作用。

那总的来说,为什么玩AI的人叫炼丹?看一下下面的AI项目的一般步骤,首先是我接了一个项目,然后我用了很多数据集给他们标记好,然后开始修改模型,调调参数做一个模型出来。然后我们把这个模型放到一个硬件上去,就可以在工业上使用了,然后一个项目get,钱就赚到了。
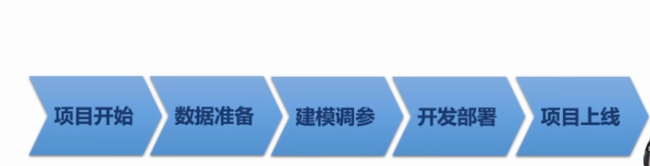
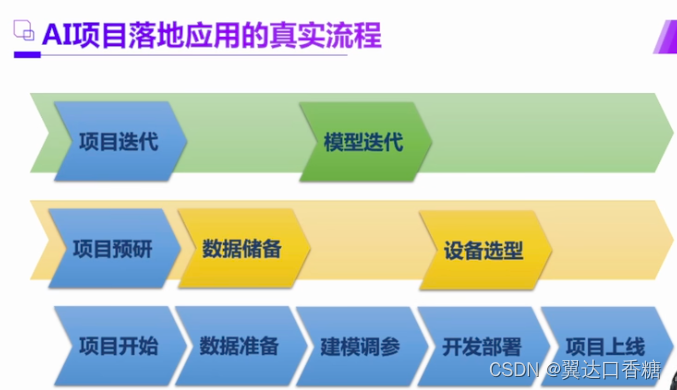
但是这期间不会这么顺的呀,首先那么我不仅要检测裂痕了,我还要检测个杂物,是不是要多个功能。然后何恺明大佬又出了一个新的模型了,那你是不是想换一下,然后龙芯又出新的芯片A35000了那是不是得换一下,所以百度这边的真实流程是下图。
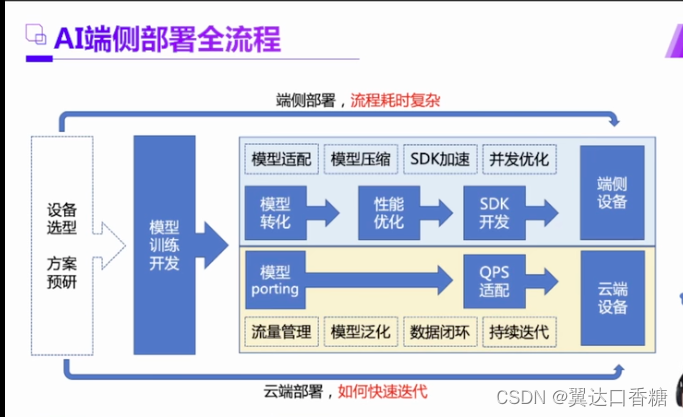
专业的流程如下图,上面是端侧,部署起来需要SDK。下面的QPS云端设备需要用一下。
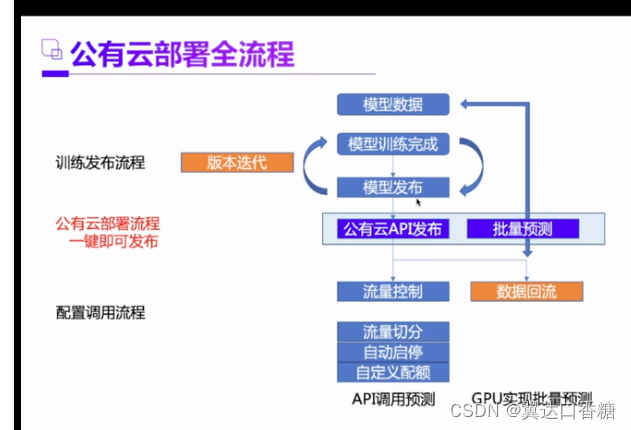
emm—这里就是百度自己家给自己做广告了,说用他们的产品这些迭代的过程可以很方遍,而且公有云管理起来很方便。
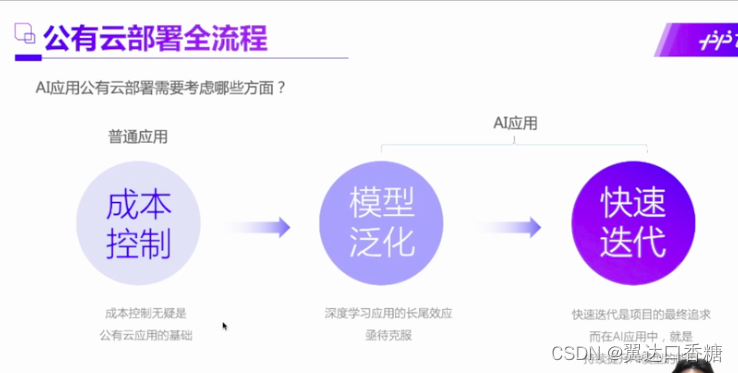
继续做广告哈,首先公有云部署第一点钱少能干就不提了,模型泛化其实几乎所有算法追求的方向。举个例子,比如说我现在针对小猫识别做出了一个很好的模型,然后我能拿这个模型去识别小狗呢,或者识别所有的小动物呢?这个可以大大地减少了模型的强度。
这里是百度特有的一些功能,也是产品优势,不作技术讲解
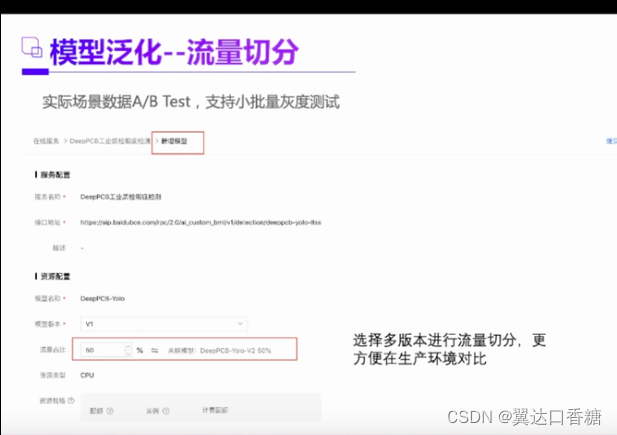
这个功能是不错的
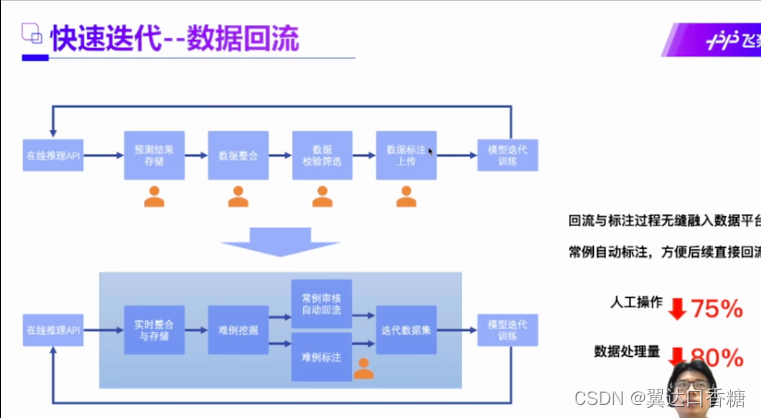
云部署和端侧部署的优缺点比较
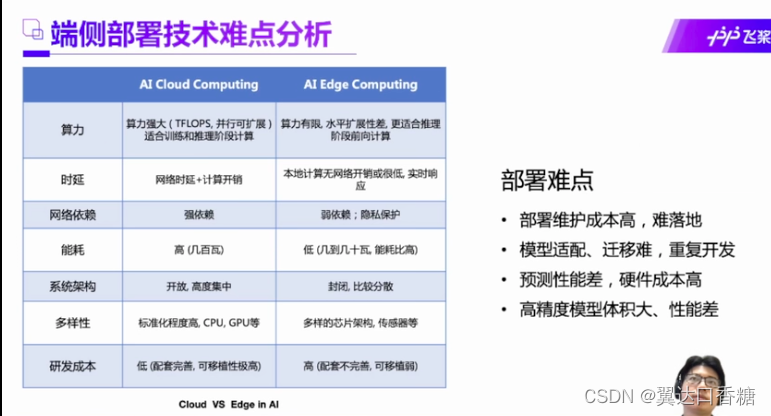
端侧部署现在主要的问题是设备太多了,各种硬件厂商都有自己的标准,这里我做个广告,大佬英伟达我就不多说了,国产华为也是YYDS。龙芯3A5000现在也可以完成了飞桨的认证,也可以玩AI了。当然英特尔的更是推荐,因为英特尔形成了自己完善的体系,几乎所有人的电脑里面都有一块英特尔,通过飞桨你不需要显卡也可以玩AI。

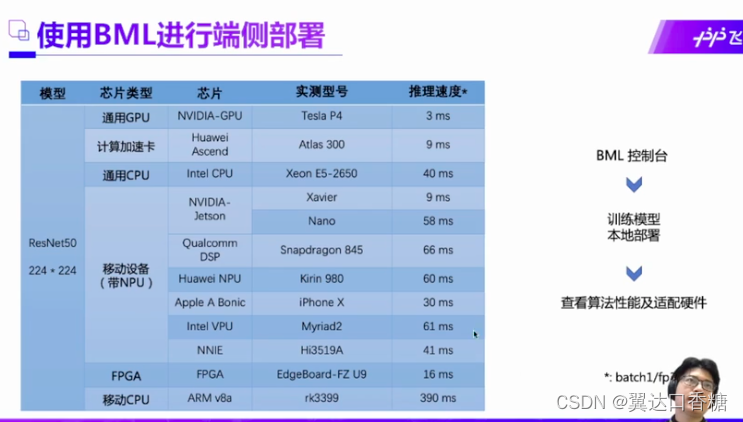
现在我们来看下市面主流的产品的有五种,算力依次递减,GPU价格比较贵,已经深有所感了哈哈哈哈。CPU的价格时最低的在众多的硬件条件中,所以在CPU的推理部署是很值得深入研究的一个领域。像龙芯和英特尔都是不错的CPU品牌。
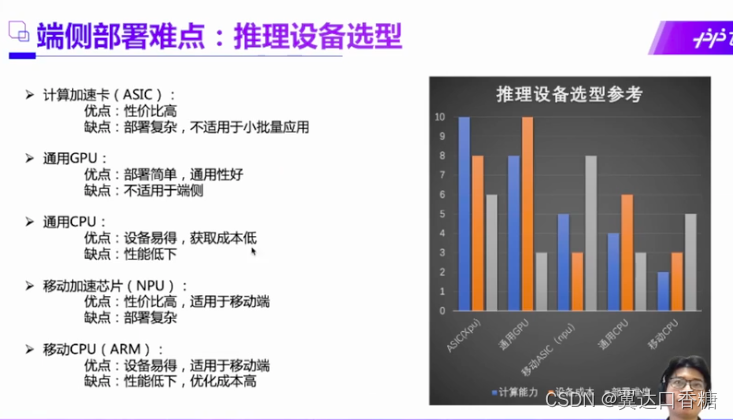
举一个例子,比如说现在一个很典型的经常做的一个项目,我在马路等地方有很多个摄像头,现在想要去识别人脸然后找到这个犯罪份子。那么首先现在的方法是把摄像头连入服务器,然后把所有视频在服务器进行分析,这就叫公有云部署。
那现在我的端侧的AI芯片越来越强大了,那我是不是可以直接在端侧就可以识别出犯罪份子。这就叫端侧部署。
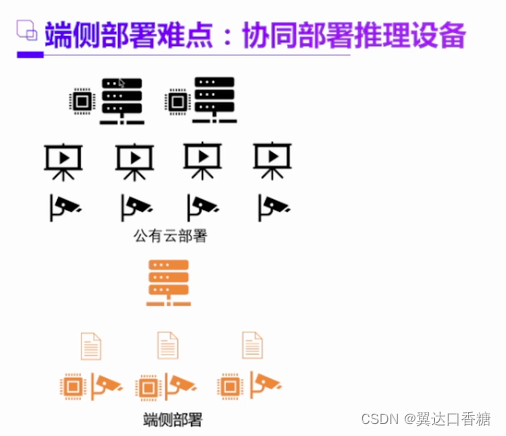
第二种方法,如果我每个摄像头都布置了一个AI芯片,然后对人流先来个人脸识别,把脸先定位出来了,然后把这脸传入到服务器端去识别。这个就是协同部署推理设备的形式。
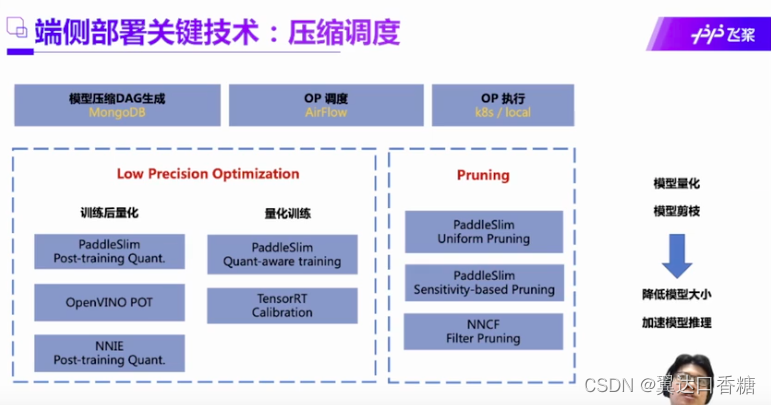
端侧部署其实是对模型的本身的算法机构有一个压缩的过程,就是会把模型进行一些列的处理。这个过程主要分为前置压缩和后置压缩,然后在百度这边发布SDK后,然后在端侧调用SDK。
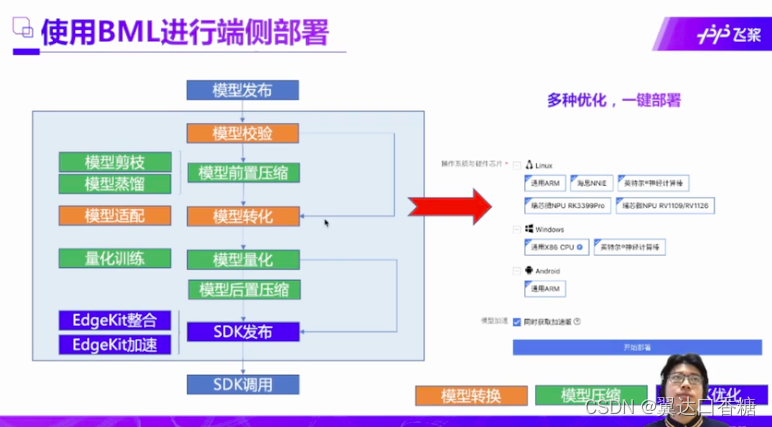
在这个过程中我们主流的深度学习架构不同,然后飞浆平台作为中间媒介,先将主流的深度框架语言转化成中间语言,然后再根据硬件条件的不同部署到不同的硬件。
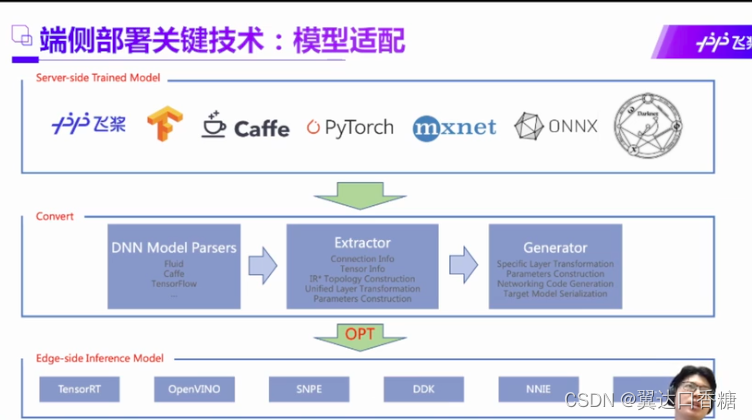
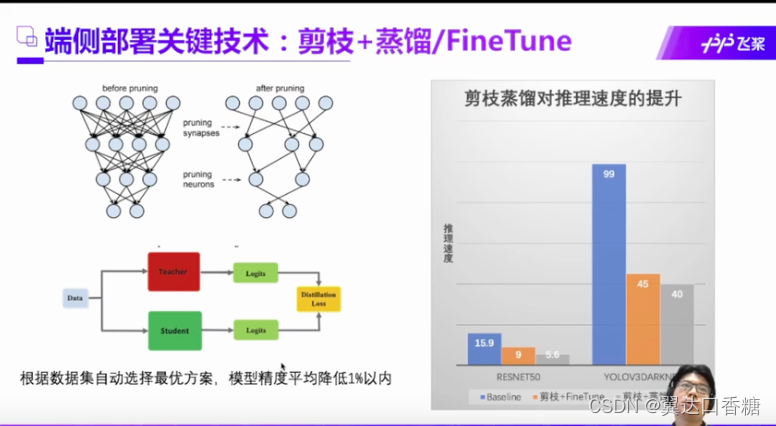
比如说左边的算法融合,把三个算子的计算量简化成一个算子的计算量,然后可以使得模型得到压缩,这种方法有很多,十多种。

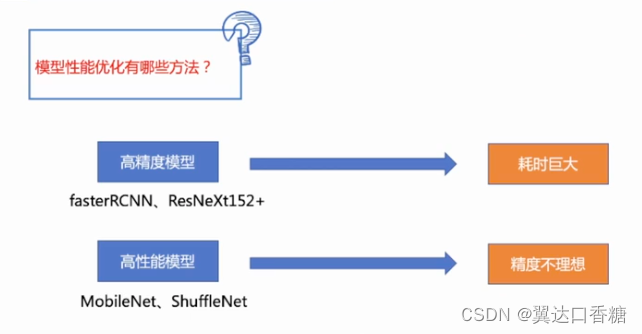
高精度模型需要耗时巨大,高性能模型的精度不够。
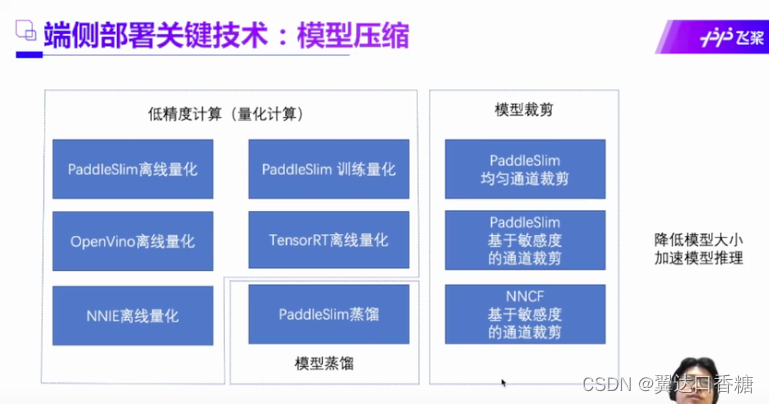
这是模型处理后的性能提升效果。
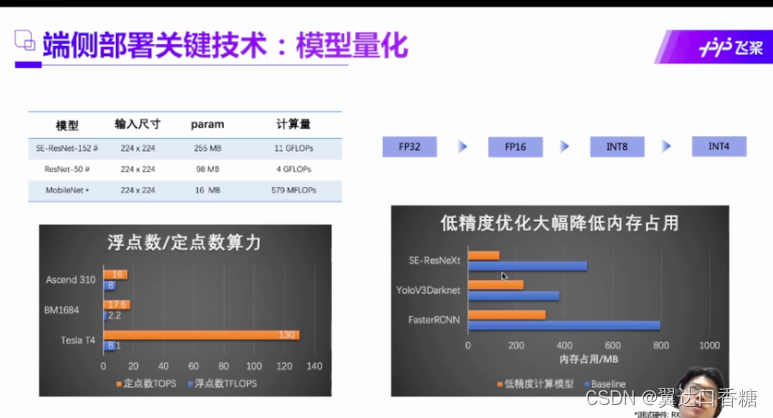
对于模型的精确度和耗时的问题两个,在保持一定的精确度条件下减少耗时,减少耗时提高精度。
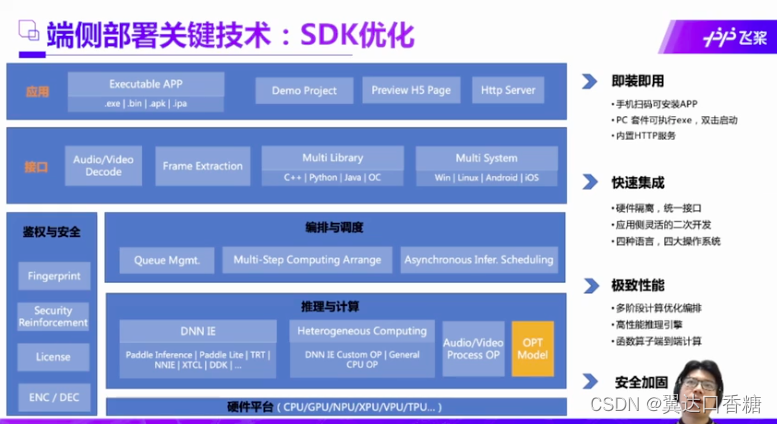
SDK是一个压缩包,在电脑下载后这是一个包的整体结构,可以适配不同语言,不同的硬件环境。

百度这块有个有个硬件商城提供了不少硬件,但是主要是还是以英伟达系列为主的一些硬件,主要分为超高性能、高性能、低成本/小功耗这三类,看不同的需求来购置不同的器件。比如说工业上有预算的话可以买个万把快的期间。

最好那些其实有点贵,学生党买起来有点吃力。我在商城看了一下,很贵。有实力有时间的伙伴还是自己买了部署一下吧。
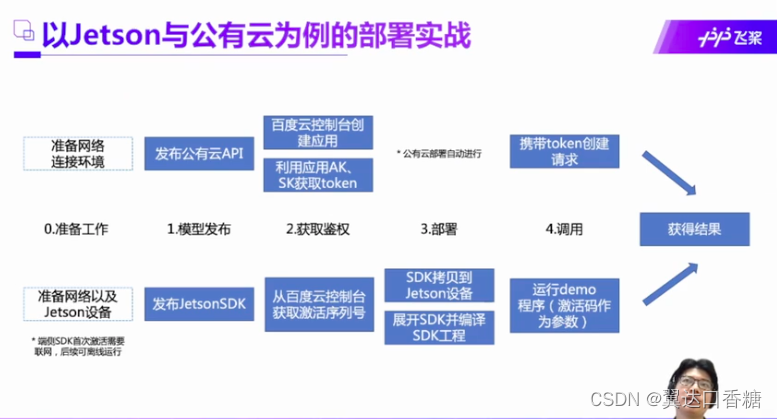
这章图就是后面要分别在服务器和Jetson nano 的部署实战的详细步骤,过几天我把nano弄过来跑一下出个教程。
















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











